DemoEvolve: Overcoming Sparse Feedback in Agentic Harness Evolution with Demonstrations
Pith reviewed 2026-06-30 13:10 UTC · model grok-4.3
The pith
Demonstrations bootstrap harness evolution to overcome sparse feedback in long-horizon agent tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
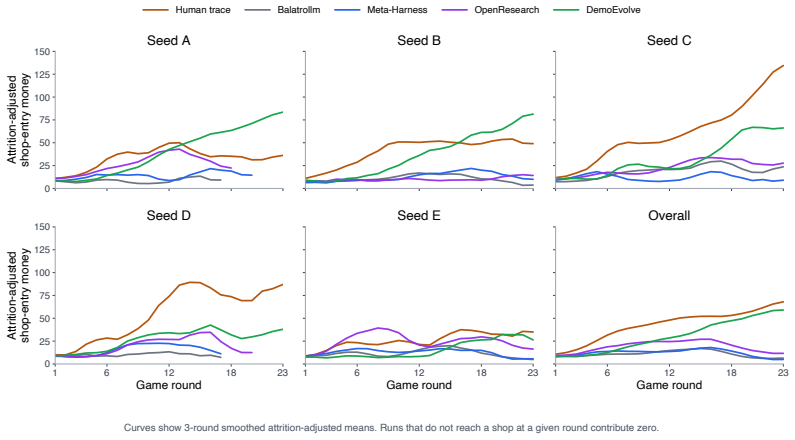
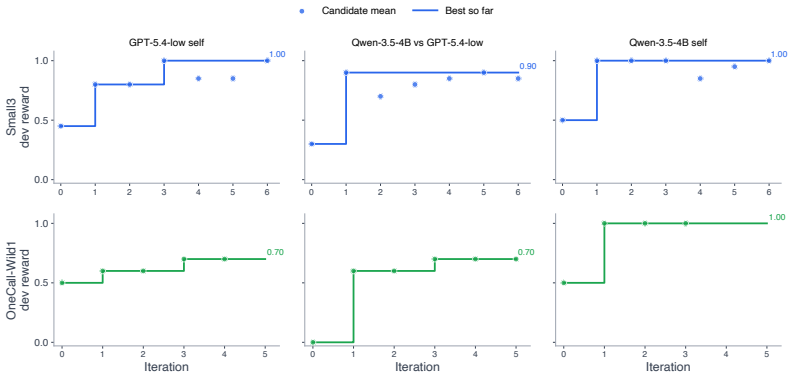
DemoEvolve is a demonstration-bootstrapped approach to harness evolution. When reward-only search is too broad and noisy, competent human trajectories serve as expert reference experience for the coding proposer, guiding harness-level diagnosis and editing. Experiments show that in short-episode settings self-rollout works, but in harder regimes like Balatro, self-rollout is misled by sparse feedback while DemoEvolve produces more effective and auditable harness edits and better performance under the same limited budget.
What carries the argument
Demonstration-bootstrapped harness evolution, using human trajectories to guide the coding proposer for harness diagnosis and editing.
If this is right
- Self-rollout evolution succeeds only when episodes are short and failures attributable.
- Tutorial-like textual knowledge alone fails to yield stable improvement in stochastic regimes.
- DemoEvolve makes harness evolution more diagnosable, localizable, and stable in sparse-feedback settings.
- Under limited budget, it achieves better agent performance in long-horizon stochastic environments.
Where Pith is reading between the lines
- Human demonstrations could serve as a general bootstrap for agent adaptation in other domains with sparse signals.
- Integrating this with model fine-tuning might amplify gains in sample efficiency.
- The approach suggests a path for making AI agents more auditable by relying on explicit harness structures guided by examples.
Load-bearing premise
Competent human trajectories provide sufficiently diagnostic and generalizable reference experience that allows the coding proposer to localize and repair harness mechanisms better than self-generated rollouts can.
What would settle it
A controlled comparison in Balatro where DemoEvolve shows no performance gain over self-rollout evolution under identical limited budgets and the same number of edits.
