GeoSVG-RL: Geometry-Aware Reinforcement Learning for Layout-Constrained Text-to-SVG Diagram Generation
Pith reviewed 2026-06-29 22:10 UTC · model grok-4.3
The pith
A reinforcement learning method optimizes text-to-SVG generation against browser-rendered geometric rewards to improve diagram reliability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
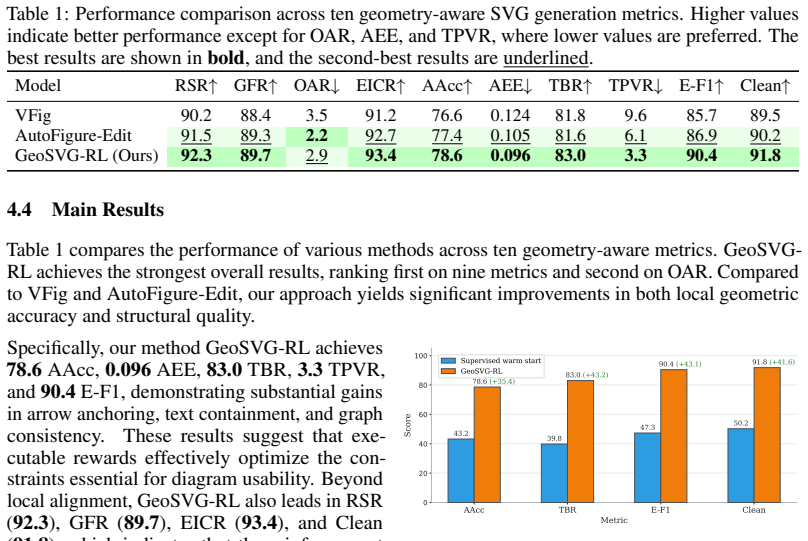
Optimizing the generation policy with explicit, executable geometric feedback from rendered SVGs rather than token-level likelihood produces diagrams with substantially improved structural reliability, particularly in arrow-anchor accuracy and text-in-box containment.
What carries the argument
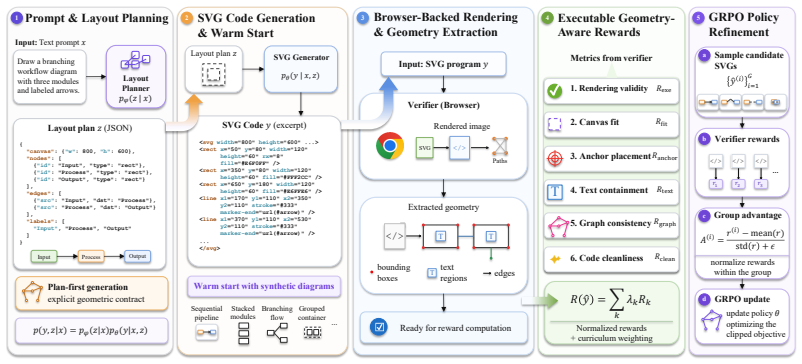
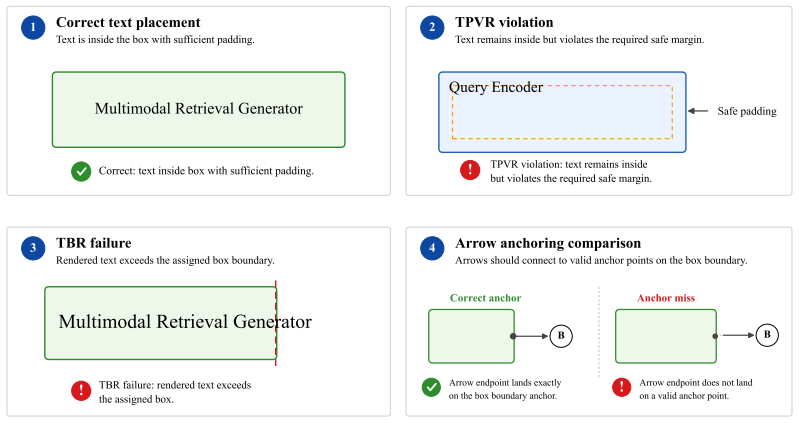
The browser-backed verifier that calculates fine-grained rewards on rendering validity, canvas fitting, precise anchor placement, text containment, graph consistency, and code cleanliness, paired with Group Relative Policy Optimization on multiple candidates per prompt.
If this is right
- Arrow-anchor accuracy and text containment rates increase substantially after the RL stage.
- Generated diagrams maintain graph connectivity more reliably than models trained only on token likelihood.
- The method establishes a pathway from synthetic-data warm-start to production-grade technical illustrations.
- Multi-candidate sampling with relative ranking enables stable policy updates without absolute reward scales.
