EchoVQA: Enabling Conversational Assistance for Point-of-Care Cardiac Ultrasound
Pith reviewed 2026-06-30 15:24 UTC · model grok-4.3
The pith
EchoVQA supplies the first large-scale visual question answering dataset for echocardiography, including guidance questions for point-of-care image acquisition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
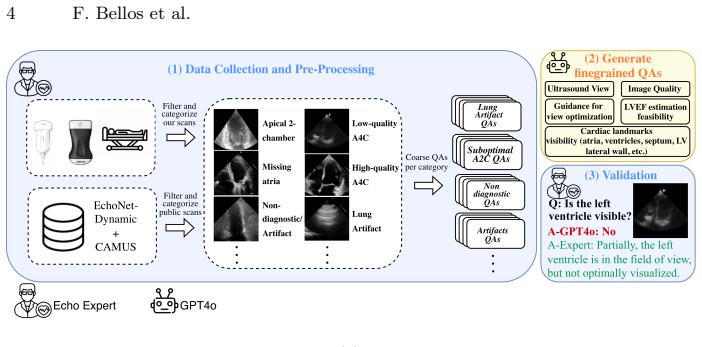
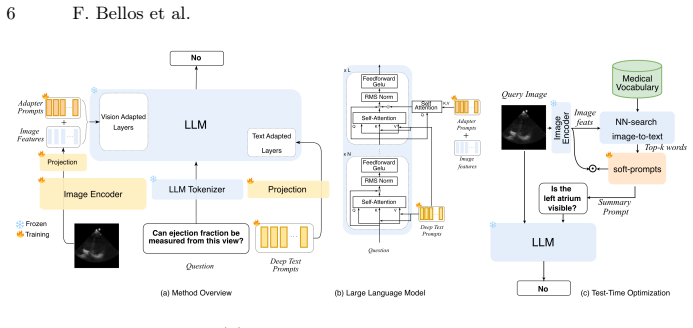
EchoVQA is the first large-scale VQA dataset for echocardiography that merges public high-quality sources with point-of-care acquisitions from handheld probes and uniquely includes acquisition guidance questions to help novice operators optimize transducer positioning toward a diagnostic apical four-chamber view. A multimodal learnable prompts method achieves state-of-the-art performance on EchoVQA and most other benchmarks while requiring significantly fewer trainable parameters than existing approaches.
What carries the argument
The EchoVQA dataset of 14,299 images and 74,819 question-answer pairs that incorporates acquisition guidance questions, combined with a multimodal learnable prompts method for parameter-efficient model adaptation.
If this is right
- Models can supply real-time transducer positioning instructions that help non-experts obtain diagnostic-quality apical four-chamber views during point-of-care scans.
- The same models can answer clinical interpretation questions on both high-quality and suboptimal images typical of handheld use.
- The low parameter count allows the assistance system to run on the limited hardware available in many point-of-care settings.
- Training on mixed high-quality and suboptimal images reduces the performance gap that usually appears when models move from controlled lab data to bedside conditions.
Where Pith is reading between the lines
- The dataset construction approach could be replicated for other ultrasound applications such as lung or abdominal point-of-care imaging.
- Live video rather than static frames would be required to turn the current question-answering system into true conversational guidance during scanning.
- Deployment studies measuring whether novice users actually produce better diagnostic images when following the model's advice would test clinical utility beyond benchmark accuracy.
Load-bearing premise
The combination of public high-quality datasets with new point-of-care acquisitions is representative enough for models to generalize to real clinical point-of-care use.
What would settle it
Testing the trained model on an independent collection of point-of-care echocardiography images and acquisition guidance questions gathered with the same handheld probes but outside the training distribution and measuring whether accuracy on guidance and diagnostic questions falls substantially below reported levels.
