PeerBTS: Incentivizing Effort in Strategyproof Peer Selection
Pith reviewed 2026-06-30 14:27 UTC · model grok-4.3
The pith
Incentivizing effort in peer selection requires information beyond any single evaluation from each agent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
No single-evaluation peer-selection rule can incentivize costly effort; attaching a Robust Bayesian Truth Serum peer-prediction lottery to any existing Bayes-Nash incentive-compatible mechanism produces a new rule that rewards accurate evaluation while preserving the original incentive properties.
What carries the argument
PeerBTS, the composite mechanism that layers a peer-prediction lottery onto any base peer-selection rule.
If this is right
- Agents will choose higher effort levels when the lottery component is present than when it is absent.
- The overall mechanism remains Bayes-Nash incentive compatible for any base mechanism that already satisfies that property.
- Selection accuracy can improve because agents now have reason to produce higher-quality evaluations.
- The approach works with any existing strategyproof peer-selection rule without redesigning the base rule.
Where Pith is reading between the lines
- In settings such as MOOC grading or conference review, the lottery could be funded from a small tax on the selection prizes themselves.
- If the common-prior assumption fails, the lottery may need to be replaced by a mechanism that elicits beliefs directly.
- The same layering technique might be applied to other multi-agent selection problems where effort is costly but unobservable.
Load-bearing premise
All agents share common prior beliefs about the distribution of true qualities and about one another's reporting strategies.
What would settle it
A controlled experiment in which agents receive different private signals about quality distributions and the combined mechanism produces lower effort or truthful reporting rates than the base mechanism alone.
Figures


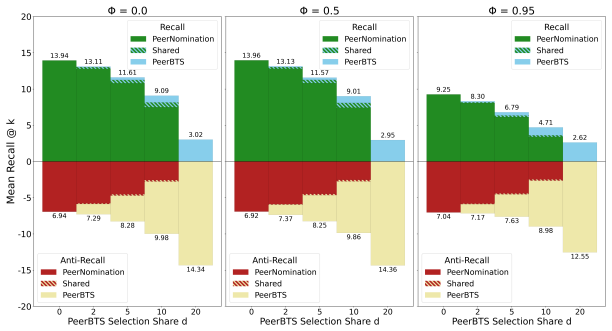


read the original abstract
Peer selection, the evaluation and selection of agents by their peers, is an important problem in the field of computational social choice; with applications to grading in massively online courses (MOOCs) and academic peer review. Current existing algorithmic and empirical work focuses on developing and analyzing novel \emph{strategyproof} mechanisms, wherein no agent has an incentive to misreport their evaluations. However, the majority of published mechanisms share a flaw: they do not \emph{reward} agents for any effort expended during the evaluation process. In cases where high quality evaluations are costly to produce this missing incentive fails to align agents with an overall goal of accurate selection. To address this gap we first prove theoretically that incentivizing effort in peer selection requires information beyond a single evaluation. We then propose \textsc{PeerBTS}, a mechanism that combines a peer-prediction lottery, leveraging work on the Robust Bayesian Truth Serum, with any existing peer-selection mechanism to incentivize effort while remaining Bayes-Nash incentive compatible. We find that while an incentive-compatible peer-selection mechanism using agent predictions to incentivize effort is possible it requires adjustments to the assumed problem context and limits other mechanistics properties. We additionally present a series of non-strategic simulations to validate incentives and evaluate the performance of PeerBTS relative to existing strategyproof peer selection mechanisms. Finally, we discuss the results of an initial study on the validity of peer-prediction from a small academic workshop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to prove theoretically that no single-evaluation peer-selection mechanism can incentivize costly effort, then proposes PeerBTS: a modular construction that augments any existing strategyproof peer-selection mechanism with a Robust Bayesian Truth Serum (RBTS) peer-prediction lottery. The combined mechanism is asserted to remain Bayes-Nash incentive compatible while providing effort incentives. Support is offered via non-strategic simulations comparing performance to existing mechanisms and a small empirical study on the validity of peer predictions in an academic workshop setting.
Significance. If the impossibility result and the BNIC preservation claim hold under the stated assumptions, the work addresses a genuine gap in computational social choice: existing strategyproof peer-selection mechanisms (e.g., for MOOCs or peer review) provide no reward for evaluation effort. The modular design is a positive feature. However, the reliance on common priors for both the impossibility and the incentive transfer, together with the absence of strategic analysis or quantitative performance metrics, reduces the immediate impact. The small workshop study offers limited empirical grounding.
major comments (3)
- [Abstract] Abstract and introduction: the central impossibility claim—that incentivizing effort requires information beyond a single evaluation—is asserted without a formal theorem statement, proof sketch, or explicit list of maintained assumptions (including common priors over qualities and strategies). This is load-bearing for the motivation of PeerBTS.
