Breaking Changes in Software Ecosystems: A Systematic Literature Review
Pith reviewed 2026-06-30 13:43 UTC · model grok-4.3
The pith
A systematic review of 97 studies synthesizes a four-dimensional taxonomy of breaking changes and catalogs their reasons, detection limits, and handling strategies across five software ecosystems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
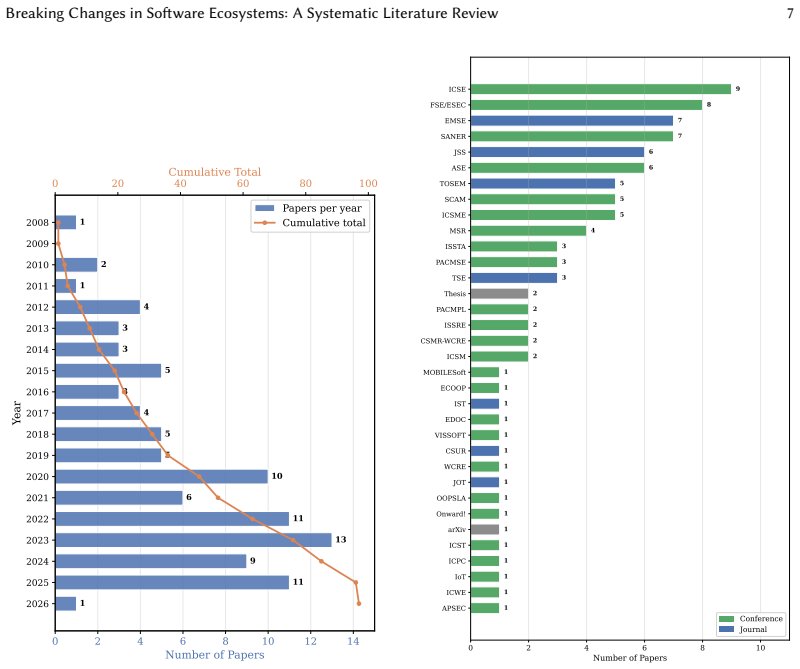
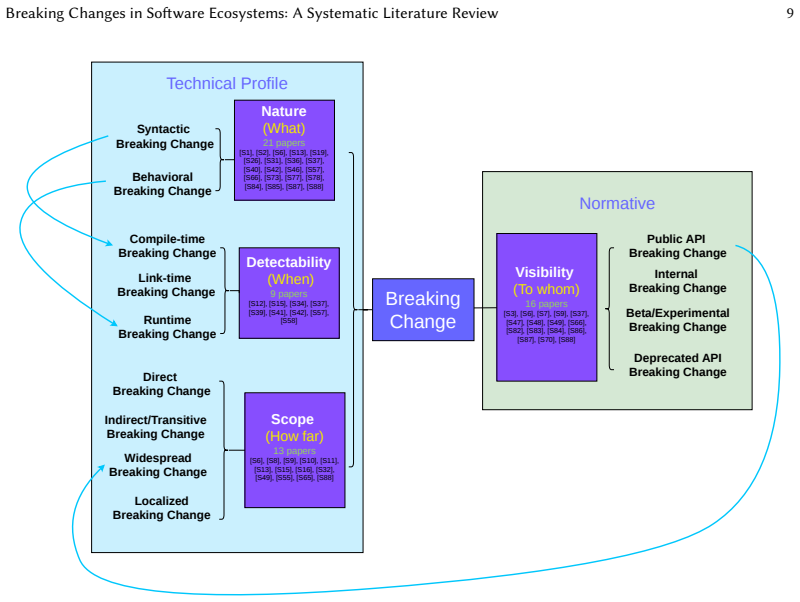
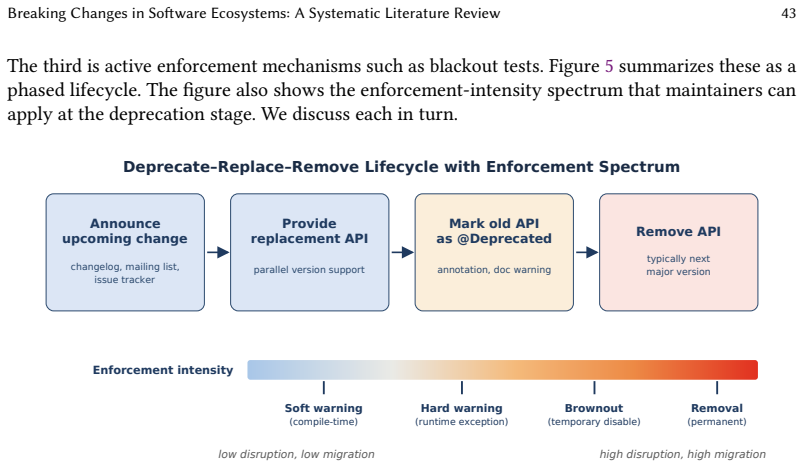
The synthesis of 97 primary studies across the five ecosystems produces a four-dimensional taxonomy along Nature, Detectability, Scope, and Visibility. It identifies five reason categories and five impact dimensions in which maintenance and design improvements account for a larger share of breaking changes than new feature work. It also catalogs 43 detection approaches that reach high accuracy on syntactic breaks but show limited coverage on behavioral ones, and 66 strategies for communicating, preventing, and recovering from breaking changes organized by the actor's role. The review further identifies three open challenges and three research opportunities.
