EMA: Effort Metric Attention for Anatomical Effort-Guided Human Motion Diffusion
Pith reviewed 2026-06-30 13:18 UTC · model grok-4.3
The pith
Effort Metric Attention conditions diffusion models on numerical effort signals for region-wise motion intensity control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
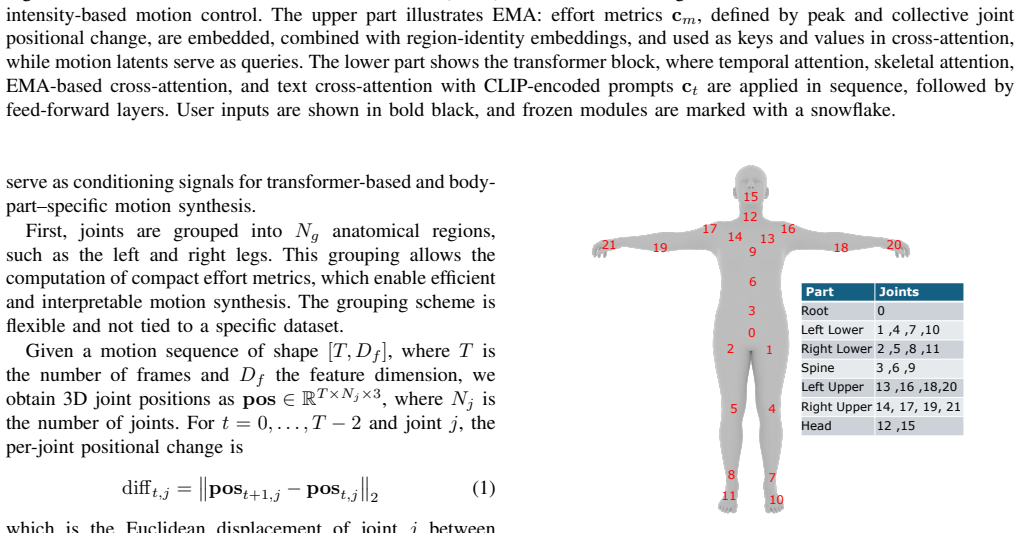
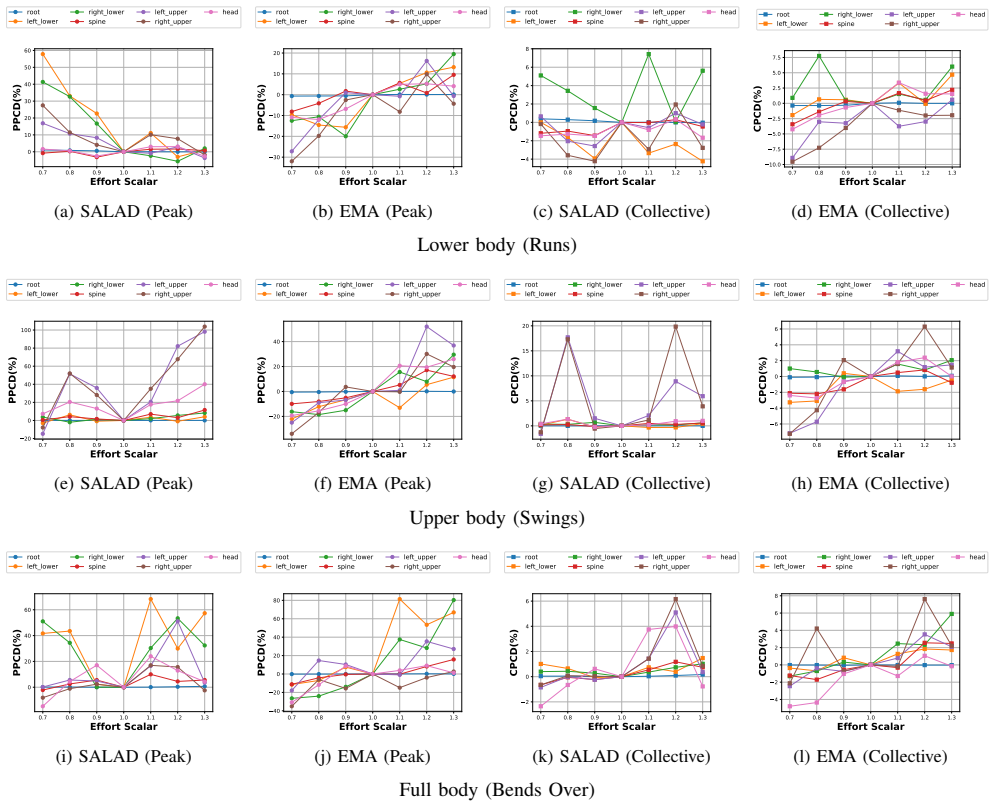
Effort Metric Attention is a cross-attention module that conditions a human motion diffusion model on numerical effort values for the Time and Weight factors of Laban Movement Analysis. These values are obtained from peak joint positional change (pacing) and collective joint positional change (motion amount). The resulting generations exhibit near-monotonic alignment between input effort levels, output motion dynamics, and established LMA descriptors, while permitting independent modulation across body parts.
