Unified 3D Scene Understanding Through Physical World Modeling
Pith reviewed 2026-06-30 14:15 UTC · model grok-4.3
The pith
A single probabilistic graphical model unifies 3D tasks by treating them as different inference pathways through shared multimodal nodes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
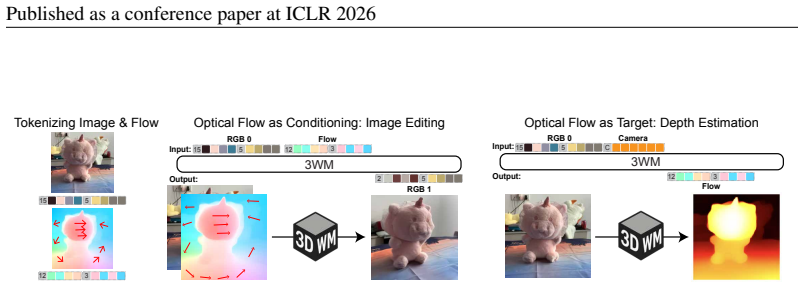
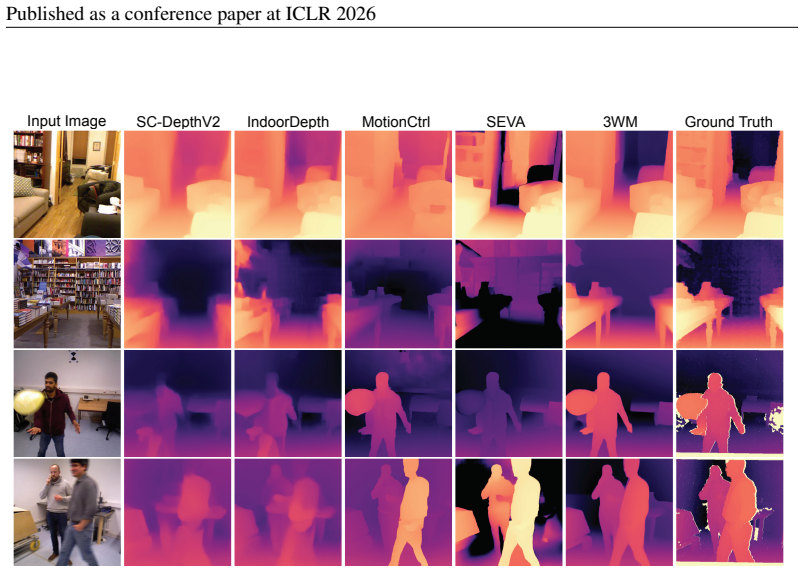
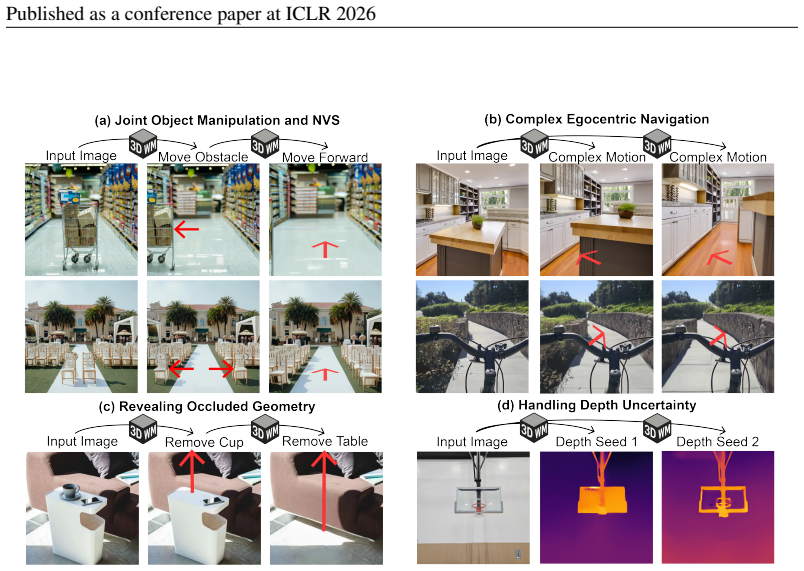
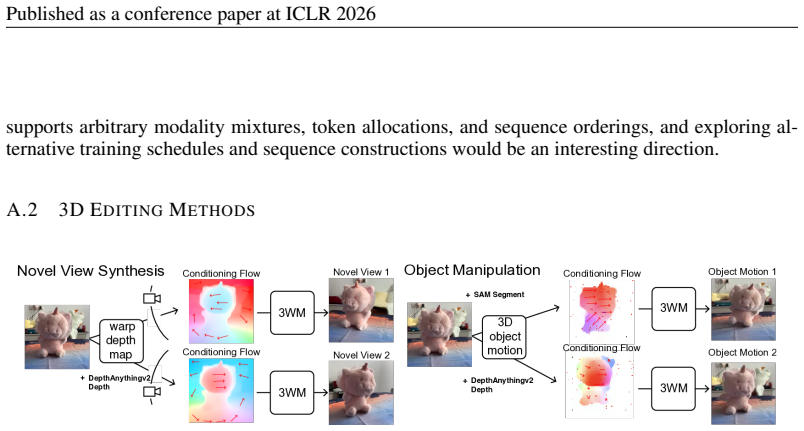
The central claim is that a physical world model formulated as a probabilistic graphical model with nodes for multimodal scene elements such as RGB, optical flow, and camera pose allows diverse tasks to emerge from different inference pathways: novel view synthesis from RGB and dense flow prompts, object manipulation from RGB and sparse flow prompts, and depth estimation from RGB and camera conditioning, all performed zero-shot without task-specific training, while outperforming specialized baselines through precise controllability, strong geometric consistency, and robustness in real-world scenarios.
What carries the argument
Probabilistic graphical model whose nodes represent multimodal scene elements (RGB, optical flow, camera pose); it carries the argument by letting tasks appear as alternate inference pathways through the same graph.
If this is right
- Diverse tasks are handled by selecting inference pathways rather than by separate training objectives or finetuning.
- State-of-the-art performance is reached on novel view synthesis and 3D object manipulation.
- Composable inference pathways support complex geometric reasoning such as moving objects aside while navigating a 3D environment.
- Precise controllability, strong geometric consistency, and robustness appear in real-world scenarios without task-specific adaptation.
Where Pith is reading between the lines
- The same node structure could incorporate additional elements such as semantic labels to activate further tasks without architectural change.
- Composable pathways might support robotic planning by chaining manipulations and viewpoint changes inside the model.
- If the graph captures physical relations reliably, the model could extend to forward prediction of scene dynamics.
- Maintaining one model instead of many could lower the cost of deploying systems that need several 3D capabilities at once.
Load-bearing premise
Diverse 3D tasks can be reduced to different inference pathways through a single probabilistic graphical model whose nodes are multimodal scene elements, enabling zero-shot performance without task-specific training or finetuning.
What would settle it
A real-world scene on which the model produces inconsistent geometry or fails to execute a composable task such as object manipulation combined with novel view synthesis when given only the shared prompts, while separate specialized models succeed on the same inputs.
