SeqRoute: Global Budget-Aware Sequential LLM Routing via Offline Reinforcement Learning
Pith reviewed 2026-06-29 23:11 UTC · model grok-4.3
The pith
SeqRoute models multi-turn LLM routing as a budget-aware finite-horizon MDP solved by offline RL to avoid early resource exhaustion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
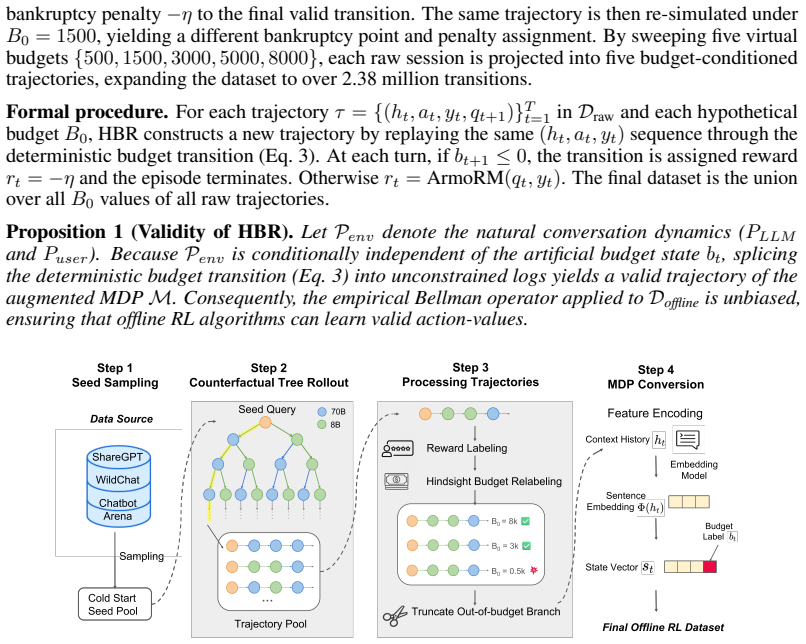
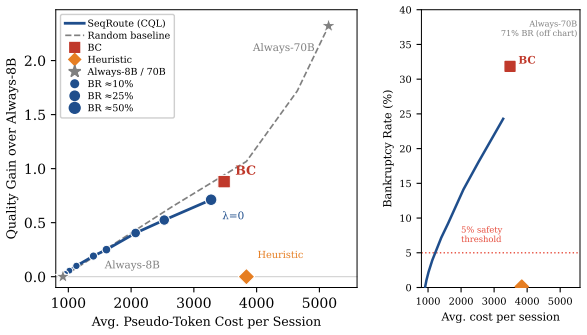
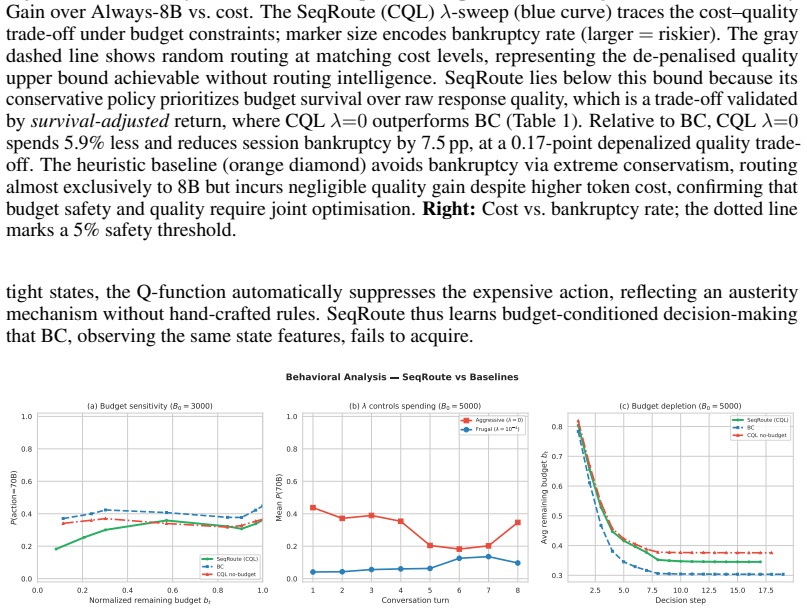
SeqRoute formulates multi-turn LLM routing as a finite-horizon Markov Decision Process whose state contains the remaining global budget and solves it with Conservative Q-Learning on offline data. Hindsight Budget Relabeling retrospectively replays 10,000 raw sessions under many hypothetical budgets, producing 2.38 million transitions that include bankruptcy signals. At inference a dynamic lambda-sweep lets the same policy trace the cost-quality Pareto frontier without retraining. Evaluations show cost reductions of 6.0-73.5 percent, maintained or improved quality, and bankruptcy rates below 1 percent, strictly dominating behavior cloning, budget-aware heuristics, and static baselines across
What carries the argument
Hindsight Budget Relabeling that augments raw sessions into budget-diverse trajectories for training a budget-augmented finite-horizon MDP via Conservative Q-Learning.
