Quantifying Empirical Compute-Supervision Tradeoffs in RLVR
Pith reviewed 2026-06-30 11:43 UTC · model grok-4.3
The pith
Imperfect verifiers in RLVR create accuracy gaps that extra compute fails to close.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
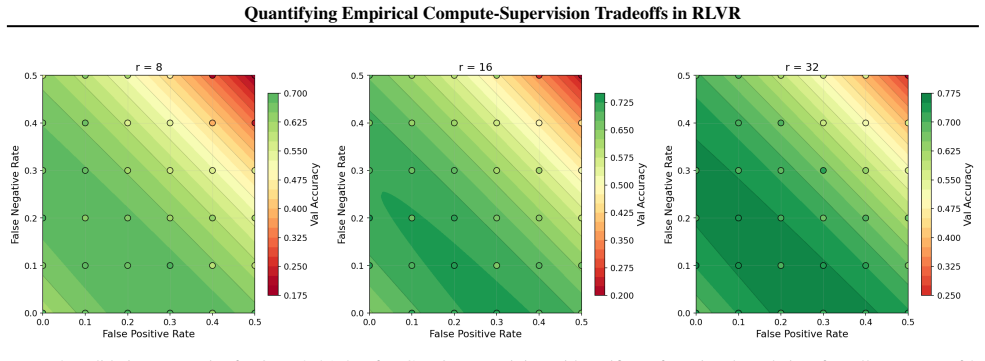
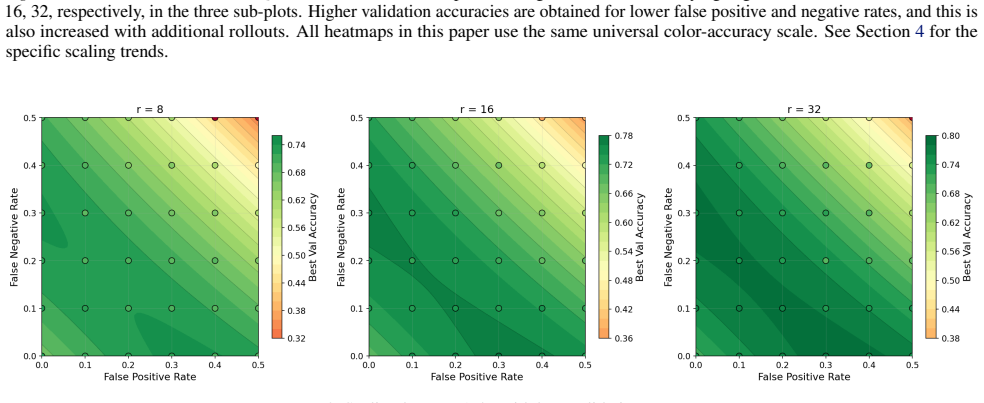
By post-training Qwen2.5 models with GRPO on GSM8K under controlled verifier noise and varying rollouts, the study finds that validation accuracy gaps induced by imperfect supervision persist under compute scaling with sharply diminishing returns, and that false negatives degrade performance more rapidly than false positives.
What carries the argument
Controlled injection of false-positive and false-negative noise into the binary correctness signal, combined with rollout count as the compute axis.
If this is right
- Verifier quality and training compute are not interchangeable.
- Reducing false negatives is a more effective improvement lever than scaling compute alone.
- Returns to additional compute diminish sharply in the presence of verifier noise.
- The final performance outcome depends on supervision quality, not just total compute.
Where Pith is reading between the lines
- Real-world RLVR applications may require prioritizing verifier accuracy improvements over raw compute increases.
- Similar tradeoffs could appear in other verifiable reward tasks beyond math word problems.
- The asymmetry suggests designing verifiers that minimize missed correct answers first.
- Future theoretical models of RLVR should account for persistent effects of noise rather than only rate effects.
Load-bearing premise
Injecting controlled noise into GSM8K correctness signals produces a representative model of real-world verifier imperfections during RLVR post-training.