Figures




read the original abstract
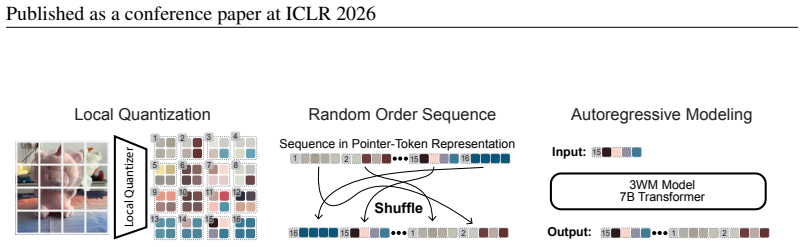
Understanding 3D scenes requires flexible combinations of visual reasoning tasks, including depth estimation, novel view synthesis, and object manipulation, all of which are essential for perception and interaction. Existing approaches have typically addressed these tasks in isolation, preventing them from sharing a common representation or transferring knowledge across tasks. A conceptually simpler but practically non-trivial alternative is to unify these diverse tasks into a single model, reducing different tasks from separate training objectives to merely different prompts and allowing for joint training across all datasets. In this work, we present a physical world model for unified 3D understanding and interaction (3WM), formulated as a probabilistic graphical model in which nodes represent multimodal scene elements such as RGB, optical flow, and camera pose. Diverse tasks emerge from different inference pathways through the graph: novel view synthesis from RGB and dense flow prompts, object manipulation from RGB and sparse flow prompts, and depth estimation from RGB and camera conditioning, all zero-shot without task-specific training. 3WM outperforms specialized baselines without the need for finetuning by offering precise controllability, strong geometric consistency, and robustness in real-world scenarios, achieving state-of-the-art performance on NVS and 3D object manipulation. Beyond predefined tasks, the model supports composable inference pathways, such as moving objects aside while navigating a 3D environment, enabling complex geometric reasoning. This demonstrates that a unified model can serve as a practical alternative to fragmented task-specific systems, taking a step towards a general-purpose visual world model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents 3WM, a probabilistic graphical model for unified 3D scene understanding in which nodes represent multimodal scene elements (RGB, optical flow, camera pose). Diverse tasks including novel view synthesis (from RGB and dense flow prompts), object manipulation (from RGB and sparse flow prompts), and depth estimation (from RGB and camera conditioning) are reduced to different inference pathways through the graph. The work claims these tasks can be performed zero-shot without task-specific training or finetuning, that the model outperforms specialized baselines on NVS and 3D object manipulation, and that it supports composable inference pathways for complex geometric reasoning.
Significance. If the empirical claims hold, the result would be significant because it offers a single model that shares representations across tasks, replaces fragmented task-specific systems, and enables flexible prompt-based control with geometric consistency. The reduction of multiple 3D tasks to inference pathways in one PGM could advance general-purpose visual world models.