Figures
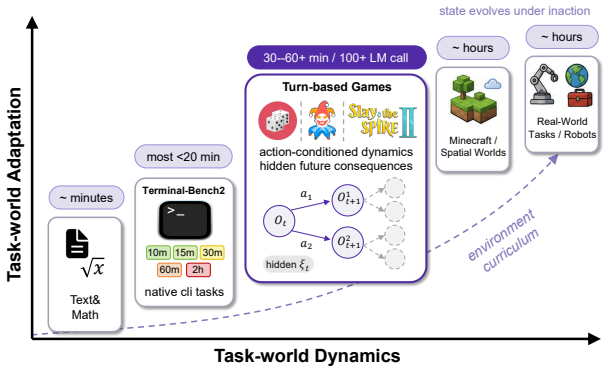
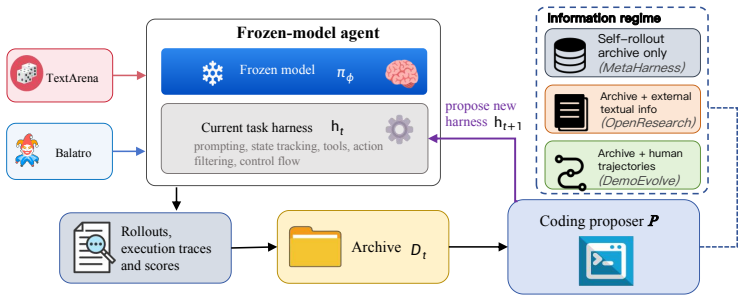
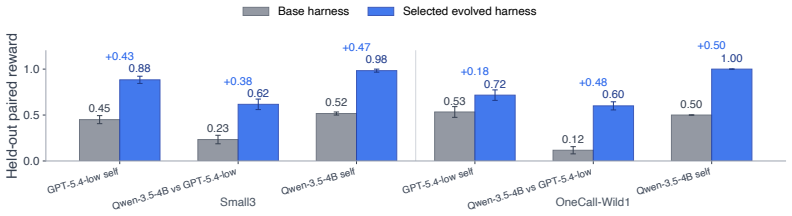

read the original abstract
Agent harness evolution improves frozen language-model agents by modifying the executable structures around them. We study this paradigm as a form of sample-efficient fast adaptation: instead of updating model weights, an agent can acquire task-specific competence by changing its external harness, while leaving the base model's general capabilities intact. Prior work shows that self-generated rollouts can support harness search, suggesting that agents may acquire new task competence through practice. Yet in long-horizon stochastic environments, self-practice becomes fragile: rewards are sparse, outcomes are high-variance, and failures are hard to attribute to concrete harness mechanisms. We introduce DemoEvolve, a demonstration-bootstrapped approach to harness evolution. When reward-only search is too broad and noisy, competent human trajectories serve as expert reference experience for the coding proposer, guiding harness-level diagnosis and editing. Experiments on Liar's Dice show that self-rollout evolution can work when episodes are short and failures are attributable. In contrast, Balatro exposes a harder long-horizon stochastic regime, where self-rollout evolution is misled by sparse feedback and candidate-selection noise, while tutorial-like textual knowledge alone does not yield stable improvement. Under the same limited budget, DemoEvolve produces more effective and auditable harness edits and achieves better performance. Overall, demonstrations make sparse-feedback harness evolution more diagnosable, localizable, and stable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DemoEvolve, a demonstration-bootstrapped method for evolving executable harnesses around frozen language-model agents. It argues that self-generated rollouts become fragile in long-horizon stochastic settings with sparse rewards and high-variance outcomes, while tutorial-style textual knowledge alone yields unstable gains; competent human trajectories are instead used as reference experience to guide the coding proposer in localizing and repairing harness mechanisms. Experiments contrast short-episode Liar's Dice (where self-rollout succeeds) with the harder Balatro regime, claiming that DemoEvolve produces more effective, auditable edits and superior performance under the same limited budget.
Significance. If the empirical results hold after addressing budget accounting, the work would demonstrate a practical route to sample-efficient, weight-preserving adaptation for LM agents in regimes where pure self-practice fails, with the added benefit of more diagnosable and auditable harness changes. The explicit regime contrast between the two environments is a strength that helps isolate when demonstrations are necessary.
major comments (2)
- [Abstract] Abstract: the central claim of superior performance 'under the same limited budget' is load-bearing for the contribution, yet the budget metric is undefined. If the cost of collecting competent human trajectories is excluded while counting only LLM calls or proposal iterations, the comparison to self-rollout evolution is asymmetric and the reported gains cannot be attributed solely to the demonstration mechanism.
