Large Language Model Selection with Limited Annotations
Pith reviewed 2026-06-30 12:11 UTC · model grok-4.3
The pith
SELECT-LLM selects a minimal set of queries to annotate so the best LLM for a task can be identified with far lower labeling cost than full evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SELECT-LLM finds a small set of queries whose annotations are most informative for identifying the best LLM by using a query selection rule based on expected information gain computed from pairwise similarities between candidate model outputs, and this rule works without any assumptions on model architecture or access to weights.
What carries the argument
The query selection rule based on expected information gain computed from pairwise similarities between candidate model outputs
If this is right
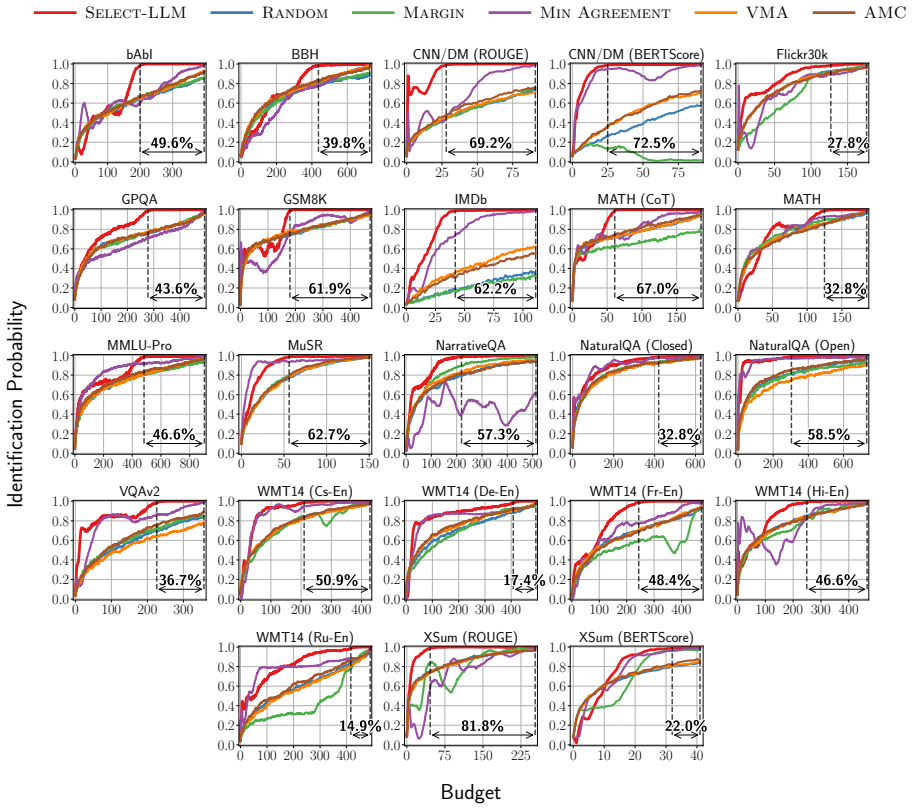
- Best-model identification requires up to 81.8 percent fewer annotations than exhaustive evaluation.
- Near-best model identification requires up to 84.78 percent fewer annotations.
- The same selection procedure improves over the strongest baseline in every tested setting.
- The procedure applies equally to open-weight and black-box LLMs because it uses only generated responses.
- The approach scales to diverse task families and multiple text evaluation metrics.
Where Pith is reading between the lines
- The similarity-based selection rule might also reduce labeling cost when the goal is to rank models rather than pick only the single best one.
- If model outputs become more correlated, the information-gain calculation could select fewer queries before the ranking stabilizes.
- Combining the method with cheap proxy metrics computed before any human annotation could further lower the total cost.
- The framework could be tested on tasks where the evaluation metric itself changes with the chosen model.
Load-bearing premise
The query selection rule based on expected information gain computed from pairwise similarities between candidate model outputs is effective for identifying the best LLM without assumptions about their architecture or access to model weights.
What would settle it
A controlled run on a fresh collection of models and tasks where the queries chosen by SELECT-LLM produce a final model ranking that differs from the ranking obtained after full annotation would falsify the central claim.
