ClueAegis: Heuristic-to-Reasoning Cognitive-skill Learning for Unified Evidence-based Synthetic Image Detection
Pith reviewed 2026-06-30 12:29 UTC · model grok-4.3
The pith
A two-stage agentic system extracts perceptual clues, selects forensic skills, and reasons over evidence to detect synthetic images more robustly than end-to-end classifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
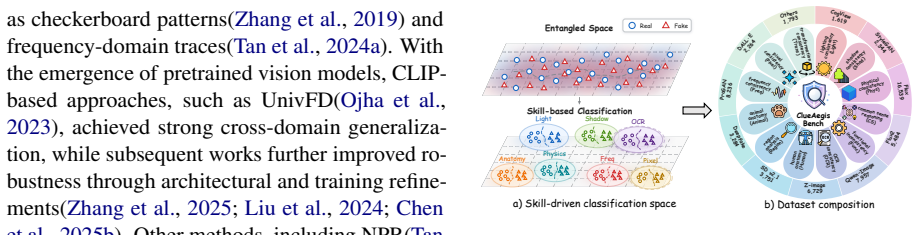
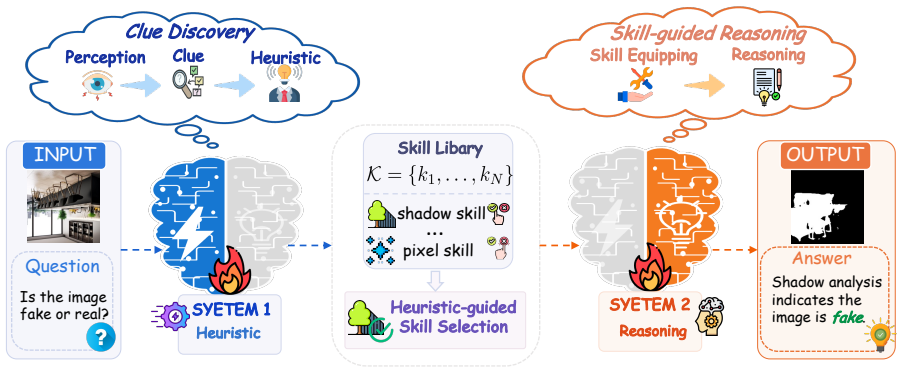
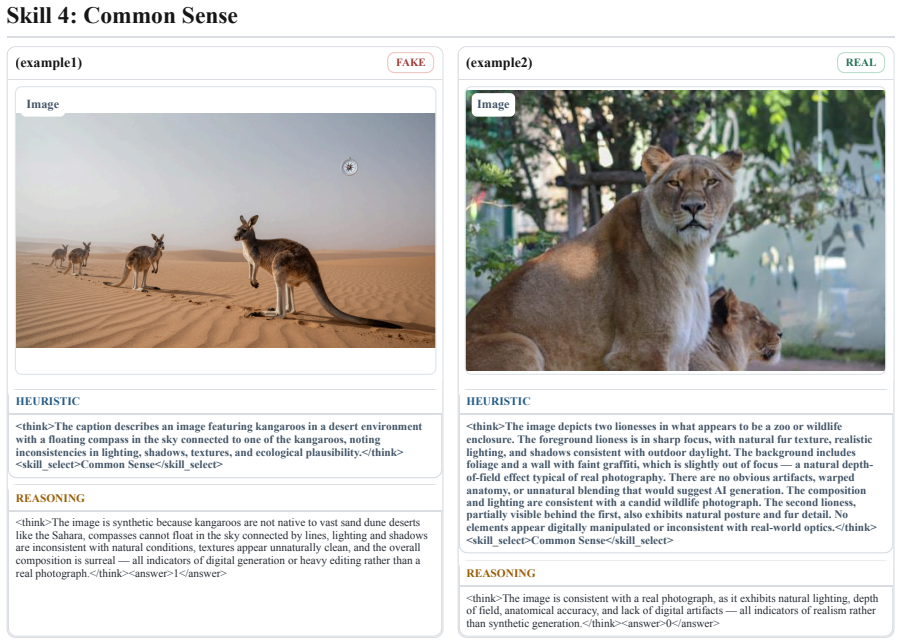
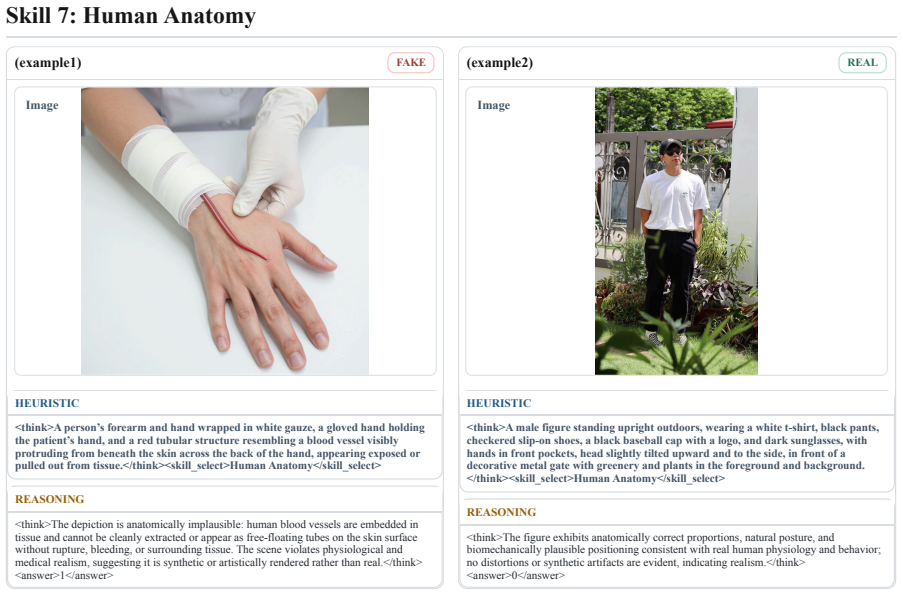