Figures

read the original abstract
Point-of-care transthoracic echocardiography (TTE) enables cardiac assessment in virtually any clinical setting, yet its diagnostic utility remains constrained by the expertise required for image acquisition and interpretation. Visual question answering (VQA) offers a promising paradigm for bridging this expertise gap through interactive clinical assistance, but existing echocardiography VQA datasets are limited in scale, restricted to high-quality images, and only cover a few views. We introduce EchoVQA, the first large-scale VQA dataset for echocardiography, comprising 14,299 images and 74,819 question-answer pairs. The dataset integrates public sources (EchoNet-Dynamic, CAMUS) with our own point-of-care acquisitions from two handheld probes (Lumify, Clarius), spanning diverse views and including both high-quality and suboptimal images. Uniquely, EchoVQA includes acquisition guidance questions to help users optimize transducer positioning toward a diagnostic apical 4-chamber view for left ventricular ejection fraction estimation -- a challenging task for novice operators in point-of-care settings. We further develop a parameter-efficient method based on multimodal learnable prompts achieving state-of-the-art performance on most benchmarks, including EchoVQA, with significantly less trainable parameters than existing state-of-the-art approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EchoVQA, the first large-scale VQA dataset for echocardiography comprising 14,299 images and 74,819 question-answer pairs. The dataset combines public sources (EchoNet-Dynamic, CAMUS) with new point-of-care acquisitions from two handheld probes (Lumify, Clarius), spanning diverse views and including both high-quality and suboptimal images. It uniquely incorporates acquisition guidance questions aimed at optimizing transducer positioning for apical 4-chamber views and left ventricular ejection fraction estimation. The authors also propose a parameter-efficient method based on multimodal learnable prompts that is stated to achieve state-of-the-art performance on EchoVQA and most other benchmarks while using significantly fewer trainable parameters than prior approaches.
Significance. If the dataset scale, diversity, and inclusion of acquisition guidance questions are as described and the prompt-based method demonstrably outperforms existing approaches with reduced parameters, the work could provide a valuable benchmark and practical tool for conversational assistance in point-of-care cardiac ultrasound. The emphasis on suboptimal images and real-world acquisition challenges addresses a genuine clinical gap, and the parameter efficiency would be a strength for deployment. However, the significance is currently limited by the absence of supporting quantitative evidence for the performance claims.
major comments (1)
- [Abstract] Abstract: The central claim that the proposed method achieves 'state-of-the-art performance on most benchmarks, including EchoVQA, with significantly less trainable parameters than existing state-of-the-art approaches' is asserted without any quantitative results, baselines, error bars, ablation studies, or description of the evaluation protocol. This absence makes it impossible to assess whether the data support the SOTA claim, which is load-bearing for the paper's contribution.
minor comments (1)
- [Abstract] Abstract: The phrase 'most benchmarks' is used without specifying which benchmarks are included or the criteria for 'most,' reducing clarity on the scope of the performance claims.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the single major comment below and will revise the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the proposed method achieves 'state-of-the-art performance on most benchmarks, including EchoVQA, with significantly less trainable parameters than existing state-of-the-art approaches' is asserted without any quantitative results, baselines, error bars, ablation studies, or description of the evaluation protocol. This absence makes it impossible to assess whether the data support the SOTA claim, which is load-bearing for the paper's contribution.
Authors: We agree that the abstract as currently written asserts the performance claim without supporting numbers, which limits immediate verifiability. The full manuscript contains the requested elements: Section 4 reports quantitative results on EchoVQA and external benchmarks (including accuracy, parameter counts, and comparisons against prior VQA and multimodal models), with ablation studies on prompt design and evaluation protocols detailed in Section 3.2 and the supplementary material; error bars are included for repeated runs. To address the concern directly, we will revise the abstract to incorporate key quantitative highlights (e.g., specific accuracy gains and parameter reductions relative to baselines) while preserving its length constraints. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims consist of introducing a new dataset (EchoVQA with explicit size, sources, and question types) and describing a parameter-efficient multimodal prompt method that achieves reported benchmark results. No equations, fitted parameters, predictions, or derivation steps appear in the abstract or described content. The work is self-contained as a data-collection and empirical-method contribution; no self-citation chain, ansatz smuggling, or input-renaming reductions are present. This matches the default expectation for non-circular papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bick, J.S., Demaria, S., Kennedy, J.D., Schwartz, A.D., Weiner, M.M., Levine, A.I., Shi, Y., Schildcrout, J.S., Wagner, C.E.: Comparison of expert and novice perfor- mance of a simulated transesophageal echocardiography examination. Simulation in Healthcare: Journal of the Society for Simulation in Healthcare8(5), 329–334 (Oct 2013). https://doi.org/10.10...