What carries the argument
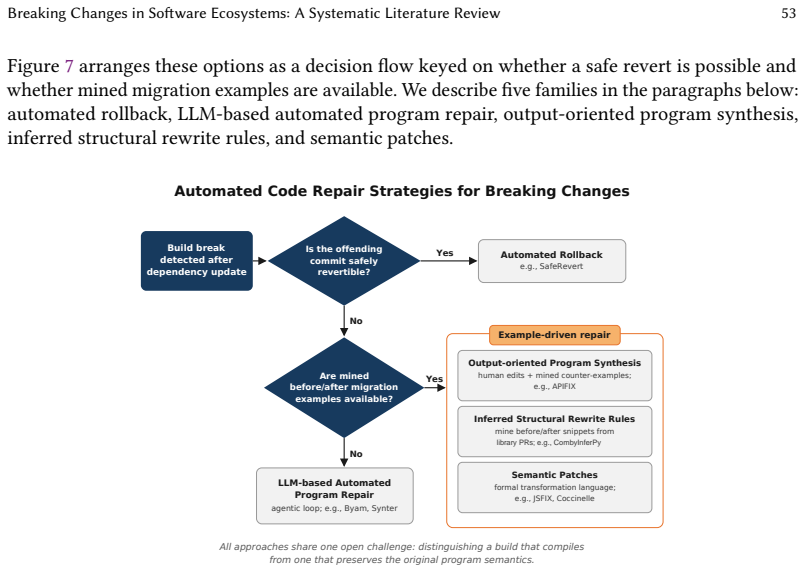
The four-dimensional taxonomy of breaking changes along Nature, Detectability, Scope, and Visibility, which structures the results of the literature synthesis.
If this is right
- Maintenance and design improvements cause a larger share of breaking changes than new feature development.
- Detection approaches achieve high accuracy for syntactic breaks but have limited coverage for behavioral ones.
- Strategies for handling breaking changes can be grouped by the distinct roles of library maintainers, consumers, and other actors.
- Semantic versioning fails to function as an effective trust mechanism for downstream users.
- Transitive dependency propagation occurs under conditions of information asymmetry between actors.
Where Pith is reading between the lines
- Ecosystem-level tools that analyze full dependency graphs could reduce the impact of transitive breaks by surfacing risks earlier.
- Domain-specific tooling tailored to machine learning and data science libraries might address gaps where general approaches fall short.
- Large language models could be tested for inferring behavioral contracts from code and tests to improve detection coverage.