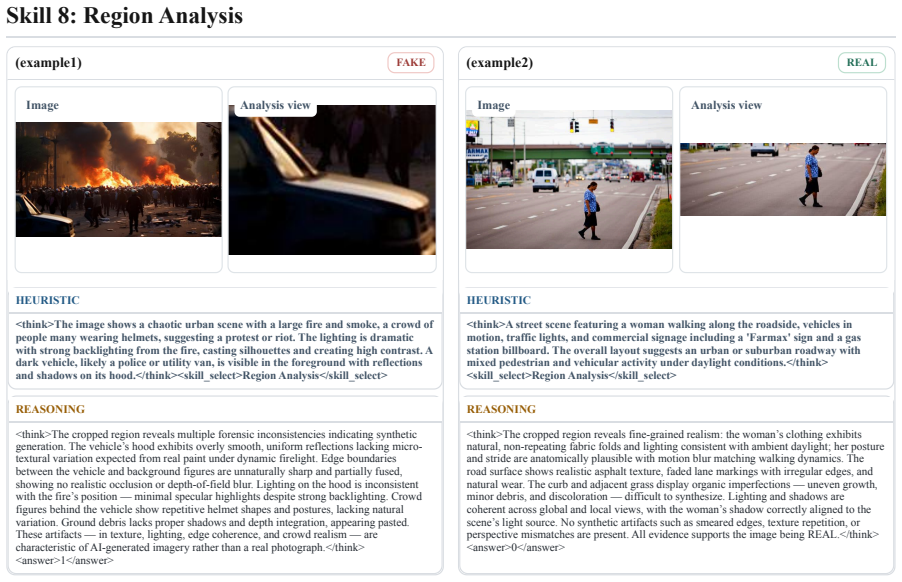
ClueAegis reformulates synthetic image detection as a configurable multi-skill reasoning process: given an input image the framework extracts heuristic perceptual clues, selects the optimal forensic skill, and performs skill-conditioned reasoning through toolchains for evidence extraction and decision making, thereby bridging perception, skill selection, and forensic reasoning.
What carries the argument
The two-stage agentic framework that performs heuristic skill selection followed by evidence-guided reasoning through skill-conditioned toolchains.
