SEED: Semi-supervised Continual MalwarE Detection for Tackling ConcEpt Drift on a BuDget
Pith reviewed 2026-06-30 00:15 UTC · model grok-4.3
The pith
SEED detects unseen malware using only 20 percent labeled data on prior tasks by projecting samples into an SVD-derived representation space and selecting uncertain ones via cosine distance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
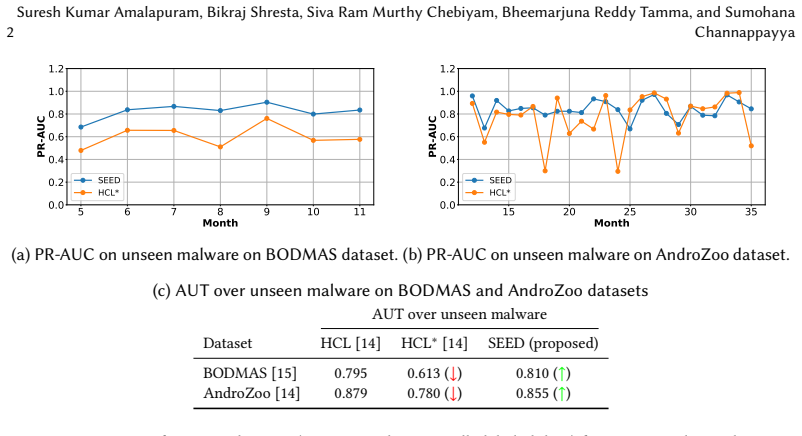
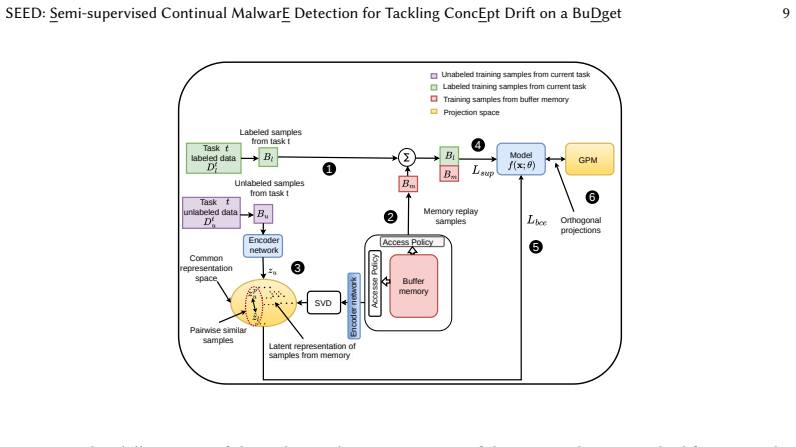
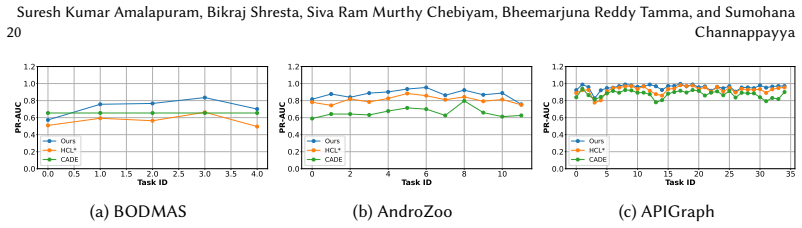
SEED is a semantic-structure-agnostic approach that combines a tailored binary cross-entropy loss with semi-supervised continual learning and active learning; unlabeled samples from seen tasks are projected via singular value decomposition into a space built from prior data to encourage consistency, while cosine distance in that space quantifies uncertainty to select samples for labeling on unseen tasks, yielding 40 percent AUT gains on BODMAS and 14 percent on AndroZoo with 20 percent labeled data relative to the semi-supervised baseline.
What carries the argument
The SVD-constructed representation space from previously seen data, which projects unlabeled samples for consistency on seen tasks and supplies cosine-distance uncertainty scores for active learning on unseen tasks.
If this is right
- SEED remains competitive with the baseline on APIGraph while improving on BODMAS and AndroZoo under 20 percent labeling.