- [Mechanism Design] Mechanism section (PeerBTS construction): the claim that grafting the RBTS lottery onto an arbitrary base mechanism preserves Bayes-Nash incentive compatibility is presented as transferring unchanged, yet the manuscript does not derive or cite the precise conditions under which RBTS truthfulness survives the composition; the common-prior assumption is invoked but not stress-tested for robustness.
- [Simulations] Simulations section: the reported experiments are explicitly non-strategic and supply no quantitative performance numbers, effort levels, or strategic deviation analysis; this leaves the validation of the claimed effort incentives and BNIC properties unsupported by the presented evidence.
minor comments (2)
- [Mechanism Design] Notation for the RBTS component and the base mechanism should be unified and defined before the combination is described to improve readability.
- [Empirical Study] The small workshop study would benefit from clearer reporting of sample size, selection criteria, and statistical tests used to assess peer-prediction validity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the central impossibility claim—that incentivizing effort requires information beyond a single evaluation—is asserted without a formal theorem statement, proof sketch, or explicit list of maintained assumptions (including common priors over qualities and strategies). This is load-bearing for the motivation of PeerBTS.
Authors: We agree that the abstract and introduction would benefit from greater formality. The full manuscript contains the proof of the impossibility result, but we will revise the abstract and introduction to include an explicit theorem statement, a proof sketch, and a clear list of assumptions including the common-prior requirement over qualities and strategies. revision: yes
-
Referee: [Mechanism Design] Mechanism section (PeerBTS construction): the claim that grafting the RBTS lottery onto an arbitrary base mechanism preserves Bayes-Nash incentive compatibility is presented as transferring unchanged, yet the manuscript does not derive or cite the precise conditions under which RBTS truthfulness survives the composition; the common-prior assumption is invoked but not stress-tested for robustness.
Authors: The BNIC preservation follows from the composition of the base mechanism's strategyproofness with the known BNIC properties of RBTS under common priors. We will revise the mechanism section to derive the precise conditions for the composition, cite the relevant RBTS results, and add a discussion of the common-prior assumption's role and potential robustness considerations. revision: yes
-
Referee: [Simulations] Simulations section: the reported experiments are explicitly non-strategic and supply no quantitative performance numbers, effort levels, or strategic deviation analysis; this leaves the validation of the claimed effort incentives and BNIC properties unsupported by the presented evidence.
Authors: The simulations are intentionally non-strategic, as stated in the manuscript, and serve to compare performance metrics of PeerBTS against existing mechanisms under truthful reporting; the effort incentives and BNIC properties are established theoretically rather than via simulation. We will add quantitative performance numbers and clarify the scope and limitations of the simulations, while noting that full strategic analysis remains future work. revision: partial
Circularity Check
No significant circularity; derivation relies on external RBTS properties and standard assumptions
full rationale
The paper's core steps are (1) a new impossibility theorem showing single-evaluation mechanisms cannot incentivize effort (under common priors) and (2) a construction that grafts an RBTS-based lottery onto an arbitrary base mechanism while preserving BNIC. Neither step reduces by construction to the paper's own fitted values, self-citations, or renamed inputs. The RBTS component is treated as a black-box leveraging prior external work; the impossibility proof is derived directly rather than fitted or self-referential. The common-prior assumption is maintained but does not create a definitional loop or self-citation chain. This is a standard non-circular theoretical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fischer, Ariel D
Noga Alon, Felix A. Fischer, Ariel D. Procaccia, and Moshe Tennenholtz. 2011. Sum of us: strategyproof selection from the selectors. InProceedings of the 13th Conference on Theoretical Aspects of Rationality and Knowledge (TARK-2011), Groningen, The Netherlands, July 12-14, 2011, Krzysztof R. Apt (Ed.). ACM, 101–
2011
-
[2]
doi:10.1145/2000378.2000390
-
[3]
Parinaz Naghizadeh Ardabili and Mingyan Liu. 2013. Incentives, Quality, and Risks: A Look Into the NSF Proposal Review Pilot.CoRRabs/1307.6528 (2013). arXiv:1307.6528 http://arxiv.org/abs/1307.6528
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[4]
Kenneth J Arrow, Robert Forsythe, Michael Gorham, Robert Hahn, Robin Hanson, John O Ledyard, Saul Levmore, Robert Litan, Paul Milgrom, Forrest D Nelson, et al. 2008. The promise of prediction markets. 877–878 pages
2008
-
[5]
Rosenschein, and Toby Walsh
Haris Aziz, Omer Lev, Nicholas Mattei, Jeffrey S. Rosenschein, and Toby Walsh
-
[6]
Strategyproof peer selection using randomization, partitioning, and appor- tionment.Artificial Intelligence275 (2019), 295–309. doi:10.1016/j.artint.2019.06. 004
-
[7]
Haris Aziz, Evi Micha, and Nisarg Shah. 2023. Group Fairness in Peer Review. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine (Eds.). htt...
