HCL-FF: Hierarchical and Contrastive Learning for Forward-Forward Algorithm
Pith reviewed 2026-06-30 12:33 UTC · model grok-4.3
The pith
HCL-FF adds a coarse-to-fine hierarchical strategy and supervised contrastive objective to the Forward-Forward algorithm to fix layer coordination and semantic ambiguity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the Hierarchical and Contrastive Learning FF framework (HCL-FF) overcomes the lack of hierarchical coordination and semantically ambiguous features in the Forward-Forward algorithm by introducing a coarse-to-fine hierarchical learning strategy and a supervised contrastive objective, achieving new state-of-the-art performance among FF-based methods with accuracy gains of +5.46% on CIFAR-10, +17.00% on CIFAR-100, and +12.51% on Tiny-ImageNet.
What carries the argument
The coarse-to-fine hierarchical learning strategy that builds representations from low-level cues to high-level semantics, combined with a supervised contrastive objective that enforces class-discriminative alignment after goodness decoupling.
If this is right
- FF-based training becomes competitive on complex image classification benchmarks while preserving layer-independent updates.
- Representations gain semantic clarity and class discriminability without requiring global backpropagation.
- The method provides a concrete way to add cross-layer coordination to any local goodness-based learner.
- Accuracy improvements scale with dataset difficulty, as seen in larger relative gains on CIFAR-100 and Tiny-ImageNet.
Where Pith is reading between the lines
- The same two additions could be tested on non-vision domains such as audio or text where local training is desirable.
- The contrastive component might be adapted to fully unsupervised settings by replacing class labels with other similarity signals.
- Hardware implementations that already support local updates could adopt HCL-FF with minimal extra communication between layers.
Load-bearing premise
The hierarchical strategy and contrastive objective can be added without undermining the purely local, layer-independent training that defines the Forward-Forward approach.
What would settle it
An ablation that removes either the hierarchical layering or the contrastive objective and checks whether the reported accuracy gains disappear on CIFAR-100.
Figures






read the original abstract
Deep neural networks trained with backpropagation have achieved outstanding performance in vision tasks but remain biologically implausible, computationally demanding, and difficult to interpret. The Forward-Forward (FF) algorithm offers a promising alternative by training each layer independently through local goodness objectives. However, its purely local optimization lacks hierarchical coordination across layers, and the decoupling of goodness from features leaves the representations unconstrained and semantically ambiguous. We propose a Hierarchical and Contrastive Learning FF framework (HCL-FF) to address these limitations. HCL-FF introduces (1) a coarse-to-fine hierarchical learning strategy that guides representations from low-level cues to high-level semantics, and (2) a supervised contrastive objective that enforces class-discriminative alignment after goodness decoupling. Experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet demonstrate that HCL-FF achieves new state-of-the-art performance among FF-based methods, with notable accuracy gains of +5.46%, +17.00%, and +12.51%, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HCL-FF, an extension of the Forward-Forward algorithm that adds a coarse-to-fine hierarchical learning strategy to coordinate representations across layers and a supervised contrastive objective to enforce class-discriminative features after goodness decoupling. Experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet are reported to yield accuracy gains of +5.46%, +17.00%, and +12.51% respectively over prior FF-based methods, establishing new state-of-the-art results within the FF family.
Significance. If the empirical claims hold after full experimental details are supplied, the work would show that targeted global signals can be injected into layer-local training without destroying the locality that distinguishes FF from backpropagation. This would strengthen the case for FF-style algorithms as competitive, biologically motivated alternatives on standard vision benchmarks.
major comments (1)
- [Abstract] Abstract: the central claim of new state-of-the-art performance rests on reported accuracy gains of +5.46%, +17.00%, and +12.51%, yet the abstract supplies no information on the precise baseline FF methods, their absolute accuracies, the number of independent runs, hyperparameter search protocol, or statistical significance tests. These omissions render the magnitude and reliability of the improvements impossible to assess from the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the work's potential impact. We address the sole major comment below and will revise the manuscript to strengthen the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of new state-of-the-art performance rests on reported accuracy gains of +5.46%, +17.00%, and +12.51%, yet the abstract supplies no information on the precise baseline FF methods, their absolute accuracies, the number of independent runs, hyperparameter search protocol, or statistical significance tests. These omissions render the magnitude and reliability of the improvements impossible to assess from the provided text.