If this is right
- The method attains state-of-the-art detection accuracy on existing benchmarks.
- Cross-domain generalization and robustness both increase relative to monolithic detectors.
- Reasoning trajectories become transparent and forensic evidence is produced in structured form.
- The system supplies a more explainable alternative to conventional end-to-end classifiers.
Where Pith is reading between the lines
- The modular skill-selection design could transfer to related tasks such as video deepfake detection or image manipulation localization.
- Because each skill is explicitly chosen and documented, the framework may reduce the amount of labeled data needed for new generator families.
- The same heuristic-to-reasoning pattern might improve other perceptual judgment problems that currently rely on opaque neural classifiers.
Load-bearing premise
Breaking synthetic image detection into selectable heuristic perceptual clues and discrete forensic cognitive skills yields better evidence extraction and decisions than treating the task as a single end-to-end classification problem.
What would settle it
A controlled test in which ClueAegis records lower accuracy or weaker cross-generator robustness than a standard end-to-end classifier on a fresh collection of synthetic images produced by an unseen generative model.
Figures










read the original abstract
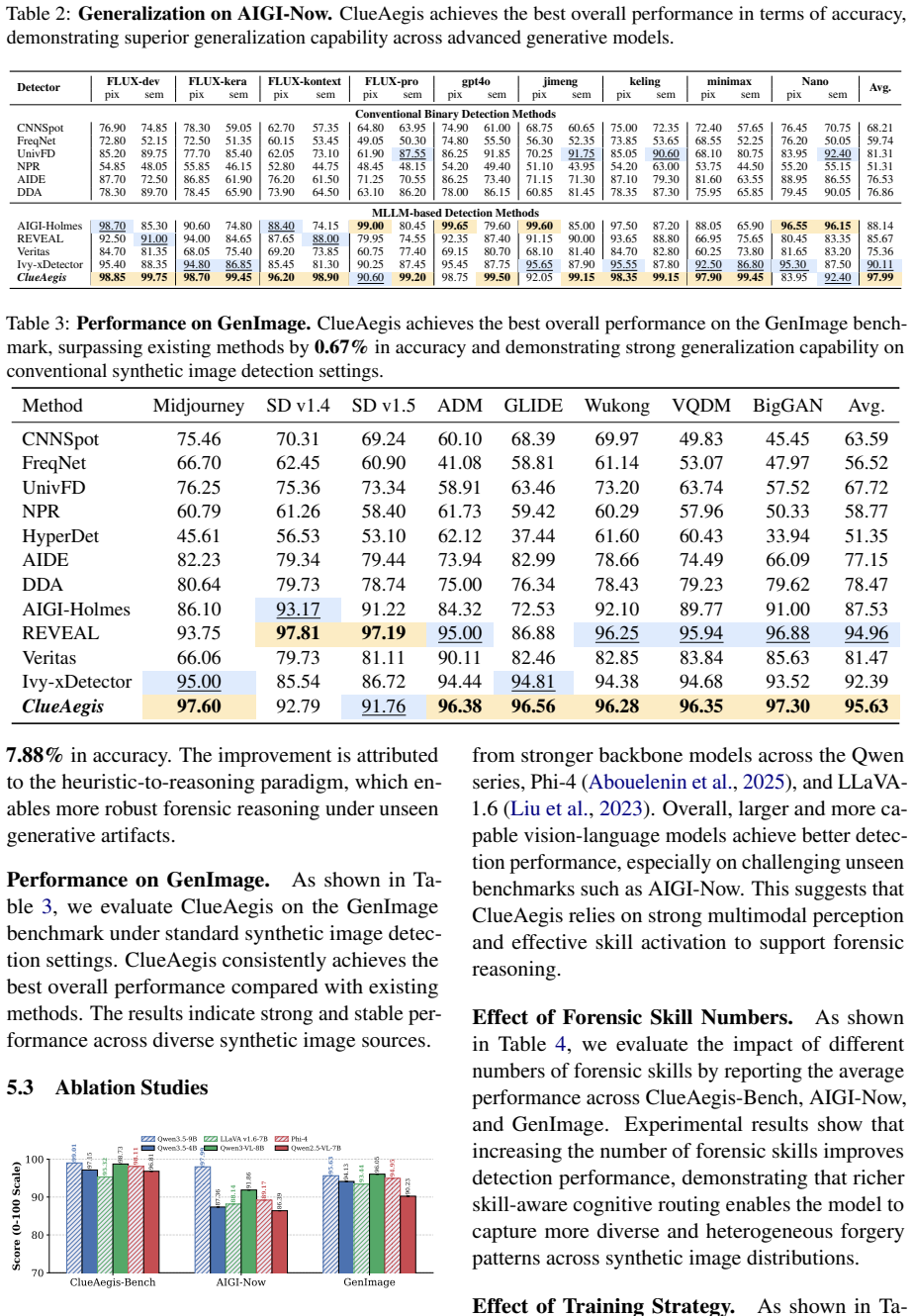
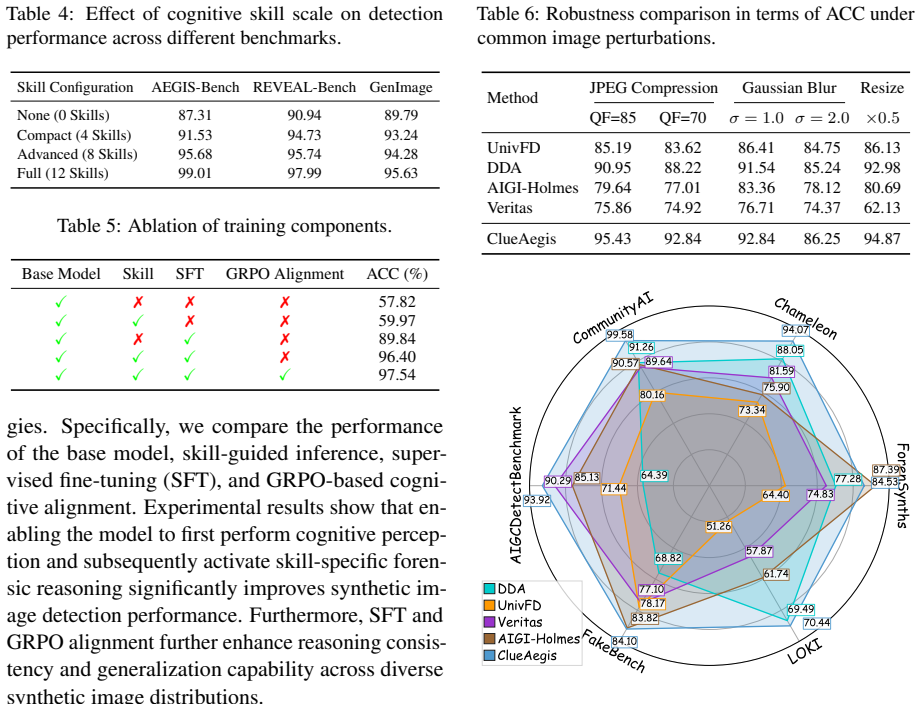
The rapid advancement of generative models has made synthetic images increasingly realistic, challenging reliable detection. Existing methods are often limited to end-to-end classification or monolithic reasoning, and thus fail to model structured forensic reasoning and heterogeneous visual evidence. We revisit synthetic image detection from a cognitive perspective and propose a \textit{Heuristic-to-Reasoning} cognitive skill learning framework for evidence-based forensic