2023
-
[8]
Niclas Boehmer, Piotr Faliszewski, Łukasz Janeczko, Andrzej Kaczmarczyk, Grze- gorz Lisowski, Grzegorz Pierczyński, Simon Rey, Dariusz Stolicki, Stanisław Szufa, and Tomasz Was. 2024. Guide to numerical experiments on elections in computational social choice. InProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. 7962–7970
2024
-
[9]
2015.An introduction to the theory of mechanism design
Tilman Börgers. 2015.An introduction to the theory of mechanism design. Oxford university press
2015
-
[10]
Ioannis Caragiannis, George A Krimpas, and Alexandros A Voudouris. 2015. Aggregating Partial Rankings with Applications to Peer Grading in Massive Online Open Courses. InProceedings of the 2015 International Conference on Autonomous Agents and Multiagent Systems. 675–683
2015
-
[11]
Anujit Chakraborty, Jatin Jindal, and Swaprava Nath. 2024. Removing Bias and Incentivizing Precision in Peer-grading.J. Artif. Intell. Res.79 (2024), 1001–1046. doi:10.1613/JAIR.1.15329
-
[12]
S Cole, JR Cole, and GA Simon. 1981. Chance and consensus in peer review. Science214, 4523 (1981), 881–886. doi:10.1126/science.7302566
-
[13]
Morris H DeGroot. 1974. Reaching a consensus.Journal of the American Statistical association69, 345 (1974), 118–121
1974
-
[14]
Piotr Faliszewski and Ariel D Procaccia. 2010. AI’s war on manipulation: Are we winning?AI Magazine31, 4 (2010), 53–64
2010
-
[15]
Christian Genest and James V Zidek. 1986. Combining probability distributions: A critique and an annotated bibliography.Statist. Sci.1, 1 (1986), 114–135
1986
-
[16]
Iryna Gurevych, Anna Rogers, Nihar B Shah, and Jingyan Wang. 2024. Reviewer No. 2: Old and New Problems in Peer Review (Dagstuhl Seminar 24052).Dagstuhl Reports14, 1 (2024), 130–161
2024
-
[17]
Shah, Vincent Conitzer, and Fei Fang
Steven Jecmen, Hanrui Zhang, Ryan Liu, Nihar B. Shah, Vincent Conitzer, and Fei Fang. 2020. Mitigating Manipulation in Peer Review via Randomized Reviewer Assignments. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, Hugo Larochelle, Marc’Au...
2020
-
[18]
Maurice G Kendall. 1938. A new measure of rank correlation.Biometrika30, 1/2 (1938), 81–93
1938
-
[19]
1936.The State of Long-Term Expectation
John Maynard Keynes. 1936.The State of Long-Term Expectation. Macmillan, London, Chapter 12, 147–164
1936
-
[20]
Procaccia
David Kurokawa, Omer Lev, Jamie Morgenstern, and Ariel D. Procaccia. 2015. Impartial Peer Review. InProceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, July 25-31, 2015, Qiang Yang and Michael J. Wooldridge (Eds.). AAAI Press, 582–588. http://ijcai.org/Abstract/15/088
2015
-
[21]
Omer Lev, Harper Lyon, and Nicholas Mattei. 2024. Impartial Peer Selection: An Annotated Reading List.ACM SIGecom Exchanges22, 1 (2024), 113–117
2024
-
[22]
Omer Lev, Nicholas Mattei, Paolo Turrini, and Stanislav Zhydkov. 2023. Peer- Nomination: A novel peer selection algorithm to handle strategic and noisy assessments.Artificial Intelligence316 (2023), 103843
2023
-
[23]
Heng Luo, Anthony C Robinson, and Jae-Young Park. 2014. Peer grading in a MOOC: Reliability, validity, and perceived effects.Journal of Asynchronous Learning Networks18, 2 (2014), n2
2014
-
[24]
2024.Drawing Lots: From Egalitarianism to Democ- racy in Ancient Greece
Irad Malkin and Josine Blok. 2024.Drawing Lots: From Egalitarianism to Democ- racy in Ancient Greece. Oxford University Press
2024
-
[25]
Colin L Mallows. 1957. Non-null ranking models. I.Biometrika44, 1/2 (1957), 114–130
1957
-
[26]
Robert A McNutt, Arthur T Evans, Robert H Fletcher, and Suzanne W Fletcher
-
[27]
The Journal of the American Medical Association263, 10 (1990), 1371–1376
The Effects of Blinding on the Quality of Peer Review: A Randomized Trial. The Journal of the American Medical Association263, 10 (1990), 1371–1376
1990
-
[28]
Michael R Merrifield and Donald G Saari. 2009. Telescope time without tears: a distributed approach to peer review.Astronomy & Geophysics50, 4 (2009), 4–16
