Tool-Call Dependency Structure is Linearly Decodable in LLM Agent Residual Streams
Pith reviewed 2026-06-29 23:08 UTC · model grok-4.3
The pith
The dependency structure among an LLM agent's tool calls is linearly decodable from its residual stream activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
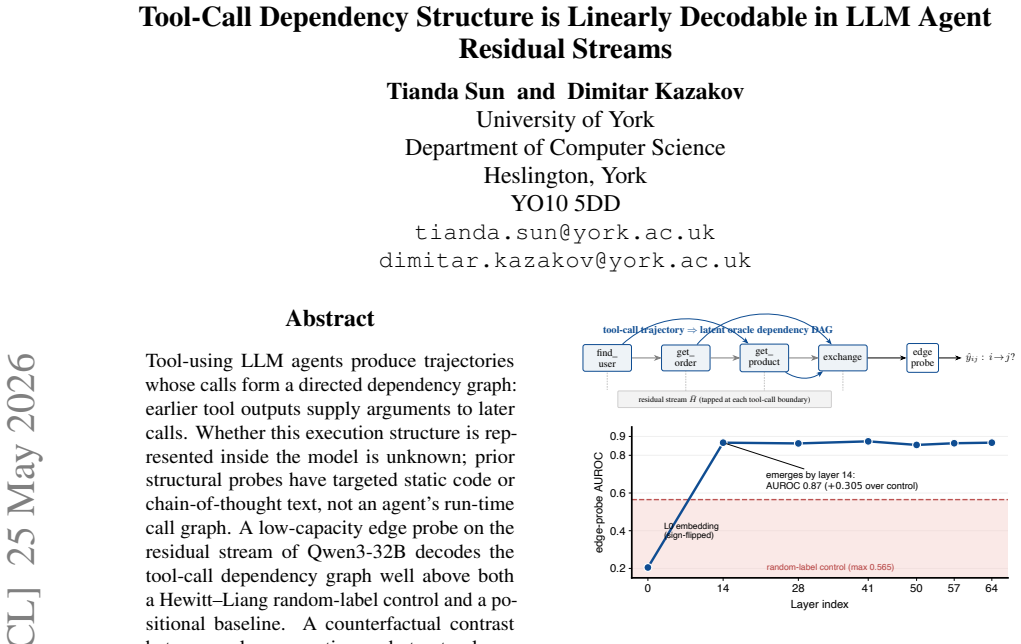
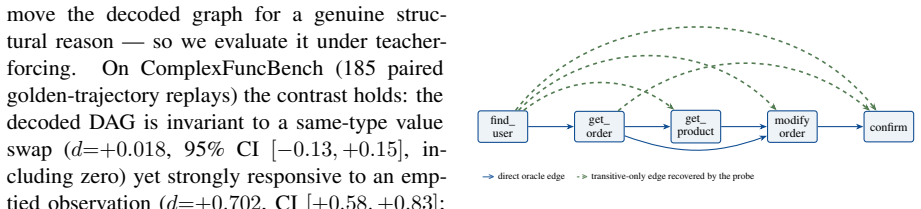
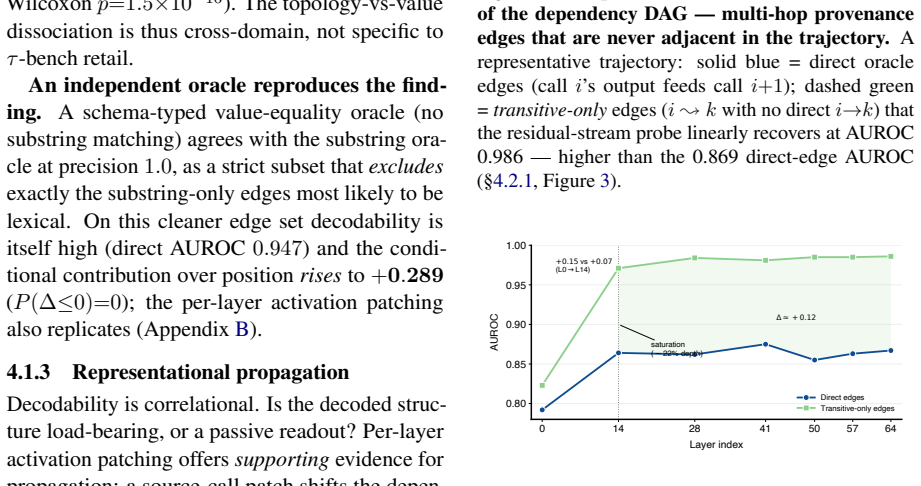
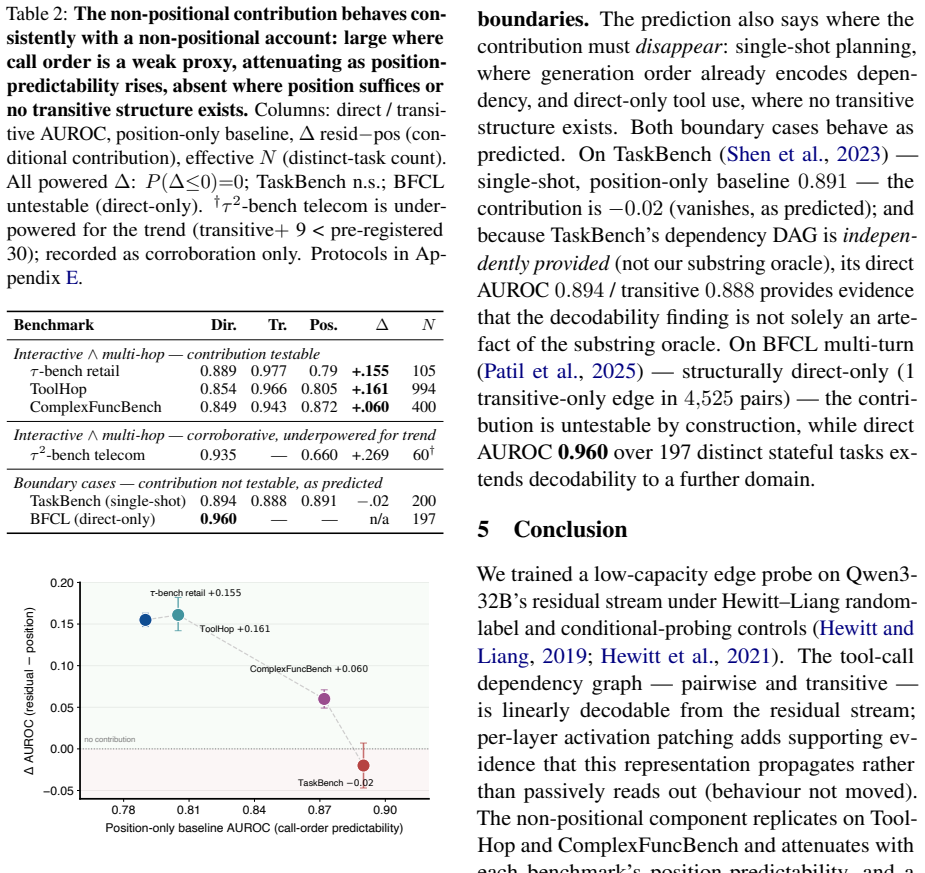
A low-capacity edge probe on the residual stream of Qwen3-32B recovers the tool-call dependency graph at accuracy well above random-label and positional baselines. Counterfactual experiments that corrupt values while preserving structure versus perturbing structure show the probe tracks abstract topology. The non-positional signal appears in three other interactive benchmarks and disappears in single-shot planning where order suffices. Activation patching shifts the probe location, indicating the representation is propagated forward.
What carries the argument
low-capacity edge probe on residual stream activations that classifies directed dependencies between tool calls
Load-bearing premise
The counterfactual contrast between value corruption and structural perturbation, together with the non-substring oracle, fully isolates abstract topology from all other correlated features in the residual stream.
What would settle it
A dataset in which the probe still succeeds after structural edges are randomly rewired while value tokens remain unchanged, or fails after value tokens are changed while edges stay fixed.