Load-bearing premise
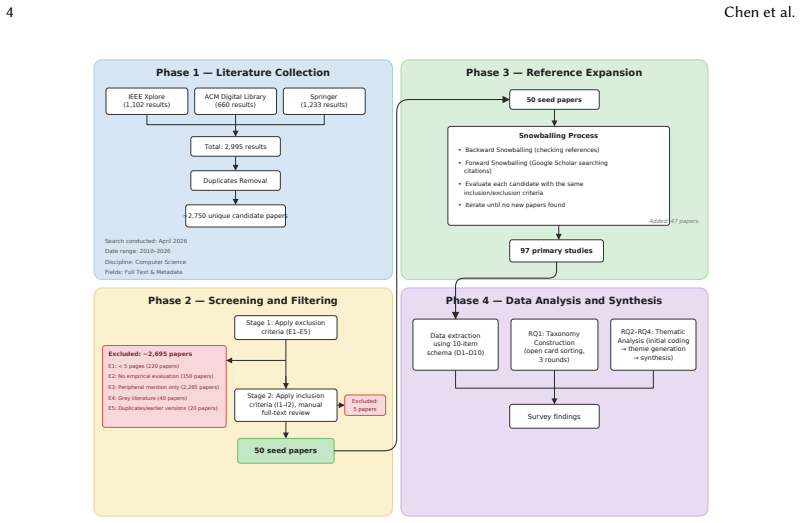
The 97 primary studies identified through the systematic search and inclusion criteria comprehensively and representatively capture the relevant literature on breaking changes across the five ecosystems without significant omission or bias.
What would settle it
A search that uncovers a large body of additional studies on behavioral break detection methods achieving high accuracy at scale, or that demonstrates semantic versioning reliably prevents downstream failures in practice, would undermine the synthesis claims on detection limits and trust mechanisms.
Figures

read the original abstract
Modern software systems rely on dependency networks of reusable libraries, where breaking changes propagate and cause downstream consumers to fail. Despite growing research across ecosystems, no comprehensive synthesis exists. We conduct a systematic literature review of 97 primary studies, answering four research questions across five ecosystems: Maven/Java, npm/JavaScript, Python, Web APIs, and Linux distributions. The synthesis yields four results. First, a four-dimensional taxonomy along Nature, Detectability, Scope, and Visibility. Second, five reason categories and five impact dimensions, where maintenance and design improvements account for a larger share of breaking changes than new feature work. Third, 43 detection approaches that reach high accuracy on syntactic breaks but limited coverage on behavioral ones. Fourth, 66 strategies for communicating, preventing, and recovering from breaking changes, organized by the actor's role. Based on these findings, we identify three open challenges and three research opportunities. The challenges are behavioral break detection at scale, the failure of semantic versioning as a trust mechanism, and transitive dependency propagation under information asymmetry. The opportunities are LLM-augmented behavioral contract inference, ecosystem-level dependency graph intelligence, and domain-specific tooling for ML and data science.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic literature review synthesizing 97 primary studies on breaking changes across five ecosystems (Maven/Java, npm/JavaScript, Python, Web APIs, Linux distributions). It answers four RQs by deriving a four-dimensional taxonomy (Nature, Detectability, Scope, Visibility), five reason categories and five impact dimensions (maintenance/design improvements predominate over new features), 43 detection approaches (high syntactic accuracy, limited behavioral coverage), and 66 strategies organized by actor role, then identifies three challenges (behavioral detection at scale, semantic versioning failure, transitive propagation under asymmetry) and three opportunities (LLM contract inference, ecosystem graph intelligence, domain-specific ML tooling).
Significance. If the sample is representative, the work supplies a needed cross-ecosystem synthesis that consolidates fragmented literature into actionable taxonomies and role-based strategies. The explicit contrast between syntactic and behavioral detection gaps, plus the actor-organized strategies, offers immediate value for both researchers and practitioners. The three opportunities are concrete and falsifiable, strengthening the paper's forward-looking contribution.
major comments (1)
- [Methodology] Methodology section: the claim that the 97 studies form a representative cross-section of the five ecosystems rests on the search strategy, database selection, date bounds, and PRISMA flow diagram. These details are required to evaluate selection bias (e.g., under-sampling of behavioral breaks in Python data-science libraries or transitive issues in Linux). Without explicit reporting of inter-rater reliability, quality assessment scores, and exclusion counts per ecosystem, the four synthesized results cannot be assessed for robustness.
minor comments (2)
- [Results] Abstract and §4: the five reason categories and five impact dimensions are introduced without a table or figure summarizing their distribution across the 97 studies; adding such a breakdown would improve traceability of the claim that maintenance/design dominate new-feature work.