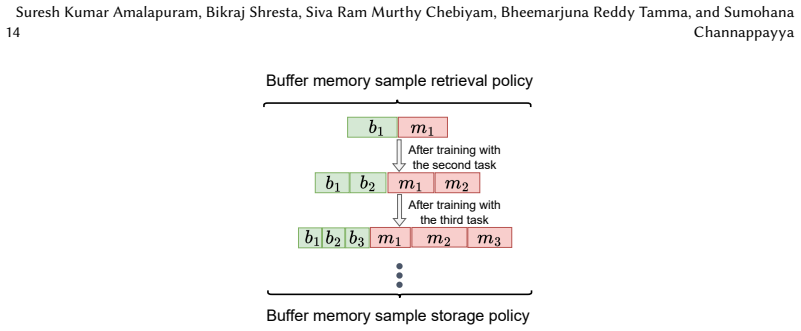
- A delayed buffer update reduces label noise propagation during replay and improves learning stability across tasks.
- The same pipeline applies to both Windows and Android malware datasets under partial and full unlabeled settings.
- Active learning on unseen tasks uses only the representation space built from seen tasks, avoiding the need for semantic structure assumptions.
Where Pith is reading between the lines
- The projection-and-distance mechanism might transfer to other continual-learning settings that face concept drift with scarce labels, such as network intrusion detection.
- Lowering the labeled fraction below 20 percent on seen tasks would test how far the SVD consistency signal can be stretched before performance collapses.
- Combining the delayed buffer update with other replay strategies could further stabilize training when label noise is high.
- The method's reliance on a single fixed representation space raises the question of how often that space must be rebuilt as the number of seen tasks grows.
Load-bearing premise
Unlabeled samples can be projected into an SVD-built space from earlier tasks to produce reliable consistency and uncertainty signals.
What would settle it
An experiment that replaces the SVD-derived space with random vectors or replaces cosine-distance selection with random selection and measures whether the reported AUT improvements on BODMAS and AndroZoo disappear.