Figures
read the original abstract
Tool-using LLM agents produce trajectories whose calls form a directed dependency graph: earlier tool outputs supply arguments to later calls. Whether this execution structure is represented inside the model is unknown; prior structural probes have targeted static code or chain-of-thought text, not an agent's run-time call graph. A low-capacity edge probe on the residual stream of Qwen3-32B decodes the tool-call dependency graph well above both a Hewitt--Liang random-label control and a positional baseline. A counterfactual contrast between value corruption and structural perturbation indicates the signal tracks abstract topology rather than identifier values, and replicates under an independent, non-substring oracle. The non-positional component replicates on three further interactive multi-hop benchmarks and attenuates as call order alone becomes a sufficient proxy for dependency, vanishing in single-shot planning. Per-layer activation patching shifts the probe at a later, non-patched boundary, evidence that the representation propagates rather than passively reads out, though the realised tool call does not move. To our knowledge this is the first structural probe of an LLM agent's runtime tool-call dependency graph. Our claims concern representation, not behavioural control, and span two model families and one primary domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a low-capacity linear edge probe on the residual stream of Qwen3-32B (and another model family) decodes the directed tool-call dependency graph in LLM agent trajectories above Hewitt-Liang random-label and positional baselines. Counterfactual contrasts (value corruption vs. structural perturbation) plus a non-substring oracle indicate the decoded signal tracks abstract topology rather than identifier values; the non-positional component replicates on three further multi-hop benchmarks, attenuates when call order alone suffices as a proxy, and vanishes in single-shot planning. Per-layer activation patching shifts the probe at a later boundary, suggesting the representation propagates rather than being a passive readout.
Significance. If the controls isolate abstract topology, the result would be the first structural probe of runtime tool-call dependency graphs in agents. Credit is due for the suite of controls (random-label, positional, value corruption, non-substring oracle), replication across benchmarks, and the activation-patching experiment; these elements go beyond simple probe accuracy and address several obvious surface-feature confounds.
major comments (2)
- [counterfactual contrast experiments] The section describing the counterfactual contrast between value corruption and structural perturbation: the claim that this isolates abstract topology from all correlated residual features (call-order statistics, argument-length distributions, identifier co-occurrence, execution timing) is load-bearing for the central claim, yet the manuscript provides no ablation demonstrating that the chosen perturbations exhaustively remove those confounds while leaving only topology.
- [activation patching results] The section on activation patching: the reported shift at a later, non-patched boundary is presented as evidence of propagation, but without quantitative comparison to a null patching baseline or explicit measurement of whether the realised tool call itself changes, it is unclear whether the patching result supports representation of the dependency graph or merely a downstream readout.
minor comments (3)
- [methods] The methods section should report the exact probe architecture, hidden dimension, and training details (including how edges are encoded as binary targets) so that capacity and label construction can be directly assessed.
- [replication experiments] Table or figure presenting replication results on the three additional benchmarks should include per-benchmark probe accuracies, control baselines, and effect sizes for direct comparison with the primary Qwen3-32B results.
- [abstract and §1] Clarify in the abstract and introduction whether the reported probe accuracies are macro-averaged over edges or micro-averaged, and whether they are computed on held-out trajectories or held-out positions within trajectories.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for acknowledging the suite of controls in our work. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [counterfactual contrast experiments] The section describing the counterfactual contrast between value corruption and structural perturbation: the claim that this isolates abstract topology from all correlated residual features (call-order statistics, argument-length distributions, identifier co-occurrence, execution timing) is load-bearing for the central claim, yet the manuscript provides no ablation demonstrating that the chosen perturbations exhaustively remove those confounds while leaving only topology.
Authors: The counterfactual design contrasts value corruption, which disrupts identifier-specific information while preserving the dependency structure, against structural perturbation, which alters the graph topology while retaining call values and order statistics. This contrast, combined with the non-substring oracle, is intended to isolate topology from the listed confounds. We do not claim the perturbations are exhaustive of every possible residual feature, but the differential effect supports the abstract topology interpretation. We can add further discussion of the perturbation design in a revision to clarify this. revision: partial
-
Referee: [activation patching results] The section on activation patching: the reported shift at a later, non-patched boundary is presented as evidence of propagation, but without quantitative comparison to a null patching baseline or explicit measurement of whether the realised tool call itself changes, it is unclear whether the patching result supports representation of the dependency graph or merely a downstream readout.