- [Results] The 43 detection approaches and 66 strategies are aggregated but lack a supplementary table mapping each approach/strategy to its primary-study citation and ecosystem; this would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our systematic literature review. We address the single major comment below and will revise the manuscript accordingly to strengthen the methodology reporting.
read point-by-point responses
-
Referee: [Methodology] Methodology section: the claim that the 97 studies form a representative cross-section of the five ecosystems rests on the search strategy, database selection, date bounds, and PRISMA flow diagram. These details are required to evaluate selection bias (e.g., under-sampling of behavioral breaks in Python data-science libraries or transitive issues in Linux). Without explicit reporting of inter-rater reliability, quality assessment scores, and exclusion counts per ecosystem, the four synthesized results cannot be assessed for robustness.
Authors: We agree that the current methodology section requires expanded reporting to allow readers to fully assess selection bias and the robustness of the synthesized taxonomies, reason/impact categories, detection approaches, and mitigation strategies. In the revised manuscript we will: (1) provide the complete search strings, list of databases, and explicit date bounds; (2) include the full PRISMA flow diagram with per-ecosystem exclusion counts; (3) report inter-rater reliability (e.g., Cohen’s kappa) for screening and extraction; and (4) summarize quality assessment scores. These additions will directly address concerns about under-sampling of behavioral breaks in Python data-science libraries or transitive issues in Linux distributions and will enable evaluation of whether the 97 studies constitute a representative cross-section. revision: yes
Circularity Check
No circularity: descriptive synthesis of external primary studies
full rationale
The paper performs a systematic literature review that aggregates and categorizes results reported in 97 independently published primary studies. No equations, fitted parameters, predictions, or derivations appear in the work. The four main results (taxonomy, reason/impact categories, 43 detectors, 66 strategies) are presented as direct summaries of content extracted from the cited external papers rather than quantities computed from the review's own inputs. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify the synthesis itself. The representativeness concern raised in the skeptic note pertains to selection bias, not to any reduction of claims to the paper's own definitions or fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The literature search and selection process captured a representative set of studies on breaking changes.
Reference graph
Works this paper leans on
-
[1]
Rabe Abdalkareem, Olivier Nourry, Sultan Wehaibi, Suhaib Mujahid, and Emad Shihab. 2017. Why Do Developers Use Trivial Packages? An Empirical Case Study on npm. InProceedings of the 11th Joint Meeting on Foundations of Software Engineering (ESEC/FSE). ACM, 385–395. doi:10.1145/3106237.3106267
-
[2]
Gleison Brito, Andre Hora, Marco Tulio Valente, and Romain Robbes. 2018. On the Use of Replacement Messages in API Deprecation: An Empirical Study.Journal of Systems and Software137 (2018), 306–321. doi:10.1016/j.jss.2017.12.007
-
[3]
Eleni Constantinou and Tom Mens. 2017. An Empirical Comparison of Developer Retention in the RubyGems and npm Software Ecosystems.Innovations in Systems and Software Engineering13, 2–3 (2017), 101–115. doi:10.1007/s11334- 017-0303-4
-
[4]
Russ Cox. 2019. Surviving Software Dependencies.Commun. ACM62, 9 (2019), 36–43. doi:10.1145/3347446
-
[5]
Daniela S Cruzes and Tore Dyba. 2011. Recommended steps for thematic synthesis in software engineering. In2011 International Symposium on Empirical Software Engineering and Measurement. IEEE, 275–284. doi:10.1109/ESEM.2011.36
-
[6]
