MDIA: A Multi-Agent Diagnostic Intelligence Pipeline on HealthBench Professional
Pith reviewed 2026-06-30 13:11 UTC · model grok-4.3
The pith
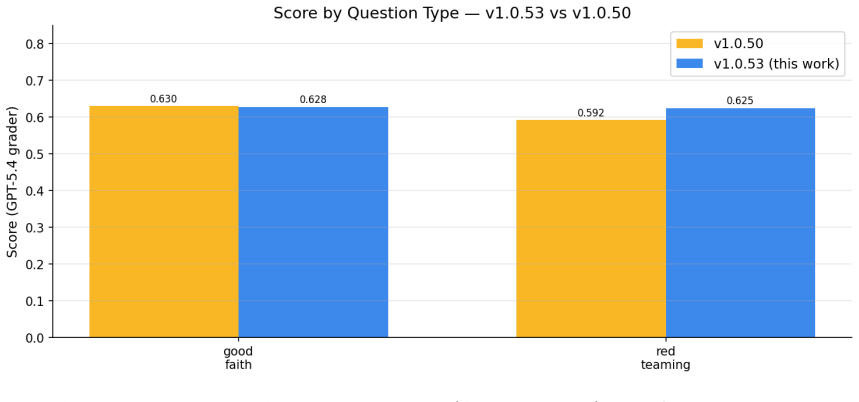
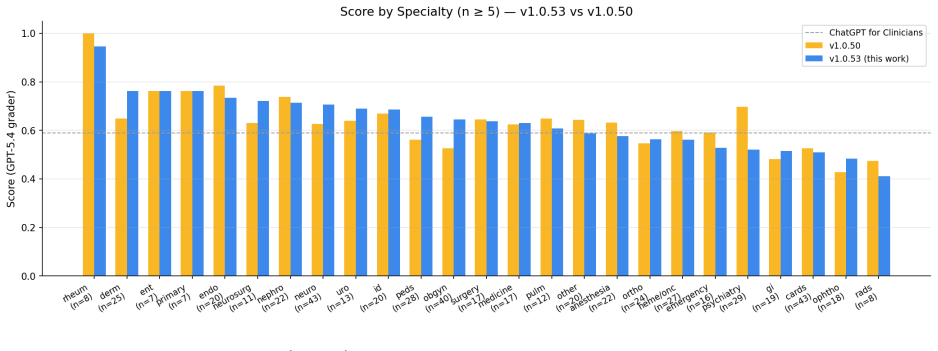
MDIA, a 7-node multi-agent graph, scores 0.6272 on HealthBench Professional and exceeds the ChatGPT for Clinicians baseline by 3.72 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
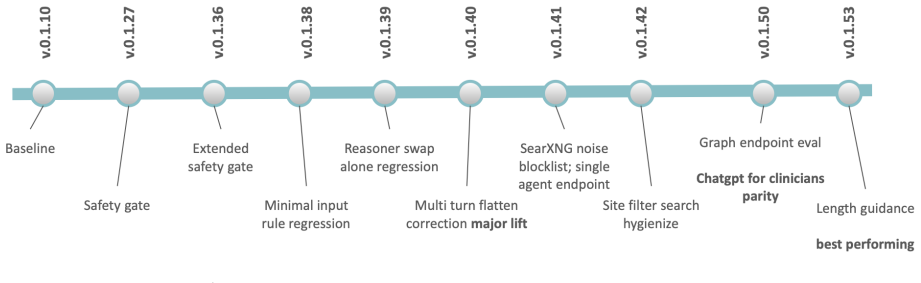
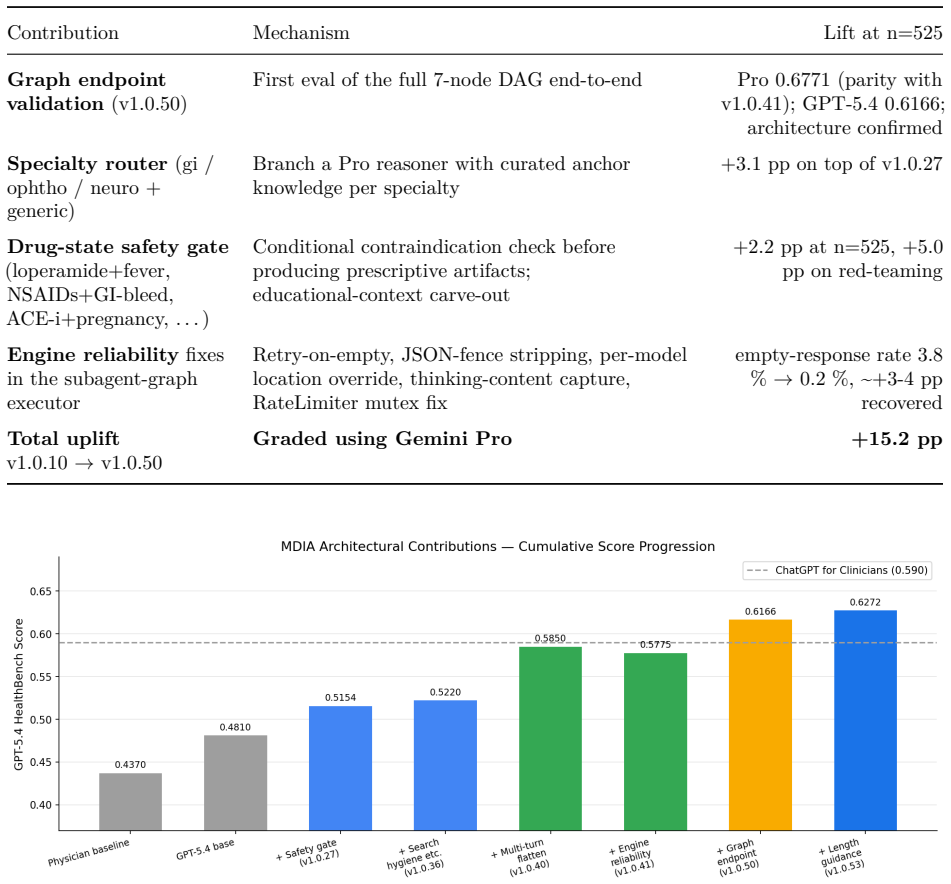
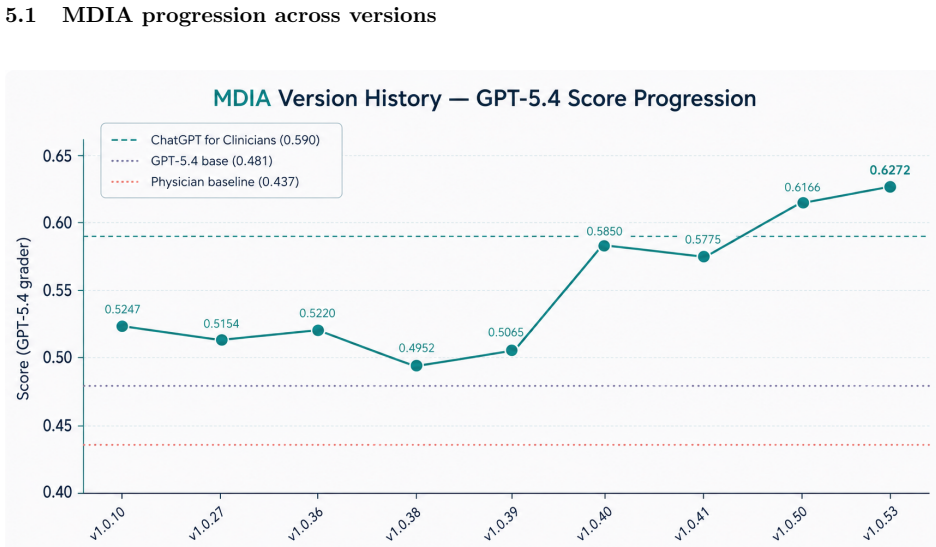
MDIA achieves 0.6272 on HealthBench Professional under GPT-5.4-2026-03-05, which is +3.72 pp above OpenAI's ChatGPT for Clinicians. The performance lift is attributable to system architecture: specialty routing, multi-turn context preservation, drug-state safety gating, site-filtered search, length-aware synthesis, and engine-level reliability. These findings support the view that agentic clinical benchmark performance is shaped both by the underlying foundation model and the orchestration architecture. When using Gemini 2.5 Pro as grader, MDIA scored 0.6585, suggesting that the choice of grader is a source of variability and that robust evaluation of LLMs requires assessment across several
What carries the argument
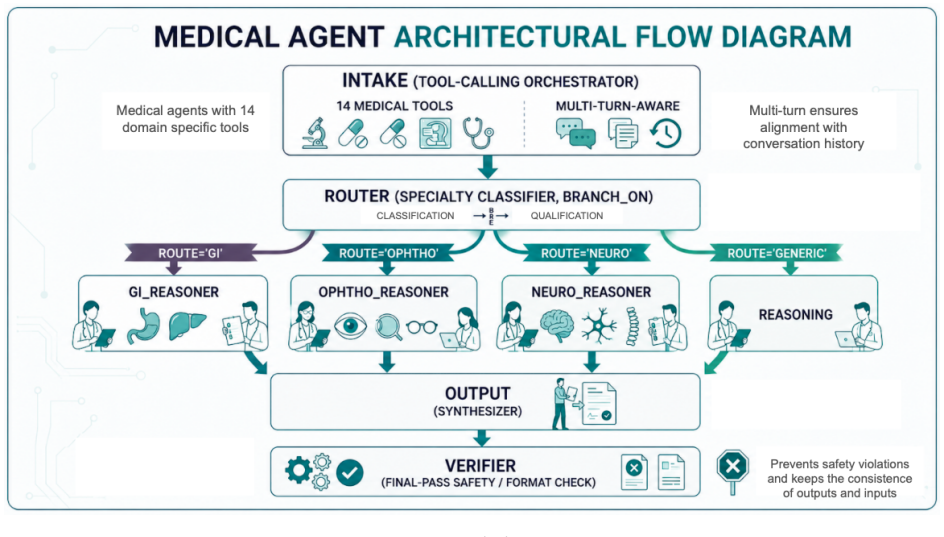
The 7-node specialty-routed clinical reasoning graph that implements MDIA and supplies specialty routing, multi-turn context preservation, drug-state safety gating, site-filtered search, length-aware synthesis, and engine-level reliability.
If this is right
- Agentic clinical benchmark performance is shaped by both the foundation model and the orchestration architecture.
- Larger gains on clinical benchmarks can come from architectural and engine-level design than from prompt engineering alone.