Authors: We agree that the abstract should be more self-contained. In the revised version we will explicitly name the baseline FF methods (original FF, FF with local contrastive loss, and the strongest prior variant), report their absolute accuracies alongside the gains, state that results are averaged over 5 independent runs with standard deviations, briefly note the hyperparameter protocol (grid search over learning rate and layer-wise goodness thresholds), and indicate that gains exceed run-to-run variance. Full tables, search details, and significance testing appear in Section 4; the abstract update will simply surface the key numbers without lengthening the text excessively. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an algorithmic extension to the Forward-Forward method (hierarchical coarse-to-fine strategy plus supervised contrastive loss) and reports empirical accuracy on public benchmarks (CIFAR-10/100, Tiny-ImageNet). No equations, uniqueness theorems, or first-principles derivations are present that reduce reported results to quantities defined by the method's own fitted parameters or self-citations. All central claims are direct experimental measurements on external datasets, making the evaluation chain independent of internal construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marginal con- trastive loss: A step forward for forward-forward
Hossein Aghagolzadeh and Mehdi Ezoji. Marginal con- trastive loss: A step forward for forward-forward. In2024 13th Iranian/3rd International Machine Vision and Image Processing Conference (MVIP), pages 1–6. IEEE, 2024. 2
2024
-
[2]
Forward-forward contrastive learning.arXiv preprint arXiv:2305.02927, 2023
Md Atik Ahamed, Jin Chen, and Abdullah-Al-Zubaer Im- ran. Forward-forward contrastive learning.arXiv preprint arXiv:2305.02927, 2023. 2
-
[3]
Deep learning without weight transport.Advances in neural information processing systems, 32, 2019
Mohamed Akrout, Collin Wilson, Peter Humphreys, Timo- thy Lillicrap, and Douglas B Tweed. Deep learning without weight transport.Advances in neural information processing systems, 32, 2019. 2
2019
-
[4]
Layer-wise learning framework for efficient dnn deployment in biomedical wear- able systems
Saleh Baghersalimi, Alireza Amirshahi, Tomas Teijeiro, Amir Aminifar, and David Atienza. Layer-wise learning framework for efficient dnn deployment in biomedical wear- able systems. In2023 IEEE 19th International Conference On Body Sensor Networks (BSN), pages 1–4. IEEE, 2023. 1
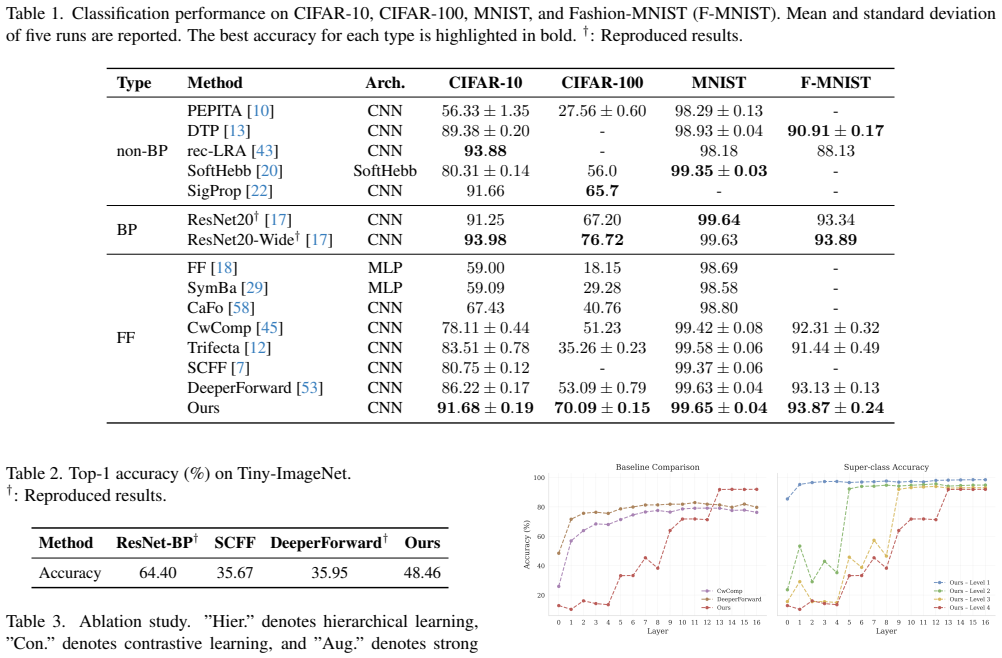
2023
-
[5]
Assessing the scalability of biologically-motivated deep learning algo- rithms and architectures.Advances in neural information processing systems, 31, 2018
Sergey Bartunov, Adam Santoro, Blake Richards, Luke Mar- ris, Geoffrey E Hinton, and Timothy Lillicrap. Assessing the scalability of biologically-motivated deep learning algo- rithms and architectures.Advances in neural information processing systems, 31, 2018. 1, 2
2018
-
[6]
How Auto-Encoders Could Provide Credit Assignment in Deep Networks via Target Propagation
Yoshua Bengio. How auto-encoders could provide credit assignment in deep networks via target propagation.arXiv preprint arXiv:1407.7906, 2014. 2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[7]
Self-contrastive forward-forward algorithm.Na- ture Communications, 16(1):5978, 2025
Xing Chen, Dongshu Liu, J ´er´emie Laydevant, and Julie Grollier. Self-contrastive forward-forward algorithm.Na- ture Communications, 16(1):5978, 2025. 1, 2, 5, 6
