PQDT: Pseudo-Query Dual Transformer for Robust Point Cloud Restoration
Pith reviewed 2026-06-30 11:50 UTC · model grok-4.3
The pith
The Pseudo-Query module lets one Transformer network restore point clouds suffering from incompleteness, noise, and deformation at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
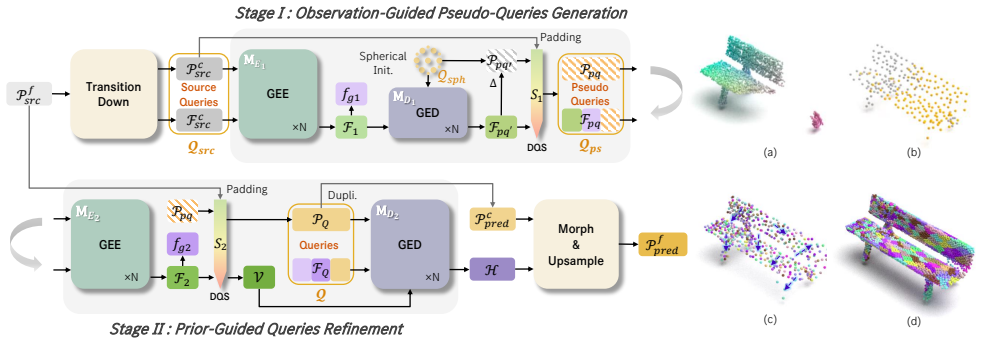
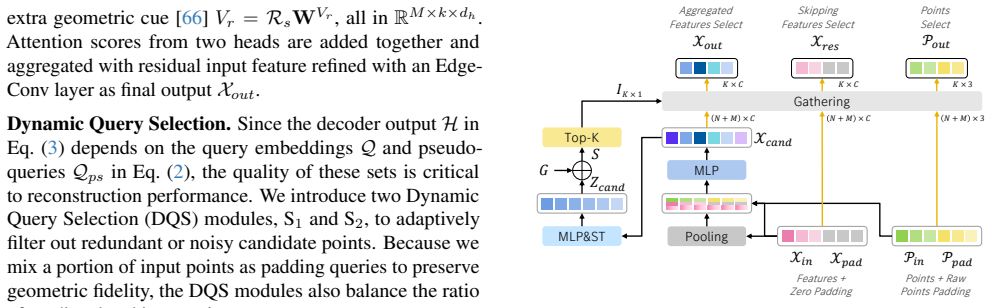
The paper claims that implementing a Pseudo-Query module within a Transformer backbone reformulates geometric translation into two cooperative stages, which enhances structural clarity, robustness, and local detail preservation in point cloud restoration, allowing a single point-only network to handle diverse degradations including completion, deformation, and denoising better than existing methods.
What carries the argument
The Pseudo-Query module that reformulates geometric translation into two cooperative stages.
If this is right
- It effectively handles complex combinations of completion, deformation, and denoising degradations.
- Surpasses state-of-the-art performance in general 3D restoration on curated benchmarks.
- Provides a novel unified, point-only backbone for robust 3D restoration.
- Enables more versatile 3D perception for downstream applications.
Where Pith is reading between the lines
- The two-stage reformulation could be adapted to other geometric tasks like surface reconstruction from images.
- If the cooperative stages preserve details well, it might improve performance on very sparse point clouds from LiDAR.
- Testing on real-world sensor data not seen in training would reveal how well the robustness generalizes.
Load-bearing premise
The two cooperative stages in the Pseudo-Query module improve structural clarity and local details without creating new artifacts or sensitivity to input changes.
What would settle it
Running the model on point clouds with novel combinations of degradations or higher noise levels than in the benchmarks and measuring if it still outperforms other methods or maintains detail without artifacts.