- [Experiments] Experiments section (Liar's Dice vs. Balatro comparison): without reported ablations that isolate the contribution of human trajectories from other factors (e.g., proposal prompting style or candidate selection heuristics), it remains unclear whether the performance edge stems from the reference experience itself or from incidental differences in search procedure.
minor comments (2)
- [Abstract] The abstract uses 'auditable harness edits' without defining the auditability criterion or providing examples of what makes an edit more or less auditable than a self-rollout edit.
- Terminology: 'harness evolution' and 'coding proposer' are introduced without a brief formalization or pseudocode sketch, which would help readers map the method to prior harness or tool-use literature.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important points about experimental clarity and fair comparison that we will address in revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of superior performance 'under the same limited budget' is load-bearing for the contribution, yet the budget metric is undefined. If the cost of collecting competent human trajectories is excluded while counting only LLM calls or proposal iterations, the comparison to self-rollout evolution is asymmetric and the reported gains cannot be attributed solely to the demonstration mechanism.
Authors: We agree that the budget accounting must be defined explicitly for the claim to be interpretable. In the current manuscript the 'limited budget' is intended to denote the number of LLM calls and evolution iterations allocated to the proposer and evaluator, with human demonstrations treated as a fixed, one-time reference input rather than part of the per-run search budget. Nevertheless, the manuscript does not state this distinction clearly. We will revise the abstract, introduction, and experimental setup to provide a precise budget definition together with a cost breakdown that separates demonstration collection from LLM-based search steps. This change will allow readers to evaluate the asymmetry directly. revision: yes
-
Referee: [Experiments] Experiments section (Liar's Dice vs. Balatro comparison): without reported ablations that isolate the contribution of human trajectories from other factors (e.g., proposal prompting style or candidate selection heuristics), it remains unclear whether the performance edge stems from the reference experience itself or from incidental differences in search procedure.
Authors: The existing regime contrast (short-episode Liar's Dice where self-rollout succeeds versus long-horizon Balatro where it fails) is designed to isolate the value of demonstrations under sparse feedback. However, we acknowledge that this does not fully disentangle the effect of the human trajectories from possible differences in prompting templates or selection heuristics between the self-rollout and DemoEvolve conditions. We will add targeted ablations in the revised experiments section that hold prompting style and selection procedure fixed while varying only the presence and quality of reference trajectories. These results will be reported alongside the existing comparisons. revision: yes
Circularity Check
No circularity: empirical comparison with independent experimental support
full rationale
The paper advances an empirical method (DemoEvolve) for harness evolution that incorporates human demonstrations to address sparse rewards in long-horizon settings. Its central claims rest on experimental outcomes comparing DemoEvolve against self-rollout and tutorial baselines on Liar's Dice and Balatro, under a stated budget. No equations, fitted parameters, or first-principles derivations appear in the abstract or described structure; the performance advantage is presented as an observed result rather than a quantity forced by construction from the inputs. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing elements. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning, pages 41–48. Association for Computing Machinery, 2009
2009
-
[2]
Balatrobench.https://balatrobench.com/, 2026