Figures

read the original abstract
Choosing a Large Language Model (LLM) for a given task requires comparing many strong candidates, yet standard evaluation relies on costly annotations over fixed evaluation sets. To address this challenge, we develop SELECT-LLM, the first framework for active model selection of LLMs. SELECT-LLM aims to find a small set of queries whose annotations are most informative for identifying the best LLM for a given task. To this end, we introduce a query selection rule based on expected information gain, computed from pairwise similarities between candidate model outputs. Because this rule only uses generated model responses, SELECT-LLM can be applied across candidate models without assumptions about their architecture or access to model weights. This makes it suitable for both open-weight and black-box LLMs. We evaluate SELECT-LLM across 23 datasets, 156 evaluated models, diverse task families, and multiple text evaluation metrics. Across all experiments, SELECT-LLM improves over the strongest baseline in every setting, with annotation cost reductions up to 81.8% for best model selection and up to 84.78% for near-best model selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SELECT-LLM, the first active model selection framework for LLMs. It selects a small set of queries for annotation using a rule based on expected information gain computed from pairwise similarities between candidate model outputs. The method requires only generated responses and applies to both open-weight and black-box models without architectural assumptions. Experiments across 23 datasets and 156 models show consistent outperformance over the strongest baseline in every setting, with annotation cost reductions up to 81.8% for best-model selection and 84.78% for near-best selection.
Significance. If the results hold, the work is significant for practical LLM evaluation: it directly tackles the high cost of comparing many strong models by minimizing required annotations while remaining applicable to black-box APIs. The scale of the evaluation (23 datasets, 156 models, multiple task families and metrics) and the explicit use of only generated outputs are strengths that support generalizability. The approach is internally consistent with its stated goal and avoids self-referential parameter fitting.
major comments (2)
- [§3] §3 (method): the exact formula for expected information gain and the definition of pairwise similarity (e.g., exact match vs. embedding-based) must be stated with equations; without them the central claim that the selection rule is effective cannot be verified or reproduced from the generated responses alone.
- [Results section] Results section / Table 2 or equivalent: the claim of improvement 'in every setting' requires reporting the annotation budget (number of queries) per experiment and either standard deviations across runs or statistical tests; the current high-level summary leaves the magnitude and reliability of the 81.8% / 84.78% reductions unquantified.
minor comments (2)
- Add a short related-work paragraph contrasting SELECT-LLM with prior active-learning or query-selection methods for model comparison to substantiate the 'first framework' claim.
- Ensure all figures reporting cost reductions label the exact baseline, the metric used for 'near-best', and the number of models/datasets per panel for immediate readability.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and helpful suggestions. We address the two major comments below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [§3] §3 (method): the exact formula for expected information gain and the definition of pairwise similarity (e.g., exact match vs. embedding-based) must be stated with equations; without them the central claim that the selection rule is effective cannot be verified or reproduced from the generated responses alone.
Authors: We agree that the exact formulas are required for full reproducibility. In the revised version we will insert the precise mathematical definitions of expected information gain and the pairwise similarity function (including whether exact match or embedding-based) as equations in §3. revision: yes
-
Referee: [Results section] Results section / Table 2 or equivalent: the claim of improvement 'in every setting' requires reporting the annotation budget (number of queries) per experiment and either standard deviations across runs or statistical tests; the current high-level summary leaves the magnitude and reliability of the 81.8% / 84.78% reductions unquantified.