Figures











read the original abstract
Point clouds are a fundamental 3D representation in computer vision, enabling a wide range of perception tasks. However, real-world point clouds often suffer from degradations such as incompleteness, noise, outliers, and irregular density, caused by sensor limitations or occlusions. Recovering clean and detailed shapes from such degraded data is crucial for downstream applications. While existing learning-based methods achieve progress on individual tasks like completion or denoising, they typically rely on global bottleneck features, which lose fine-grained geometry and remain sensitive to varying input quality. We propose a unified 3D restoration network that directly takes point clouds as input and adaptively reconstructs high-quality geometry under diverse degradation scenarios. At the core of our approach is a Pseudo-Query module, implemented within a Transformer backbone, which reformulates geometric translation into two cooperative stages to enhance structural clarity, robustness, and local detail preservation. Extensive experiments on curated benchmarks demonstrate that our approach surpasses state-of-the-art performance in general 3D restoration. It effectively handles complex combinations of completion, deformation, and denoising degradations. With this work, we provide a novel unified, point-only backbone for robust 3D restoration, enabling more versatile 3D perception.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PQDT, a unified point-cloud restoration network built around a Pseudo-Query Dual Transformer. A Pseudo-Query module inside the Transformer backbone reformulates geometric translation into two cooperative stages intended to improve structural clarity, robustness, and local-detail preservation. The work claims to surpass prior state-of-the-art methods on curated benchmarks for general 3D restoration and to handle complex combinations of completion, deformation, and denoising degradations within a single point-only backbone.
Significance. A validated unified backbone that demonstrably copes with simultaneous multi-degradation inputs would constitute a meaningful advance over task-specific pipelines that rely on global bottleneck features. The absence of any quantitative results, baseline comparisons, ablation tables, or benchmark descriptions in the supplied text, however, precludes any assessment of whether that advance has been achieved.
major comments (1)
- [Abstract] Abstract: the headline claim that the method 'effectively handles complex combinations of completion, deformation, and denoising degradations' is load-bearing for the central contribution, yet the text supplies no experimental protocol, per-combination metrics, or description of whether the curated benchmarks contain simultaneous multi-degradation inputs versus single or sequentially applied degradations. Without this information the generalization asserted for the Pseudo-Query module cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract. We address the concern point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that the method 'effectively handles complex combinations of completion, deformation, and denoising degradations' is load-bearing for the central contribution, yet the text supplies no experimental protocol, per-combination metrics, or description of whether the curated benchmarks contain simultaneous multi-degradation inputs versus single or sequentially applied degradations. Without this information the generalization asserted for the Pseudo-Query module cannot be evaluated.
Authors: We acknowledge that the abstract is brief and does not detail the experimental protocol. The full manuscript (Section 4) describes the curated benchmarks, which are generated by applying completion, deformation, and denoising degradations simultaneously to each input point cloud (rather than sequentially or in isolation). Quantitative results, including per-combination metrics on these multi-degradation cases, are reported in Tables 1–3 with comparisons to prior methods. To address the referee's concern, we will revise the abstract to explicitly note that the benchmarks feature simultaneous multi-degradation inputs and to reference the experimental section for the evaluation protocol and metrics. revision: yes
Circularity Check
No circularity: architecture and claims rest on external benchmarks, not self-referential definitions or fits.
full rationale