If this is right
- Operational costs drop between 6.0 and 73.5 percent while answer quality stays the same or improves.
- Bankruptcy rates across entire sessions fall below 1 percent.
- The learned policy strictly dominates behavior cloning, budget-aware heuristics, and static model selection on every point of the cost-quality Pareto frontier.
- A single trained policy can be steered across the entire frontier at deployment time by changing a scalar lambda without any retraining.
Where Pith is reading between the lines
- The same budget-in-state formulation and hindsight relabeling could be applied to other sequential resource problems such as chained tool calls or multi-step reasoning traces.
- If the relabeling technique works, it offers a general way to create offline datasets for any constrained sequential decision task where the constraint level varies across episodes.
- Longer sessions than those in the evaluation set would test whether the finite-horizon assumption continues to hold or whether an infinite-horizon formulation becomes necessary.
Load-bearing premise
Hindsight Budget Relabeling produces training transitions whose distribution matches the statistics of real user sessions under varied budgets, and the finite-horizon MDP with budget in the state fully captures the decision-relevant dynamics of actual multi-turn interactions.
What would settle it
Run SeqRoute on a production trace of real multi-turn sessions with fixed per-session budgets and record whether bankruptcy occurs in more than 1 percent of sessions or whether average cost falls short of the reported 6 percent reduction while quality metrics stay at or above baseline levels.
Figures
read the original abstract
Existing LLM routing frameworks treat queries as independent events, neglecting the sequential nature of real-world user sessions constrained by global computational budgets. This mismatch inevitably leads to budget bankruptcy: myopic routing policies exhaust resources on early interactions, forcing subsequent and often more complex queries onto inadequate models. We introduce SeqRoute, a framework that formulates multi-turn routing as a finite-horizon Markov Decision Process and solves it via offline reinforcement learning. By incorporating the remaining budget into the state space and training with Conservative Q-Learning (CQL), SeqRoute learns delayed gratification to strategically preserve resources for high-stakes turns later in the session. To overcome data starvation, we propose Hindsight Budget Relabeling (HBR). This technique retrospectively simulates historical trajectories under diverse hypothetical budgets, expanding 10,000 raw sessions into 2.38 million transitions enriched with critical bankruptcy signals. At deployment, a dynamic $\lambda$-sweep mechanism enables zero-shot navigation of the cost-quality Pareto frontier without retraining. Extensive evaluations demonstrate that SeqRoute reduces operational costs by 6.0-73.5% while maintaining or improving quality, and suppresses bankruptcy rates to under 1%, strictly dominating behavior cloning, budget-aware heuristics, and static baselines across the entire Pareto frontier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. SeqRoute formulates multi-turn LLM routing as a finite-horizon MDP with remaining budget in the state, solved via offline RL with Conservative Q-Learning. Hindsight Budget Relabeling augments 10k raw sessions into 2.38M transitions to address data scarcity and bankruptcy signals. At inference a dynamic λ-sweep enables zero-shot Pareto navigation. The central empirical claim is that SeqRoute reduces operational costs by 6.0-73.5% while maintaining or improving quality, suppresses bankruptcy to <1%, and strictly dominates behavior cloning, budget-aware heuristics, and static baselines across the entire frontier.