Figures


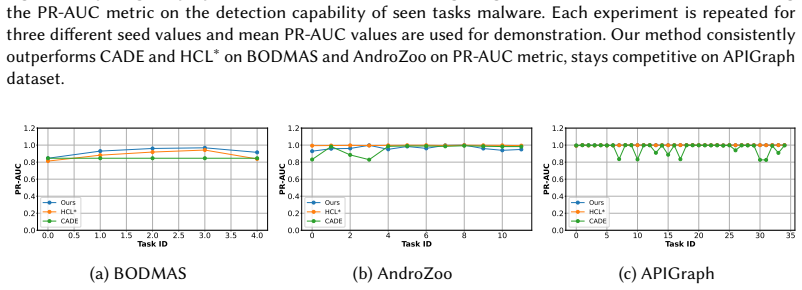
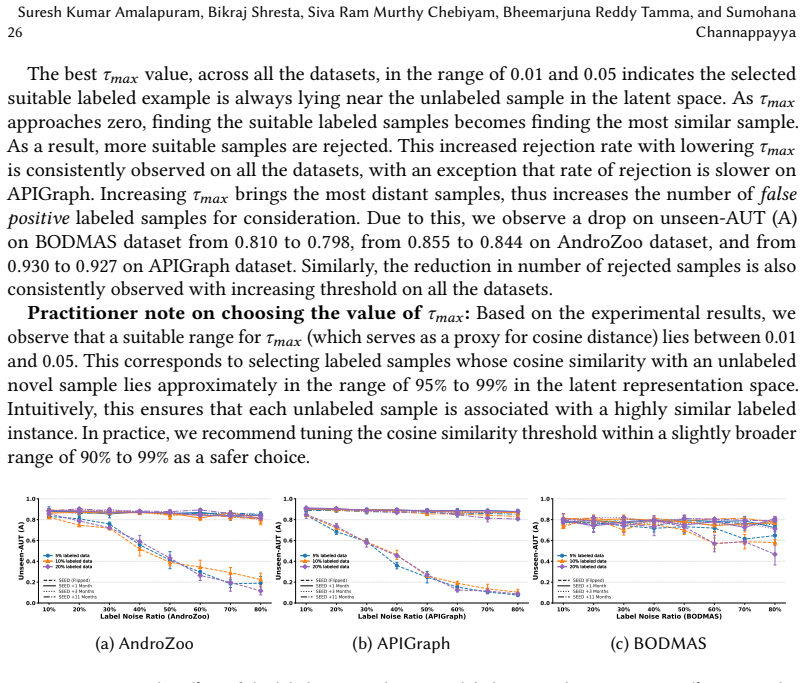
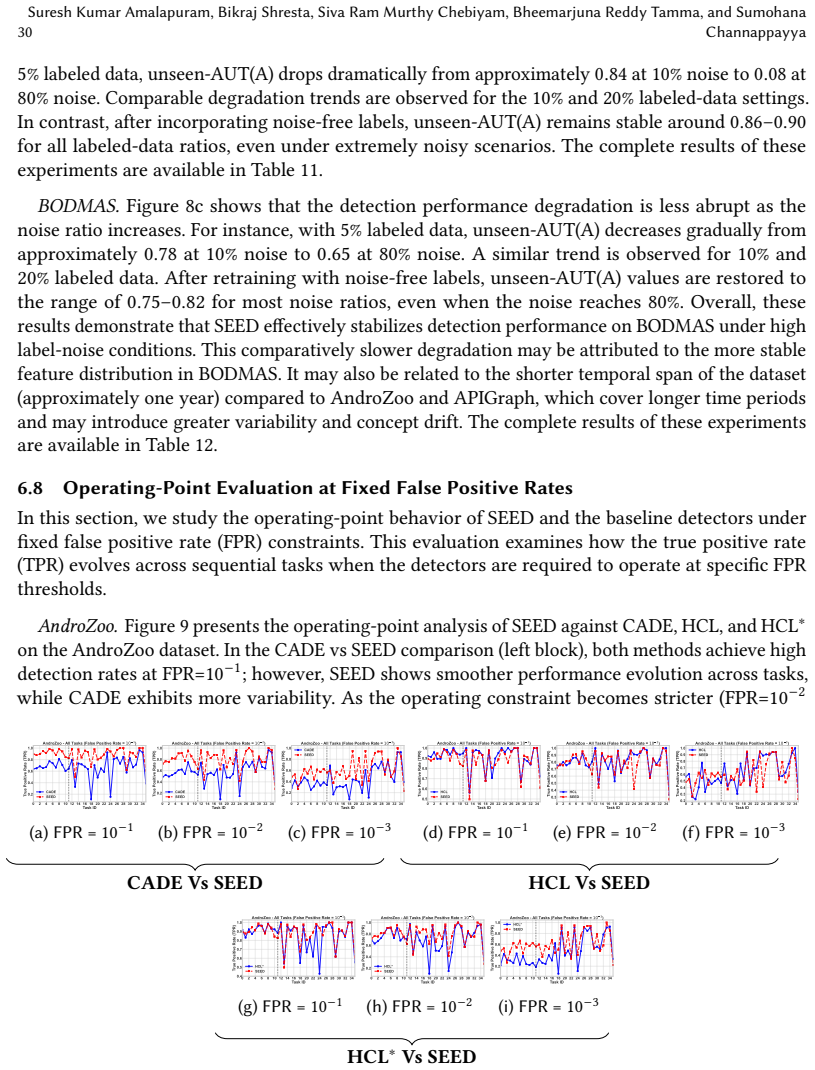
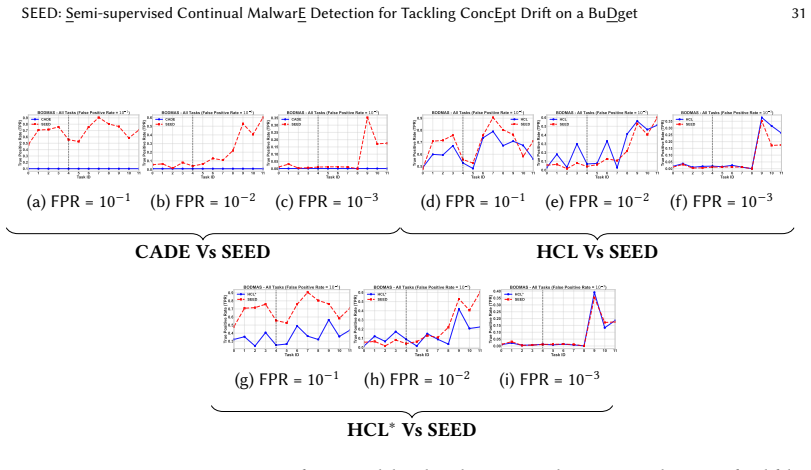
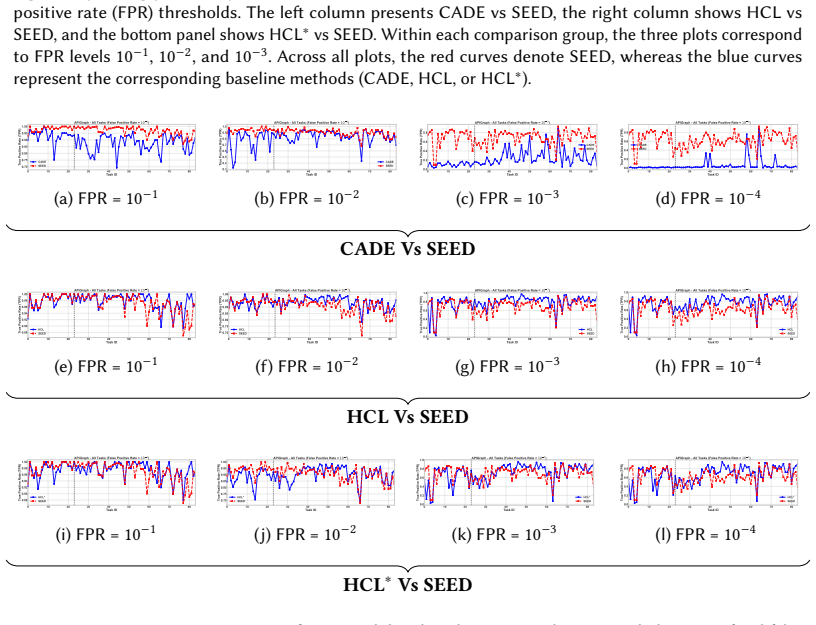


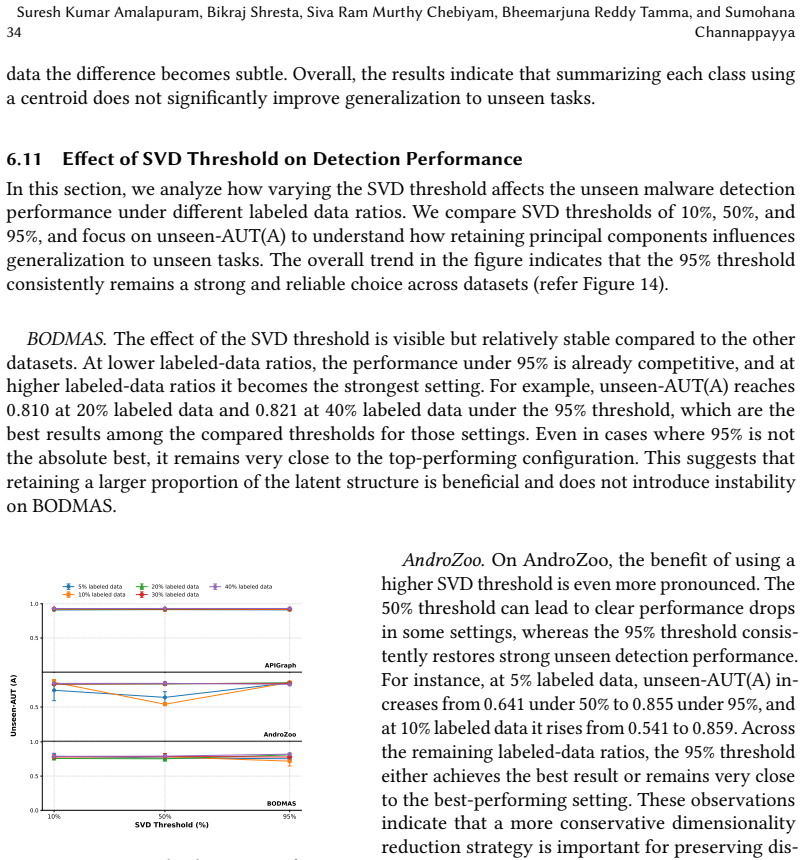
read the original abstract
Machine learning based malware detectors become obsolete over time due to concept drift in benign and malware applications. Recent methods rely on fully labeled data and use hierarchical contrastive loss (HCL) with active learning to improve robustness against drift by exploiting semantic structure in malware representations. However, obtaining labeled data in the security domain is difficult. Under partially labeled settings, HCL suffers significant performance degradation in detecting unseen malware, especially on datasets such as BODMAS where strong semantic structure may not exist. In this paper, we propose SEED, a semantic-structure-agnostic method for malware detection under limited supervision. SEED combines a tailored binary cross-entropy objective with semi-supervised continual learning and active learning. For partially labeled seen tasks, unlabeled samples are projected into a representation space constructed from previously seen data using singular value decomposition, and paired with suitable labeled samples to encourage representation consistency. For unseen tasks with fully unlabeled data, uncertainty is quantified using cosine distance in representation space, and the most uncertain samples are selected for analyst labeling. We evaluate SEED on both Windows and Android malware datasets. Using only 20% labeled data on seen tasks, SEED achieves average AUT improvements of 40% on BODMAS and 14% on AndroZoo for unseen malware detection compared to HCL* (the semi-supervised adaptation of HCL), while remaining competitive on APIGraph. Finally, we introduce a delayed buffer update strategy to reduce label noise propagation during replay and improve learning stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SEED, a semantic-structure-agnostic method for semi-supervised continual malware detection under concept drift and limited labels. It augments a binary cross-entropy objective with semi-supervised continual learning and active learning: unlabeled samples from partially labeled seen tasks are projected via SVD into a representation space derived from prior data to enforce consistency, while fully unlabeled unseen tasks use cosine-distance uncertainty sampling for active labeling. A delayed buffer update is added to mitigate label noise in replay. On BODMAS, AndroZoo, and APIGraph, SEED with 20% labeled data on seen tasks reports average AUT gains of 40% and 14% over the semi-supervised HCL* baseline for unseen malware detection (competitive on APIGraph).