2009
-
[29]
Miranda Mowbray and Dieter Gollmann. 2007. Electing the Doge of Venice: Analysis of a 13th century protocol. InProceedings of the IEEE Symposium on Computer Security Foundations. 295–310
2007
-
[30]
Matthew Olckers and Toby Walsh. 2022. Manipulation and Peer Mechanisms: A Survey.CoRRabs/2210.01984 (2022). arXiv:2210.01984 doi:10.48550/ARXIV.2210. 01984
-
[32]
Tuned Models of Peer Assessment in MOOCs
Chris Piech, Jonathan Huang, Zhenghao Chen, Chuong B. Do, Andrew Y. Ng, and Daphne Koller. 2013. Tuned Models of Peer Assessment in MOOCs.CoRR abs/1307.2579 (2013). arXiv:1307.2579 http://arxiv.org/abs/1307.2579
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[33]
Dražen Prelec. 2004. A Bayesian Truth Serum for Subjective Data.Science306, 5695 (2004), 462–466. arXiv:https://www.science.org/doi/pdf/10.1126/science.1102081 doi:10.1126/ science.1102081
-
[34]
Goran Radanovic and Boi Faltings. 2013. A Robust Bayesian Truth Serum for Non- Binary Signals. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 27. 833–839
2013
-
[35]
2006.Behavioral social choice: probabilistic models, statistical inference, and applications
Michel Regenwetter. 2006.Behavioral social choice: probabilistic models, statistical inference, and applications. Cambridge University Press
2006
-
[36]
Reinhard Selten. 1998. Axiomatic characterization of the quadratic scoring rule. Experimental Economics1, 1 (1998), 43–61
1998
-
[37]
Nihar B. Shah. 2022. Challenges, experiments, and computational solutions in peer review.Commun. ACM65, 6 (2022), 76–87. doi:10.1145/3528086
- [38]
-
[39]
2016.Superforecasting: The art and science of prediction
Philip E Tetlock and Dan Gardner. 2016.Superforecasting: The art and science of prediction. Random House
2016
-
[40]
Christine Wenneras and Agnes Wold. 1997. Nepotism and sexism in peer-review. Nature387 (1997), 341–343. doi:10.1038/387341a0
-
[41]
Jens Witkowski and David C. Parkes. 2012. A Robust Bayesian Truth Serum for Small Populations. InProceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, July 22-26, 2012, Toronto, Ontario, Canada, Jörg Hoffmann and Bart Selman (Eds.). AAAI Press, 1492–1498. doi:10.1609/AAAI.V26I1.8261
-
[42]
Justin Wolfers and Eric Zitzewitz. 2004. Prediction markets.Journal of economic perspectives18, 2 (2004), 107–126
2004
-
[43]
Yichong Xu, Han Zhao, Xiaofei Shi, and Nihar B. Shah. 2019. On strategyproof conference peer review. InProceedings of the 28th International Joint Conference on Artificial Intelligence(Macao, China)(IJCAI’19). AAAI Press, 616–622. A APPENDIX A.1 Proofs for Conditions for Incentive Compatability For the lottery mechanism described in Algorithm 2 to inherit...
2019
-
[44]
To prove Theorem 2, we first need several lemmata
(the common theoretical assumption made by peer-selection papers), or any other relevant distribution to the particular situa- tion. To prove Theorem 2, we first need several lemmata. Lemma 1.If all agent beliefs (i.e., their preferences over others) are drawn from shared distribution 𝐷∈Δ(N N) (i.e., ∀𝑗∈ N : 𝜎 𝑗 ∼𝐷 ), then there exists a shared prior ∀𝑖, ...
-
[45]
We can see that condition2since elements in 𝑇 have a positive probability for any element inN N (yet only 𝑘 elements are selected from N), each element 𝑖∈ N has a positive probability of not being selected and of being selected, i.e.,0 <𝑝 𝑗,𝑡 < 1, satisfying condition
-
[46]
Lemmas 1 and 2 show that our use of the RBTS algorithm, maintains its Bayes-Nash incentive compatible property
Finally, condition3is satisfied as it is explicitly assumed by the lemma.□ We can now finish proving Theorem 2: Proof of Theorem 2. Lemmas 1 and 2 show that our use of the RBTS algorithm, maintains its Bayes-Nash incentive compatible property. So what is left is to show that our combination of the RBTS with the regular mechanism (Algorithm 2) does so as w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.