Authors: We accept this point. The revised results section will report the exact annotation budget (number of queries) for each experiment together with standard deviations across runs or the results of statistical significance tests, thereby quantifying the reported cost reductions. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces SELECT-LLM as an empirical active selection procedure that computes expected information gain directly from pairwise similarities of generated model outputs on candidate queries. This computation operates on external data (model responses) without reducing any claimed prediction or selection rule to a fitted parameter or self-referential definition. No load-bearing self-citation, ansatz smuggling, or renaming of known results appears in the provided description; the central claim of annotation-cost reduction is presented as an empirical outcome across datasets and models rather than a mathematical identity derived from the method's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pairwise similarities between candidate model outputs can be used to compute expected information gain that identifies the most informative queries for best-model selection
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, S´ebastien Bubeck, Martin Cai, Caio C´esar Teodoro Mendes, Weizhu Chen, Vishrav Chaudhary , Parul Chopra, Allie Del Giorno, Gustavo de Rosa, Matthew Dixon, Ronen El...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Jurassic-1: Technical details and evaluation.https://www.ai21.com/blog/ announcing-ai21-studio-and-jurassic-1, 2021
AI21 Labs. Jurassic-1: Technical details and evaluation.https://www.ai21.com/blog/ announcing-ai21-studio-and-jurassic-1, 2021
2021
-
[3]
Luminous.https://docs.aleph-alpha.com/docs/introduction/luminous/
Aleph Alpha. Luminous.https://docs.aleph-alpha.com/docs/introduction/luminous/
-
[4]
The Falcon Series of Open Language Models
Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, M´erouane Debbah, ´Etienne Goffinet, Daniel Hesslow, Julien Launay , Quentin Malartic, et al. The falcon series of open language models.arXiv preprint arXiv:2311.16867, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, et al. Palm 2 technical report.arXiv preprint arXiv:2305.10403, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Anthropic claude api.https://console.anthropic.com
Anthropic. Anthropic claude api.https://console.anthropic.com
-
[7]
Model card and evaluations for claude models, 2023
Anthropic. Model card and evaluations for claude models, 2023
2023
-
[8]
Introducing the next generation of claude, 2024
Anthropic. Introducing the next generation of claude, 2024
2024
-
[9]
Introducing Claude Opus 4.7.https://www.anthropic.com/news/claude-opus-4-7,
Anthropic. Introducing Claude Opus 4.7.https://www.anthropic.com/news/claude-opus-4-7,
-
[10]
Accessed: 2026-05-02
2026
-
[11]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Scaling up active testing to large language models.arXiv preprint arXiv:2508.09093, 2025
Gabrielle Berrada, Jannik Kossen, Muhammed Razzak, Freddie Bickford Smith, Yarin Gal, and Tom Rainforth. Scaling up active testing to large language models.arXiv preprint arXiv:2508.09093, 2025. 11
-
[14]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, Andre Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony , Herbie Bradley , Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling.arXiv preprint arXiv:2304.01373, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony , Leo Gao, Laurence Golding, Horace He, Connor Leahy , Kyle McDonell, Jason Phang, et al. Gpt-neox-20b: An open-source autoregressive language model.arXiv preprint arXiv:2204.06745, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Findings of the 2014 workshop on statistical machine translation
Ond ˇrej Bojar, Christian Buck, Christian Federmann, Barry Haddow, Philipp Koehn, Johannes Leveling, Christof Monz, Pavel Pecina, Matt Post, Herve Saint-Amand, Radu Soricut, Lucia Specia, and Ale ˇs Tamchyna. Findings of the 2014 workshop on statistical machine translation. InProceedings of the Ninth Workshop on Statistical Machine Translation, pages 12–5...
2014
-
[18]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry , Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott G...
1901
-
[19]
Yu, Qiang Yang, and Xing Xie
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. A survey on evaluation of large language models.ACM Trans. Intell. Syst. Technol., 15(3), March 2024
2024
-
[20]
Humans or LLMs as the judge? a study on judgement bias
Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, and Benyou Wang. Humans or LLMs as the judge? a study on judgement bias. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8301–8327, Miami, Florida, USA, November 2024. Association for Computational Linguistics
2024
-
[21]
Hamed Hassani, Amin Karbasi, and Andreas Krause
Yuxin Chen, S. Hamed Hassani, Amin Karbasi, and Andreas Krause. Sequential information maxi- mization: When is greedy near-optimal? In Peter Gr ¨unwald, Elad Hazan, and Satyen Kale, editors, Proceedings of The 28th Conference on Learning Theory, volume 40 ofProceedings of Machine Learning Research, pages 338–363, Paris, France, 03–06 Jul 2015. PMLR
2015
-
[22]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality , March 2023
2023
-
[23]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
Cohere api.https://docs.cohere.com
Cohere. Cohere api.https://docs.cohere.com
-
[25]
Command r: Retrieval-augmented generation at production scale, 2024
Cohere. Command r: Retrieval-augmented generation at production scale, 2024
2024
-
[26]
Introducing command r+: A scalable llm built for business, 2024
Cohere. Introducing command r+: A scalable llm built for business, 2024. 12
2024
-
[27]
Committee-based sampling for training probabilistic classifiers
Ido Dagan and Sean P Engelson. Committee-based sampling for training probabilistic classifiers. In Machine Learning Proceedings 1995, pages 150–157. Elsevier, 1995
1995
-
[28]
Introducing dbrx: A new state-of-the-art open llm.https://www.databricks.com/blog/ introducing-dbrx-new-state-art-open-llm, March 2024
Databricks. Introducing dbrx: A new state-of-the-art open llm.https://www.databricks.com/blog/ introducing-dbrx-new-state-art-open-llm, March 2024. Accessed: 2025-08-31
2024
-
[29]
GLM: general language model pretraining with autoregressive blank infilling
Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. GLM: general language model pretraining with autoregressive blank infilling. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 320–335. Association for Co...
