GeoMathCode: Understanding Interleaved Math-Code Reasoning for Geometry Problem Solving
Pith reviewed 2026-06-29 22:41 UTC · model grok-4.3
The pith
Supervised fine-tuning disentangles reasoning steps from code generation in the latent space of geometry-solving models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the GeoMathCode setup programmatic representations function as intermediate visual outputs for geometry problems. Reasoning and code generation steps can be disentangled in the latent space, supervised fine-tuning makes the reasoning manifold more structured and informative, and hierarchical syntactic code structures appear as disentangled latent subspaces that contain more mathematical symbolic information than visual representations.
What carries the argument
Disentanglement of reasoning and code-generation trajectories in the latent space of fine-tuned multimodal models, with hierarchical syntactic code structures forming separate subspaces.
If this is right
- Hierarchical code subspaces can be inspected or edited independently of the main reasoning path.
- Programmatic intermediates supply more usable symbolic information than purely visual auxiliary constructions.
- The reasoning manifold after fine-tuning supports more reliable multi-step deduction in geometry tasks.
- Code generation steps can be isolated without disrupting the overall problem-solving flow.
Where Pith is reading between the lines
- Similar latent-space analysis might reveal whether code intermediates help in other domains that mix symbolic and visual reasoning such as physics diagram problems.
- Explicit objectives that encourage subspace separation could be added during training to amplify the observed effect.
- If the subspaces truly isolate symbolic content they could be used to diagnose specific failure modes like algebraic errors versus geometric misinterpretation.
Load-bearing premise
The structure that appears in latent space after supervised fine-tuning actually tracks genuine gains in geometric reasoning ability rather than being produced by the way representations are extracted or by properties of the training data alone.
What would settle it
A controlled experiment that applies the same supervised fine-tuning but measures no corresponding rise in accuracy on geometry problems whose solutions require symbolic manipulation would show the latent changes are not tied to improved reasoning.
Figures

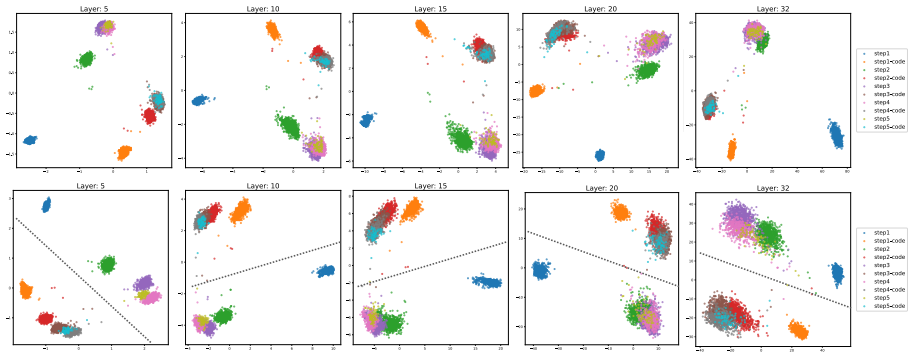
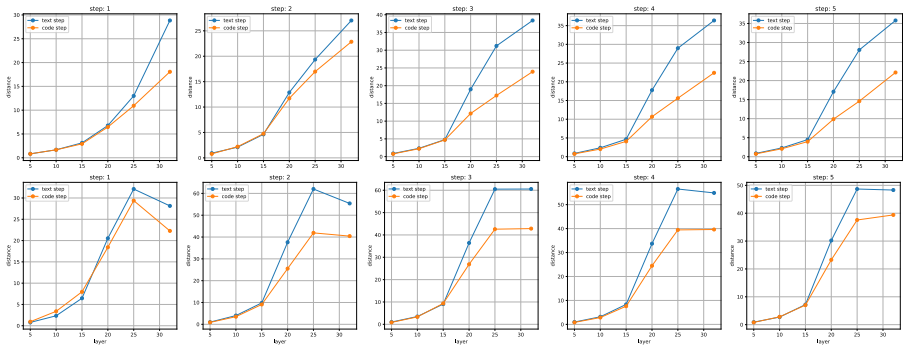
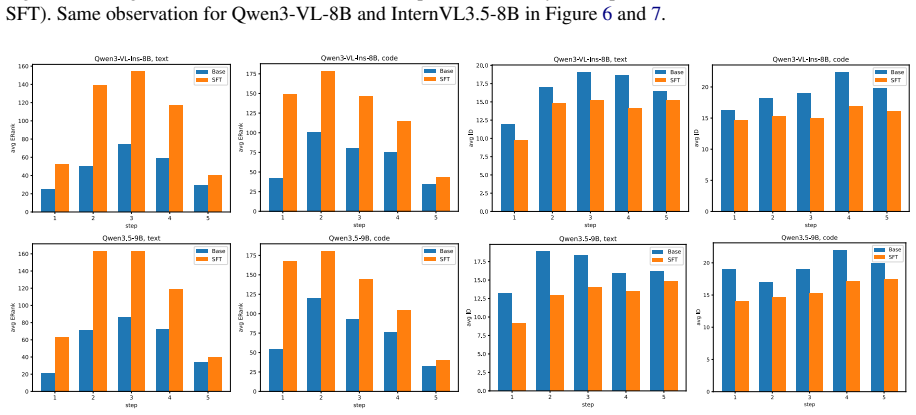
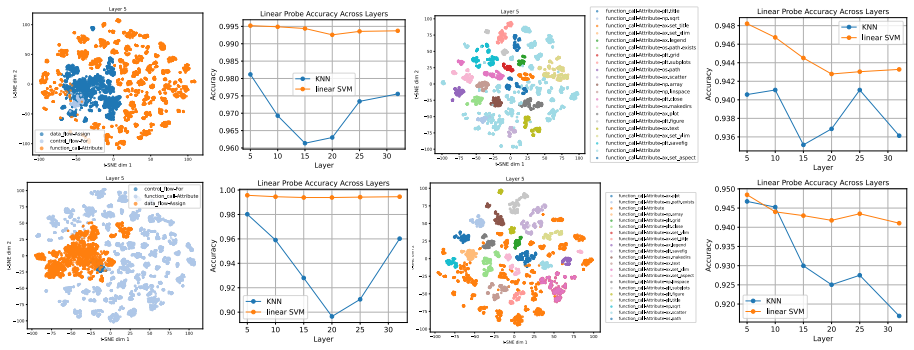
read the original abstract
Mathematical reasoning is a hallmark of human intelligence, requiring logical deduction, symbolic manipulation, and abstract thinking. Recent multimodal large language models (MLLMs) have demonstrated strong performance on geometry problems through multi-step reasoning. To better emulate human problem-solving, intermediate steps can incorporate auxiliary visual constructions, such as additional lines or points, which improve geometric interpretation and educational clarity. In this work, we introduce the GeoMathCode, where programmatic representations serve as intermediate visual outputs. We further