2025
-
[8]
An analysis of single-layer networks in unsupervised feature learning
Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 215–223. JMLR Workshop and Conference Proceedings, 2011. 2
2011
-
[9]
The recent excitement about neural networks
Francis Crick. The recent excitement about neural networks. Nature, 337(6203):129–132, 1989. 1
1989
-
[10]
Error-driven in- put modulation: solving the credit assignment problem with- out a backward pass
Giorgia Dellaferrera and Gabriel Kreiman. Error-driven in- put modulation: solving the credit assignment problem with- out a backward pass. InInternational Conference on Ma- chine Learning, pages 4937–4955. PMLR, 2022. 2, 5, 6
2022
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 4
2009
-
[12]
The trifecta: Three simple techniques for training deeper forward-forward networks
Thomas Dooms, Ing Jyh Tsang, and Jose Oramas. The tri- fecta: Three simple techniques for training deeper forward- forward networks.arXiv preprint arXiv:2311.18130, 2023. 1, 2, 5, 6
-
[13]
Towards scaling difference target propagation by learning backprop targets
Maxence M Ernoult, Fabrice Normandin, Abhinav Moudgil, Sean Spinney, Eugene Belilovsky, Irina Rish, Blake Richards, and Yoshua Bengio. Towards scaling difference target propagation by learning backprop targets. InInterna- tional Conference on Machine Learning, pages 5968–5987. PMLR, 2022. 1, 2, 5, 6
2022
-
[14]
Learn- ing without feedback: Fixed random learning signals allow for feedforward training of deep neural networks.Frontiers in neuroscience, 15:629892, 2021
Charlotte Frenkel, Martin Lefebvre, and David Bol. Learn- ing without feedback: Fixed random learning signals allow for feedforward training of deep neural networks.Frontiers in neuroscience, 15:629892, 2021. 2
2021
-
[15]
Investigating random variations of the forward-forward algorithm for training neural networks
Fabio Giampaolo, Stefano Izzo, Edoardo Prezioso, and Francesco Piccialli. Investigating random variations of the forward-forward algorithm for training neural networks. In 2023 International Joint Conference on Neural Networks (IJCNN), pages 1–7. IEEE, 2023. 2
2023
-
[16]
Competitive learning: From interactive activation to adaptive resonance.Cognitive science, 11(1): 23–63, 1987
Stephen Grossberg. Competitive learning: From interactive activation to adaptive resonance.Cognitive science, 11(1): 23–63, 1987. 1, 2
1987
-
[17]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 5, 6, 11
2016
-
[18]
The forward-forward algorithm: Some preliminary investigations
Geoffrey Hinton. The forward-forward algorithm: Some pre- liminary investigations.arXiv preprint arXiv:2212.13345, 2 (3):5, 2022. 1, 2, 5, 6
-
[19]
Decoupled neural interfaces using synthetic gradients
Max Jaderberg, Wojciech Marian Czarnecki, Simon Osin- dero, Oriol Vinyals, Alex Graves, David Silver, and Koray Kavukcuoglu. Decoupled neural interfaces using synthetic gradients. InInternational conference on machine learning, pages 1627–1635. PMLR, 2017. 1
2017
-
[20]
Hebbian deep learning without feed- back.arXiv preprint arXiv:2209.11883, 2022
Adrien Journ ´e, Hector Garcia Rodriguez, Qinghai Guo, and Timoleon Moraitis. Hebbian deep learning without feed- back.arXiv preprint arXiv:2209.11883, 2022. 1, 2, 5, 6
-
[21]
Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673,
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673,
-
[22]
Signal propagation: The framework for learning and infer- ence in a forward pass.IEEE Transactions on Neural Net- works and Learning Systems, 35(6):8585–8596, 2023