The paper proposes a Transformer-based network with a Pseudo-Query module for point cloud restoration and supports its performance claims solely via experiments on curated benchmarks. No equations, derivations, or first-principles results are present that could reduce to inputs by construction. The design choices are presented as empirical engineering decisions rather than mathematically forced outcomes, and no self-citation chains or fitted parameters renamed as predictions appear in the abstract or described structure. This is the standard case of a self-contained empirical ML contribution whose validity is tested externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas L´eonard, and Aaron Courville. Es- timating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
State of the art in surface reconstruction from point clouds.Euro- graphics 2014-State of the Art Reports, 2014
Matthew Berger, Andrea Tagliasacchi, Lee Seversky, Pierre Alliez, Joshua Levine, Andrei Sharf, and Cl´audio Silva. State of the art in surface reconstruction from point clouds.Euro- graphics 2014-State of the Art Reports, 2014. 2
2014
-
[3]
End- to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End- to-end object detection with transformers. InECCV, pages 213–229, 2020. 3, 2
2020
-
[4]
Anchorformer: Point cloud completion from discriminative nodes
Zhikai Chen, Fuchen Long, Zhaofan Qiu, Ting Yao, Wen- gang Zhou, Jiebo Luo, and Tao Mei. Anchorformer: Point cloud completion from discriminative nodes. InCVPR, pages 13581–13590, 2023. 2, 4, 6, 7, 3, 9
2023
-
[5]
Shape completion using 3d-encoder-predictor cnns and shape synthesis
Angela Dai, Charles Ruizhongtai Qi, and Matthias Nießner. Shape completion using 3d-encoder-predictor cnns and shape synthesis. InCVPR, pages 5868–5877, 2017. 2
2017
-
[6]
Iterativepfn: True iterative point cloud filtering
Dasith de Silva Edirimuni, Xuequan Lu, Zhiwen Shao, Gang Li, Antonio Robles-Kelly, and Ying He. Iterativepfn: True iterative point cloud filtering. InCVPR, pages 13530–13539,
-
[7]
Superpc: a single diffusion model for point cloud completion, upsampling, de- noising, and colorization
Yi Du, Zhipeng Zhao, Shaoshu Su, Sharath Golluri, Haoze Zheng, Runmao Yao, and Chen Wang. Superpc: a single diffusion model for point cloud completion, upsampling, de- noising, and colorization. InCVPR, pages 16953–16964,
-
[8]
T-corresnet: template guided 3d point cloud completion with correspondence pool- ing query generation strategy
Fan Duan, Jiahao Yu, and Li Chen. T-corresnet: template guided 3d point cloud completion with correspondence pool- ing query generation strategy. InECCV, pages 90–106, 2024. 2, 6, 7
2024
-
[9]
A point set generation network for 3d object reconstruction from a single image
Haoqiang Fan, Hao Su, and Leonidas J Guibas. A point set generation network for 3d object reconstruction from a single image. InCVPR, pages 605–613, 2017. 5, 2
2017
-
[10]
Robust moving least-squares fitting with sharp features.ACM TOG, 24(3):544–552, 2005
Shachar Fleishman, Daniel Cohen-Or, and Cl´audio T Silva. Robust moving least-squares fitting with sharp features.ACM TOG, 24(3):544–552, 2005. 2
2005
-
[11]
Me-pcn: Point completion conditioned on mask emptiness
Bingchen Gong, Yinyu Nie, Yiqun Lin, Xiaoguang Han, and Yizhou Yu. Me-pcn: Point completion conditioned on mask emptiness. InICCV, pages 12488–12497, 2021. 2
2021
-
[12]
3d-coded: 3d correspondences by deep deformation
Thibault Groueix, Matthew Fisher, Vladimir G Kim, Bryan C Russell, and Mathieu Aubry. 3d-coded: 3d correspondences by deep deformation. InECCV, pages 230–246, 2018. 3
2018
-
[13]
Body in white (biw)
SKH Group. Body in white (biw). https : / / www.skhgroup.co.in/our-products/body-in- white-biw. Accessed: Nov. 2025. 4
2025
-
[14]
High-resolution shape completion using deep neural networks for global structure and local geometry inference
Xiaoguang Han, Zhen Li, Haibin Huang, Evangelos Kaloger- akis, and Yizhou Yu. High-resolution shape completion using deep neural networks for global structure and local geometry inference. InICCV, pages 85–93, 2017. 2
2017
-
[15]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InNeurIPS, pages 6840–6851,
-
[16]
Render4completion: Synthesizing multi-view depth maps for 3d shape completion
Tao Hu, Zhizhong Han, Abhinav Shrivastava, and Matthias Zwicker. Render4completion: Synthesizing multi-view depth maps for 3d shape completion. InICCVW, 2019. 2
2019
-
[17]
Local frequency interpretation and non-local self-similarity on graph for point cloud inpainting.IEEE TIP, 28(8):4087–4100, 2019
Wei Hu, Zeqing Fu, and Zongming Guo. Local frequency interpretation and non-local self-similarity on graph for point cloud inpainting.IEEE TIP, 28(8):4087–4100, 2019. 2