Coder. Balatrobench.https://balatrobench.com/, 2026. Accessed May 2, 2026
2026
-
[3]
BalatroLLM: Play Balatro with LLMs
Coder. BalatroLLM: Play Balatro with LLMs. https://github.com/coder/balatrollm,
-
[4]
Accessed May 2, 2026
2026
-
[5]
Gtbench: Uncovering the strategic reasoning limitations of llms via game-theoretic evaluations, 2024
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, and Kaidi Xu. Gtbench: Uncovering the strategic reasoning limitations of llms via game-theoretic evaluations, 2024. URL https://arxiv. org/abs/2402.12348
-
[6]
Stanley, and Jeff Clune
Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O. Stanley, and Jeff Clune. First return, then explore.Nature, 590(7847):580–586, 2021
2021
-
[7]
Reverse curriculum generation for reinforcement learning
Carlos Florensa, David Held, Markus Wulfmeier, Michael Zhang, and Pieter Abbeel. Reverse curriculum generation for reinforcement learning. InConference on Robot Learning, pages 482–495, 2017
2017
-
[8]
Catarena: Evaluating evolutionary capabilities of code agents via iterative tournaments, 2025
Lingyue Fu, Xin Ding, Linyue Pan, Yaoming Zhu, Shao Zhang, Lin Qiu, Weiwen Liu, Weinan Zhang, Xuezhi Cao, Xunliang Cai, Jiaxin Ding, and Yong Yu. Catarena: Evaluating evolutionary capabilities of code agents via iterative tournaments, 2025. URL https://arxiv.org/abs/ 2510.26852
-
[9]
Textarena,
Leon Guertler, Bobby Cheng, Simon Yu, Bo Liu, Leshem Choshen, and Cheston Tan. Textarena,
- [10]
-
[11]
Deep q-learning from demonstrations
Todd Hester, Mel Vecerik, Olivier Pietquin, Marc Lanctot, Tom Schaul, Bilal Piot, Jean-Baptiste Lespiau, Laurent Sartran, and Guillaume Beaudoin. Deep q-learning from demonstrations. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), 2018
2018
-
[12]
Generative adversarial imitation learning
Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning. InAdvances in Neural Information Processing Systems, 2016
2016
-
[13]
Gamearena: Evaluating llm reasoning through live computer games, 2024
Lanxiang Hu, Qiyu Li, Anze Xie, Nan Jiang, Ion Stoica, Haojian Jin, and Hao Zhang. Gamearena: Evaluating llm reasoning through live computer games, 2024. URL https: //arxiv.org/abs/2412.06394
-
[14]
Automated design of agentic systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems. InThe Thirteenth International Conference on Learning Representations, October 2024. URL https: //openreview.net/forum?id=t9U3LW7JVX
2024
-
[15]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. Swe-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, October 2023. URL https://openreview.net/forum?id=VTF8yNQM66
2023
-
[16]
Pawan Kumar, Benjamin Packer, and Daphne Koller
M. Pawan Kumar, Benjamin Packer, and Daphne Koller. Self-paced learning for latent variable models.Advances in Neural Information Processing Systems, 23, 2010
2010
-
[17]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses, March 2026. URL http: //arxiv.org/abs/2603.28052
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Textatari: 100k frames game playing with language agents, 2025
Wenhao Li, Wenwu Li, Chuyun Shen, Junjie Sheng, Zixiao Huang, Di Wu, Yun Hua, Wei Yin, Xiangfeng Wang, Hongyuan Zha, and Bo Jin. Textatari: 100k frames game playing with language agents, 2025. URLhttps://arxiv.org/abs/2506.04098
-
[19]
Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
Jiahang Lin, Shichun Liu, Chengjun Pan, Lizhi Lin, Shihan Dou, Xuanjing Huang, Hang Yan, Zhenhua Han, and Tao Gui. Agentic harness engineering: Observability-driven automatic evo- lution of coding-agent harnesses, April 2026. URLhttp://arxiv.org/abs/2604.25850. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [20]
-
[21]
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
Ziyu Ma, Shidong Yang, Yuxiang Ji, Xucong Wang, Yong Wang, Yiming Hu, Tongwen Huang, and Xiangxiang Chu. Skillclaw: Let skills evolve collectively with agentic evolver, April 2026. URLhttp://arxiv.org/abs/2604.08377
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Self- refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self- refine: Iterative refinement with self-feedback. InThirty-Seventh Conference on Neural Infor- m...