conduct an in-depth analysis of the underlying reasoning geometry. Experimental results show that reasoning and code generation steps can be disentangled in the latent space, while supervised fine-tuning (SFT) makes the reasoning manifold more structured and informative. Moreover, hierarchical syntactic code structures emerge as disentangled latent subspaces, and contain more mathematical symbolic information than visual representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeoMathCode, a framework using programmatic representations as intermediate visual outputs for geometry problem solving in multimodal LLMs. It claims that reasoning and code generation steps can be disentangled in latent space, that supervised fine-tuning (SFT) makes the reasoning manifold more structured and informative, and that hierarchical syntactic code structures emerge as disentangled latent subspaces containing more mathematical symbolic information than visual representations.
Significance. If the empirical claims are substantiated with proper controls and metrics, the work could advance interpretability of how MLLMs internally represent interleaved math-code reasoning for geometry, potentially guiding more effective fine-tuning and highlighting advantages of code-based intermediates. The focus on latent manifold structure and disentanglement offers a novel angle on geometric reasoning beyond standard accuracy metrics.
major comments (3)
- [Abstract] Abstract: The central claims about disentanglement of reasoning vs. code steps, structured reasoning manifolds after SFT, and hierarchical syntactic code subspaces carrying more symbolic information lack any reported experimental details, datasets, metrics, controls, or ablation studies, preventing assessment of whether the observations support the claims.
- [Abstract] Abstract: The claim that observed latent subspaces reflect improved geometric reasoning (rather than extraction artifacts or data distribution effects) is load-bearing but unsupported without ablations varying representation extraction procedures or comparing against non-reasoning controls such as code-only fine-tuning or shuffled labels.
- [Abstract] Abstract: The comparison that hierarchical syntactic code structures 'contain more mathematical symbolic information than visual representations' requires an explicit, reproducible definition and quantification of 'mathematical symbolic information'; absent this, the claim is not falsifiable or comparable.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the abstract, as a concise summary, omitted key experimental details and definitions. We have revised the abstract to reference the datasets, metrics, controls, ablations, and the operational definition of mathematical symbolic information, while directing readers to the relevant sections for full details. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims about disentanglement of reasoning vs. code steps, structured reasoning manifolds after SFT, and hierarchical syntactic code subspaces carrying more symbolic information lack any reported experimental details, datasets, metrics, controls, or ablation studies, preventing assessment of whether the observations support the claims.