Adam Kohan, Edward A Rietman, and Hava T Siegelmann. Signal propagation: The framework for learning and infer- ence in a forward pass.IEEE Transactions on Neural Net- works and Learning Systems, 35(6):8585–8596, 2023. 1, 2, 5, 6
2023
-
[23]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 5
2009
-
[24]
Hebbian semi-supervised learning in a sample efficiency setting.Neural Networks, 143:719–731,
Gabriele Lagani, Fabrizio Falchi, Claudio Gennaro, and Giuseppe Amato. Hebbian semi-supervised learning in a sample efficiency setting.Neural Networks, 143:719–731,
-
[25]
Principled Training of Neural Networks with Direct Feedback Alignment
Julien Launay, Iacopo Poli, and Florent Krzakala. Principled training of neural networks with direct feedback alignment. arXiv preprint arXiv:1906.04554, 2019. 2
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[26]
Ya Le and Xuan S. Yang. Tiny imagenet visual recognition challenge. 2015. 5
2015
-
[27]
Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 2002
Yann LeCun, L ´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 2002. 5
2002
-
[28]
Difference target propagation
Dong-Hyun Lee, Saizheng Zhang, Asja Fischer, and Yoshua Bengio. Difference target propagation. InJoint european conference on machine learning and knowledge discovery in databases, pages 498–515. Springer, 2015. 2
2015
-
[29]
Heung-Chang Lee and Jeonggeun Song. Symba: Symmet- ric backpropagation-free contrastive learning with forward- forward algorithm for optimizing convergence.arXiv preprint arXiv:2303.08418, 2023. 2, 5, 6
-
[30]
Random synaptic feedback weights support error backpropagation for deep learning.Nature communications, 7(1):13276, 2016
Timothy P Lillicrap, Daniel Cownden, Douglas B Tweed, and Colin J Akerman. Random synaptic feedback weights support error backpropagation for deep learning.Nature communications, 7(1):13276, 2016. 2
2016
-
[31]
Backpropagation and the brain.Nature Reviews Neuroscience, 21(6):335–346, 2020
Timothy P Lillicrap, Adam Santoro, Luke Marris, Colin J Akerman, and Geoffrey Hinton. Backpropagation and the brain.Nature Reviews Neuroscience, 21(6):335–346, 2020. 1
2020
-
[32]
Sphereface: Deep hypersphere embedding for face recognition
Weiyang Liu, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song. Sphereface: Deep hypersphere embedding for face recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 212–220,
-
[33]
Layer collaboration in the forward- forward algorithm
Guy Lorberbom, Itai Gat, Yossi Adi, Alexander Schwing, and Tamir Hazan. Layer collaboration in the forward- forward algorithm. InProceedings of the AAAI Conference on Artificial Intelligence, pages 14141–14148, 2024. 2
2024
-
[34]
Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9 (Nov):2579–2605, 2008. 7
2008
-
[35]
Thomas Miconi. Hebbian learning with gradients: Hebbian convolutional neural networks with modern deep learning frameworks.arXiv preprint arXiv:2107.01729, 2021. 2
-
[36]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013. 4, 7
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[37]
Wordnet: a lexical database for english
George A Miller. Wordnet: a lexical database for english. Communications of the ACM, 38(11):39–41, 1995. 4, 7
1995
-
[38]
Softhebb: Bayesian inference in unsupervised hebbian soft winner-take-all networks.Neu- romorphic Computing and Engineering, 2(4):044017, 2022
Timoleon Moraitis, Dmitry Toichkin, Adrien Journ ´e, Yan- song Chua, and Qinghai Guo. Softhebb: Bayesian inference in unsupervised hebbian soft winner-take-all networks.Neu- romorphic Computing and Engineering, 2(4):044017, 2022. 2