2022
-
[30]
Sample-efficient human evaluation of large language models via maximum discrepancy competition
Kehua Feng, Keyan Ding, Tan Hongzhi, Kede Ma, Zhihua Wang, Shuangquan Guo, Cheng Yuzhou, Ge Sun, Guozhou Zheng, Qiang Zhang, and Huajun Chen. Sample-efficient human evaluation of large language models via maximum discrepancy competition. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page...
2025
-
[31]
Open llm leaderboard v2.https://huggingface.co/spaces/open-llm-leaderboard/open_llm_ leaderboard, 2024
Cl ´ementine Fourrier, Nathan Habib, Alina Lozovskaya, Konrad Szafer, and Thomas Wolf. Open llm leaderboard v2.https://huggingface.co/spaces/open-llm-leaderboard/open_llm_ leaderboard, 2024
2024
-
[32]
Selective sampling using the query by committee algorithm.Machine learning, 28:133–168, 1997
Yoav Freund, H Sebastian Seung, Eli Shamir, and Naftali Tishby . Selective sampling using the query by committee algorithm.Machine learning, 28:133–168, 1997
1997
-
[33]
Bayesian active model selection with an application to automated audiometry
Jacob Gardner, Gustavo Malkomes, Roman Garnett, Kilian Q Weinberger, Dennis Barbour, and John P Cunningham. Bayesian active model selection with an application to automated audiometry . In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc., 2015
2015
-
[34]
Gemini: A Family of Highly Capable Multimodal Models
Google. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Gemma open models, 2024
Google. Gemma open models, 2024
2024
-
[36]
Gemini api.https://ai.google.dev
Google DeepMind. Gemini api.https://ai.google.dev
-
[37]
Gemini 3.1 Pro Model Card.https://deepmind.google/models/model-cards/ gemini-3-1-pro/, 2026
Google DeepMind. Gemini 3.1 Pro Model Card.https://deepmind.google/models/model-cards/ gemini-3-1-pro/, 2026. Accessed: 2026-05-02
2026
-
[38]
The Flores-101 evaluation benchmark for low-resource and multilingual machine translation.Transactions of the Association for Computational Linguistics, 10:522–538, 2022
Naman Goyal, Cynthia Gao, Vishrav Chaudhary , Peng-Jen Chen, Guillaume Wenzek, Da Ju, San- jana Krishnan, Marc’Aurelio Ranzato, Francisco Guzm´an, and Angela Fan. The Flores-101 evaluation benchmark for low-resource and multilingual machine translation.Transactions of the Association for Computational Linguistics, 10:522–538, 2022
2022
-
[39]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay , Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6904–6913, July 2017
2017
-
[40]
Rating roulette: Self-inconsistency in LLM-as-a-judge frame- works
Rajarshi Haldar and Julia Hockenmaier. Rating roulette: Self-inconsistency in LLM-as-a-judge frame- works. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 24986–25004, Suzhou, China, November 2025. Association for Computational Linguistics
2025
-
[41]
DeBERTa: Decoding-enhanced BERT with disentangled attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. DeBERTa: Decoding-enhanced BERT with disentangled attention. InInternational Conference on Learning Representations, 2021
2021
-
[42]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021. 13
2021
-
[43]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. InAdvances in Neural Information Processing Systems, volume 34, 2021
2021
-
[44]
Teaching machines to read and comprehend
Karl Moritz Hermann, Tomas Kocisky , Edward Grefenstette, Lasse Espeholt, Will Kay , Mustafa Su- leyman, and Phil Blunsom. Teaching machines to read and comprehend. InAdvances in Neural Information Processing Systems, volume 28, 2015
2015
-
[45]