analysis. Given an input image, our framework first extracts heuristic perceptual clues, selects the optimal forensic skill, and then performs skill-conditioned reasoning for evidence extraction and decision making. To support this paradigm, we introduce \textbf{ClueAegis-Bench}, which decomposes synthetic image detection into explicitly annotated forensic cognitive skills for structured evaluation beyond binary classification. Based on this benchmark, we propose \textbf{ClueAegis} (\underline{C}ognitive-skill \underline{L}earning for \underline{U}nified \underline{E}vidence-based Synthetic Image Detection), a two-stage agentic framework that conducts heuristic skill selection followed by evidence-guided reasoning through skill-conditioned toolchains. This design reformulates synthetic image detection as a configurable multi-skill reasoning process that bridges perception, skill selection, and forensic reasoning. Extensive experiments show that ClueAegis achieves state-of-the-art performance while improving cross-domain generalization and robustness. It also provides transparent reasoning trajectories and structured forensic evidence, offering a more explainable alternative to conventional end-to-end detectors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ClueAegis, a two-stage agentic framework for synthetic image detection. Given an input image, it extracts heuristic perceptual clues, selects an optimal forensic skill, and performs skill-conditioned reasoning for evidence extraction and decision making. It introduces ClueAegis-Bench, which decomposes detection into explicitly annotated forensic cognitive skills. The framework is claimed to reformulate detection as a configurable multi-skill reasoning process that bridges perception, skill selection, and forensic reasoning, achieving SOTA performance with improved cross-domain generalization, robustness, and explainability over end-to-end detectors.