- Robust evaluation of LLMs on clinical tasks requires assessment across several independent grader models because single-grader scores vary.
- MDIA demonstrates that a non-fine-tuned LLM can reach higher scores on HealthBench Professional when wrapped in the described multi-agent graph.
Where Pith is reading between the lines
- Similar multi-agent graphs could be tested on other clinical benchmarks to check whether the reported architectural gains generalize beyond HealthBench Professional.
- The grader variability finding implies that published leaderboards using a single grader model may overstate or understate true system differences.
- If the architecture components prove portable, future clinical agents could combine the same routing and safety mechanisms with different base models without retraining.
- The emphasis on engine-level reliability suggests that production clinical systems may benefit more from explicit safety gates than from scaling model size alone.
Load-bearing premise
The performance difference between MDIA and the ChatGPT for Clinicians baseline is caused by the listed architectural features rather than differences in prompting, model version details, or unstated experimental controls.
What would settle it
A side-by-side run of MDIA and the baseline that holds the underlying LLM, prompt wording, and all other controls fixed while disabling only the architectural components, then measuring whether the 3.72-point gap disappears.
Figures




read the original abstract
Most reported gains on agentic-LLM clinical benchmarks are often attributed to prompt engineering, yet our results suggest that larger improvements can come from architectural and engine-level design. We present MDIA, a Multi-agent Diagnostic Intelligence Agent implemented as a 7-node specialty-routed clinical