Alexandre Decan, Tom Mens, and Maelick Claes. 2017. An Empirical Comparison of Dependency Issues in OSS Packaging Ecosystems. InProceedings of the 24th IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 2–12. doi:10.1109/SANER.2017.7884604
-
[7]
Alexandre Decan, Tom Mens, and Eleni Constantinou. 2018. On the Evolution of Technical Lag in the npm Package Dependency Network. InProceedings of the 34th IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 404–414. doi:10.1109/ICSME.2018.00050
-
[8]
Alexandre Decan, Tom Mens, and Eleni Constantinou. 2018. On the Impact of Security Vulnerabilities in the npm Package Dependency Network. InProceedings of the 15th International Conference on Mining Software Repositories (MSR). ACM, 181–191. doi:10.1145/3196398.3196401
-
[10]
Jim des Rivières. 2007. Evolving Java-based APIs. https://wiki.eclipse.org/Evolving_Java-based_APIs. Eclipse Foundation
2007
-
[11]
Danny Dig and Ralph Johnson. 2006. How Do APIs Evolve? A Story of Refactoring.Journal of Software Maintenance and Evolution: Research and Practice18, 2 (2006), 83–107. doi:10.1002/smr.328
-
[12]
Elizabeth Dinella, Gabriel Ryan, Todd Mytkowicz, and Shuvendu K. Lahiri. 2022. TOGA: A Neural Method for Test Oracle Generation. InProceedings of the 44th International Conference on Software Engineering (ICSE). ACM, 2130–2141. doi:10.1145/3510003.3510141
-
[13]
Madeline Endres, Sarah Fakhoury, Saikat Chakraborty, and Shuvendu K. Lahiri. 2024. Can Large Language Models Transform Natural Language Intent into Formal Method Postconditions?Proceedings of the ACM on Software Engineering 1, FSE, Article 84 (2024). doi:10.1145/3660791
-
[14]
Lars Heinemann, Florian Deissenboeck, Mario Gleirscher, Benjamin Hummel, and Maximilian Irlbeck. 2011. On the Extent and Nature of Software Reuse in Open Source Java Projects. InProceedings of the 12th International Conference on Software Reuse (ICSR). Springer, 207–222. doi:10.1007/978-3-642-21347-2_16
-
[15]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InThe Twelfth International Conference on Learning Representations (ICLR)
2024
-
[16]
Miryung Kim, Dongxiang Cai, and Sunghun Kim. 2011. An Empirical Investigation into the Role of API-Level Refactorings during Software Evolution. InProceedings of the 33rd International Conference on Software Engineering (ICSE). ACM, 151–160. doi:10.1145/1985793.1985815
-
[17]
2007.Guidelines for Performing Systematic Literature Reviews in Software Engineering
Barbara Kitchenham and Stuart Charters. 2007.Guidelines for Performing Systematic Literature Reviews in Software Engineering. EBSE Technical Report EBSE-2007-01. Keele University and University of Durham
2007
-
[18]
German, Ali Ouni, Takashi Ishio, and Katsuro Inoue
Raula Gaikovina Kula, Daniel M. German, Ali Ouni, Takashi Ishio, and Katsuro Inoue. 2018. Do Developers Update Their Library Dependencies? An Empirical Study on the Impact of Security Advisories on Library Migration.Empirical Software Engineering23, 1 (2018), 384–417. doi:10.1007/s10664-017-9521-5
-
[19]
Piergiorgio Ladisa, Henrik Plate, Matias Martinez, and Olivier Barais. 2023. SoK: Taxonomy of Attacks on Open-Source Software Supply Chains. In2023 IEEE Symposium on Security and Privacy (SP). IEEE, 1509–1526. doi:10.1109/SP46215. 2023.10179304
-
[20]
Maxime Lamothe, Yann-Gaël Guéhéneuc, and Weiyi Shang. 2021. A Systematic Review of API Evolution Literature. Comput. Surveys54, 8, Article 171 (2021), 36 pages. doi:10.1145/3470133
-
[21]
M. M. Lehman. 1980. Programs, Life Cycles, and Laws of Software Evolution.Proc. IEEE68, 9 (1980), 1060–1076. doi:10.1109/PROC.1980.11805
-
[22]
Tom Mens and Serge Demeyer (Eds.). 2008.Software Evolution. Springer. doi:10.1007/978-3-540-76440-3
-
[23]
Samim Mirhosseini and Chris Parnin. 2017. Can Automated Pull Requests Encourage Software Developers to Upgrade Out-of-Date Dependencies?. InProceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 84–94. doi:10.1109/ASE.2017.8115621
-
[24]
Audris Mockus. 2007. Large-Scale Code Reuse in Open Source Software. InFirst International Workshop on Emerging Trends in FLOSS Research and Development (FLOSS’07: ICSE Workshops 2007). IEEE, 7. doi:10.1109/FLOSS.2007.10