2019
-
[18]
Fea- ture graph learning for 3d point cloud denoising.IEEE TSP, 68:2841–2856, 2020
Wei Hu, Xiang Gao, Gene Cheung, and Zongming Guo. Fea- ture graph learning for 3d point cloud denoising.IEEE TSP, 68:2841–2856, 2020. 2
2020
-
[19]
Rfnet: Recurrent forward network for dense point cloud completion
Tianxin Huang, Hao Zou, Jinhao Cui, Xuemeng Yang, Meng- meng Wang, Xiangrui Zhao, Jiangning Zhang, Yi Yuan, Yifan Xu, and Yong Liu. Rfnet: Recurrent forward network for dense point cloud completion. InICCV, pages 12508–12517,
-
[20]
Pf-net: Point fractal network for 3d point cloud completion
Zitian Huang, Yikuan Yu, Jiawen Xu, Feng Ni, and Xinyi Le. Pf-net: Point fractal network for 3d point cloud completion. InCVPR, pages 7662–7670, 2020. 1, 2
2020
-
[21]
Point cloud completion with pretrained text-to-image diffusion models
Yoni Kasten, Ohad Rahamim, and Gal Chechik. Point cloud completion with pretrained text-to-image diffusion models. InNeurIPS, pages 12171–12191, 2023. 2
2023
-
[22]
Learning part-based templates from large collections of 3d shapes
Vladimir G Kim, Wilmot Li, Niloy J Mitra, Siddhartha Chaud- huri, Stephen DiVerdi, and Thomas Funkhouser. Learning part-based templates from large collections of 3d shapes. ACM TOG, 32(4):1–12, 2013. 2
2013
-
[23]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InICLR, 2015. 1
2015
-
[24]
Robo3d: Towards robust and reliable 3d perception against corruptions
Lingdong Kong, Youquan Liu, Xin Li, Runnan Chen, Wenwei Zhang, Jiawei Ren, Liang Pan, Kai Chen, and Ziwei Liu. Robo3d: Towards robust and reliable 3d perception against corruptions. InICCV, pages 19994–20006, 2023. 2
2023
-
[25]
Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement
Wouter Kool, Herke Van Hoof, and Max Welling. Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement. InICML, pages 3499–3508, 2019. 5
2019
-
[26]
Procedural noise using sparse gabor convolution.ACM SIGGRAPH, 28(3):54–64, 2009
Ares Lagae, Sylvain Lefebvre, George Drettakis, and Philip Dutr´e. Procedural noise using sparse gabor convolution.ACM SIGGRAPH, 28(3):54–64, 2009. 6, 3 6 Table 10. Results of our method and state-of-the-art methods on ShapeNet-55. We report the detailed results for each method on 10 categories and the overall results on 55 categories for three difficulty...
2009
-
[27]
M. Levoy. Display of surfaces from volume data.IEEE Computer Graphics and Applications, 8(3):29–37, 1988. 6
1988
-
[28]
Proxyformer: Proxy alignment assisted point cloud comple- tion with missing part sensitive transformer
Shanshan Li, Pan Gao, Xiaoyang Tan, and Mingqiang Wei. Proxyformer: Proxy alignment assisted point cloud comple- tion with missing part sensitive transformer. InCVPR, pages 9466–9475, 2023. 2, 4, 6, 7
2023
-
[29]
Database-assisted object retrieval for real-time 3d reconstruction
Yangyan Li, Angela Dai, Leonidas Guibas, and Matthias Nießner. Database-assisted object retrieval for real-time 3d reconstruction. InCGF, pages 435–446, 2015. 2
2015
-
[30]
SGDR: stochastic gradient descent with warm restarts
Ilya Loshchilov and Frank Hutter. SGDR: stochastic gradient descent with warm restarts. InICLR, 2017. 1
2017
-
[31]
Diffusion probabilistic models for 3d point cloud generation
Shitong Luo and Wei Hu. Diffusion probabilistic models for 3d point cloud generation. InCVPR, pages 2837–2845, 2021. 3
2021
-
[32]
Pd-flow: A point cloud denoising framework with normalizing flows
Aihua Mao, Zihui Du, Yu-Hui Wen, Jun Xuan, and Yong- Jin Liu. Pd-flow: A point cloud denoising framework with normalizing flows. InECCV, pages 398–415, 2022. 2
2022
-
[33]
Denoising point clouds in latent space via graph convolution and in- vertible neural network
Aihua Mao, Biao Yan, Zijing Ma, and Ying He. Denoising point clouds in latent space via graph convolution and in- vertible neural network. InCVPR, pages 5768–5777, 2024. 2
2024
-
[34]
Symmetry in 3d geometry: Extraction and applications.CGF, 32(6), 2013
Niloy Mitra, Mark Pauly, Michael Wand, and Duygu Ceylan. Symmetry in 3d geometry: Extraction and applications.CGF, 32(6), 2013. 2
2013
-
[35]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. In NeurIPS, 2019. 1
2019
-
[36]
Categorical results of our method on ShapeNet-55 and ShapeNet-Deform
Mark Pauly, Niloy J Mitra, Joachim Giesen, Markus H Gross, 7 Table 11. Categorical results of our method on ShapeNet-55 and ShapeNet-Deform. We report the detailed results under CD ℓ2 and F-Score@1% metric for Simple, Moderate and Hard settings. Category ShapeNet-55 ShapeNet-Deform Simple Moderate Hard Simple Moderate Hard CDℓ2 (↓) F1 (↑) CD ℓ2 (↓) F1 (↑)...