Significance. If the empirical gains prove robust, the work is significant for security ML because it directly targets the high cost of labeling and the rapid obsolescence of detectors due to drift. The SVD-projection and cosine-distance mechanisms provide a lightweight way to leverage unlabeled data without requiring strong semantic structure, and the delayed-buffer heuristic addresses a practical stability issue in replay-based continual learning. These elements could inform future semi-supervised continual-learning pipelines in adversarial domains.
minor comments (2)
- [Abstract] Abstract: performance numbers (40% and 14% AUT) are stated without reference to the number of runs, error bars, dataset splits, or the precise definition of AUT; the main text should make these details immediately locatable (e.g., via a dedicated experimental-setup subsection or table footnote).
- The stylized title capitalization (SEED, MalwarE, ConcEpt, BuDget) is a minor distraction for citation and indexing; consider a conventional title or a parenthetical expansion on first use.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the work's significance in security ML, and recommendation for minor revision. No specific major comments were listed in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an empirical semi-supervised continual learning method (SEED) that combines binary cross-entropy loss with SVD-based projection for representation consistency on partially labeled seen tasks and cosine-distance uncertainty sampling for active learning on unseen tasks. Performance claims rest on direct empirical comparisons to an externally adapted baseline (HCL*) across independent datasets (BODMAS, AndroZoo, APIGraph) under 20% labeling. No equations, predictions, or uniqueness claims reduce to self-definition, fitted inputs renamed as outputs, or load-bearing self-citations. The construction is self-contained against external benchmarks with no internal reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Unlabeled samples can be projected into an SVD-derived representation space from seen data to encourage consistency with labeled samples.
- domain assumption Cosine distance in the representation space quantifies sample uncertainty for selecting labels on unseen tasks.
Reference graph
Works this paper leans on
-
[1]
Imagenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. “Imagenet classification with deep convolutional neural networks”. In:in Proceedings of the Advances in Neural Information Processing Systems25 (2012)
2012
-
[2]
Attention is All you Need
Ashish Vaswani et al. “Attention is All you Need”. In:Proceedings of the Advances in Neural Information Processing Systems. Vol. 30. 2017
2017
-
[3]
https://media.kaspersky.com/en/enterprise- security/KasperskyLab-Whitepaper-Machine-Learning.pdf
Kaspersky Lab Whitepaper Machine Learning. https://media.kaspersky.com/en/enterprise- security/KasperskyLab-Whitepaper-Machine-Learning.pdf. [4]Themida - Advanced Windows Software Protection. https://www.oreans.com/Themida.php
-
[4]
https://www.oreans.com/ CodeVirtualizer.php
CodeVirtualizer - Obfuscation System Against Reverse Engineering. https://www.oreans.com/ CodeVirtualizer.php
-
[5]
Drift Forensics of Malware Classifiers
Theo Chow et al. “Drift Forensics of Malware Classifiers”. In:Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec). 2023, pp. 197–207. , Vol. 1, No. 1, Article . Publication date: May 2026. 40 Suresh Kumar Amalapuram, Bikraj Shresta, Siva Ram Murthy Chebiyam, Bheemarjuna Reddy Tamma, and Sumohana Channappayya
2023
-
[6]
Robust semi-supervised learning when not all classes have labels
Lan-Zhe Guo et al. “Robust semi-supervised learning when not all classes have labels”. In:in Proceedings of the Advances in Neural Information Processing Systems35 (2022), pp. 3305–3317
2022
-
[7]
Open-World Semi-Supervised Learning
Kaidi Cao, Maria Brbic, and Jure Leskovec. “Open-World Semi-Supervised Learning”. In: Proceedings of the International Conference on Learning Representations. 2022.url: https: //openreview.net/forum?id=O-r8LOR-CCA
2022
-
[8]
A comprehensive survey of continual learning: Theory, method and application
Liyuan Wang et al. “A comprehensive survey of continual learning: Theory, method and application”. In:IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2024), pp. 1–20
2024
-
[9]
Gradient episodic memory for continual learn- ing