Authors: The manuscript explicitly notes that the realised tool call does not change under patching, which addresses the concern about behavioral impact. The observed shift in probe accuracy at the later boundary, relative to the patched layer, is presented as evidence of propagation through the network. We agree that a quantitative null baseline (e.g., random activation patching) would strengthen the result and will incorporate such a comparison in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical probe results rest on held-out evaluation and controls
full rationale
The paper reports an empirical linear probe trained on residual-stream activations to decode tool-call dependency edges. Performance is measured on held-out trajectories against random-label (Hewitt-Liang) and positional baselines, with additional counterfactual contrasts (value corruption vs. structural perturbation) and a non-substring oracle. No equation or claim reduces a reported result to its own fitted parameters by construction; the probe weights are not renamed as a prediction, and no self-citation supplies a uniqueness theorem or ansatz that the present work then treats as external. The central claim therefore remains a statistical decoding result rather than a self-referential derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear probe weights
axioms (1)
- domain assumption Linear probes on residual streams can recover structural information when performance exceeds random-label and positional baselines
Reference graph
Works this paper leans on
-
[1]
Polar probe linearly decodes semantic structures from LLMs
Are you still on track!? catching LLM task drift with activations.arXiv preprint. Nora Belrose, Igor Ostrovsky, Lev McKinney, Zach Fur- man, Logan Smith, Danny Halawi, Stella Biderman, and Jacob Steinhardt. 2023. Eliciting latent predic- tions from transformers with the tuned lens.arXiv preprint. Pablo J. Diego-Simón and 1 others. 2026. Polar probe linear...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
InProceedings of NAACL-HLT (Short Papers)
The geometry of numerical reasoning: Lan- guage models compare numeric properties in linear subspaces. InProceedings of NAACL-HLT (Short Papers). Jiahai Feng, Stuart Russell, and Jacob Steinhardt. 2025. Monitoring latent world states in language models with propositional probes. InInternational Confer- ence on Learning Representations (ICLR). Spotlight. D...
2025
-
[3]
InIn- ternational Conference on Learning Representations (ICLR)
Emergent world representations: Exploring a sequence model trained on a synthetic task. InIn- ternational Conference on Learning Representations (ICLR). Weijiang Li, Yilin Zhu, Rajarshi Das, and Parijat Dube
-
[4]
InInternational Conference on Learning Representations (ICLR)
Do LLMs build spatial world models? evi- dence from grid-world maze tasks. InInternational Conference on Learning Representations (ICLR). Erik Nordby, Tasha Pais, and Aviel Parrack. 2026. Lin- ear probe accuracy scales with model size and bene- fits from multi-layer ensembling.arXiv preprint. Shishir G. Patil, Huanzhi Mao, Fanjia Yan, Char- lie Cheng-Jie ...
-
[5]
From Chains to DAGs: Probing the Graph Structure of Reasoning in LLMs
From chains to DAGs: Probing the graph structure of reasoning in LLMs.arXiv preprint arXiv:2601.17593. A Implementation Details Model and inference.Qwen3-32B (Qwen Team,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Trajectory generation: do_sample=True, temperature 0.6, top-p 0.95, top-k 20, max_new_tokens=4096, max turns
(HuggingFace revision prefix 9216db5) served in bf16 on one NVIDIA GH200 120 GB GPU per worker, with a decode-time hook captur- ing the residual stream at each transformer block for every assistant token. Trajectory generation: do_sample=True, temperature 0.6, top-p 0.95, top-k 20, max_new_tokens=4096, max turns
-
[7]
yusuf_rossi_9620
Random seed 42 across Python, NumPy, Py- Torch, and scikit-learn; identical seeds across clean and corrupted runs. The τ-bench commit hash is recorded with the release artefacts. Trajectory selection.We collect 120 retail task instances; after filtering trajectories with <2 tool calls, 105 remain. The pair space comprises 1,129 ordered (i, j) pairs with i...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.