2005
-
[37]
Learning graph-convolutional representations Table 13
Francesca Pistilli, Giulia Fracastoro, Diego Valsesia, and Enrico Magli. Learning graph-convolutional representations Table 13. Results of our method and state-of-the-art methods on ShapeNetCar-Occ. We report the detailed results for each method on Car category for three difficulty degrees. We use CD-S, CD-M and CD-H to represent the CD results under the ...
2020
-
[38]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InCVPR, pages 652–660, 2017. 1, 2
2017
-
[39]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. InNeurIPS, 2017. 1, 2, 4
2017
-
[40]
Geotransformer: Fast and robust point cloud registration with geometric trans- former.IEEE TPAMI, 45(8):9806–9821, 2023
Zheng Qin, Hao Yu, Changjian Wang, Yulan Guo, Yuxing Peng, Slobodan Ilic, Dewen Hu, and Kai Xu. Geotransformer: Fast and robust point cloud registration with geometric trans- former.IEEE TPAMI, 45(8):9806–9821, 2023. 4, 1
2023
-
[41]
Pointcleannet: Learning to denoise and remove outliers from dense point clouds
Marie-Julie Rakotosaona, Vittorio La Barbera, Paul Guerrero, Niloy J Mitra, and Maks Ovsjanikov. Pointcleannet: Learning to denoise and remove outliers from dense point clouds. In CGF, pages 185–203, 2020. 2
2020
-
[42]
Kripasindhu Sarkar, Kiran Varanasi, and Didier Stricker. 9 (a) (b) (c) (d) InputOutput AdaPoinTr P2S AdaPoinTr Output AnchorFormer P2S AnchorFormer Output PQDT P2S PQDT Ground Truth Output SnowflakeNet P2S SnowflakeNet Output SeedFormer P2S SeedFormer 0% 2% Figure 13. Qualitative evaluation on PFS. Colors indicate the point- to-surface (P2S) distance betw...
2017
-
[43]
Learning 3d shape comple- tion from laser scan data with weak supervision
David Stutz and Andreas Geiger. Learning 3d shape comple- tion from laser scan data with weak supervision. InCVPR, pages 1955–1964, 2018. 2
1955
-
[44]
Data-driven structural priors for shape completion
Minhyuk Sung, Vladimir G Kim, Roland Angst, and Leonidas Guibas. Data-driven structural priors for shape completion. ACM TOG, 34(6):1–11, 2015. 2
2015
-
[45]
What do single-view 3d reconstruction networks learn? InCVPR, pages 3405– 3414, 2019
Maxim Tatarchenko, Stephan R Richter, Ren´e Ranftl, Zhuwen Li, Vladlen Koltun, and Thomas Brox. What do single-view 3d reconstruction networks learn? InCVPR, pages 3405– 3414, 2019. 6, 2
2019
-
[46]
Tchapmi, Vineet Kosaraju, Hamid Rezatofighi, Ian Reid, and Silvio Savarese
Lyne P. Tchapmi, Vineet Kosaraju, Hamid Rezatofighi, Ian Reid, and Silvio Savarese. Topnet: Structural point cloud decoder. InCVPR, pages 383–392, 2019. 2
2019
-
[47]
Deformation-aware 3d model embedding and retrieval
Mikaela Angelina Uy, Jingwei Huang, Minhyuk Sung, Tolga Birdal, and Leonidas Guibas. Deformation-aware 3d model embedding and retrieval. InECCV, pages 397–413, 2020. 3
2020
-
[48]
Joint learning of 3d shape retrieval and deforma- tion
Mikaela Angelina Uy, Vladimir G Kim, Minhyuk Sung, Noam Aigerman, Siddhartha Chaudhuri, and Leonidas J Guibas. Joint learning of 3d shape retrieval and deforma- tion. InCVPR, pages 11713–11722, 2021. 3
2021
-
[49]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, page 6000–6010, 2017. 1
2017
-
[50]
3dn: 3d deformation network
Weiyue Wang, Duygu Ceylan, Radomir Mech, and Ulrich Neumann. 3dn: 3d deformation network. InCVPR, pages 1038–1046, 2019. 3
2019
-
[51]
Cas- caded refinement network for point cloud completion