David Lopez-Paz and Marc’Aurelio Ranzato. “Gradient episodic memory for continual learn- ing”. In:Proceedings of 31st Conference on Advances in Neural Information Processing Systems (NeurIPS). Vol. 30. 2017, pp. 6470–6479
2017
-
[10]
Efficient Lifelong Learning with A-GEM
Arslan Chaudhry et al. “Efficient lifelong learning with a-gem”. In:arXiv preprint arXiv:1812.00420 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Gradient based sample selection for online continual learning
Rahaf Aljundi et al. “Gradient based sample selection for online continual learning”. In: Proceeding of 33rd Conference on Neural Information Processing Systems (NeurIPS). Vol. 32. 2019
2019
-
[12]
Online continual learning from imbalanced data
Aristotelis Chrysakis and Marie-Francine Moens. “Online continual learning from imbalanced data”. In:Proceeding of 37th International Conference on Machine Learning (ICML). 2020, pp. 1952–1961
2020
-
[13]
Continuous Learning for Android Malware Detection
Yizheng Chen, Zhoujie Ding, and David Wagner. “Continuous Learning for Android Malware Detection”. In:Proceedings of the 32nd USENIX Security Symposium (USENIX Security). Aug. 2023, pp. 1127–1144
2023
-
[14]
BODMAS: An open dataset for learning based temporal analysis ofPE malware
Limin Yang et al. “BODMAS: An open dataset for learning based temporal analysis ofPE malware”. In:2021 IEEE Security and Privacy Workshops (SPW). 2021, pp. 78–84
2021
-
[15]
Drebin: Effective and explainable detection of android malware in your pocket
Daniel Arp et al. “Drebin: Effective and explainable detection of android malware in your pocket.” In:Proceedings of the Network and Distributed Systems Security (NDSS) Symposium. Vol. 14. 2014, pp. 23–26
2014
-
[16]
TESSERACT: Eliminating experimental bias in malware classifica- tion across space and time
Feargus Pendlebury et al. “TESSERACT: Eliminating experimental bias in malware classifica- tion across space and time”. In:Proceedings of the 28th USENIX Security Symposium (USENIX Security). 2019, pp. 729–746
2019
-
[17]
CADE: Detecting and explaining concept drift samples for security appli- cations
Limin Yang et al. “CADE: Detecting and explaining concept drift samples for security appli- cations”. In:30th USENIX Security Symposium (USENIX Security 21). 2021, pp. 2327–2344
2021
-
[18]
From grim reality to practical solution: Malware classification in real-world noise
Xian Wu et al. “From grim reality to practical solution: Malware classification in real-world noise”. In:Proceedings of the IEEE Symposium on Security and Privacy (SP). 2023, pp. 2602– 2619
2023
-
[19]
On the limitations of contin- ual learning for malware classification
Mohammad Saidur Rahman, Scott Coull, and Matthew Wright. “On the limitations of contin- ual learning for malware classification”. In:Proceedings of the First Conference on Lifelong Learning Agents (CoLLAs). 2022, pp. 564–582
2022
-
[20]
Reviewer integration and performance measurement for malware detec- tion
Brad Miller et al. “Reviewer integration and performance measurement for malware detec- tion”. In:Proceedings of the Detection of Intrusions and Malware, and Vulnerability Assessment (DIMV A). 2016, pp. 122–141
2016
-
[21]
Error prevalence in nids datasets: A case study on cic-ids-2017 and cse-cic- ids-2018
Lisa Liu et al. “Error prevalence in nids datasets: A case study on cic-ids-2017 and cse-cic- ids-2018”. In:Proceedings of IEEE Conference on Communications and Network Security (CNS). 2022, pp. 254–262
2017
-
[22]
Springer Nature, 2022
Xiaojin Zhu and Andrew B Goldberg.Introduction to semi-supervised learning. Springer Nature, 2022
2022
-
[23]
Transcend: Detecting concept drift in malware classification models
Roberto Jordaney et al. “Transcend: Detecting concept drift in malware classification models”. In:26th USENIX security symposium (USENIX security 17). 2017, pp. 625–642. , Vol. 1, No. 1, Article . Publication date: May 2026. SEED: Semi-supervised Continual MalwarE Detection for Tackling ConcEpt Drift on a BuDget 41
2017
-
[24]
Anomaly Detection in the Open World: Normality Shift Detection, Explanation, and Adaptation
Dongqi Han et al. “Anomaly Detection in the Open World: Normality Shift Detection, Explanation, and Adaptation”. In:Proceeding of Network and Distributed System Security Symposium (NDSS). 2023
2023
-
[25]
Transcending transcend: Revisiting malware classification in the presence of concept drift