Significance. If the empirical results hold under proper validation of the data-generation procedure, the work addresses a practically relevant gap between myopic per-query routing and real sequential budget-constrained sessions. The offline-RL framing together with hindsight relabeling provides a concrete, deployable mechanism for delayed gratification in resource allocation; successful validation would be a useful contribution to cost-efficient LLM serving.
major comments (3)
- [Hindsight Budget Relabeling] Hindsight Budget Relabeling section: the central performance numbers (6.0-73.5% cost reduction, <1% bankruptcy, Pareto dominance) rest entirely on the claim that the 2.38M relabeled transitions match the joint distribution of query difficulty, model choice, and budget-consumption trajectories that arise under varied global budgets in real sessions. No statistical comparison, Kolmogorov-Smirnov test, or ablation against held-out real-budget trajectories is reported; without this the learned Q-function and offline metrics are at risk of being artifacts of the synthetic distribution.
- [MDP formulation] Finite-horizon MDP formulation (abstract and method): the state is defined to include remaining budget and the horizon is finite, yet no experiment tests whether this Markovian finite-horizon model captures non-Markovian effects such as topic drift or session-length variation beyond the training distribution. If longer or non-stationary sessions violate the assumption, both the CQL policy and the reported bankruptcy suppression may not transfer.
- [Experiments] Experimental evaluation: the abstract asserts strong gains and strict dominance, yet the manuscript supplies no details on the number of random seeds, statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals), hyperparameter search protocol, or controls for post-hoc model selection. These omissions make it impossible to assess whether the reported Pareto dominance is robust or sensitive to experimental choices.
minor comments (2)
- [Deployment] The dynamic λ-sweep mechanism is described only at a high level; a short pseudocode block or explicit update rule would improve reproducibility.
- [Figures/Tables] Table or figure captions should explicitly state the number of sessions, models, and budget values used in each Pareto curve.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, providing clarifications and committing to revisions where the manuscript is incomplete. All changes will be incorporated in the revised version.
read point-by-point responses
-
Referee: [Hindsight Budget Relabeling] Hindsight Budget Relabeling section: the central performance numbers (6.0-73.5% cost reduction, <1% bankruptcy, Pareto dominance) rest entirely on the claim that the 2.38M relabeled transitions match the joint distribution of query difficulty, model choice, and budget-consumption trajectories that arise under varied global budgets in real sessions. No statistical comparison, Kolmogorov-Smirnov test, or ablation against held-out real-budget trajectories is reported; without this the learned Q-function and offline metrics are at risk of being artifacts of the synthetic distribution.
Authors: We agree that an explicit distributional validation (e.g., KS test or ablation on held-out real-budget trajectories) is absent. HBR is designed to preserve original query sequences and model choices while varying only the budget labels, thereby generating bankruptcy signals that are otherwise rare. The strong empirical outcomes (low bankruptcy, Pareto dominance) provide indirect support, but we acknowledge this is insufficient for rigorous validation. We will add a new subsection with statistical comparisons and an ablation against held-out real sessions. revision: yes
-
Referee: [MDP formulation] Finite-horizon MDP formulation (abstract and method): the state is defined to include remaining budget and the horizon is finite, yet no experiment tests whether this Markovian finite-horizon model captures non-Markovian effects such as topic drift or session-length variation beyond the training distribution. If longer or non-stationary sessions violate the assumption, both the CQL policy and the reported bankruptcy suppression may not transfer.
Authors: The MDP formulation treats remaining budget as part of the state to enable delayed gratification within finite sessions. Real evaluation sessions already contain natural variations in length and content; the observed performance gains and bankruptcy suppression indicate the model is effective on the tested data. However, we did not conduct dedicated experiments isolating topic drift or out-of-distribution session lengths. We will expand the discussion section to explicitly state this assumption and its potential limitations on transfer. revision: partial
-
Referee: [Experiments] Experimental evaluation: the abstract asserts strong gains and strict dominance, yet the manuscript supplies no details on the number of random seeds, statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals), hyperparameter search protocol, or controls for post-hoc model selection. These omissions make it impossible to assess whether the reported Pareto dominance is robust or sensitive to experimental choices.