Xiaogang Wang, Marcelo H Ang Jr, and Gim Hee Lee. Cas- caded refinement network for point cloud completion. In CVPR, pages 790–799, 2020. 2
2020
-
[52]
Dynamic graph cnn for learning on point clouds.ACM TOG, 38(5): 1–12, 2019
Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bronstein, and Justin M Solomon. Dynamic graph cnn for learning on point clouds.ACM TOG, 38(5): 1–12, 2019. 4, 1
2019
-
[53]
Pcdreamer: Point cloud completion through multi-view diffusion priors
Guangshun Wei, Yuan Feng, Long Ma, Chen Wang, Yuanfeng Zhou, and Changjian Li. Pcdreamer: Point cloud completion through multi-view diffusion priors. InCVPR, pages 27243– 27253, 2025. 5, 7
2025
-
[54]
Point cloud completion by skip-attention network with hi- erarchical folding
Xin Wen, Tianyang Li, Zhizhong Han, and Yu-Shen Liu. Point cloud completion by skip-attention network with hi- erarchical folding. InCVPR, pages 1939–1948, 2020. 1, 2
1939
-
[55]
Simple statistical gradient-following al- gorithms for connectionist reinforcement learning.Machine learning, 8(3):229–256, 1992
Ronald J Williams. Simple statistical gradient-following al- gorithms for connectionist reinforcement learning.Machine learning, 8(3):229–256, 1992. 2
1992
-
[56]
Lever- aging single-view images for unsupervised 3d point cloud completion.IEEE TMM, 27:940–953, 2023
Lintai Wu, Qijian Zhang, Junhui Hou, and Yong Xu. Lever- aging single-view images for unsupervised 3d point cloud completion.IEEE TMM, 27:940–953, 2023. 2
2023
-
[57]
Point transformer v2: Grouped vector attention and partition-based pooling
Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, and Heng- shuang Zhao. Point transformer v2: Grouped vector attention and partition-based pooling. InNeurIPS, 2022. 1
2022
-
[58]
Point transformer v3: Simpler, faster, stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xihui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler, faster, stronger. In CVPR, 2024. 1 10
2024
-
[59]
3d shapenets: A deep representation for volumetric shapes
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Lin- guang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. InCVPR, pages 1912–1920, 2015. 5
1912
-
[60]
Snowflakenet: Point cloud completion by snowflake point deconvolution with skip- transformer
Peng Xiang, Xin Wen, Yu-Shen Liu, Yan-Pei Cao, Pengfei Wan, Wen Zheng, and Zhizhong Han. Snowflakenet: Point cloud completion by snowflake point deconvolution with skip- transformer. InICCV, pages 5499–5509, 2021. 1, 2, 5, 6, 7, 9
2021
-
[61]
Grnet: Gridding residual network for dense point cloud completion
Haozhe Xie, Hongxun Yao, Shangchen Zhou, Jiageng Mao, Shengping Zhang, and Wenxiu Sun. Grnet: Gridding residual network for dense point cloud completion. InECCV, pages 365–381, 2020. 2, 6, 4, 7
2020
-
[62]
Reparameterizable subset sampling via continuous relaxations
Sang Michael Xie and Stefano Ermon. Reparameterizable subset sampling via continuous relaxations. InIJCAI, page 3919–3925, 2019. 5
2019
-
[63]
Explicitly guided information interaction network for cross-modal point cloud completion
Hang Xu, Chen Long, Wenxiao Zhang, Yuan Liu, Zhen Cao, Zhen Dong, and Bisheng Yang. Explicitly guided information interaction network for cross-modal point cloud completion. InECCV, pages 414–432, 2024. 2
2024
-
[64]
3d object reconstruction from a single depth view with adversarial learning