What carries the argument
Effort Metric Attention (EMA), a cross-attention module that injects numerical effort signals derived from joint positional changes directly into the diffusion denoising process.
If this is right
- Motions can be modulated at the level of individual body regions without post-hoc optimization.
- Generated dynamics align near-monotonically with the supplied numerical effort values.
- New tasks of metric-to-motion consistency and body-part effort modulation become usable benchmarks.
- Control remains compatible with existing text conditioning in diffusion models.
Where Pith is reading between the lines
- The same numerical conditioning pattern could be applied to non-diffusion motion generators.
- Extending the kinematic approximations to the remaining Laban factors would enlarge the controllable space.
- The approach opens a route to effort-specified motion in interactive animation tools.
Load-bearing premise
The two chosen kinematic metrics provide a valid approximation of the Time and Weight effort factors from Laban Movement Analysis.
What would settle it
If raising the numerical effort input does not produce correspondingly higher peak or collective joint velocities in the generated sequences, as measured by the metric-to-motion consistency task, the conditioning mechanism fails.
Figures


read the original abstract
Human motion diffusion models can synthesize action sequences from text, but controlling motion intensity remains challenging. Existing approaches rely on effort-related adverbs, which are ambiguous and fail to capture quantitative aspects such as pacing, often resulting in flat and monotonous dynamics. We propose an intensity-control framework based on Effort Metric Attention (EMA), a cross-attention module that conditions diffusion on numerical effort signals. Inspired by Laban Movement Analysis (LMA), the framework focuses on the Time and Weight effort factors. We approximate these factors using two kinematic metrics: peak joint positional change for pacing and collective joint positional change for motion amount. EMA enables fine-grained, region-wise control without costly post-hoc optimization. We introduce two evaluation tasks, metric-to-motion consistency and body-part-level effort modulation, to assess numerical fidelity and localized control. Experiments and a user study show near-monotonic alignment between specified effort levels, generated motion dynamics, and established LMA descriptors. These results indicate effective and interpretable control of effort dynamics in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Effort Metric Attention (EMA), a cross-attention module that conditions human motion diffusion models on numerical effort signals derived from Laban Movement Analysis (LMA) Time and Weight factors. These factors are approximated via two kinematic metrics—peak joint positional change for pacing and collective joint positional change for motion amount—enabling fine-grained, region-wise control. The central claims are that this yields interpretable intensity control without post-hoc optimization and that experiments plus a user study demonstrate near-monotonic alignment between specified effort levels, generated dynamics, and LMA descriptors.