Significance. If the performance and generalization claims hold with proper validation, the work could advance synthetic image detection by moving beyond monolithic classification to structured, skill-based forensic reasoning, potentially yielding more robust and interpretable systems. The introduction of ClueAegis-Bench for cognitive-skill evaluation is a constructive contribution that could support future research on evidence-based detection.
major comments (2)
- [Abstract] Abstract: The central claims of SOTA performance, improved cross-domain generalization, and robustness are asserted without any quantitative results, baselines, dataset sizes, error bars, or experimental protocol. This absence is load-bearing because the abstract itself states that 'extensive experiments show' these outcomes, yet supplies no supporting data.
- [Abstract] Abstract: No ablations, component-wise comparisons, or controls are referenced that isolate the contribution of the heuristic skill selection and two-stage reasoning versus a direct clue-to-decision mapping. This leaves the key premise—that the explicit heuristic-to-skill decomposition itself drives the claimed gains—unverified and untested against monolithic alternatives.
minor comments (1)
- [Abstract] Abstract: The acronym expansion for ClueAegis is given with underlines as Cognitive-skill Learning for Unified Evidence-based Synthetic Image Detection; verify that the full manuscript maintains consistent acronym usage and definition.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract. We agree that the abstract should better ground its claims and will revise accordingly while preserving conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of SOTA performance, improved cross-domain generalization, and robustness are asserted without any quantitative results, baselines, dataset sizes, error bars, or experimental protocol. This absence is load-bearing because the abstract itself states that 'extensive experiments show' these outcomes, yet supplies no supporting data.
Authors: We accept this observation. The current abstract is high-level by design, but the full manuscript contains the requested details (ClueAegis-Bench statistics, baseline comparisons, cross-domain splits, and error bars). In revision we will insert one or two concise quantitative highlights (e.g., peak accuracy and generalization gap) and a brief protocol reference to make the claims immediately verifiable from the abstract itself. revision: yes
-
Referee: [Abstract] Abstract: No ablations, component-wise comparisons, or controls are referenced that isolate the contribution of the heuristic skill selection and two-stage reasoning versus a direct clue-to-decision mapping. This leaves the key premise—that the explicit heuristic-to-skill decomposition itself drives the claimed gains—unverified and untested against monolithic alternatives.