reasoning graph, on the full HealthBench Professional benchmark (n = 525), on a non-fine-tuned LLM. MDIA achieves 0.6272 under OpenAI's GPT-5.4-2026-03-05, which is +3.72 pp above the performance of OpenAI's ChatGPT for Clinicians. The experimental work shows that performance lift is attributable to system architecture: specialty routing, multi-turn context preservation, drug-state safety gating, site-filtered search, length-aware synthesis, and engine-level reliability. These findings support the view that agentic clinical benchmark performance is shaped both by the underlying foundation model and the orchestration architecture. Nevertheless, we also noticed notable differences when using other models as a grader; in particular, when using Gemini 2.5 Pro, MDIA scored 0.6585, which suggests that the choice of grader is a source of variability. Robust evaluation of LLMs would therefore require assessment across several independent grader models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MDIA, a 7-node multi-agent diagnostic intelligence pipeline implemented as a specialty-routed clinical reasoning graph. Evaluated on the full HealthBench Professional benchmark (n=525) using a non-fine-tuned LLM (GPT-5.4-2026-03-05), MDIA scores 0.6272, which is reported as +3.72 pp above OpenAI's ChatGPT for Clinicians baseline. The central claim is that this lift is attributable to architectural and engine-level features (specialty routing, multi-turn context preservation, drug-state safety gating, site-filtered search, length-aware synthesis, and engine-level reliability) rather than prompt engineering. The paper additionally notes grader-model variability, with MDIA scoring 0.6585 under Gemini 2.5 Pro, and concludes that robust LLM evaluation requires multiple independent graders.