Federico Barbero et al. “Transcending transcend: Revisiting malware classification in the presence of concept drift”. In:2022 IEEE Symposium on Security and Privacy (SP). 2022, pp. 805–823
2022
-
[26]
ReCDA: Concept Drift Adaptation with Representation Enhancement for Network Intrusion Detection
Shuo Yang et al. “ReCDA: Concept Drift Adaptation with Representation Enhancement for Network Intrusion Detection”. In:Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2024, pp. 3818–3828
2024
-
[27]
Detecting and Mitigating Sampling Bias in Cybersecu- rity with Unlabeled Data
Saravanan Thirumuruganathan et al. “Detecting and Mitigating Sampling Bias in Cybersecu- rity with Unlabeled Data”. In:33rd USENIX Security Symposium (USENIX Security 24). 2024, pp. 1741–1758
2024
-
[28]
Insomnia: Towards concept-drift robustness in network intrusion detection
Giuseppina Andresini et al. “Insomnia: Towards concept-drift robustness in network intrusion detection”. In:Proceedings of the 14th ACM Workshop on Artificial Intelligence and Security. 2021, pp. 111–122
2021
-
[29]
Droidevolver: Self-evolving android malware detection system
Ke Xu et al. “Droidevolver: Self-evolving android malware detection system”. In:2019 IEEE European Symposium on Security and Privacy (EuroS&P). IEEE. 2019, pp. 47–62
2019
-
[30]
Investigating labelless drift adaptation for malware detection
Zeliang Kan et al. “Investigating labelless drift adaptation for malware detection”. In:Pro- ceedings of the 14th ACM Workshop on Artificial Intelligence and Security. 2021, pp. 123– 134
2021
-
[31]
Application of Anomaly Detection Models to Malware Detection in the Presence of Concept Drift
David Escudero García and Noemí DeCastro-García. “Application of Anomaly Detection Models to Malware Detection in the Presence of Concept Drift”. In:International Conference on Hybrid Artificial Intelligence Systems. Springer. 2023, pp. 15–26
2023
-
[32]
Vime: Extending the success of self-and semi-supervised learning to tabular domain
Jinsung Yoon et al. “Vime: Extending the success of self-and semi-supervised learning to tabular domain”. In:Advances in Neural Information Processing Systems33 (2020), pp. 11033– 11043
2020
-
[33]
When Adversarial Perturbations meet Concept Drift: an Exploratory Analysis on ML-NIDS
Giovanni Apruzzese, Aurore Fass, and Fabio Pierazzi. “When Adversarial Perturbations meet Concept Drift: an Exploratory Analysis on ML-NIDS”. In:The 17th ACM Workshop on Artificial Intelligence Security (AISec). 2024
2024
-
[34]
Pseudo-Labeling for Class Incremental Learning
Alexis Lechat, Stéphane Herbin, and Frédéric Jurie. “Pseudo-Labeling for Class Incremental Learning”. In:Proceedings of the 32nd British Machine Vision Conference (BMVC). 2021
2021
-
[35]
Ordisco: Effective and efficient usage of incremental unlabeled data for semi-supervised continual learning
Liyuan Wang et al. “Ordisco: Effective and efficient usage of incremental unlabeled data for semi-supervised continual learning”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2021, pp. 5383–5392
2021
-
[36]
SPIDER: A Semi-Supervised Continual Learning-based Network Intrusion Detection System
Suresh K. Amalapuram, Bheemarjuna Tamma, and Sumohana S. Channappayya. “SPIDER: A Semi-Supervised Continual Learning-based Network Intrusion Detection System”. In: Proceedings of the 43rd IEEE Conference on Computer Communications (IEEE INFOCOM). 2024, pp. 571–580
2024
-
[37]
Learning Multiple Layers of Features from Tiny Images
A. Krizhevsky. “Learning Multiple Layers of Features from Tiny Images”. In:Master’s Thesis, University of Toronto(2009).url: https://www.cs.utoronto.ca/~kriz/learning-features-2009- TR.pdf
2009
-
[38]
Imbalanced malware family classification using multimodal fusion and weight self-learning
Shudong Li et al. “Imbalanced malware family classification using multimodal fusion and weight self-learning”. In:IEEE Transactions on Intelligent Transportation Systems24.7 (2022), pp. 7642–7652
2022
-
[39]
Enhancing state-of-the-art classifiers with api semantics to detect evolved android malware
Xiaohan Zhang et al. “Enhancing state-of-the-art classifiers with api semantics to detect evolved android malware”. In:Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security. 2020, pp. 757–770. [41]AndroZoo. https://androzoo.uni.lu/.. , Vol. 1, No. 1, Article . Publication date: May 2026. 42 Suresh Kumar Amalapuram, Bikraj S...