Where Pith is reading between the lines
- The layout-plan-plus-verifier pattern could transfer to other spatially constrained code outputs such as HTML layouts or circuit diagrams.
- If the verifier dimensions prove composable, the same reward structure might support iterative refinement loops in interactive diagram tools.
- Larger base models fine-tuned with this geometric signal may close remaining gaps on highly complex multi-object scenes.
Load-bearing premise
The browser-backed verifier supplies accurate and unbiased rewards across the six dimensions that reliably improve the policy without creating new failure modes.
What would settle it
A side-by-side measurement on a held-out prompt set of anchor placement error rates and broken graph connections in SVGs from the RL model versus the supervised baseline.
Figures

read the original abstract
Generating structured, editable diagrams remains a significant challenge for contemporary large language models, despite their proficiency in general-purpose vector code generation. The primary difficulty lies in the structural fragility of the output; minor errors such as misaligned connector endpoints, text labels overlapping borders, or complex layouts drifting beyond the canvas boundaries render the resulting SVG files functionally unusable for professional applications. To address these issues, we introduce GeoSVG-RL, a specialized reinforcement learning framework designed for layout-constrained text-to-SVG generation. Unlike standard training objectives that rely solely on maximizing token-level likelihood, our approach optimizes the policy against explicit, executable geometric feedback. The model first produces a structured layout plan that serves as a geometric contract for the subsequent generation of the SVG code. This code is then rendered through a browser-backed verifier, enabling the calculation of fine-grained rewards across six critical dimensions: rendering validity, canvas fitting, precise anchor placement, text containment, graph consistency, and code cleanliness. We utilize Group Relative Policy Optimization (GRPO) to refine the model, sampling multiple candidates per prompt to facilitate updates based on relative quality. Starting from a supervised warm-start phase on synthetic data, GeoSVG-RL achieves substantial gains in structural reliability, particularly in arrow-anchor accuracy and text-in-box rates. Quantitative evaluations demonstrate that our method consistently outperforms current state-of-the-art systems in local geometric precision and the preservation of graph connectivity, providing a robust pathway toward automated yet reliable technical illustration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeoSVG-RL, a reinforcement learning framework for text-to-SVG diagram generation that first produces a structured layout plan and then optimizes the policy via Group Relative Policy Optimization (GRPO) against rewards from a browser-backed verifier. The verifier supplies scalar feedback across six dimensions (rendering validity, canvas fitting, precise anchor placement, text containment, graph consistency, and code cleanliness). The work starts from a supervised warm-start on synthetic data and claims substantial gains in structural reliability, with quantitative evaluations showing consistent outperformance over current state-of-the-art systems in local geometric precision and preservation of graph connectivity.
Significance. If the central empirical claims hold, the approach offers a concrete route to more reliable automated technical illustration by replacing token-level likelihood with executable geometric feedback. The use of relative policy optimization over multiple samples per prompt and the explicit multi-dimensional reward design are potentially reusable ideas for other structured generation tasks. However, the significance is limited by the absence of any reported numbers, baselines, or validation of the verifier itself.
major comments (2)
- [Abstract] Abstract: the central claim that 'quantitative evaluations demonstrate that our method consistently outperforms current state-of-the-art systems in local geometric precision and the preservation of graph connectivity' is stated without any supporting numbers, tables, baselines, or dataset details. This makes the primary empirical contribution impossible to assess from the manuscript as presented.
- [Method] Method description (six reward dimensions): the claim that the browser-backed verifier supplies reliable, unbiased rewards across rendering validity, canvas fitting, precise anchor placement, text containment, graph consistency, and code cleanliness lacks any ablation, error analysis, correlation with human judgment, or external validation. Because GRPO updates are driven directly by these scalar rewards, systematic bias in any dimension (e.g., lenient path parsing or incorrect bounding-box computation) would render the reported gains artifacts of reward hacking rather than genuine structural improvement.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below and commit to revisions that strengthen the presentation of our empirical results and the validation of the reward components.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'quantitative evaluations demonstrate that our method consistently outperforms current state-of-the-art systems in local geometric precision and the preservation of graph connectivity' is stated without any supporting numbers, tables, baselines, or dataset details. This makes the primary empirical contribution impossible to assess from the manuscript as presented.
Authors: We agree that the abstract would be improved by including concrete numerical support to allow immediate assessment of the claims. The body of the manuscript contains the full quantitative results, including tables with metrics on geometric precision and graph connectivity, comparisons against baselines, and details on the synthetic dataset. To address the concern directly, we will revise the abstract to incorporate key performance numbers and a brief description of the evaluation setup and baselines. revision: yes
-
Referee: [Method] Method description (six reward dimensions): the claim that the browser-backed verifier supplies reliable, unbiased rewards across rendering validity, canvas fitting, precise anchor placement, text containment, graph consistency, and code cleanliness lacks any ablation, error analysis, correlation with human judgment, or external validation. Because GRPO updates are driven directly by these scalar rewards, systematic bias in any dimension (e.g., lenient path parsing or incorrect bounding-box computation) would render the reported gains artifacts of reward hacking rather than genuine structural improvement.
