Streaming Reinforcement Learning under Partial Observability with Real-Time Recurrent Learning
Pith reviewed 2026-06-30 14:32 UTC · model grok-4.3
The pith
Recurrent trace units enable exact real-time recurrent learning for streaming RL in partially observable environments with linear complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Recurrent trace units are a diagonal recurrent architecture that enables exact RTRL with linear time and memory complexity in the parameter count, and they integrate cleanly into existing streaming algorithms across both discrete and continuous control under partial observability.
What carries the argument
recurrent trace units, a diagonal recurrent architecture that enables exact RTRL with linear time and memory complexity in the parameter count
If this is right
- Performance holds on MemoryChain diagnostic tasks with chain lengths from 2 to 128 where streaming TBPTT(1) baselines collapse.
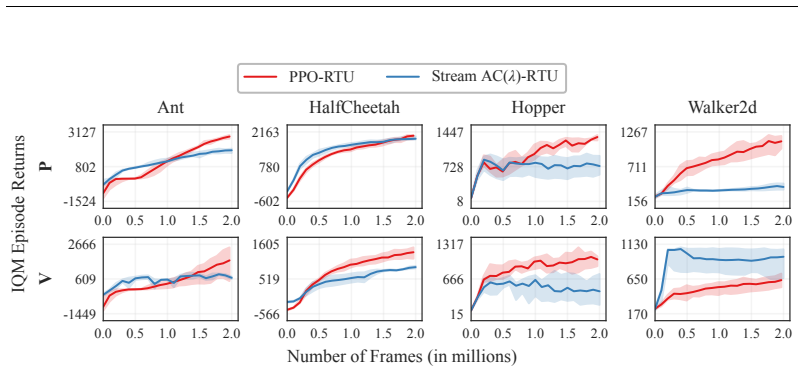
- The streaming method matches batched PPO on five POPGym tasks.
- On partially observable MuJoCo continuous control the approach recovers a substantial fraction of batched performance without replay buffers or batched updates.
Where Pith is reading between the lines
- The linear complexity may open streaming RL to real-time agents that must act on partial observations without storing large buffers.
- Diagonal structure could be tested on longer-horizon or higher-dimensional POMDPs to check where it ceases to suffice.
- Integration with other online methods might extend the same linear RTRL benefit beyond the tested control settings.
Load-bearing premise
The diagonal recurrent architecture supplies enough expressivity to capture the temporal dependencies needed for the POMDP tasks without full recurrent connections.
What would settle it
A POMDP task whose solution requires non-diagonal temporal mixing where recurrent trace units fail to learn but a full recurrent network succeeds would falsify the claim.
Figures

read the original abstract
Streaming reinforcement learning has emerged as an online learning paradigm that conforms to the restrictions of natural learning agents that process data incrementally, i.e. with a batch size of 1 and no replay buffer. While streaming RL has recently been shown to scale with deep function approximation with full observability, partially observable settings have remained out of reach. Truncated backpropagation through time collapses to a one-step gradient horizon under the streaming setting, and exact real-time recurrent learning is prohibitively expensive. We close this gap using recurrent trace units, a diagonal recurrent architecture that enables exact RTRL with linear time and memory complexity in the parameter count, and show that they integrate cleanly into existing streaming algorithms across both discrete and continuous control. On a MemoryChain diagnostic with chain lengths from 2 to 128, our method sustains performance where streaming TBPTT(1) baselines using feedforward, GRU, and RTU networks collapse. On five POPGym tasks and on partially observable MuJoCo continuous control, the streaming approach is competitive with batched PPO on POPGym and recovers a substantial fraction of batched performance on masked MuJoCo, despite using no replay buffer or batched updates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes recurrent trace units (RTUs), a diagonal recurrent neural network architecture that permits exact real-time recurrent learning (RTRL) with linear time and memory complexity in the number of parameters. The authors integrate RTUs into streaming RL algorithms and evaluate them on a MemoryChain diagnostic task with varying chain lengths, five tasks from the POPGym suite, and partially observable MuJoCo environments, claiming competitive performance with batched methods despite using batch size 1 and no replay buffer.
Significance. Should the central claims hold, the work would be significant for advancing streaming reinforcement learning to partially observable settings, where previous approaches either truncate gradients or incur prohibitive costs. The linear-complexity exact RTRL is a clear technical advance, and the empirical results on both diagnostic and standard benchmarks provide concrete evidence of the method's viability in discrete and continuous control. The absence of replay buffers aligns with the streaming paradigm and strengthens the contribution.
major comments (2)
- [§3 (Recurrent Trace Units)] §3 (Recurrent Trace Units definition): The recurrence matrix is strictly diagonal, so hidden units evolve independently with no direct mixing. No representational-capacity argument, proof, or counter-example is supplied showing this restriction is without loss of generality for POMDPs whose belief states require nonlinear cross-channel interactions; this assumption is load-bearing for the claim that RTUs suffice across the evaluated tasks.