Authors: The abstract is intended as a high-level summary. The full experimental details—including the geometry problem datasets (e.g., GeoQA and related benchmarks), metrics for disentanglement and manifold structure (linear probing accuracy, intrinsic dimensionality), controls (code-only fine-tuning, shuffled labels), and ablation studies on representation extraction—are reported in Sections 3–5. The revised abstract now briefly notes these elements and points to the relevant sections. revision: yes
-
Referee: [Abstract] Abstract: The claim that observed latent subspaces reflect improved geometric reasoning (rather than extraction artifacts or data distribution effects) is load-bearing but unsupported without ablations varying representation extraction procedures or comparing against non-reasoning controls such as code-only fine-tuning or shuffled labels.
Authors: The manuscript contains the requested ablations: we vary representation extraction (different layers, PCA vs. nonlinear methods) and include non-reasoning controls (code-only SFT and shuffled reasoning labels). These results, showing that disentanglement is not an artifact, appear in Section 4.2. The revised abstract now references the presence of these controls. revision: yes
-
Referee: [Abstract] Abstract: The comparison that hierarchical syntactic code structures 'contain more mathematical symbolic information than visual representations' requires an explicit, reproducible definition and quantification of 'mathematical symbolic information'; absent this, the claim is not falsifiable or comparable.
Authors: We define 'mathematical symbolic information' as the mutual information between latent representations and symbolic geometric elements (theorems, equations, relations), quantified via linear probe accuracy and information-theoretic measures. This definition and the associated quantification procedure are formalized in Section 3.4. The revised abstract now includes a concise statement of this definition. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents experimental observations on latent-space disentanglement after SFT on interleaved math-code data for geometry problems. No load-bearing step reduces by construction to its inputs via self-definition, fitted-parameter renaming, or self-citation chains. Claims rest on post-hoc analysis of representations rather than tautological re-derivation of the same quantities. The derivation is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior self-work as forcing mechanisms.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Viraat Aryabumi, Yixuan Su, Raymond Ma, Adrien Morisot, Ivan Zhang, Acyr Locatelli, Marzieh Fadaee, Ahmet \"U st \"u n, and Sara Hooker. 2025. To code or not to code? exploring impact of code in pre-training. In International Conference on Learning Representations, volume 2025, pages 79469--79495
2025
-
[4]
Carvalho, Yingji Zhang, Giangiacomo Mercatali, and Andre Freitas
Danilo S. Carvalho, Yingji Zhang, Giangiacomo Mercatali, and Andre Freitas. 2023. Learning disentangled representations for natural language definitions. Findings of the European chapter of Association for Computational Linguistics (Findings of EACL)
2023
- [5]
-
[6]
Gongwei Chen, Leyang Shen, Rui Shao, Xiang Deng, and Liqiang Nie. 2023. https://api.semanticscholar.org/CorpusID:265294429 Lion : Empowering multimodal large language model with dual-level visual knowledge . 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26530--26540
2023
- [7]
-
[8]
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. 2025. Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [9]
-
[10]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [11]
-
[12]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, et al. 2024. Metagpt: Meta programming for a multi-agent collaborative framework. In International Conference on Learning Representations, volume 2024, pages 23247--23275
2024
- [13]
-
[14]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3
2022
-
[15]
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. 2024. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models. Advances in Neural Information Processing Systems, 37:139348--139379
2024
-
[16]
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. 2024. The platonic representation hypothesis. arXiv preprint arXiv:2405.07987
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Yibo Jiang, Bryon Aragam, and Victor Veitch. 2024. Uncovering meanings of embeddings via partial orthogonality. Advances in Neural Information Processing Systems, 36
2024
-
[18]
Bowen Jing, Gabriele Corso, Renato Berlinghieri, and Tommi Jaakkola. 2022. Subspace diffusion generative models. In European conference on computer vision, pages 274--289. Springer
2022
- [19]
-
[20]
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. 2024. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
-
[22]
Melody Li, Kumar Krishna Agrawal, Arna Ghosh, Komal Teru, Adam Santoro, Guillaume Lajoie, and Blake Richards. 2026. Tracing the representation geometry of language models from pretraining to post-training. Advances in Neural Information Processing Systems, 38:54691--54724
2026
-
[23]
Qingyuan Liang, Zhao Zhang, Zeyu Sun, Zheng Lin, Qi Luo, Yueyi Xiao, Yizhou Chen, Yuqun Zhang, Haotian Zhang, Lu Zhang, Bin Chen, and Yingfei Xiong. 2025. https://doi.org/10.18653/v1/2025.findings-acl.807 Grammar-based code representation: Is it a worthy pursuit for LLM s? In Findings of the Association for Computational Linguistics: ACL 2025, pages 15640...