2022
-
[39]
Direct feedback alignment provides learning in deep neural networks.Advances in neural information processing systems, 29, 2016
Arild Nøkland. Direct feedback alignment provides learning in deep neural networks.Advances in neural information processing systems, 29, 2016. 2
2016
-
[40]
The predictive forward-forward algorithm
Alexander Ororbia and Ankur Mali. The predictive forward- forward algorithm.arXiv preprint arXiv:2301.01452, 2023. 2
-
[41]
Brain-inspired machine intelligence: A survey of neurobiologically-plausible credit assignment
Alexander G Ororbia. Brain-inspired machine intelligence: A survey of neurobiologically-plausible credit assignment. arXiv preprint arXiv:2312.09257, 2023. 2
-
[42]
Biologically moti- vated algorithms for propagating local target representations
Alexander G Ororbia and Ankur Mali. Biologically moti- vated algorithms for propagating local target representations. InProceedings of the aaai conference on artificial intelli- gence, pages 4651–4658, 2019. 2
2019
-
[43]
Backpropagation-free deep learning with recur- sive local representation alignment
Alexander G Ororbia, Ankur Mali, Daniel Kifer, and C Lee Giles. Backpropagation-free deep learning with recur- sive local representation alignment. InProceedings of the AAAI conference on artificial intelligence, pages 9327–9335,
-
[44]
Graph neural networks go forward-forward.arXiv preprint arXiv:2302.05282, 2023
Daniele Paliotta, Mathieu Alain, B ´alint M´at´e, and Franc ¸ois Fleuret. Graph neural networks go forward-forward.arXiv preprint arXiv:2302.05282, 2023. 2
-
[45]
Convolutional channel- wise competitive learning for the forward-forward algorithm
Andreas Papachristodoulou, Christos Kyrkou, Stelios Timo- theou, and Theocharis Theocharides. Convolutional channel- wise competitive learning for the forward-forward algorithm. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 14536–14544, 2024. 1, 2, 3, 5, 6, 13
2024
-
[46]
Suitabil- ity of forward-forward and pepita learning to mlcommons- tiny benchmarks
Danilo Pietro Pau and Fabrizio Maria Aymone. Suitabil- ity of forward-forward and pepita learning to mlcommons- tiny benchmarks. In2023 IEEE International Conference on Omni-layer Intelligent Systems (COINS), pages 1–6. IEEE,
-
[47]
Forward- forward algorithm for hyperspectral image classification
Abel A Reyes-Angulo and Sidike Paheding. Forward- forward algorithm for hyperspectral image classification. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 3153–3161, 2024. 2
2024
-
[48]
Feature discovery by competitive learning.Cognitive science, 9(1):75–112, 1985
David E Rumelhart and David Zipser. Feature discovery by competitive learning.Cognitive science, 9(1):75–112, 1985. 2
1985
-
[49]
Learning representations by back-propagating er- rors.nature, 323(6088):533–536, 1986
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating er- rors.nature, 323(6088):533–536, 1986. 1
1986
-
[50]
Riccardo Scodellaro, Ajinkya Kulkarni, Frauke Alves, and Matthias Schr ¨oter. Training convolutional neural net- works with the forward-forward algorithm.arXiv preprint arXiv:2312.14924, 2023. 2
-
[51]
Competi- tive hebbian learning through spike-timing-dependent synap- tic plasticity.Nature neuroscience, 3(9):919–926, 2000
Sen Song, Kenneth D Miller, and Larry F Abbott. Competi- tive hebbian learning through spike-timing-dependent synap- tic plasticity.Nature neuroscience, 3(9):919–926, 2000. 2