Significance. If the attribution of the observed performance difference to the listed architectural components is substantiated, the result would indicate that system-level orchestration can produce larger gains on agentic clinical benchmarks than prompt engineering alone. This would strengthen the case for treating multi-agent design choices as first-class variables in clinical LLM research and would motivate controlled studies of individual components such as safety gating and specialty routing.
major comments (2)
- [Abstract] Abstract: the claim that 'the experimental work shows that performance lift is attributable to system architecture' lacks any description of the required controls. No ablation studies, single-agent baselines with matched prompts and model versions, or incremental addition of components are reported, so the +3.72 pp difference cannot be isolated from confounding factors such as prompt template differences, temperature settings, or exact model versioning.
- [Abstract] Abstract: the reported grader-model sensitivity (0.6272 vs. 0.6585) demonstrates that evaluation outcomes are sensitive to setup choices, yet no statistical tests, confidence intervals, or multi-grader protocol is applied to the primary MDIA-versus-baseline comparison, leaving the main result vulnerable to the same source of variability.
minor comments (1)
- [Abstract] Abstract: the benchmark size (n=525) and exact scoring metric are stated, but the manuscript does not indicate whether the ChatGPT for Clinicians baseline was evaluated under identical conditions (same grader, same prompt style, same number of turns).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the attribution of performance gains and the robustness of the evaluation. We address each major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the experimental work shows that performance lift is attributable to system architecture' lacks any description of the required controls. No ablation studies, single-agent baselines with matched prompts and model versions, or incremental addition of components are reported, so the +3.72 pp difference cannot be isolated from confounding factors such as prompt template differences, temperature settings, or exact model versioning.
Authors: We agree that the manuscript does not contain ablation studies, matched single-agent baselines, or incremental component additions that would isolate the contribution of each architectural element from potential confounders such as prompt differences or configuration settings. The reported comparison is solely against the provided ChatGPT for Clinicians baseline under the same model version. Consequently, the strong claim of attribution to system architecture cannot be rigorously supported by the current experiments. We will revise the abstract and relevant discussion sections to present the +3.72 pp difference as an observed performance gap rather than an attributed causal effect, and we will add an explicit limitations paragraph acknowledging the absence of controlled ablation experiments. revision: yes
-
Referee: [Abstract] Abstract: the reported grader-model sensitivity (0.6272 vs. 0.6585) demonstrates that evaluation outcomes are sensitive to setup choices, yet no statistical tests, confidence intervals, or multi-grader protocol is applied to the primary MDIA-versus-baseline comparison, leaving the main result vulnerable to the same source of variability.
Authors: We acknowledge that the primary MDIA-versus-baseline comparison (both under GPT-5.4) is reported as point estimates without accompanying statistical tests, confidence intervals, or a multi-grader protocol, even though we separately illustrate grader sensitivity with the Gemini 2.5 Pro score. This leaves the main result open to the variability concern raised. We will revise the manuscript to include a limitations discussion on this point and to recommend that future evaluations adopt multi-grader protocols with statistical analysis. No additional data collection is planned for the current revision, but the text will be updated to reflect the limitation accurately. revision: yes
Circularity Check
No circularity; empirical benchmark with no self-referential derivation
full rationale
The paper reports an empirical score (0.6272) on HealthBench Professional for the MDIA system versus a baseline, attributing the +3.72 pp difference to listed architectural components. No equations, fitted parameters, self-citations, or derivations appear in the provided text. The central claim is a direct experimental measurement rather than a quantity defined in terms of itself or reduced by construction to prior inputs. This matches the default expectation of a self-contained empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Benefits, limits, and risks of GPT-4 as an AI chatbot for medicine.New England Journal of Medicine, 388(13):1233–1239, 2023
Peter Lee, Sébastien Bubeck, and Joseph Petro. Benefits, limits, and risks of GPT-4 as an AI chatbot for medicine.New England Journal of Medicine, 388(13):1233–1239, 2023. 28
2023
-
[2]
HealthBench Professional: Evaluating Large Language Models on Real Clinician Chats
OpenAI. HealthBench Professional: Evaluating large language models on real clinician chats. arXiv preprint arXiv:2604.27470, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Glicksberg, Girish N