-
[2]
Circulation95(6), 1686– 1744 (Mar 1997)
Cheitlin, M.D., et al.: ACC/AHA Guidelines for the Clini- cal Application of Echocardiography. Circulation95(6), 1686– 1744 (Mar 1997). https://doi.org/10.1161/01.CIR.95.6.1686, https://www.ahajournals.org/doi/10.1161/01.cir.95.6.1686, publisher: Ameri- can Heart Association
-
[3]
arXiv preprint arXiv:2401.02797 (2024)
He, J., Li, P., Liu, G., He, G., Chen, Z., Zhong, S.: Pefomed: Parameter effi- cient fine-tuning of multimodal large language models for medical imaging. arXiv preprint arXiv:2401.02797 (2024). https://doi.org/10.48550/arXiv.2401.02797
-
[4]
Rico Sennrich, Barry Haddow, and Alexandra Birch
He, X., Cai, Z., Wei, W., Zhang, Y., Mou, L., Xing, E., Xie, P.: Towards visual question answering on pathology images. In: Zong, C., Xia, F., Li, W., Navigli, R. (eds.) Proceedings of the 59th Annual Meeting of the Association for Compu- tational Linguistics and the 11th International Joint Conference on Natural Lan- guage Processing (Volume 2: Short Pap...
-
[5]
In: Interna- tional Conference on Learning Representations (ICLR) (2022)
Hu, E.J., et al.: Lora: Low-rank adaptation of large language models. In: Interna- tional Conference on Learning Representations (ICLR) (2022)
2022
-
[6]
In: Experimental IR Meets Multilinguality, Multimodality, and Interaction
Ionescu, B., et al.: Overview of the imageclef 2022: Multimedia retrieval in medical, social media and nature applications. In: Experimental IR Meets Multilinguality, Multimodality, and Interaction. Lecture Notes in Computer Science, vol. 13390, pp. 541–564. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-13643-6_31
-
[7]
Johnson, A.E.W., et al.: Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific Data6, 317 (2019). https://doi.org/10.1038/s41597-019-0322-0 10 F. Bellos et al
-
[8]
BMC Primary Care24, 183 (Sep 2023)
Kornelsen, J., Ho, H., Robinson, V., Frenkel, O.: Rural family physician use of point-of-care ultrasonography: experiences of pri- mary care providers in British Columbia, Canada. BMC Primary Care24, 183 (Sep 2023). https://doi.org/10.1186/s12875-023-02128-z, https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10486031/
-
[9]
Scientific Data5, 180251 (2018)
Lau, J.J., Gayen, S., Ben Abacha, A., Demner-Fushman, D.: A dataset of clinically generated visual questions and answers about radiology images. Scientific Data5, 180251 (2018). https://doi.org/10.1038/sdata.2018.251
-
[10]
IEEE Transactions on Medical Imaging38(9), 2198–2210 (2019)
Leclerc, S., et al.: Deep learning for segmentation using an open large-scale dataset in 2d echocardiography. IEEE Transactions on Medical Imaging38(9), 2198–2210 (2019). https://doi.org/10.1109/TMI.2019.2900516
-
[11]
In: Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track (2023), spotlight
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava-med: Training a large language-and-vision assistant for biomedicine in one day. In: Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track (2023), spotlight
2023
-
[12]
Artificial Intelligence in Medicine143, 102611 (2023)
Lin, Z., Zhang, D., Tao, Q., Shi, D., Haffari, G., Wu, Q., He, M., Ge, Z.: Medical visual question answering: A survey. Artificial Intelligence in Medicine143, 102611 (2023). https://doi.org/10.1016/j.artmed.2023.102611
-
[13]
Liu, B., Zhan, L.M., Xu, L., Ma, L., Yang, Y., Wu, X.M.: Slake: A semantically- labeledknowledge-enhanceddatasetformedicalvisualquestionanswering.In:2021 IEEE18thInternationalSymposiumonBiomedicalImaging(ISBI).pp.1650–1654. IEEE (2021). https://doi.org/10.1109/ISBI48211.2021.9434010
-
[14]
In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. In: Advances in Neural Information Processing Systems (NeurIPS) (2023)
2023
-
[15]
Liu, X., Ji, K., Fu, Y., Tam, W.L., Du, Z., Yang, Z., Tang, J.: P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In: Proceedings of the 60th Annual Meeting of the Association for Com- putational Linguistics (Volume 2: Short Papers). pp. 61–68. Association for Computational Linguistics (2022). https://doi.org/10.18653/v1/20...