Significance. If the kinematic-to-LMA mapping holds and the reported alignments are robust, the work would supply a practical, quantitative alternative to adverb-based conditioning in motion diffusion models, with potential utility in animation, robotics, and VR. The introduction of dedicated evaluation tasks (metric-to-motion consistency and body-part-level modulation) is a constructive contribution to the controllability literature.
major comments (2)
- [Abstract / metric definition] Abstract and metric-definition section: the claim that peak joint positional change and collective joint positional change serve as usable proxies for LMA Time (pacing/suddenness) and Weight (force/strength) is load-bearing, yet these quantities are purely kinematic aggregates that omit acceleration profiles, contact forces, and the qualitative timing distinctions that define LMA effort. No validation against expert LMA annotations or dynamic/force data is described to establish the mapping.
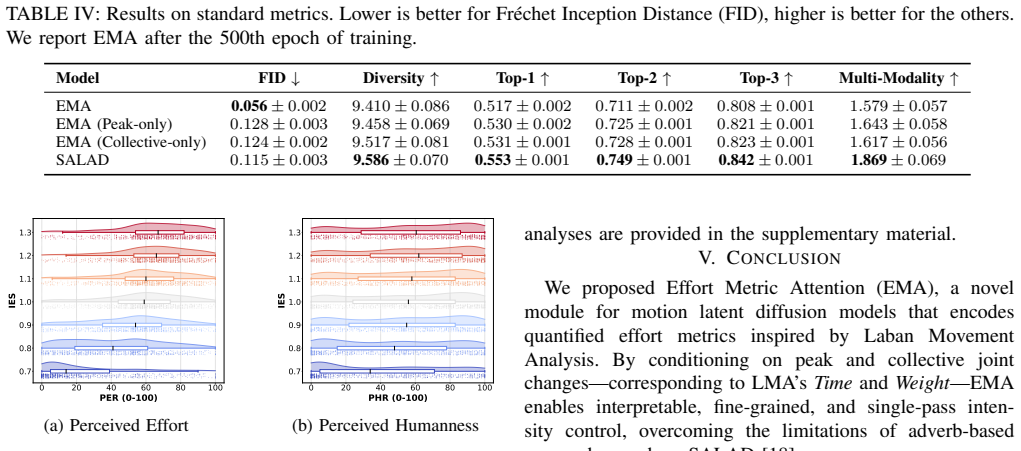
- [Experiments / evaluation tasks] Experiments and evaluation sections: the abstract asserts that experiments and a user study show near-monotonic alignment, but the manuscript provides neither quantitative tables reporting the alignment statistics, nor implementation details for the kinematic metrics, nor the procedure used to compute LMA descriptors on generated motions. This prevents assessment of whether the reported fidelity is independent of post-hoc metric choices.
minor comments (2)
- Clarify the precise diffusion backbone and any additional conditioning mechanisms (e.g., text encoder) used in the EMA integration.
- The effort-signal scaling parameter is listed as the sole free parameter; confirm this is the only tunable hyper-parameter and report its value range in the experimental protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the metric definitions and evaluation details. We address each major comment point by point below, acknowledging where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Abstract / metric definition] Abstract and metric-definition section: the claim that peak joint positional change and collective joint positional change serve as usable proxies for LMA Time (pacing/suddenness) and Weight (force/strength) is load-bearing, yet these quantities are purely kinematic aggregates that omit acceleration profiles, contact forces, and the qualitative timing distinctions that define LMA effort. No validation against expert LMA annotations or dynamic/force data is described to establish the mapping.
Authors: We agree that the metrics are kinematic approximations rather than complete LMA measures and do not incorporate acceleration profiles, contact forces, or expert qualitative distinctions. The paper positions them explicitly as computationally tractable proxies inspired by the Time and Weight factors to enable numerical conditioning. No direct validation against expert LMA annotations or force data was performed, as the contribution centers on practical controllability in diffusion models. We will revise the metric-definition section to state these limitations more explicitly, provide additional rationale for the kinematic choices, and note that the user study evaluates alignment with LMA descriptors rather than claiming equivalence. revision: yes
-
Referee: [Experiments / evaluation tasks] Experiments and evaluation sections: the abstract asserts that experiments and a user study show near-monotonic alignment, but the manuscript provides neither quantitative tables reporting the alignment statistics, nor implementation details for the kinematic metrics, nor the procedure used to compute LMA descriptors on generated motions. This prevents assessment of whether the reported fidelity is independent of post-hoc metric choices.