Authors: We agree these experimental details are missing and limit assessment of robustness. The reported results were obtained from multiple independent runs, but the manuscript does not specify seed count, significance testing, or hyperparameter protocol. We will add a dedicated experimental details subsection reporting the number of seeds, bootstrap confidence intervals, hyperparameter search procedure, and controls for model selection. revision: yes
Circularity Check
No significant circularity; derivation uses standard MDP/RL components and data augmentation without self-referential reduction
full rationale
The paper formulates multi-turn routing as a finite-horizon MDP with budget in the state and applies Conservative Q-Learning (CQL), both established techniques. Hindsight Budget Relabeling (HBR) is presented as a data-generation procedure that retrospectively applies hypothetical budgets to 10k raw sessions to produce 2.38M transitions; this is an empirical augmentation step rather than a derivation that reduces the claimed performance metrics to fitted parameters by construction. No equations are shown that equate predictions to inputs, no self-citations are invoked as load-bearing uniqueness theorems, and the Pareto-frontier navigation via λ-sweep is a deployment heuristic. The central claims rest on offline RL training and reported empirical dominance, which do not collapse to tautology. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-turn user sessions can be represented as finite-horizon MDPs whose state includes remaining budget
Reference graph
Works this paper leans on
-
[1]
Hindsight experience replay.Advances in neural information processing systems, 30, 2017
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay.Advances in neural information processing systems, 30, 2017
2017
-
[2]
Amit Singh Bhatti, Vishal Vaddina, and Dagnachew Birru. PROTEUS: SLA-aware routing via lagrangian RL for multi-LLM serving systems.arXiv preprint arXiv:2601.19402, 2026
-
[3]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Lingjiao Chen, Matei Zaharia, and James Zou. Frugalgpt: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Learning to route LLMs with confidence tokens
Yu-Neng Chuang, Prathusha Kameswara Sarma, Parikshit Gopalan, John Boccio, Sara Bolouki, Xia Hu, and Helen Zhou. Learning to route LLMs with confidence tokens. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 10859–10878. PMLR, 2025
2025
-
[5]
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Rühle, Laks V . S. Lakshmanan, and Ahmed Hassan Awadallah. Hybrid llm: Cost-efficient and quality-aware query routing. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[6]
Dujian Ding, Ankur Mallick, Shaokun Zhang, Chi Wang, Daniel Madrigal, Mirian Del Car- men Hipolito Garcia, Menglin Xia, Laks V . S. Lakshmanan, Qingyun Wu, and Victor Rühle. BEST-route: Adaptive LLM routing with test-time optimal compute. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning R...
2025
-
[7]
GraphRouter: A graph-based router for LLM selections
Tao Feng, Yanzhen Shen, and Jiaxuan You. GraphRouter: A graph-based router for LLM selections. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[8]
LLMRouter: An open-source library for LLM routing
Tao Feng, Haozhen Zhang, Zijie Lei, Haodong Yue, Chongshan Lin, Ge Liu, and Jiaxuan You. LLMRouter: An open-source library for LLM routing. GitHub repository, 2025. Project page: https://ulab-uiuc.github.io/LLMRouter/
2025
-
[9]
RouterBench: A benchmark for multi-LLM routing system
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. RouterBench: A benchmark for multi-LLM routing system. Agentic Markets Workshop at ICML 2024, 2024
2024
-
[10]
Zhongzhan Huang, Guoming Ling, Yupei Lin, Yandong Chen, Shanshan Zhong, Hefeng Wu, and Liang Lin. RouterEval: A comprehensive benchmark for routing LLMs to explore model- level scaling up in LLMs.arXiv preprint arXiv:2503.10657, 2025
-
[11]
Ruihan Jin, Pengpeng Shao, Zhengqi Wen, Jinyang Wu, Mingkuan Feng, Shuai Zhang, and Jianhua Tao. RadialRouter: Structured representation for efficient and robust large language models routing.arXiv preprint arXiv:2506.03880, 2025