2000
-
[52]
Ravi Srinivasan, Francesca Mignacco, Martino Sorbaro, Maria Refinetti, Avi Cooper, Gabriel Kreiman, and Gior- gia Dellaferrera. Forward learning with top-down feedback: Empirical and analytical characterization.arXiv preprint arXiv:2302.05440, 2023. 1, 2
-
[53]
Deeperforward: Enhanced forward- forward training for deeper and better performance
Liang Sun, Yang Zhang, Jiajun Wen, Linlin Shen, Weicheng Xie, and Weizhao He. Deeperforward: Enhanced forward- forward training for deeper and better performance. InInter- national Conference on Learning Representations, 2025. 1, 2, 3, 5, 6, 11, 12, 13
2025
-
[54]
Nbdt: Neural-backed decision trees.arXiv preprint arXiv:2004.00221,
Alvin Wan, Lisa Dunlap, Daniel Ho, Jihan Yin, Scott Lee, Henry Jin, Suzanne Petryk, Sarah Adel Bargal, and Joseph E Gonzalez. Nbdt: Neural-backed decision trees.arXiv preprint arXiv:2004.00221, 2020. 4, 13
-
[55]
Normface: L2 hypersphere embedding for face veri- fication
Feng Wang, Xiang Xiang, Jian Cheng, and Alan Loddon Yuille. Normface: L2 hypersphere embedding for face veri- fication. InProceedings of the 25th ACM international con- ference on Multimedia, pages 1041–1049, 2017
2017
-
[56]
Cosface: Large margin cosine loss for deep face recognition
Hao Wang, Yitong Wang, Zheng Zhou, Xing Ji, Dihong Gong, Jingchao Zhou, Zhifeng Li, and Wei Liu. Cosface: Large margin cosine loss for deep face recognition. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition, pages 5265–5274, 2018. 13
2018
-
[57]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion- mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[58]
The cascaded forward algorithm for neural network training.Pattern Recognition, 161:111292, 2025
Gongpei Zhao, Tao Wang, Yi Jin, Congyan Lang, Yidong Li, and Haibin Ling. The cascaded forward algorithm for neural network training.Pattern Recognition, 161:111292, 2025. 2, 5, 6 Table 6. Architectural configurations and training hyperparameters for all datasets. CIFAR-10 CIFAR-100 MNIST F-MNIST Tiny-ImageNet Channels per residual block [100, 200, 400, 8...
2025
-
[59]
Table 6 summarizes the full architectural configurations and training hyperparameters
Implementation Details For all experiments, we adopt a residual Forward-Forward (FF) architecture [53] consisting of four residual blocks. Table 6 summarizes the full architectural configurations and training hyperparameters. CIFAR-10 and CIFAR-100 use channel widths of[100,200,400,800]across the four residual blocks; MNIST and F-MNIST use lighter widths ...
-
[60]
In the FF setting, where gra- dients are not propagated across layers, residual shortcuts instead serve to fuse information across depths
Residual Shortcuts Residual structures are commonly used in backpropagation- based (BP) networks to ease optimization by providing gra- dient shortcut pathways [17]. In the FF setting, where gra- dients are not propagated across layers, residual shortcuts instead serve to fuse information across depths. Follow- ing DeeperForward [53], we adopt parameter-f...
-
[61]
Unlike BP-based models, which rely solely on the final layer’s logits, FF networks produce a goodness score at ev- ery layer
Signal Integrating and Pruning Module In this section, we elaborate on the Signal Integrating and Pruning (SIP) module introduced in DeeperForward [53]. Unlike BP-based models, which rely solely on the final layer’s logits, FF networks produce a goodness score at ev- ery layer. Each layer-wise goodness vectorg (ℓ) already en- codes partial class evidence ...