-
[25]
Marc Ohm, Henrik Plate, Arnold Sykosch, and Michael Meier. 2020. Backstabber’s Knife Collection: A Review of Open Source Software Supply Chain Attacks. InProceedings of the 17th International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment (DIMV A). Springer, 23–43. doi:10.1007/978-3-030-52683-2_2
-
[26]
OpenAI. 2024. Introducing SWE-bench Verified. https://openai.com/index/introducing-swe-bench-verified/. Technical report; 500-instance human-validated subset of SWE-bench, released in collaboration with the SWE-bench authors
2024
-
[27]
Ivan Pashchenko, Henrik Plate, Serena Elisa Ponta, Antonino Sabetta, and Fabio Massacci. 2018. Vulnerable Open Source Dependencies: Counting Those That Matter. InProceedings of the 12th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). ACM, 42:1–42:10. doi:10.1145/3239235.3268920
-
[28]
Tom Preston-Werner. 2013. Semantic Versioning 2.0.0. https://semver.org/. Specification
2013
-
[29]
Romain Robbes, Mircea Lungu, and David Röthlisberger. 2012. How Do Developers React to API Deprecation? The Case of a Smalltalk Ecosystem. InProceedings of the 20th ACM SIGSOFT International Symposium on the Foundations of Software Engineering (FSE). ACM, 56:1–56:11. doi:10.1145/2393596.2393662
-
[30]
Robillard, Eric Bodden, David Kawrykow, Mira Mezini, and Tristan Ratchford
Martin P. Robillard, Eric Bodden, David Kawrykow, Mira Mezini, and Tristan Ratchford. 2013. Automated API Property Inference Techniques.IEEE Transactions on Software Engineering39, 5 (2013), 613–637. doi:10.1109/TSE.2012.63
-
[31]
Anand Ashok Sawant, Romain Robbes, and Alberto Bacchelli. 2019. To React, or Not to React: Patterns of Reaction to API Deprecation.Empirical Software Engineering24, 6 (2019), 3824–3870. doi:10.1007/s10664-019-09713-w
-
[32]
César Soto-Valero, Nicolas Harrand, Martin Monperrus, and Benoit Baudry. 2021. A Comprehensive Study of Bloated Dependencies in the Maven Ecosystem.Empirical Software Engineering26, 3, Article 45 (2021). doi:10.1007/s10664- 020-09914-8 ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: May 2026. Breaking Changes in Software Ecosy...
-
[33]
Murugiah Souppaya, Karen Scarfone, and Donna Dodson. 2022.Secure Software Development Framework (SSDF) Version 1.1: Recommendations for Mitigating the Risk of Software Vulnerabilities. Technical Report NIST SP 800-218. National Institute of Standards and Technology. doi:10.6028/NIST.SP.800-218
-
[34]
2009.Card Sorting: Designing Usable Categories
Donna Spencer. 2009.Card Sorting: Designing Usable Categories. Rosenfeld Media, Brooklyn, NY
2009
-
[35]
The White House. 2021. Executive Order 14028: Improving the Nation’s Cybersecurity. https://www.whitehouse.gov/ briefing-room/presidential-actions/2021/05/12/executive-order-on-improving-the-nations-cybersecurity/
2021
-
[36]
2020.Software Engineering at Google: Lessons Learned from Programming Over Time
Titus Winters, Tom Manshreck, and Hyrum Wright (Eds.). 2020.Software Engineering at Google: Lessons Learned from Programming Over Time. O’Reilly Media
2020
-
[37]
Erik Wittern, Philippe Suter, and Shriram Rajagopalan. 2016. A Look at the Dynamics of the JavaScript Package Ecosystem. InProceedings of the 13th International Conference on Mining Software Repositories (MSR). ACM, 351–361. doi:10.1145/2901739.2901743
-
[38]
Claes Wohlin. 2014. Guidelines for Snowballing in Systematic Literature Studies and a Replication in Software Engineering. InProceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering (EASE). ACM, 38:1–38:10. doi:10.1145/2601248.2601268
-
[39]
Markus Zimmermann, Cristian-Alexandru Staicu, Cam Tenny, and Michael Pradel. 2019. Small World with High Risks: A Study of Security Threats in the npm Ecosystem. InProceedings of the 28th USENIX Security Symposium (USENIX Security). USENIX Association, 995–1010. ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: May 2026
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.