-
[12]
Offline reinforcement learning with implicit q-learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. InThe Tenth International Conference on Learning Representations, 2022
2022
-
[13]
Conservative q-learning for offline reinforcement learning
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. InAdvances in Neural Information Processing Systems 33, pages 1179–1191. Curran Associates, Inc., 2020
2020
-
[14]
Guannan Lai and Han-Jia Ye. When routing collapses: On the degenerate convergence of LLM routers.arXiv preprint arXiv:2602.03478, 2026
-
[15]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[16]
SelfBudgeter: Adaptive Token Allocation for Efficient LLM Reasoning
Zheng Li, Qingxiu Dong, Jingyuan Ma, Di Zhang, Kai Jia, and Zhifang Sui. SelfBudgeter: Adaptive token allocation for efficient LLM reasoning.arXiv preprint arXiv:2505.11274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
RouterArena: An open platform for comprehensive comparison of LLM routers
Yifan Lu, Rixin Liu, Jiayi Yuan, Xingqi Cui, Shenrun Zhang, Hongyi Liu, and Jiarong Xing. RouterArena: An open platform for comprehensive comparison of LLM routers. InThe Fourteenth International Conference on Learning Representations, 2026. 10
2026
-
[18]
Gonzalez, M
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M. Waleed Kadous, and Ion Stoica. RouteLLM: Learning to route LLMs from preference data. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[19]
Zhihong Pan, Kai Zhang, Yuze Zhao, and Yupeng Han. Route to reason: Adaptive routing for LLM and reasoning strategy selection.arXiv preprint arXiv:2505.19435, 2025
-
[20]
AdaptEvolve: Improving Efficiency of Evolutionary AI Agents through Adaptive Model Selection
Pretam Ray, Pratik Prabhanjan Brahma, Zicheng Liu, and Emad Barsoum. AdaptEvolve: Improving efficiency of evolutionary AI agents through adaptive model selection.arXiv preprint arXiv:2602.11931, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
CP-Router: An uncertainty-aware router between LLM and LRM.Proceedings of the AAAI Conference on Artificial Intelligence, 40(39):33065– 33073, 2026
Jiayuan Su, Fulin Lin, Zhaopeng Feng, Han Zheng, Teng Wang, Zhenyu Xiao, Xinlong Zhao, Zuozhu Liu, Lu Cheng, and Hongwei Wang. CP-Router: An uncertainty-aware router between LLM and LRM.Proceedings of the AAAI Conference on Artificial Intelligence, 40(39):33065– 33073, 2026
2026
-
[22]
Chenxu Wang, Hao Li, Yiqun Zhang, Linyao Chen, Jianhao Chen, Ping Jian, Peng Ye, Qiaosheng Zhang, and Shuyue Hu. ICL-Router: In-context learned model representations for LLM routing.arXiv preprint arXiv:2510.09719, 2025
-
[23]
Jize Wang, Han Wu, Zhiyuan You, Yiming Song, Yijun Wang, Zifei Shan, Yining Li, Songyang Zhang, Xinyi Le, Cailian Chen, Xinping Guan, and Dacheng Tao. RouteMoA: Dynamic routing without pre-inference boosts efficient mixture-of-agents.arXiv preprint arXiv:2601.18130, 2026
-
[24]
MixLLM: Dynamic routing in mixed large language models.arXiv preprint arXiv:2502.18482, 2025
Xinyuan Wang, Yanchi Liu, Wei Cheng, Xujiang Zhao, Zhengzhang Chen, Wenchao Yu, Yanjie Fu, and Haifeng Chen. MixLLM: Dynamic routing in mixed large language models.arXiv preprint arXiv:2502.18482, 2025
-
[25]
BudgetThinker: Empowering Budget-aware LLM Reasoning with Control Tokens
Hao Wen, Xinrui Wu, Yi Sun, Feifei Zhang, Liye Chen, Jie Wang, Yunxin Liu, Yunhao Liu, Ya-Qin Zhang, and Yuanchun Li. BudgetThinker: Empowering budget-aware LLM reasoning with control tokens.arXiv preprint arXiv:2508.17196, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Encheng Xie, Yihang Sun, Tao Feng, and Jiaxuan You. GMTRouter: Personalized LLM router over multi-turn user interactions.arXiv preprint arXiv:2511.08590, 2025
-
[27]
Budget-aware agentic routing via boundary-guided training.arXiv preprint arXiv:2602.21227, 2026
Caiqi Zhang, Menglin Xia, Xuchao Zhang, Daniel Madrigal, Ankur Mallick, Samuel Kessler, Victor Rühle, and Saravan Rajmohan. Budget-aware agentic routing via boundary-guided training.arXiv preprint arXiv:2602.21227, 2026
-
[28]
Router-R1: Teaching LLMs multi-round routing and aggregation via reinforcement learning