-
[62]
Following the Neural- Backed Decision Tree (NBDT) framework [54], we employ a data-driven procedure that derives a semantic hierarchy directly from a trained classifier
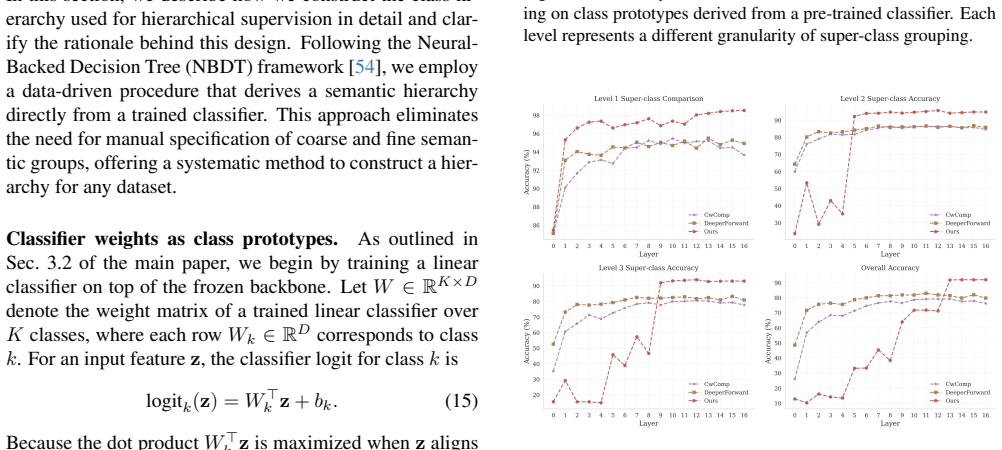
Building Hierarchies In this section, we describe how we construct the class hi- erarchy used for hierarchical supervision in detail and clar- ify the rationale behind this design. Following the Neural- Backed Decision Tree (NBDT) framework [54], we employ a data-driven procedure that derives a semantic hierarchy directly from a trained classifier. This a...
-
[63]
3 of the main paper, we further examine layer-wise accuracy at each hierarchy level, comparing against CwComp [45] and DeeperForward [53]
Super-class Accuracy To complement the per-layer analysis presented in Fig. 3 of the main paper, we further examine layer-wise accuracy at each hierarchy level, comparing against CwComp [45] and DeeperForward [53]. Figure 7 reports Level 1, Level 2, and Level 3 super-class accuracy, as well as overall fine-grained Figure 6. Hierarchy of CIFAR-10 classes c...
-
[64]
Figure 8 re- ports CIFAR-10 accuracy as a function of total parameter count
Model Efficiency To evaluate parameter efficiency, we compare HCL-FF with DeeperForward, along with BP-trained ResNet-20 and the parameter-matched ResNet-20-wide baseline. Figure 8 re- ports CIFAR-10 accuracy as a function of total parameter count. We evaluate four model capacities for both HCL-FF and DeeperForward, where the channel widths of the four re...
-
[65]
All models are trained for 150 epochs for a fair comparison
Learning Dynamics To further compare the convergence behavior of HCL-FF, DeeperForward, and standard backpropagation, we exam- ine their CIFAR-10 learning curves under a matched train- ing schedule. All models are trained for 150 epochs for a fair comparison. Figure 9 reports test accuracy across train- ing epochs. HCL-FF converges noticeably faster and t...
-
[66]
10 of the main paper, we evaluate two alternative strate- gies for assigning hierarchy levels across layers
Hierarchy Mapping In addition to the hierarchy mapping method described in Eq. 10 of the main paper, we evaluate two alternative strate- gies for assigning hierarchy levels across layers. Table 9. Effect of alternative hierarchy mapping strategies. Dataset Incremental Decremental Balanced CIFAR-100 Accuracy 70.30 68.40 70.76 Table 10. Effect of batch size...
-
[67]
HCL-FF demonstrates stable performance across a broad range, with accuracy varying by less than 0.5% between batch sizes of 32 and 512
Effect of Batch Size Table 10 shows the effect of batch size on CIFAR-10 per- formance. HCL-FF demonstrates stable performance across a broad range, with accuracy varying by less than 0.5% between batch sizes of 32 and 512. This indicates that the contrastive component of HCL-FF does not rely on ex- tremely large batches, in contrast to many contrastive l...
-
[68]
All models have comparable numbers of parameters and are trained for 200 epochs with a batch size of 512, ensuring fair model size and equal numbers of weight updates
Computational Cost To demonstrate the computational aspect of HCL-FF, we compare HCL-FF against a BP-trained ResNet variant and DeeperForward under matched training conditions. All models have comparable numbers of parameters and are trained for 200 epochs with a batch size of 512, ensuring fair model size and equal numbers of weight updates. For HCL-FF, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.