- [§4.2 (POPGym and masked MuJoCo results)] §4.2 (POPGym and masked MuJoCo results): The claim that the streaming RTU approach 'recovers a substantial fraction' of batched PPO performance is central to the empirical contribution, yet the text supplies neither the exact recovered fractions, seed-wise standard deviations, nor an ablation contrasting diagonal RTU against a non-diagonal recurrent baseline, preventing isolation of the diagonal restriction's effect.
minor comments (2)
- [Abstract] Abstract: the phrase 'linear time and memory complexity in the parameter count' would benefit from explicit big-O notation and a direct contrast to the quadratic cost of standard RTRL.
- [§5 (Discussion)] §5 (Discussion): a brief reference to prior diagonal or low-rank recurrent architectures would help situate the novelty of the RTU construction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: §3 (Recurrent Trace Units definition): The recurrence matrix is strictly diagonal, so hidden units evolve independently with no direct mixing. No representational-capacity argument, proof, or counter-example is supplied showing this restriction is without loss of generality for POMDPs whose belief states require nonlinear cross-channel interactions; this assumption is load-bearing for the claim that RTUs suffice across the evaluated tasks.
Authors: We agree that the manuscript does not supply a general proof or counter-example establishing that the diagonal restriction is without loss of generality. The diagonal form is deliberately chosen to obtain exact RTRL at linear complexity; we will revise §3 to state this motivation explicitly, acknowledge that direct nonlinear cross-channel mixing in the recurrence is precluded, and clarify that we make no universality claim. We will instead highlight that the combination of input projections, nonlinear activations, and per-unit traces enables effective belief-state tracking on the evaluated POMDPs, as demonstrated by the MemoryChain and POPGym results. A short limitations paragraph will be added noting that more complex belief states may require richer recurrence. revision: yes
-
Referee: §4.2 (POPGym and masked MuJoCo results): The claim that the streaming RTU approach 'recovers a substantial fraction' of batched PPO performance is central to the empirical contribution, yet the text supplies neither the exact recovered fractions, seed-wise standard deviations, nor an ablation contrasting diagonal RTU against a non-diagonal recurrent baseline, preventing isolation of the diagonal restriction's effect.
Authors: We accept that the current text is insufficiently quantitative. In the revised manuscript we will (i) report the precise average recovered fraction of batched PPO performance together with per-task values, (ii) include seed-wise standard deviations for all reported curves, and (iii) add an ablation on a representative subset of tasks that contrasts diagonal RTU against a non-diagonal recurrent baseline (where the latter remains computationally tractable). These additions will allow readers to assess the practical impact of the diagonal restriction more precisely. revision: yes
Circularity Check
No circularity: new diagonal architecture derived and tested independently on external benchmarks
full rationale
The paper introduces recurrent trace units as a novel diagonal recurrent architecture enabling exact RTRL with linear complexity, then evaluates the resulting streaming RL method on MemoryChain (chain lengths 2-128), five POPGym tasks, and partially observable MuJoCo. These are external benchmarks with no indication that performance metrics or architectural claims reduce by construction to fitted parameters, self-citations, or renamed inputs. The abstract and description present the method as a self-contained proposal whose correctness is assessed via independent empirical comparison to baselines like TBPTT(1), GRU, and batched PPO. No load-bearing derivation step is shown to collapse to its own inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
recurrent trace unit
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/1607.06450. Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neural machine translation: Encoder-decoder approaches,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
On the Properties of Neural Machine Translation: Encoder-Decoder Approaches
URLhttps://arxiv. org/abs/1409.1259. Esraa Elelimy, Adam White, Michael Bowling, and Martha White. Real-time recurrent learning us- ing trace units in reinforcement learning. InAdvances in Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URLhttps://arxiv. org/abs/2507.09087. Mohamed Elsayed, Gautham Vasan, and A. Rupam Mahmood. Streaming deep reinforcement learn- ing finally works.arXiv preprint arXiv:2410.14606,
-
[4]
Neural Computation 9, 1735–1780
DOI: 10.1162/neco.1997.9.8.1735. Kazuki Irie, Anand Gopalakrishnan, and Jürgen Schmidhuber. Exploring the promise and limits of real-time recurrent learning. InInternational Conference on Learning Representations,
-
[5]
URL https://arxiv.org/abs/2303.06349. Ian Osband, Yotam Doron, Matteo Hessel, John Aslanides, Eren Sezener, Andre Saraiva, Katrina McKinney, Tor Lattimore, Csaba Szepesvári, Satinder Singh, Benjamin Van Roy, Richard Sutton, David Silver, and Hado van Hasselt. Behaviour suite for reinforcement learning. InInternational Conference on Learning Representations,
-
[6]
Proximal Policy Optimization Algorithms
URLhttps://arxiv.org/abs/1707.06347. Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. The MIT Press, Cambridge, MA,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.