Authors: We acknowledge that the presentation of quantitative alignment statistics could be more prominent. Implementation details for the kinematic metrics appear in Section 3, and the LMA descriptor procedure is described in the evaluation protocol, but we agree that dedicated tables (e.g., correlation or monotonicity measures across effort levels) and expanded step-by-step procedures would improve transparency and reproducibility. In the revision we will add these tables and details to the experiments section so that fidelity can be assessed independently of any post-hoc choices. revision: yes
Circularity Check
No significant circularity; derivation introduces independent conditioning module and metrics
full rationale
The paper defines two new kinematic metrics as approximations to LMA factors, inserts them into a novel cross-attention module (EMA) atop an existing diffusion backbone, and evaluates via consistency tasks and a user study. No equation or claim reduces the reported alignment or control performance to a quantity defined by the same fitted parameters or self-citations; the metric-to-motion consistency test measures whether the conditioned model reproduces its own conditioning signal, which is the intended behavior of conditioning rather than a definitional tautology. The LMA alignment is assessed externally via descriptors and human raters, not by construction from the kinematic definitions alone. This places the work in the normal non-circular range.
Axiom & Free-Parameter Ledger
free parameters (1)
- effort signal scaling
axioms (1)
- domain assumption Laban Movement Analysis Time and Weight factors can be approximated by peak and collective joint positional changes
Reference graph
Works this paper leans on
-
[1]
Allen, D
M. Allen, D. Poggiali, K. Whitaker, T. R. Marshall, and R. A. Kievit. Raincloud plots: a multi-platform tool for robust data visualization. Wellcome open research, 4, 2019
2019
-
[2]
Aristidou, E
A. Aristidou, E. Stavrakis, P. Charalambous, Y . Chrysanthou, and S. L. Himona. Folk dance evaluation using laban movement analysis. Journal on Computing and Cultural Heritage, 8(4):1–19, 2015
2015
-
[3]
J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization, 2016
2016
-
[4]
Belpaeme, P
T. Belpaeme, P. V ogt, R. van den Berghe, K. Bergmann, T. Goksun, M. de Haas, J. Kanero, J. Kennedy, A. K ¨untay, O. Oudgenoeg-Paz, F. Papadopoulos, T. Schodde, J. Verhagen, C. Wallbridge, B. Willem- sen, J. de Wit, V . Geckin, L. Kunold Ne ´e Hoffmann, S. Kopp, and A. K. Pandey. Guidelines for designing social robots as second language tutors.Internation...
2018
-
[5]
B. M. Chaudhry and H. R. Debi. User perceptions and experiences of an AI-driven conversational agent for mental health support.mHealth, 10:22, July 2024
2024
- [6]
-
[7]
X. Chen, B. Jiang, W. Liu, Z. Huang, B. Fu, T. Chen, and G. Yu. Executing your commands via motion diffusion in latent space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18000–18010, 2023
2023
-
[8]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding, 2019
2019
-
[9]
K. Fan, S. Lu, M. Dai, R. Yu, L. Xiao, Z. Dou, J. Dong, L. Ma, and J. Wang. Go to zero: Towards zero-shot motion generation with million-scale data, 2025
2025
-
[10]
C. Guo, S. Zou, X. Zuo, S. Wang, W. Ji, X. Li, and L. Cheng. Generating diverse and natural 3d human motions from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5152–5161, 2022
2022
-
[11]
C. Guo, X. Zuo, S. Wang, S. Zou, Q. Sun, A. Deng, M. Gong, and L. Cheng. Action2motion: Conditioned generation of 3d human motions. InProceedings of the 28th ACM International Conference on Multimedia, 2020