-
[24]
Che Liu, Yingji Zhang, Dong Zhang, Weijie Zhang, Chenggong Gong, Yu Lu, Shilin Zhou, Ziliang Gan, Ziao Wang, Haipang Wu, et al. 2025 a . Nexus-o: An omni-perceptive and-interactive model for language, audio, and vision. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 10787--10796
2025
- [25]
-
[26]
Yue Liu, Yue Yu, Yuanliang Zhang, Yu Jiang, Changjian Wang, Shanshan Li, et al. 2024. At which training stage does code data help llms reasoning? In International Conference on Learning Representations, volume 2024, pages 36281--36300
2024
-
[27]
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chun yue Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. 2023. https://api.semanticscholar.org/CorpusID:264491155 Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts . In International Conference on Learning Representations
2023
-
[28]
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. 2021. https://api.semanticscholar.org/CorpusID:234337054 Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning . In Annual Meeting of the Association for Computational Linguistics
2021
-
[29]
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and A. Kalyan. 2022. https://api.semanticscholar.org/CorpusID:252383606 Learn to explain: Multimodal reasoning via thought chains for science question answering . ArXiv, abs/2209.09513
-
[30]
Yanbiao Ma, Fei Luo, Linfeng Zhang, Chuangxin Zhao, Mingxuan Wang, Yinan Wu, Zhe Qian, Yang Lu, Long Chen, Zhao Cao, Xiaoshuai Hao, Ji-Rong Wen, and Jungong Han. 2026. https://api.semanticscholar.org/CorpusID:288257488 Reasoning emerges from constrained inference manifolds in large language models
2026
- [31]
- [32]
- [33]
-
[34]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [35]
-
[36]
Rajmohan
Lihao Sun, Hang Dong, Bo Qiao, Qingwei Lin, Dongmei Zhang, and S. Rajmohan. 2026. https://api.semanticscholar.org/CorpusID:287208541 Llm reasoning as trajectories: Step-specific representation geometry and correctness signals
2026
-
[37]
Matthew Trager, Pramuditha Perera, Luca Zancato, Alessandro Achille, Parminder Bhatia, and Stefano Soatto. 2023. Linear spaces of meanings: compositional structures in vision-language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15395--15404
2023
-
[38]
Alex Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte MacDiarmid. 2023. Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [39]
-
[40]
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. 2024. https://openreview.net/forum?id=QWTCcxMpPA Measuring multimodal mathematical reasoning with MATH -vision dataset . In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2024
-
[41]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. 2025. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. 2026. Dapo: An open-source llm reinforcement learning system at scale. Advances in Neural Information Processing Systems, 38:113222--113244
2026
-
[44]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. 2023. https://api.semanticscholar.org/CorpusID:265466525 Mmmu: A massive multi-discipline...
2023
-
[45]
Renrui Zhang, Xinyu Wei, Dongzhi Jiang, Ziyu Guo, Shicheng Li, Yichi Zhang, Chengzhuo Tong, Jiaming Liu, Aojun Zhou, Bin Wei, Shanghang Zhang, Peng Gao, Chunyuan Li, and Hongsheng Li. 2024 a . https://api.semanticscholar.org/CorpusID:273811833 Mavis: Mathematical visual instruction tuning with an automatic data engine
2024
-
[46]
Yingji Zhang, Danilo Carvalho, and Andre Freitas. 2024 b . https://doi.org/10.18653/v1/2024.acl-long.116 Learning disentangled semantic spaces of explanations via invertible neural networks . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2113--2134, Bangkok, Thailand. Association ...
-
[47]
Yingji Zhang, Danilo Carvalho, and Andre Freitas. 2025. https://doi.org/10.18653/v1/2025.conll-1.2 Quasi-symbolic semantic geometry over transformer-based variational A uto E ncoder . In Proceedings of the 29th Conference on Computational Natural Language Learning, pages 12--29, Vienna, Austria. Association for Computational Linguistics
-
[48]
Yingji Zhang, Danilo Carvalho, and Andre Freitas. 2026 a . https://openreview.net/forum?id=ti7Lxjv3Ol Guiding explanatory inference through inference types
2026
-
[49]
Yingji Zhang, Marco Valentino, Danilo Carvalho, and Andr \'e Freitas. 2026 b . Learning to disentangle latent reasoning rules with language vaes: a systematic study. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 19458--19466
2026
-
[50]
Yuze Zhao, Junpeng Fang, Lu Yu, Zhenya Huang, Kai Zhang, Qing Cui, Qi Liu, Jun Zhou, and Enhong Chen. 2026. What really improves mathematical reasoning: Structured reasoning signals beyond pure code. arXiv preprint arXiv:2605.19762
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Yuze Zhao, Tianyun Ji, Wenjun Feng, Zhenya Huang, Qi Liu, Zhiding Liu, Yixiao Ma, Kai Zhang, and Enhong Chen. 2025. https://openreview.net/forum?id=kN25ggeq1J Unveiling the magic of code reasoning through hypothesis decomposition and amendment . In The Thirteenth International Conference on Learning Representations
2025
-
[52]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024. http://arxiv.org/abs/2403.13372 Llamafactory: Unified efficient fine-tuning of 100+ language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand. Assoc...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.