Haozhen Zhang, Tao Feng, and Jiaxuan You. Router-R1: Teaching LLMs multi-round routing and aggregation via reinforcement learning. InAdvances in Neural Information Processing Systems 38, 2025
2025
-
[29]
Jiarui Zhang, Xiangyu Liu, Yong Hu, Chaoyue Niu, Fan Wu, and Guihai Chen. RAGRouter: Learning to route queries to multiple retrieval-augmented language models.arXiv preprint arXiv:2505.23052, 2025
-
[30]
Let the LLM stick to its strengths: Learning to route economical LLM
Yi-Kai Zhang, Shiyin Lu, Qing-Guo Chen, Weihua Luo, De-Chuan Zhan, and Han-Jia Ye. Let the LLM stick to its strengths: Learning to route economical LLM. InAdvances in Neural Information Processing Systems 38, 2025
2025
-
[31]
Zheyuan Zhang, Kaiwen Shi, Zhengqing Yuan, Zehong Wang, Tianyi Ma, Keerthiram Muruge- san, Vincent Galassi, Chuxu Zhang, and Yanfang Ye. AgentRouter: A knowledge-graph-guided LLM router for collaborative multi-agent question answering.arXiv preprint arXiv:2510.05445, 2025. 11 A Implementation Details A.1 Data Generation Seed pool.We extract 10,000 first-t...
-
[32]
Find a logical bug, edge case, or demand a performance optimization. Be concise and blunt
Critical software engineer:“Find a logical bug, edge case, or demand a performance optimization. Be concise and blunt. ”
-
[33]
Complain that the answer is too complex, full of jargon, and demand a much simpler explanation with an analogy
Impatient beginner:“Complain that the answer is too complex, full of jargon, and demand a much simpler explanation with an analogy. ” 13
-
[34]
Acknowledge the current answer, but immediately introduce a brand new, highly restrictive constraint that forces a rewrite
Demanding client:“Acknowledge the current answer, but immediately introduce a brand new, highly restrictive constraint that forces a rewrite. ”
-
[35]
Pick one specific claim or step from the response and ask a probing ‘Why’ or ‘What is the theoretical justification for this’ question
Skeptical academic:“Pick one specific claim or step from the response and ask a probing ‘Why’ or ‘What is the theoretical justification for this’ question. ”
-
[36]
Ask the AI to clarify the last point using very simple vocabulary and short sentences
Non-native English speaker:“Ask the AI to clarify the last point using very simple vocabulary and short sentences. ”
-
[37]
Ask the AI to brainstorm 3 wild, unconventional alternatives based on its previous response
Creative writer:“Ask the AI to brainstorm 3 wild, unconventional alternatives based on its previous response. ” 7.Meticulous reviewer:“Ask the AI to format its previous response into a highly structured markdown table or a step-by-step numbered checklist. ”
-
[38]
Ask a naive but fundamentally deep ‘What if’ question related to the AI’s explanation
Curious child:“Ask a naive but fundamentally deep ‘What if’ question related to the AI’s explanation. ”
-
[39]
Question the safety, privacy, or ethical implications of the AI’s proposed solution
Security auditor:“Question the safety, privacy, or ethical implications of the AI’s proposed solution. ”
-
[40]
Demand a ‘TL;DR’ (Too Long; Didn’t Read) consisting of exactly two bullet points summarizing the bottom line
Busy executive:“Demand a ‘TL;DR’ (Too Long; Didn’t Read) consisting of exactly two bullet points summarizing the bottom line. ”
-
[41]
Strongly disagree with the AI’s conclusion and present a counter- argument, asking the AI to defend its stance
Devil’s advocate:“Strongly disagree with the AI’s conclusion and present a counter- argument, asking the AI to defend its stance. ”
-
[42]
Claim you tried what the AI suggested but got an unexpected error or completely different result, and ask for troubleshooting
Confused user:“Claim you tried what the AI suggested but got an unexpected error or completely different result, and ask for troubleshooting. ” H Broader Impacts SeqRoute enables more efficient LLM deployment by reducing unnecessary expensive-model invo- cations while maintaining response quality. This has positive environmental implications (reduced ener...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.