2020
-
[12]
Habibie, D
I. Habibie, D. Holden, J. Schwarz, J. Yearsley, and T. Komura. A recurrent variational autoencoder for human motion synthesis. 01 2017
2017
-
[13]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition, 2015
2015
- [14]
-
[15]
Hertz, R
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, and D. Cohen-Or. Prompt-to-prompt image editing with cross attention control, 2022
2022
-
[16]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models, 2020
2020
-
[17]
Ho and T
J. Ho and T. Salimans. Classifier-free diffusion guidance, 2022
2022
-
[18]
S. Hong, C. Kim, S. Yoon, J. Nam, S. Cha, and J. Noh. Salad: Skeleton-aware latent diffusion for text-driven motion generation and editing, 2025
2025
-
[19]
Huang, W
Y . Huang, W. Wan, Y . Yang, C. Callison-Burch, M. Yatskar, and L. Liu. Como: Controllable motion generation through language guided pose code editing, 2024
2024
-
[20]
Huang, Y .-C
Z. Huang, Y .-C. Guo, H. Wang, R. Yi, L. Ma, Y .-P. Cao, and L. Sheng. Mv-adapter: Multi-view consistent image generation made easy, 2024
2024
-
[21]
D.-K. Jang, S. Park, and S.-H. Lee. Motion puzzle: Arbitrary motion style transfer by body part.ACM Transactions on Graphics, 41(3):1–16, June 2022
2022
-
[22]
Karunratanakul, K
K. Karunratanakul, K. Preechakul, S. Suwajanakorn, and S. Tang. Guided motion diffusion for controllable human motion synthesis, 2023
2023
-
[23]
D. Kim, S. Lee, Y . Jun, Y . Shin, and J. Lee. Vtuber’s atelier: The design space, challenges, and opportunities for vtubing. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25, page 1–23. ACM, Apr. 2025
2025
-
[24]
J. Kim, H. Kim, H. Kim, D. Lee, and S. Yoon. A comprehensive survey of deep learning for time series forecasting: architectural diversity and open challenges.Artificial Intelligence Review, 58(7):216, Apr. 2025
2025
-
[25]
J. Li, C. Xu, Z. Chen, S. Bian, L. Yang, and C. Lu. Hybrik: A hybrid analytical-neural inverse kinematics solution for 3d human pose and shape estimation, 2022
2022
-
[26]
Liang, W
H. Liang, W. Zhang, W. Li, J. Yu, and L. Xu. Intergen: Diffusion- based multi-human motion generation under complex interactions. International Journal of Computer Vision, pages 1–21, 2024
2024
-
[27]
Wonder3D: Single Image to 3D using Cross-Domain Diffusion
X. Long, Y .-C. Guo, C. Lin, Y . Liu, Z. Dou, L. Liu, Y . Ma, S.-H. Zhang, M. Habermann, C. Theobalt, et al. Wonder3d: Single image to 3d using cross-domain diffusion.arXiv preprint arXiv:2310.15008, 2023
-
[28]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization, 2019
2019
-
[29]
S. P. McKee and K. Nakayama. The detection of motion in the peripheral visual field.Vision Research, 24(1):25–32, 1984
1984
-
[30]
Mehrabian and M
A. Mehrabian and M. Wiener. Decoding of inconsistent communica- tions.Journal of Personality and Social Psychology, 6(1):109–114, 1967
1967
-
[31]
C. Meng, Y . He, Y . Song, J. Song, J. Wu, J.-Y . Zhu, and S. Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations, 2022
2022
-
[32]
X. Pan, B. Zheng, X. Jiang, Z. Zeng, Q. Kou, H. Wang, and X. Jin. Romo: A robust solver for full-body unlabeled optical motion capture. InSIGGRAPH Asia 2024 Conference Papers, SA ’24, page 1–11. ACM, Dec. 2024
2024
-
[33]
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein. Generative agents: Interactive simulacra of human behavior, 2023
2023
-
[34]
Park, D.-K
S. Park, D.-K. Jang, and S.-H. Lee. Diverse motion stylization for multiple style domains via spatial-temporal graph-based generative model. 4(3), Sept. 2021
2021
-
[35]
Perez, F
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer, 2017