Actracer: Active testing of large language model via multi-stage sampling.ACM Transactions on Software Engineering and Methodology, 2025
Yuheng Huang, Jiayang Song, Qiang Hu, Felix Juefei-Xu, and Lei Ma. Actracer: Active testing of large language model via multi-stage sampling.ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[46]
Hugging face hub.https://huggingface.co
Hugging Face. Hugging face hub.https://huggingface.co
-
[47]
Introducing idefics: An open reproduction of flamingo.https://huggingface.co/ blog/idefics, 2023
Hugging Face. Introducing idefics: An open reproduction of flamingo.https://huggingface.co/ blog/idefics, 2023
2023
-
[48]
Internlm: A multilingual language model with progressively enhanced capabilities.https: //github.com/InternLM/InternLM-techreport, 2023
InternLM. Internlm: A multilingual language model with progressively enhanced capabilities.https: //github.com/InternLM/InternLM-techreport, 2023
2023
-
[49]
Smith, Iz Beltagy , and Hannaneh Hajishirzi
Hamish Ivison, Yizhong Wang, Valentina Pyatkin, Nathan Lambert, Matthew Peters, Pradeep Dasigi, Joel Jang, David Wadden, Noah A. Smith, Iz Beltagy , and Hannaneh Hajishirzi. Camels in a changing climate: Enhancing lm adaptation with tulu 2, 2023
2023
-
[50]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L ´elio Re- nard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Tim- oth´ee Lacroix, and William El Sayed. Mistral 7b.arXiv preprint a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary , Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, L ´elio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Shuyu Jiang, Xingshu Chen, and Rui Tang. Prompt packer: Deceiving llms through compositional instruction with hidden attacks.arXiv preprint arXiv:2310.10077, 2023
-
[53]
Online active model selection for pre-trained classifiers
Mohammad Reza Karimi, Nezihe Merve G ¨urel, Bojan Karlaˇs, Johannes Rausch, Ce Zhang, and An- dreas Krause. Online active model selection for pre-trained classifiers. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), pages 307–315. PMLR, April 2021
2021
-
[54]
Anytime model selection in linear bandits
Parnian Kassraie, Nicolas Emmenegger, Andreas Krause, and Aldo Pacchiano. Anytime model selection in linear bandits. InProc. Neural Information Processing Systems (NeurIPS), December 2023
2023
-
[55]
Consensus-driven active model selection
Justin Kay , Grant Van Horn, Subhransu Maji, Daniel Sheldon, and Sara Beery . Consensus-driven active model selection. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV),
-
[56]
The NarrativeQA reading comprehension challenge.Transactions of the Association for Computational Linguistics, 6:317–328, 2018
Tom´aˇs Koˇcisk´y, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, G ´abor Melis, and Edward Grefenstette. The NarrativeQA reading comprehension challenge.Transactions of the Association for Computational Linguistics, 6:317–328, 2018
2018
-
[57]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems, vol- ume 35, pages 22199–22213, 2022. 14
2022
-
[58]
Active testing: Sample-efficient model evaluation
Jannik Kossen, Sebastian Farquhar, Yarin Gal, and Tom Rainforth. Active testing: Sample-efficient model evaluation. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 5753–
-
[59]
PMLR, 18–24 Jul 2021
2021
-
[60]
Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Matthew Kelcey , Jacob Devlin, Kenton Lee, Kristina N. Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural ques- tions: A benchmark for question answering research.Trans...