What would settle it
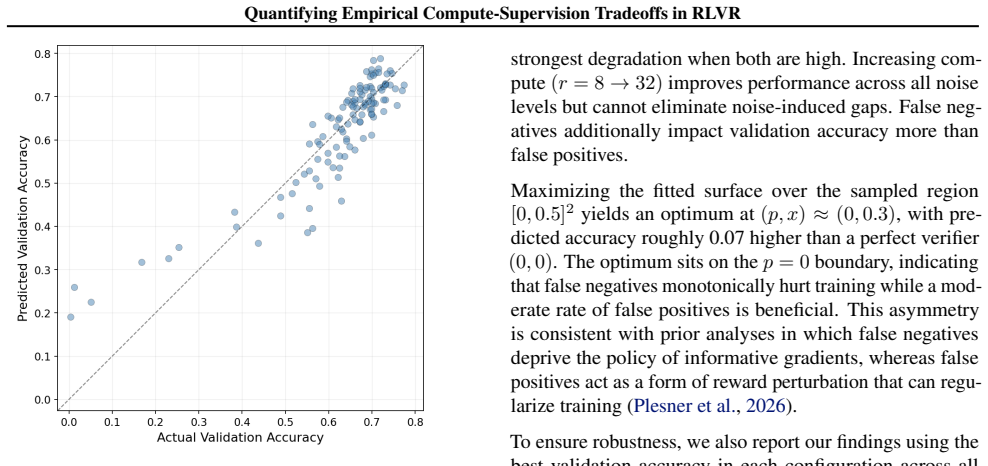
A demonstration that increasing rollouts per prompt eventually eliminates the accuracy gap between noisy and perfect verifiers would falsify the persistence claim.
Figures

read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become a standard paradigm for post-training language models, but in practice, verifiers are rarely perfect. Recent theoretical work predicts that verifier noise affects the rate of learning but not its final outcome, implying that sufficient compute should close any gap induced by imperfect supervision. We test this prediction empirically by post-training Qwen2.5 (0.5B, 1.5B) with GRPO on GSM8K while injecting controlled false-positive and false-negative noise into the binary correctness signal, and varying rollouts per prompt as a compute axis. In practice, the gap in validation accuracy persists under substantial compute scaling, with returns to compute that are sharply diminishing. We further find a structural asymmetry where false negatives monotonically degrade performance more quickly than false positives. These findings suggest verifier quality and training compute are not interchangeable, and that reducing false negatives is a more effective lever than scaling compute alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically tests theoretical predictions about verifier noise in RLVR by post-training Qwen2.5 (0.5B, 1.5B) models with GRPO on GSM8K. It injects controlled independent false-positive and false-negative flips into the binary reward signal while varying rollouts per prompt as a compute axis, reporting that validation accuracy gaps persist under scaling, returns to compute diminish sharply, and false negatives degrade performance more than false positives, implying verifier quality and compute are non-interchangeable.
Significance. If robust, the results challenge the prediction that sufficient compute overcomes imperfect supervision in RLVR and provide actionable guidance for post-training by prioritizing false-negative reduction over compute scaling alone. The controlled noise-injection design enables isolation of FP/FN effects and direct comparison to external GSM8K benchmarks, strengthening the empirical contribution.
major comments (2)
- [Methods / Experimental Setup] The experimental design (described in the methods and abstract) models verifier imperfections via independent per-sample noise flips. This is load-bearing for the claims of persistent gaps, diminishing returns, and FP/FN asymmetry, yet the manuscript provides no validation that the resulting error statistics match those of actual model-based verifiers, which often exhibit correlations with prompt difficulty or reasoning patterns. Without such checks or sensitivity analyses, the generalizability of the findings is uncertain.
- [Abstract and Results] Abstract and results: directional findings on accuracy gaps and asymmetry are reported without error bars, statistical tests, exact noise rates, number of independent runs, or validation details on the GSM8K evaluation protocol. These omissions make it impossible to assess whether the observed effects exceed experimental variability.
minor comments (2)
- [Methods] Clarify the precise noise injection procedure (e.g., whether flips are applied per rollout or per prompt, and how they interact with GRPO's group-relative advantage computation).