Bo Yang, Hongkai Wen, Sen Wang, Ronald Clark, Andrew Markham, and Niki Trigoni. 3d object reconstruction from a single depth view with adversarial learning. InICCVW, pages 679–688, 2017. 2
2017
-
[65]
Fold- ingnet: Point cloud auto-encoder via deep grid deformation
Yaoqing Yang, Chen Feng, Yiru Shen, and Dong Tian. Fold- ingnet: Point cloud auto-encoder via deep grid deformation. InCVPR, pages 206–215, 2018. 5, 6, 4, 7
2018
-
[66]
Rotation-invariant trans- former for point cloud matching
Hao Yu, Zheng Qin, Ji Hou, Mahdi Saleh, Dongsheng Li, Benjamin Busam, and Slobodan Ilic. Rotation-invariant trans- former for point cloud matching. InCVPR, pages 5384–5393,
-
[67]
Pointr: Diverse point cloud completion with geometry-aware transformers
Xumin Yu, Yongming Rao, Ziyi Wang, Zuyan Liu, Jiwen Lu, and Jie Zhou. Pointr: Diverse point cloud completion with geometry-aware transformers. InCVPR, pages 12498–12507,
-
[68]
Adapointr: Diverse point cloud completion with adap- tive geometry-aware transformers.IEEE TPAMI, 45(12): 14114–14130, 2023
Xumin Yu, Yongming Rao, Ziyi Wang, Jiwen Lu, and Jie Zhou. Adapointr: Diverse point cloud completion with adap- tive geometry-aware transformers.IEEE TPAMI, 45(12): 14114–14130, 2023. 2, 3, 5, 6, 7, 4, 9
2023
-
[69]
Pcn: Point completion network
Wentao Yuan, Tejas Khot, David Held, Christoph Mertz, and Martial Hebert. Pcn: Point completion network. In3DV, pages 728–737, 2018. 1, 2, 5, 6, 7, 4, 9
2018
-
[70]
Point cloud denoising with principal component analysis and a novel bilateral filter.Traitement du signal, 36:393–398, 2019
Feng Zhang, Chao Zhang, Huamin Yang, and Lin Zhao. Point cloud denoising with principal component analysis and a novel bilateral filter.Traitement du signal, 36:393–398, 2019. 2
2019
-
[71]
View-guided point cloud completion
Xuancheng Zhang, Yutong Feng, Siqi Li, Changqing Zou, Hai Wan, Xibin Zhao, Yandong Guo, and Yue Gao. View-guided point cloud completion. InCVPR, pages 15890–15899, 2021. 2
2021
-
[72]
Point transformer
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. Point transformer. InICCV, pages 16259– 16268, 2021. 1, 2, 4
2021
-
[73]
Rolling normal filtering for point clouds
Yinglong Zheng, Guiqing Li, Xuemiao Xu, Shihao Wu, and Yongwei Nie. Rolling normal filtering for point clouds. CAGD, 62(C):16–28, 2018. 2
2018
-
[74]
Position-aware guided point cloud completion with clip model
Feng Zhou, Qi Zhang, Ju Dai, Lei Li, Qing Fan, and Junliang Xing. Position-aware guided point cloud completion with clip model. InAAAI, pages 10734–10742, 2025. 2
2025
-
[75]
Seedformer: Patch seeds based point cloud completion with upsample transformer
Haoran Zhou, Yun Cao, Wenqing Chu, Junwei Zhu, Tong Lu, Ying Tai, and Chengjie Wang. Seedformer: Patch seeds based point cloud completion with upsample transformer. InECCV, pages 416–432, 2022. 2, 4, 5, 6, 7, 3, 9
2022
-
[76]
Open3D: A Modern Library for 3D Data Processing
Qian-Yi Zhou, Jaesik Park, and Vladlen Koltun. Open3d: A modern library for 3d data processing.arXiv preprint arXiv:1801.09847, 2018. 6
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[77]
Svdformer: Complementing point cloud via self-view augmentation and self-structure dual-generator
Zhe Zhu, Honghua Chen, Xing He, Weiming Wang, Jing Qin, and Mingqiang Wei. Svdformer: Complementing point cloud via self-view augmentation and self-structure dual-generator. InICCV, pages 14508–14518, 2023. 2 11
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.