2019
-
[61]
Vhelm: A holistic evaluation of vision language models
Tony Lee, Haoqin Tu, Chi H Wong, Wenhao Zheng, Yiyang Zhou, Yifan Mai, Josselin S Roberts, Michi- hiro Yasunaga, Huaxiu Yao, Cihang Xie, et al. Vhelm: A holistic evaluation of vision language models. Advances in Neural Information Processing Systems, 37:140632–140666, 2024
2024
-
[62]
Towards optimal evaluation efficiency for large language models
Guohong Li and Deyi Xiong. Towards optimal evaluation efficiency for large language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14176– 14183, Suzhou, China, 2025. Association for Computational Linguistics
2025
-
[63]
Junfan Li, Zenglin Xu, Zheshun Wu, and Irwin King. On the necessity of collaboration in online model selection with decentralized data.arXiv preprint arXiv:2404.09494, 2024
-
[64]
Online foun- dation model selection in robotics.arXiv preprint arXiv:2402.08570, 2024
Po-han Li, Oyku Selin Toprak, Aditya Narayanan, Ufuk Topcu, and Sandeep Chinchali. Online foun- dation model selection in robotics.arXiv preprint arXiv:2402.08570, 2024
-
[65]
Gonzalez, and Ion Stoica
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From live data to high-quality benchmarks: The arena-hard pipeline, April 2024
2024
-
[66]
Hashimoto
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval, 5 2023
2023
-
[67]
Active evaluation acqui- sition for efficient LLM benchmarking
Yang Li, Jie Ma, Miguel Ballesteros, Yassine Benajiba, and Graham Horwood. Active evaluation acqui- sition for efficient LLM benchmarking. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 35581–35602, 2025
2025
-
[68]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Alexander Cosgrove, Christopher D Manning, Christopher Re, Diana Acosta- Navas, Drew Arad Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda ...
2023
-
[69]
Helm lite: Lightweight and broad capabilities evaluation
Percy Liang, Yifan Mai, Josselin Somerville, Farzaan Kaiyom, Tony Lee, and Rishi Bommasani. Helm lite: Lightweight and broad capabilities evaluation. Stanford CRFM blog, 2023
2023
-
[70]
Active model selection for positive unlabeled time series classification
Shen Liang, Yanchun Zhang, and Jiangang Ma. Active model selection for positive unlabeled time series classification. In2020 IEEE 36th International Conference on Data Engineering (ICDE), pages 361–372, 2020
2020
-
[71]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. 15
2004
-
[72]
Contextual active online model selection with expert advice
Xuefeng Liu, Fangfang Xia, Rick L Stevens, and Yuxin Chen. Contextual active online model selection with expert advice. InICML2022 Workshop on Adaptive Experimental Design and Active Learning in the Real World. ICML, 2022
2022
-
[73]
Maas, Raymond E
Andrew L. Maas, Raymond E. Daly , Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. Learning word vectors for sentiment analysis. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150, Portland, Oregon, USA, 2011. Association for Computational Linguistics
2011
-
[74]
Lizotte, and Russell Greiner
Omid Madani, Daniel J. Lizotte, and Russell Greiner. Active model selection, 2012
2012
-
[75]
tinyBenchmarks: evaluating LLMs with fewer examples
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. tinyBenchmarks: evaluating LLMs with fewer examples. In Ruslan Salakhutdinov, Zico Kolter, Kather- ine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volu...
2024
-
[76]
Active model selection: A variance minimization approach
Mitsuru Matsuura and Satoshi Hara. Active model selection: A variance minimization approach. In NeurIPS 2023 Workshop on Adaptive Experimental Design and Active Learning in the Real World, 2023
2023
-
[77]
Introducing meta llama 3: The most capable openly available llm to date, 2024
Meta AI. Introducing meta llama 3: The most capable openly available llm to date, 2024
2024
-
[78]
Pixtral 12b.https://mistral.ai/news/pixtral-12b, 2024
Mistral AI. Pixtral 12b.https://mistral.ai/news/pixtral-12b, 2024
2024
-
[79]
Introducing mpt-30b: Raising the bar for open-source foundation models.https://www
MosaicML. Introducing mpt-30b: Raising the bar for open-source foundation models.https://www. mosaicml.com/blog/mpt-30b, 2023
2023
-
[80]
Cohen, and Mirella Lapata
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Meth- ods in Natural Language Processing, pages 1797–1807, Brusse...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.