2017
-
[36]
Petrovich, M
M. Petrovich, M. J. Black, and G. Varol. Temos: Generating diverse human motions from textual descriptions. InComputer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXII, pages 480–497, 2022
2022
-
[37]
S. Raab, I. Gat, N. Sala, G. Tevet, R. Shalev-Arkushin, O. Fried, A. H. Bermano, and D. Cohen-Or. Monkey see, monkey do: Harnessing self- attention in motion diffusion for zero-shot motion transfer, 2024
2024
-
[38]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision, 2021
2021
-
[39]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High- resolution image synthesis with latent diffusion models, 2022
2022
-
[40]
Salimans and J
T. Salimans and J. Ho. Progressive distillation for fast sampling of diffusion models, 2022
2022
-
[41]
Samadani, R
A. Samadani, R. Gorbet, and D. Kulic. Affective movement generation using laban effort and shape and hidden markov models, 2020
2020
-
[42]
H. Sawdayee, C. Guo, G. Tevet, B. Zhou, J. Wang, and A. H. Bermano. Dance like a chicken: Low-rank stylization for human motion diffusion.arXiv preprint arXiv:2503.19557, 2025
-
[43]
Serifi, R
A. Serifi, R. Grandia, E. Knoop, M. Gross, and M. B ¨acher. Robot motion diffusion model: Motion generation for robotic characters. In SIGGRAPH Asia 2024 Conference Papers, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[44]
X. Shi, W. Yao, C. Luo, J. Peng, H. Zhang, and Y . Sun. Fg- mdm: Towards zero-shot human motion generation via chatgpt-refined descriptions, 2024
2024
-
[45]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models, 2022
2022
-
[46]
T. Tao, X. Zhan, Z. Chen, and M. van de Panne. Style-erd: Responsive and coherent online motion style transfer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6593–6603, 2022
2022
-
[47]
Tashakori, A
A. Tashakori, A. Tashakori, G. Yang, and Z. J. Wang. Flexmotion: Lightweight, physics-aware, and controllable human motion genera- tion, 2025
2025
-
[48]
Tevet, S
G. Tevet, S. Raab, S. Cohan, D. Reda, Z. Luo, X. B. Peng, A. H. Bermano, and M. van de Panne. CLoSD: Closing the loop between simulation and diffusion for multi-task character control. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[49]
Tevet, S
G. Tevet, S. Raab, B. Gordon, Y . Shafir, D. Cohen-Or, and A. H. Bermano. Human motion diffusion model, 2022
2022
-
[50]
Turab, P
M. Turab, P. Colantoni, D. Muselet, and A. Tremeau. Dance style recognition using laban movement analysis, 2025
2025
- [51]
-
[52]
W. Wan, Z. Dou, T. Komura, W. Wang, D. Jayaraman, and L. Liu. Tl- control: Trajectory and language control for human motion synthesis, 2024
2024
-
[53]
Z. Wang, Y . Chen, B. Jia, P. Li, J. Zhang, J. Zhang, T. Liu, Y . Zhu, W. Liang, and S. Huang. Move as you say, interact as you can: Language-guided human motion generation with scene affordance, 2024
2024
-
[54]
Werkhoven, H
P. Werkhoven, H. P. Snippe, and A. Toet. Visual processing of optic acceleration.Vision Research, 32(12):2313–2329, 1992
1992
-
[55]
Witkin and M
A. Witkin and M. Kass. Spacetime constraints. InProceedings of the 15th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’88, page 159–168, New York, NY , USA,
-
[56]
Association for Computing Machinery
-
[57]
Y . Xie, V . Jampani, L. Zhong, D. Sun, and H. Jiang. Omnicontrol: Control any joint at any time for human motion generation. 2024
2024
-
[58]
H. Yao, Z. Song, Y . Zhou, T. Ao, B. Chen, and L. Liu. Moconvq: Uni- fied physics-based motion control via scalable discrete representations, 2023
2023
-
[59]
Y . Yuan, J. Song, U. Iqbal, A. Vahdat, and J. Kautz. Physdiff: Physics- guided human motion diffusion model, 2022