-
[16]
Mitchell, C., et al.: Guidelines for Performing a Comprehensive Transthoracic Echocardiographic Examination in Adults: Recommendations from the American Society of Echocardiography. Journal of the American Society of Echocardiogra- phy: Official Publication of the American Society of Echocardiography32(1), 1–64 (Jan 2019). https://doi.org/10.1016/j.echo.2...
-
[17]
OpenAI, et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023). https://doi.org/10.48550/arXiv.2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[18]
Nature580(7802), 252–256 (Apr 2020)
Ouyang, D., et al.: Video-based AI for beat-to-beat assessment of cardiac function. Nature580(7802), 252–256 (Apr 2020). https://doi.org/10.1038/s41586-020-2145- 8, https://www.nature.com/articles/s41586-020-2145-8, publisher: Nature Pub- lishing Group
-
[19]
Pelka, O., Koitka, S., Rückert, J., Nensa, F., Friedrich, C.M.: Radiology objects in context (roco): A multimodal image dataset. In: Multimodal Learning for Clinical Decision Support and Clinical Image-Based Procedures (LABELS / CVII-STENT @MICCAI).LectureNotesinComputerScience,vol.11043,pp.180–189.Springer, Cham (2018). https://doi.org/10.1007/978-3-030-...
-
[20]
In: Findings of the Association for Computational Linguistics: EMNLP
Subramanian,S.,etal.:Medicat:Adatasetofmedicalimages,captions,andtextual references. In: Findings of the Association for Computational Linguistics: EMNLP
-
[21]
pp. 2112–2120. Association for Computational Linguistics, Online (2020). https://doi.org/10.18653/v1/2020.findings-emnlp.191 Title Suppressed Due to Excessive Length 11
-
[22]
Thapa, R., Li, A., Wu, Q., He, B., Sahashi, Y., Binder-Rodriguez, C., Zhang, A., Ouyang, D., Zou, J.: MIMIC-IV-ECHO-Ext-MIMICEchoQA: A Benchmark Dataset for Echocardiogram-Based Visual Question Answering. PhysioNet (Oct 2025). https://doi.org/10.13026/rndk-4s36, https://doi.org/10.13026/rndk-4s36, version 1.0.0
-
[23]
ArXiv (Jul 2023)
Touvron, H., et al.: Llama 2: Open Foundation and Fine-Tuned Chat Models. ArXiv (Jul 2023)
2023
-
[24]
In: International Conference on Learning Rep- resentations (ICLR) (2025)
Xie, Y., Zhou, C., Gao, L., Wu, J., Li, X., Zhou, H.Y., Liu, S., Xing, L., Zou, J., Xie, C., Zhou, Y.: Medtrinity-25m: A large-scale multimodal dataset with multi- granular annotations for medicine. In: International Conference on Learning Rep- resentations (ICLR) (2025)
2025
-
[25]
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Zhang, R., et al.: LLaMA-Adapter: Efficient Fine-tuning of Language Mod- els with Zero-init Attention (2023). https://doi.org/10.48550/ARXIV.2303.16199, https://arxiv.org/abs/2303.16199, publisher: arXiv Version Number: 3
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.16199 2023
-
[26]
Zhang,S.,etal.:Biomedclip:amultimodalbiomedicalfoundationmodelpretrained from fifteen million scientific image-text pairs. arXiv preprint arXiv:2303.00915 (2023). https://doi.org/10.48550/arXiv.2303.00915
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.00915 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.