- [Discussion] The manuscript would benefit from explicit comparison of the chosen noise rates to observed error rates in published verifier models on GSM8K.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help improve the clarity and robustness of our work. We respond to each major comment below.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] The experimental design (described in the methods and abstract) models verifier imperfections via independent per-sample noise flips. This is load-bearing for the claims of persistent gaps, diminishing returns, and FP/FN asymmetry, yet the manuscript provides no validation that the resulting error statistics match those of actual model-based verifiers, which often exhibit correlations with prompt difficulty or reasoning patterns. Without such checks or sensitivity analyses, the generalizability of the findings is uncertain.
Authors: We agree that the independent noise model is a simplification chosen to isolate FP/FN effects and directly test theoretical predictions. While this design enables clear attribution of performance differences to noise type and rate, we acknowledge that real verifiers may introduce correlated errors. In the revision, we will add a dedicated limitations paragraph discussing this assumption and its potential impact on generalizability. Additionally, we will include sensitivity analyses by simulating correlated noise (e.g., difficulty-dependent flips) to assess robustness of the key findings. revision: partial
-
Referee: [Abstract and Results] Abstract and results: directional findings on accuracy gaps and asymmetry are reported without error bars, statistical tests, exact noise rates, number of independent runs, or validation details on the GSM8K evaluation protocol. These omissions make it impossible to assess whether the observed effects exceed experimental variability.
Authors: We appreciate this observation. The original manuscript omitted these details for brevity. In the revised version, we will report exact noise rates (e.g., FP rates of 0.05, 0.1, 0.2 and FN rates similarly), include error bars from 3 independent random seeds per configuration, add statistical tests (e.g., paired t-tests for asymmetry comparisons), and expand the evaluation protocol description including how GSM8K validation is performed to ensure full reproducibility. revision: yes
Circularity Check
No circularity: purely empirical test of external prediction
full rationale
The manuscript reports an empirical study that injects controlled noise into GSM8K rewards and varies rollout count while measuring validation accuracy on Qwen2.5 models. It references an external theoretical prediction but performs no derivation of its own; results are obtained directly from training runs against held-out validation data. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation
Baker, B., Huizinga, J., Gao, L., Dou, Z., Guan, M. Y ., Madry, A., Zaremba, W., Pachocki, J., and Farhi, D. Mon- itoring reasoning models for misbehavior and the risks of promoting obfuscation.arXiv preprint arXiv:2503.11926,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Reinforcement Learning with Verifiable yet Noisy Rewards under Imperfect Verifiers
Cai, X.-Q., Wang, W., Liu, F., Liu, T., Niu, G., and Sugiyama, M. Reinforcement learning with verifiable yet noisy rewards under imperfect verifiers.arXiv preprint arXiv:2510.00915,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[5]
Lambert, N., Morrison, J., Pyatkin, V ., Huang, S., Ivison, H., Brahman, F., Miranda, L. J. V ., Liu, A., Dziri, N., Lyu, X., Gu, Y ., Malik, S., Graf, V ., Hwang, J. D., Yang, J., Le Bras, R., Tafjord, Ø., Wilhelm, C., Soldaini, L., Smith, N. A., Wang, Y ., Dasigi, P., and Hajishirzi, H. T ¨ulu 3: Pushing frontiers in open language model post-training. a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
An Imperfect Verifier is Good Enough: Learning with Noisy Rewards
Plesner, A., Guzman, F., and Athalye, A. An imperfect verifier is good enough: Learning with noisy rewards. arXiv preprint arXiv:2604.07666,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Rad, A., Filom, K., Keivan, D., Esfahani, P. M., and Ka- malinejad, E. Rate or fate? RLV εR: Reinforcement learning with verifiable noisy rewards.arXiv preprint arXiv:2601.04411,
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. DeepSeek- Math: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Yan, Y ., Lou, X., Li, J., Zhang, Y ., Xie, J., Yu, C., Wang, Y ., Yan, D., and Shen, Y . Reward-robust RLHF in LLMs. arXiv preprint arXiv:2409.15360,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.