major comments (1)
- Abstract: The central claims of state-of-the-art performance on NVS and 3D object manipulation, zero-shot capability without task-specific training, and outperformance of specialized baselines are asserted without any training procedure, loss functions, dataset details, model architecture, or quantitative comparisons. This absence is load-bearing because the soundness of the unification claim cannot be evaluated from the manuscript as presented.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for supporting details to substantiate the claims. We address the major comment below.
read point-by-point responses
-
Referee: [—] Abstract: The central claims of state-of-the-art performance on NVS and 3D object manipulation, zero-shot capability without task-specific training, and outperformance of specialized baselines are asserted without any training procedure, loss functions, dataset details, model architecture, or quantitative comparisons. This absence is load-bearing because the soundness of the unification claim cannot be evaluated from the manuscript as presented.
Authors: We agree that the manuscript as presented (the abstract) asserts these performance and zero-shot claims without providing any details on training procedure, loss functions, dataset details, model architecture, or quantitative comparisons. This prevents evaluation of the unification claim. We will revise the manuscript to add a methods section covering the probabilistic graphical model architecture, training procedure and losses, datasets, and include quantitative results with baselines to support the claims. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper formulates 3WM as a probabilistic graphical model whose nodes are multimodal scene elements and whose tasks arise as distinct inference pathways. The abstract and provided description present this as a modeling choice that unifies tasks via prompts rather than separate objectives, with performance claims evaluated against external baselines on NVS and manipulation. No equation or claim reduces a prediction to a fitted parameter by construction, no self-citation is invoked as a load-bearing uniqueness theorem, and no ansatz is smuggled via prior work. The central claim therefore rests on the model's architecture and empirical results rather than definitional equivalence to its inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Perceptual 3D Simulation With Physical World Modeling
P3Sim integrates a probabilistic physical world model with geometric conditioning and persistent memory to simulate 3D scenes under partial observations and incomplete transforms.