Authors: The manuscript does contain the requested ablations and controls in the experimental section, directly comparing the two-stage heuristic-to-reasoning pipeline against direct clue-to-decision and end-to-end baselines. Because the abstract is a summary, it does not enumerate every ablation. We will add a short clause noting that component ablations confirm the contribution of skill selection and conditioned reasoning, thereby linking the abstract claim to the supporting evidence already present in the paper. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The abstract and description introduce a new two-stage agentic framework and benchmark without any equations, fitted parameters, self-citations, or derivations that reduce claims to inputs by construction. The central premise of heuristic-to-reasoning decomposition is presented as a design choice supported by experimental results rather than a self-referential reduction. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic image detection benefits from explicit decomposition into heuristic perceptual clues and selectable forensic cognitive skills
invented entities (1)
-
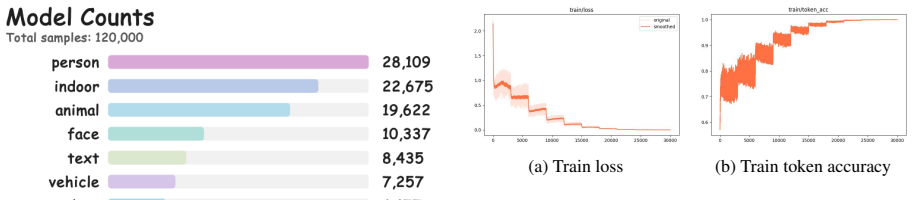
ClueAegis-Bench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Nitzan Bitton-Guetta, Yonatan Bitton, Jack Hessel, Ludwig Schmidt, Yuval Elovici, Gabriel Stanovsky, and Roy Schwartz. 2023. Breaking common sense: Whoops! a vision-and-language benchmark of syn- thetic and compositional images. InProceedings of the IEEE/CVF International Conference on Com- puter ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
InEuropean con- ference on computer vision, pages 103–120
What makes fake images detectable? under- standing properties that generalize. InEuropean con- ference on computer vision, pages 103–120. Springer. Ruoxin Chen, Jiahui Gao, Kaiqing Lin, Keyue Zhang, Yandan Zhao, Isabel Guan, Taiping Yao, and Shouhong Ding. 2025a. Task-model alignment: A simple path to generalizable ai-generated image de- tection.arXiv pre...
-
[3]
Ivy-Fake: A Unified Explainable Framework and Benchmark for Image and Video AIGC Detection
Ivy-fake: A unified explainable framework and benchmark for image and video aigc detection. arXiv preprint arXiv:2506.00979. Daniel Kahneman. 2011. Thinking, fast and slow.Far- rar, Straus and Giroux. Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, and 1 ...
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[4]
InICASSP 2019- 2019 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 2307–
Capsule-forensics: Using capsule networks to detect forged images and videos. InICASSP 2019- 2019 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 2307–
2019
-
[5]
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee
IEEE. Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. 2023. To- wards universal fake image detectors that general- ize across generative models. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, pages 24480–24489. Rémi Pautrat, Daniel Barath, Viktor Larsson, Martin R Oswald, and Marc Pollefeys. 2023. Deeplsd: Line segment d...
2023
-
[6]
Shadows don’t lie and lines can’t bend! gen- erative models don’t know projective geometry... for now. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 28140–28149. 10 Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugging- gpt: Solving ai tasks with chatgpt and its friend...
-
[7]
Dire for diffusion-generated image detection. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 22445–22455. Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, and 1 others. 2025. Qwen-image technical report.arXiv preprint arXiv:2508.02324. Chenfei Wu, Sh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
Visual chatgpt: Talking, drawing and edit- ing with visual foundation models.arXiv preprint arXiv:2303.04671. Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, and 1 others. 2024. Au- togen: Enabling next-gen llm applications via multi- agent conversations. InFirst conference on lang...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Skillrl: Evolving agents via recursive skill- augmented reinforcement learning.arXiv preprint arXiv:2602.08234. Zhipei Xu, Xuanyu Zhang, Runyi Li, Zecheng Tang, Qing Huang, and Jian Zhang. 2025. Fakeshield: Ex- plainable image forgery detection and localization via multi-modal large language models. InInter- national Conference on Learning Representations...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Use Image 1 as the reference for scene structure and illumination context
-
[11]
Compare Image 2 with Image 1 for lighting direction, intensity, highlights, and reflections
-
[12]
Check whether visible shadows and geometric cues are consistent with a coherent light source
-
[13]
Identify unrealistic lighting patterns, abrupt illumination changes, or physically implausible light behavior
-
[14]
transform_params
Decide whether lighting inconsistencies provide evidence of synthetic generation. Figure 9: Prompt template for Lighting Consistency. The prompt includes input images, auxiliary DeepLSD- based lighting analysis, and a structured reasoning checklist for real-vs-synthetic classification. 17 Skill 1: Lighting Consistency (example1) FAKE HEURISTIC <think>The ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.