2020
-
[40]
EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models
H. S. Anderson and P. Roth. “EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models”. In:ArXiv e-prints(Apr. 2018). arXiv: 1804.04637[cs.CR]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Aug- mented Memory Replay-based Continual Learning Approaches for Network Intrusion Detec- tion
Suresh Kumar Amalapuram, Sumohana S. Channappayya, and Bheemarjuna Tamma. “Aug- mented Memory Replay-based Continual Learning Approaches for Network Intrusion Detec- tion”. In:Proceedings of 37th Conference on Neural Information Processing Systems (NeurIPS). Vol. 36. 2023
2023
-
[42]
A theoretical analysis of the learning dynamics under class imbalance
Emanuele Francazi, Marco Baity-Jesi, and Aurelien Lucchi. “A theoretical analysis of the learning dynamics under class imbalance”. In:International Conference on Machine Learning. PMLR. 2023, pp. 10285–10322
2023
-
[43]
Gradient reweighting: Towards imbalanced class-incremental learning
Jiangpeng He. “Gradient reweighting: Towards imbalanced class-incremental learning”. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024, pp. 16668–16677
2024
-
[44]
Orthogonal gradient descent for continual learning
Mehrdad Farajtabar et al. “Orthogonal gradient descent for continual learning”. In:Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS). 2020, pp. 3762–3773
2020
-
[45]
Gradient Projection Memory for Continual Learning
Gobinda Saha, Isha Garg, and Kaushik Roy. “Gradient Projection Memory for Continual Learning”. In:Proceedings of the International Conference on Learning Representations (ICLR). 2020
2020
-
[46]
Rethinking Gradient Projection Continual Learning: Stability/Plasticity Feature Space Decoupling
Zhen Zhao et al. “Rethinking Gradient Projection Continual Learning: Stability/Plasticity Feature Space Decoupling”. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2023, pp. 3718–3727
2023
-
[47]
Re-measuring the label dynamics of online anti-malware engines from millions of samples
Jingjing Wang et al. “Re-measuring the label dynamics of online anti-malware engines from millions of samples”. In:Proceedings of the 2023 ACM on Internet Measurement Conference. 2023, pp. 253–267
2023
-
[48]
Measuring and Modeling the Label Dynamics of Online Anti-Malware Engines
Shuofei Zhu et al. “Measuring and Modeling the Label Dynamics of Online Anti-Malware Engines”. In:29th USENIX Security Symposium (USENIX Security 20). USENIX Association, Aug. 2020, pp. 2361–2378.isbn: 978-1-939133-17-5.url: https://www.usenix.org/conference/ usenixsecurity20/presentation/zhu
2020
-
[49]
Towards more realistic evaluations: The impact of label delays in malware detection pipelines
Marcus Botacin and Heitor Gomes. “Towards more realistic evaluations: The impact of label delays in malware detection pipelines”. In:Computers & Security148 (2025), p. 104122
2025
-
[50]
Overcoming catastrophic forgetting in neural networks
James Kirkpatrick et al. “Overcoming catastrophic forgetting in neural networks”. In:National Academy of Sciences114.13 (2017), pp. 3521–3526
2017
-
[51]
Online continual learning with maximal interfered retrieval
Rahaf Aljundi et al. “Online continual learning with maximal interfered retrieval”. In:Pro- ceeding of 33rd Conference on Neural Information Processing Systems (NeurIPS). Vol. 32. 2019
2019
-
[52]
Dos and don’ts of machine learning in computer security
Daniel Arp et al. “Dos and don’ts of machine learning in computer security”. In:Proceeding of 31st USENIX Security Symposium (USENIX Security). 2022
2022
-
[53]
AnoShift: A distribution shift benchmark for unsupervised anomaly de- tection
Marius Dragoi et al. “AnoShift: A distribution shift benchmark for unsupervised anomaly de- tection”. In:Proceeding of 36th Conference on Neural Information Processing Systems (NeurIPS). Vol. 35. 2022, pp. 32854–32867. , Vol. 1, No. 1, Article . Publication date: May 2026
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.