Reference graph
Works this paper leans on
-
[1]
Lumiere: A space-time diffusion model for video generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, et al. Lumiere: A space-time diffusion model for video generation. InSIGGRAPH Asia 2024 Conference Papers, pp. 1–11,
2024
-
[2]
Unifying (machine) vision via counterfactual world modeling
Daniel M Bear, Kevin Feigelis, Honglin Chen, Wanhee Lee, Rahul Venkatesh, Klemen Kotar, Alex Durango, and Daniel LK Yamins. Unifying (machine) vision via counterfactual world modeling. arXiv preprint arXiv:2306.01828,
-
[3]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Deeper into self-supervised monocular indoor depth estimation.arXiv preprint arXiv:2312.01283,
Chao Fan, Zhenyu Yin, Yue Li, and Feiqing Zhang. Deeper into self-supervised monocular indoor depth estimation.arXiv preprint arXiv:2312.01283,
-
[5]
I2vcontrol: Disentangled and unified video motion synthesis control.arXiv preprint arXiv:2411.17765,
Wanquan Feng, Tianhao Qi, Jiawei Liu, Mingzhen Sun, Pengqi Tu, Tianxiang Ma, Fei Dai, Songtao Zhao, Siyu Zhou, and Qian He. I2vcontrol: Disentangled and unified video motion synthesis control.arXiv preprint arXiv:2411.17765,
-
[6]
Rao Fu, Jingyu Liu, Xilun Chen, Yixin Nie, and Wenhan Xiong. Scene-llm: Extending language model for 3d visual understanding and reasoning.arXiv preprint arXiv:2403.11401,
-
[7]
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez-Guevara, Carl Doersch, Yusuf Aytar, Michael Rubinstein, et al. Motion prompting: Con- trolling video generation with motion trajectories.arXiv preprint arXiv:2412.02700,
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
11 Published as a conference paper at ICLR 2026 Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Co...
2026
-
[10]
Wonjoon Jin, Qi Dai, Chong Luo, Seung-Hwan Baek, and Sunghyun Cho. Flovd: Optical flow meets video diffusion model for enhanced camera-controlled video synthesis.arXiv preprint arXiv:2502.08244,
-
[11]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijaya- narasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Mathis Koroglu, Hugo Caselles-Dupr ´e, Guillaume Jeanneret Sanmiguel, and Matthieu Cord. On- lyflow: Optical flow based motion conditioning for video diffusion models.arXiv preprint arXiv:2411.10501,
-
[13]
Refu- sion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals
12 Published as a conference paper at ICLR 2026 Emanuele Palazzolo, Jens Behley, Philipp Lottes, Philippe Giguere, and Cyrill Stachniss. Refu- sion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 7855–7862. IEEE,
2026
-
[14]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Yujun Shi, Jun Hao Liew, Hanshu Yan, Vincent YF Tan, and Jiashi Feng. Lightningdrag: Lightning fast and accurate drag-based image editing emerging from videos.arXiv preprint arXiv:2405.13722,
-
[16]
Indoor segmentation and sup- port inference from rgbd images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and sup- port inference from rgbd images. InComputer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7-13, 2012, Proceedings, Part V 12, pp. 746–760. Springer,
2012
-
[17]
ObjCtrl-2.5D: Training-free object con- trol with camera poses
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Ge- ometric 3d vision made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20697–20709, 2024a. 13 Published as a conference paper at ICLR 2026 Zhouxia Wang, Yushi Lan, Shangchen Zhou, and Chen Change Loy. Objctrl-2.5 d: Tr...
-
[18]
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory
Shengming Yin, Chenfei Wu, Jian Liang, Jie Shi, Houqiang Li, Gong Ming, and Nan Duan. Drag- nuwa: Fine-grained control in video generation by integrating text, image, and trajectory.arXiv preprint arXiv:2308.08089,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien- Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
World-consistent video diffusion with explicit 3d modeling.arXiv preprint arXiv:2412.01821,
Qihang Zhang, Shuangfei Zhai, Miguel Angel Bautista, Kevin Miao, Alexander Toshev, Joshua Susskind, and Jiatao Gu. World-consistent video diffusion with explicit 3d modeling.arXiv preprint arXiv:2412.01821,
-
[21]
Yuchen Zhang, Nikhil Keetha, Chenwei Lyu, Bhuvan Jhamb, Yutian Chen, Yuheng Qiu, Jay Karhade, Shreyas Jha, Yaoyu Hu, Deva Ramanan, et al. Ufm: A simple path towards unified dense correspondence with flow.arXiv preprint arXiv:2506.09278,
-
[22]
14 Published as a conference paper at ICLR 2026 Jensen Jinghao Zhou, Hang Gao, Vikram V oleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, and Varun Jampani. Stable virtual camera: Generative view synthesis with diffusion models.arXiv preprint arXiv:2503.14489,
-
[23]
Stereo Magnification: Learning View Synthesis using Multiplane Images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
The latter include the train splits of ScanNet++ Yeshwanth et al
15 Published as a conference paper at ICLR 2026 A APPENDIX A.1 DATASETS ANDTRAININGDETAILS Training Datasets.3WM was pre-trained on a combination of a large-scale internet video collec- tion, termedBVD(Big Video Dataset), and several 3D vision benchmarks. The latter include the train splits of ScanNet++ Yeshwanth et al. (2023), CO3D Reizenstein et al. (20...