Alon Gorenshtein, Mahmud Omar, Benjamin S. Glicksberg, Girish N. Nadkarni, and Eyal Klang. AI agents in clinical medicine: A systematic review.medRxiv preprint, 2025
2025
-
[4]
MedAgents: Large language models as collaborators for zero-shot medical reasoning
Xiangru Tang et al. MedAgents: Large language models as collaborators for zero-shot medical reasoning. 2024
2024
-
[5]
Gpt-5.4, 2026
OpenAI. Gpt-5.4, 2026. Accessed 2026-03-05
2026
-
[6]
TietAI Hydra Platform, 2026
Roberto Cruz. TietAI Hydra Platform, 2026
2026
-
[7]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023
2023
-
[8]
Chateval: Towards better llm-based evaluators through multi-agent debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. InInternational Conference on Learning Representations, 2024
2024
-
[9]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nahid Oufattole, Wei-Hung Weng, Hui Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
2021
-
[10]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering.arXiv preprint arXiv:2203.14371, 2022
-
[11]
Pubmedqa: A dataset for biomedical research question answering.EMNLP, 2019
Qiao Jin, Bhuwan Dhingra, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering.EMNLP, 2019
2019
-
[12]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Sivasankar Kannan, Dawn Song, and Jacob Stein- hardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[13]
Large language models encode clinical knowledge.Nature, 620:172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, et al. Large language models encode clinical knowledge.Nature, 620:172–180, 2023
2023
-
[14]
Toward expert-level medical question answering with large language models.Nature Medicine, 31:943–950, 2025
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, et al. Toward expert-level medical question answering with large language models.Nature Medicine, 31:943–950, 2025
2025
-
[15]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Ruchir Arora et al. HealthBench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments.npj Digital Medicine, 2026
Samuel Schmidgall et al. AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments.npj Digital Medicine, 2026
2026
-
[17]
MedAgentBench: A realistic virtual EHR environment to benchmark medical LLM agents.NEJM AI, 2025
Stanford ML Group et al. MedAgentBench: A realistic virtual EHR environment to benchmark medical LLM agents.NEJM AI, 2025
2025
-
[18]
PhysicianBench: Evaluating LLM Agents in Real-World EHR Environments
Ruoqi Liu, Imran Q. Mohiuddin, Austin J. Schoeffler, et al. PhysicianBench: Evaluating LLM agents in real-world EHR environments.arXiv preprint arXiv:2605.02240, 2026. 29
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Gemini 2.5 pro, 2025
Google DeepMind. Gemini 2.5 pro, 2025
2025
-
[20]
Gemini 3.1 pro, 2026
Google DeepMind. Gemini 3.1 pro, 2026
2026
-
[21]
Can large language models reason about medical questions?Patterns, 5(3):100943, 2024
Valentin Liévin, Christoffer Egeberg Hother, Andreas Geert Motzfeldt, and Ole Winther. Can large language models reason about medical questions?Patterns, 5(3):100943, 2024
2024
-
[22]
Mixture-of-Agents Enhances Large Language Model Capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of-agents enhances large language model capabilities.arXiv preprint arXiv:2406.04692, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Lin Yang, Yuancheng Yang, Xu Wang, Changkun Liu, and Haihua Yang. MedMT-Bench: Can LLMs memorize and understand long multi-turn conversations in medical scenarios?arXiv preprint arXiv:2603.23519, 2026
-
[24]
Oliver Normand, Esther Borsi, Mitch Fruin, Lauren E. Walker, et al. A real-world evaluation of LLM medication safety reviews in NHS primary care.arXiv preprint arXiv:2512.21127, 2025
-
[25]
Large language model as clinical decision support system augments medication safety in 16 clinical specialties.npj Digital Medicine, 2025
Others. Large language model as clinical decision support system augments medication safety in 16 clinical specialties.npj Digital Medicine, 2025
2025
-
[26]
Guiding LLMs the right way: Fast, non-invasive constrained generation
Luca Beurer-Kellner, Marc Fischer, and Martin Vechev. Guiding LLMs the right way: Fast, non-invasive constrained generation. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[27]
Lessons from the trenches on reproducible evaluation of language models
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, et al. Lessons from the trenches on reproducible evaluation of language models. InProceedings of the First Conference on Language Modeling (COLM), 2024
2024
-
[28]
Explaining length bias in llm-based preference evaluations, 2024
Zhengyu Hu, Linxin Song, Jieyu Zhang, Zheyuan Xiao, Tianfu Wang, Zhenyu Chen, Jianxun Lian, Nicholas Jing Yuan, Kaize Ding, and Hui Xiong. Explaining length bias in llm-based preference evaluations, 2024
2024
-
[29]
Hashimoto
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators, 2024
2024
-
[30]
Yu Ying Chiu, Michael S. Lee, Rachel Calcott, Brandon Handoko, Paul de Font-Reaulx, Paula Rodriguez, Chen Bo Calvin Zhang, Ziwen Han, Udari Madhushani Sehwag, Yash Maurya, Christina Knight, Harry Lloyd, Florence Bacus, Mantas Mazeika, Bing Liu, Yejin Choi, Mitchell Gordon, and Sydney Levine. Morebench: Evaluating procedural and pluralistic moral reasoning...