2023
-
[23]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.Nature, 518(7540):529–533, 2015. doi: 10.1038/nature14236
-
[25]
Over- coming exploration in reinforcement learning with demonstrations
Ashvin Nair, Bob McGrew, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Over- coming exploration in reinforcement learning with demonstrations. In2018 IEEE International Conference on Robotics and Automation (ICRA), pages 6292–6299, 2018
2018
-
[26]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Balrog: Benchmarking agentic llm and vlm reasoning on games, 2024
Davide Paglieri, Bartlomiej Cupial, Samuel Coward, Ulyana Piterbarg, Maciej Wolczyk, Akbir Khan, Eduardo Pignatelli, Lukasz Kucinski, Lerrel Pinto, Rob Fergus, Jakob Nicolaus Foerster, Jack Parker-Holder, and Tim Rocktaschel. Balrog: Benchmarking agentic llm and vlm reasoning on games, 2024. URLhttps://arxiv.org/abs/2411.13543
-
[28]
Orak: A Foundational Benchmark for Training and Evaluating LLM Agents on Diverse Video Games
Dongmin Park, Minkyu Kim, Beongjun Choi, Junhyuck Kim, Keon Lee, Jonghyun Lee, Inkyu Park, Byeong-Uk Lee, Jaeyoung Hwang, Jaewoo Ahn, Ameya S. Mahabaleshwarkar, Bilal Kartal, Pritam Biswas, Yoshi Suhara, Kangwook Lee, and Jaewoong Cho. Orak: A foundational benchmark for training and evaluating llm agents on diverse video games, 2025. URLhttps://arxiv.org/...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Learning complex dexterous manipulation with deep reinforcement learning and demonstrations
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. InRobotics: Science and Systems, 2018. 11
2018
-
[30]
A self-improving coding agent,
Maxime Robeyns, Martin Szummer, and Laurence Aitchison. A self-improving coding agent,
- [31]
-
[32]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, pages 627–635, 2011
2011
-
[33]
Openevolve: an open-source evolutionary coding agent.https://github
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent.https://github. com/algorithmicsuperintelligence/openevolve, 2025. URL https://github.com/ algorithmicsuperintelligence/openevolve. GitHub repository
2025
-
[34]
Narasimhan, and Shunyu Yao
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R. Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InThirty-Seventh Conference on Neural Information Processing Systems, November 2023. URL https://openreview. net/forum?id=vAElhFcKW6
2023
-
[35]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, 2 edition, 2018
2018
-
[36]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models, October 2023. URLhttp://arxiv.org/abs/2305.16291
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Wenyi Wang, Piotr Piekos, Nanbo Li, Firas Laakom, Yimeng Chen, Mateusz Ostaszewski, Mingchen Zhuge, and Jurgen Schmidhuber. Huxley-godel machine: Human-level coding agent development by an approximation of the optimal self-improving machine, 2025. URL https://arxiv.org/abs/2510.21614
-
[38]
Live-swe- agent: Can software engineering agents self-evolve on the fly?
Chunqiu Steven Xia, Zhe Wang, Yan Yang, Yuxiang Wei, and Lingming Zhang. Live-swe-agent: Can software engineering agents self-evolve on the fly?, 2025. URL https://arxiv.org/ abs/2511.13646
-
[39]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning, February 2026. URL http://arxiv.org/abs/2602.08234
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Learning to continually learn via meta-learning agentic memory designs
Yiming Xiong, Shengran Hu, and Jeff Clune. Learning to continually learn via meta-learning agentic memory designs. InOpenReview, 2026. URL https://api.semanticscholar. org/CorpusID:285454009
2026
-
[41]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=WE_vluYUL-X
2022
-
[42]
Meta context engineer- ing via agentic skill evolution.arXiv preprint arXiv:2601.21557, 2026
Haoran Ye, Xuning He, Vincent Arak, Haonan Dong, and Guojie Song. Meta context engineer- ing via agentic skill evolution.arXiv preprint arXiv:2601.21557, 2026
-
[43]
MemEvolve: Meta-Evolution of Agent Memory Systems
Guibin Zhang, Haotian Ren, Chong Zhan, Zhenhong Zhou, Junhao Wang, He Zhu, Wangchun- shu Zhou, and Shuicheng Yan. Memevolve: Meta-evolution of agent memory systems.arXiv preprint arXiv:2512.18746, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Darwin godel machine: Open-ended evolution of self-improving agents, 2026
Jenny Zhang, Shengran Hu, Cong Lu, Robert Lange, and Jeff Clune. Darwin godel machine: Open-ended evolution of self-improving agents, 2026. URL https://arxiv.org/abs/2505. 22954
2026
-
[45]
Aflow: Automating agentic workflow generation
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xiong-Hui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. Aflow: Automating agentic workflow generation. InThe Thirteenth International Conference on Learning Representations, October 2024. URL https://openreview.net/ forum?id=z5u...
2024
-
[46]
Agentic context engineering: Evolving contexts for self-improving language models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic context engineering: Evolving contexts for self-improving language models. InThe Fourteenth International Conference on Learning Representations, October 2025. URLh...
2025
-
[47]
Expel: Llm agents are experiential learners, December 2024
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners, December 2024. URL http://arxiv.org/abs/2308. 10144. 13 A TextArena Liar’s Dice Details This appendix gives additional details for the TextArena Liar’s Dice experiments reported in Sec- tion 4.1. These experiments serve as a light...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.