2026
-
[25]
As observed in MAE He et al
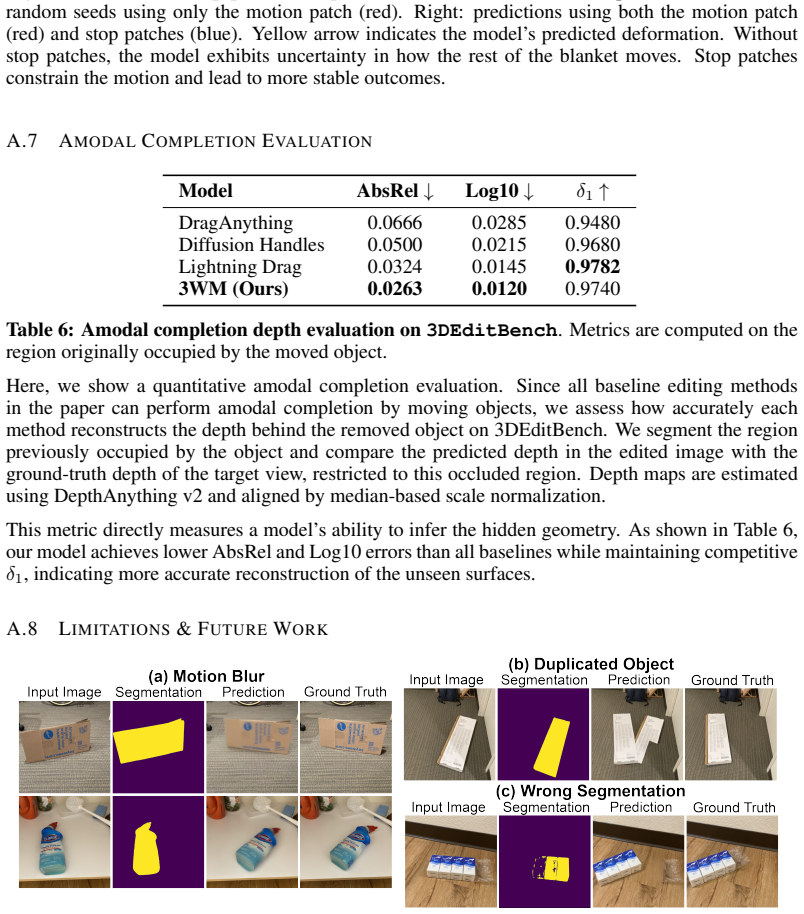
Our approach with local random se- quence shows clear benefits over the raster order approach. As observed in MAE He et al. (2022), VideoMAE Tong et al. (2022), and CWM Bear et al. (2023), random masking encourages stronger representation learning while allowing us to represent each frame with fewer tokens. In contrast, raster order models must encode all...
2022
-
[26]
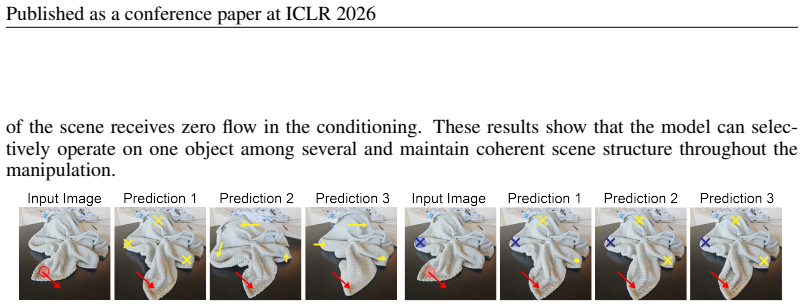
For stacked or multi-object scenes, we include additional examples in Figure 9 where the model manipulates a single object while preserving the geometry and appearance of the others. In these cases, we segment the target object and apply full flow conditioning to that object, while the rest 19 Published as a conference paper at ICLR 2026 of the scene rece...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.