2025
-
[31]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[32]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[33]
Enabling large language models to generate text with citations
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. Enabling large language models to generate text with citations. InProceedings of EMNLP, 2023. 30
2023
-
[34]
Teaching language models to support answers with verified quotes
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chad- wick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, and Nat McAleese. Teaching language models to support answers with verified quotes.arXiv preprint arXiv:2203.11147, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Kochenderfer
Anka Reuel, Amelia Hardy, Chandler Smith, Max Lamparth, Malcolm Hardy, and Mykel J. Kochenderfer. BetterBench: Assessing AI benchmarks, uncovering issues, and establishing best practices. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
2024
-
[36]
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark
Oscar Sainz, Jon Ander Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. InFindings of EMNLP, 2023
2023
-
[37]
Bowman, and Shi Feng
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM evaluators recognize and favor their own generations. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[38]
Large Language Models are not Fair Evaluators
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators.arXiv preprint arXiv:2305.17926, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Verbosity bias in preference labeling by large language models.arXiv preprint arXiv:2310.10076, 2023
Keita Saito, Akifumi Wachi, Koki Wataoka, and Youhei Akimoto. Verbosity bias in preference labeling by large language models.arXiv preprint arXiv:2310.10076, 2023
-
[40]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[41]
Matthew Lewis, Samuel Thio, Amy Roberts, et al. Grounding large language models in clinical evidence: A retrieval-augmented generation system for querying UK NICE clinical guidelines. arXiv preprint arXiv:2510.02967, 2025
-
[42]
Retrieval-augmented generation (RAG) in healthcare: A comprehensive review.AI (MDPI), 2025
Others. Retrieval-augmented generation (RAG) in healthcare: A comprehensive review.AI (MDPI), 2025
2025
-
[43]
Benchmarking retrieval-augmented generation for medicine
Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. Benchmarking retrieval-augmented generation for medicine. InFindings of the Association for Computational Linguistics (ACL Findings), 2024
2024
-
[44]
The Claude model family: Opus, Sonnet, Haiku, 2024
Anthropic. The Claude model family: Opus, Sonnet, Haiku, 2024. Anthropic technical report
2024
-
[45]
Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning for Efficient Reasoning
Derek Wong et al. Prompt-level distillation.arXiv preprint arXiv:2602.21103, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Large language models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[47]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. DSPy: Compiling declarative language model calls into self-improving pipelines.arXiv preprint arXiv:2310.03714, 2023. 31
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
TietAI Evals Public: Empirical analysis results for MDIA on HealthBench Professional, 2026
Cruz, Roberto, Rey-Blanco, David. TietAI Evals Public: Empirical analysis results for MDIA on HealthBench Professional, 2026. Public repository
2026
-
[49]
Introducing HealthBench, 2025
OpenAI. Introducing HealthBench, 2025
2025
- [50]
-
[51]
Medical Reasoning with Large Language Models: A Survey and MR-Bench
Others. Medical reasoning with large language models: A survey and MR-Bench.arXiv preprint arXiv:2604.08559, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
MedGemma: Open medical foundation models, 2025
Google Research. MedGemma: Open medical foundation models, 2025
2025
-
[53]
Multi-agent debate for llm judges with adaptive stability detection
Tianyu Hu, Zhen Tan, Song Wang, Huaizhi Qu, and Tianlong Chen. Multi-agent debate for llm judges with adaptive stability detection. InAdvances in Neural Information Processing Systems, 2025
2025
-
[54]
Laura Dietz, Oleg Zendel, Peter Bailey, Charles L. A. Clarke, Ellese Cotterill, Jeff Dalton, Faegheh Hasibi, Mark Sanderson, and Nick Craswell. Principles and guidelines for the use of llm judges. InProceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval, ICTIR ’25, pages 1–12. ACM, 2025. 32 ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.