2022
-
[60]
Zacharatos, C
H. Zacharatos, C. Gatzoulis, Y . Chrysanthou, and A. Aristidou. Emo- tion recognition for exergames using laban movement analysis. In Proceedings of Motion on Games, pages 61–66, 2013
2013
-
[61]
Zhang, Y
J. Zhang, Y . Zhang, X. Cun, S. Huang, Y . Zhang, H. Zhao, H. Lu, and X. Shen. T2m-gpt: Generating human motion from textual descriptions with discrete representations, 2023
2023
-
[62]
Zhang, Z
M. Zhang, Z. Cai, L. Pan, F. Hong, X. Guo, L. Yang, and Z. Liu. Motiondiffuse: Text-driven human motion generation with diffusion model, 2022
2022
-
[63]
Zhang, Y
Y . Zhang, Y . Feng, A. Cseke, N. Saini, N. Bajandas, N. Heron, and M. J. Black. PRIMAL: physically reactive and interactive motor model for avatar learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct. 2025
2025
-
[64]
Y . Zhao, J. Jiang, Y . Chen, R. Liu, Y . Yang, X. Xue, and S. Chen. Metaverse: Perspectives from graphics, interactions and visualization. Visual Informatics, 6(1):56–67, 2022
2022
-
[65]
Zhong, Y
L. Zhong, Y . Xie, V . Jampani, D. Sun, and H. Jiang. Smoodi: Stylized motion diffusion model. 2024. EMA: Effort Metric Attention for Anatomical Effort-Guided HumanMotion Diffusion Supplementary Material S1. SECTION3.D: IMPLEMENTATIONDETAILS AND DESIGNRATIONALE A. Denoiser Architecture Overview While the main paper describes the Effort Metric At- tention ...
2024
-
[66]
z TRANS BLOCK TRANS BLOCK TRANS BLOCK TRANS BLOCK TRANSBLOCK Salad’s VAE Decoder MLP MLP Pre trained, frozenPositional encodingSkip ConnectionTransformer block Fig
Effort Metric MAE:Given joint positionp t,j ∈R 3 at framet, we define the instantaneous positional change of skeletal groupGwithN G joints as: δG t = 1 NG X j∈G ∥pt+1,j −p t,j∥2 (13) From this signal, we define: Peak Change (PC)= max t δG t ,(14) Collective Change (CC)= X t δG t .(15) Effort Metric MAE is computed as the absolute difference between genera...
-
[67]
,1.3}using Spearman’s rank correlation
Structural Monotonicity (ρ):We evaluate monotonic intensity scaling across seven ordered effort levelsS= {0.7, . . . ,1.3}using Spearman’s rank correlation. Correla- tions are computed separately for Peak Change (M peak) and Collective Change (M coll), for each action and anatomical region: ρ= cov(RS, RM) σRS σRM (16) whereR S andR M denote ranked effort ...
-
[68]
Laban Monotonicity:We evaluate monotonic intensity scaling of dynamic quality using computational approxima- tions of Laban Effort factors adapted from Samadani et al. [41], standardized here to capture peak intensity mag- nitudes: •Weight:peak kinetic energy, Eweight = max t X j ∥vt,j∥2 2 (17) •Time:peak net acceleration, Etime = max t X j ∥at,j∥2 (18) •...
-
[69]
Global Em- bedding:Table S2 presents a comparative analysis between the Global Embedding strategy (Fig
Impact of Conditioning Strategy: ARE vs. Global Em- bedding:Table S2 presents a comparative analysis between the Global Embedding strategy (Fig. S2) and our Anatom- ical Region Embedding (ARE). The main difference of the Global Embedding strategy is that it flattens the input metrics intoc m ∈R B×(Ng·Np) and lacks the region-identity embedding (P id). The...
-
[70]
Person kicks ball forward
Necessity of Data Augmentation:Standard datasets such as HumanML3D are inherently biased toward motions of moderate intensity, which limits a model’s ability to gener- alize to extreme-effort regimes. We evaluate a baseline model trained solely on the original dataset (Orig→Aug) under out- of-distribution effort conditions. Compared to our full model, ARE...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.