Authors: We recognize that explicit validation of the verifier is necessary to substantiate the reliability of the rewards and to address potential concerns about bias or reward hacking. The rewards are computed from executable rendering in a browser environment, which provides objective geometric feedback. Nevertheless, we will add an ablation study on the six reward dimensions, an error analysis of the verifier outputs, and a correlation analysis with human judgments of diagram quality to the revised manuscript. This will include details on how each dimension is computed and any observed limitations. revision: yes
Circularity Check
No circularity; empirical RL optimization against external browser verifier.
full rationale
The provided abstract and description present GeoSVG-RL as an RL method (using GRPO) that optimizes against explicit rewards computed by an external browser-backed verifier across six rendering dimensions. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes are described. The central claim of outperformance rests on empirical results from this external feedback loop rather than any derivation that reduces to its own inputs by construction. This is the standard case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Siqi Chen, Xinyu Dong, Haolei Xu, Xingyu Wu, Fei Tang, Hang Zhang, Yuchen Yan, Lin- juan Wu, Wenqi Zhang, Guiyang Hou, Yongliang Shen, Weiming Lu, and Yueting Zhuang. Svgenius: Benchmarking llms in svg understanding, editing and generation.arXiv preprint arXiv:2506.03139, 2025
-
[2]
Qijia He, Xunmei Liu, Hammaad Memon, Ziang Li, Zixian Ma, Jaemin Cho, Jason Ren, Daniel S. Weld, and Ranjay Krishna. Vfig: Vectorizing complex figures in svg with vision- language models.arXiv preprint arXiv:2603.24575, 2026
-
[3]
Unisvg: A unified dataset for vector graphic understanding and generation with multimodal large language models
Jinke Li, Jiarui Yu, Chenxing Wei, Hande Dong, Qiang Lin, Liangjing Yang, Zhicai Wang, and Yanbin Hao. Unisvg: A unified dataset for vector graphic understanding and generation with multimodal large language models. InProceedings of the 33rd ACM International Conference on Multimedia, MM ’25, page 13156–13163, New York, NY , USA, 2025. Association for Com...
2025
-
[4]
Diagrameval: Evaluating llm-generated diagrams via graphs
Chumeng Liang and Jiaxuan You. Diagrameval: Evaluating llm-generated diagrams via graphs. arXiv preprint arXiv:2510.25761, 2025
-
[5]
Autofigure-edit: Generating editable scientific illustration.arXiv preprint arXiv:2603.06674, 2026
Zhen Lin, Qiujie Xie, Minjun Zhu, Shichen Li, Qiyao Sun, Enhao Gu, Yiran Ding, Ke Sun, Fang Guo, Panzhong Lu, Zhiyuan Ning, Yixuan Weng, and Yue Zhang. Autofigure-edit: Generating editable scientific illustration.arXiv preprint arXiv:2603.06674, 2026
-
[6]
TechING: Towards real world technical image understanding via VLMs
Tafazzul Nadeem, Bhavik Shangari, Manish Rai, Gagan Raj Gupta, and Ashutosh Modi. TechING: Towards real world technical image understanding via VLMs. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Findings of the Association for Computational Linguistics: EACL 2026, pages 2720–2749, Rabat, Morocco, March 2026. Association for Computational Linguistics
2026
-
[7]
Svgeditbench: A benchmark dataset for quantitative assessment of llm’s svg editing capabilities
Kunato Nishina and Yusuke Matsui. Svgeditbench: A benchmark dataset for quantitative assessment of llm’s svg editing capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 8142–8147, June 2024
2024
-
[8]
Svgeditbench v2: A benchmark for instruction-based svg editing, 2025
Kunato Nishina and Yusuke Matsui. Svgeditbench v2: A benchmark for instruction-based svg editing, 2025
2025
-
[9]
Juan Rodriguez, Haotian Zhang, Abhay Puri, Tianyang Zhang, Rishav Pramanik, Meng Lin, Xiaoqing Xie, Marco Terral, Darsh Kaushik, Aly Shariff, Perouz Taslakian, Spandana Gella, Sai Rajeswar, David Vazquez, Christopher Pal, and Marco Pedersoli. Vectorgym: A multitask benchmark for svg code generation, sketching, and editing.arXiv preprint arXiv:2603.29852, 2026
-
[10]
Rodriguez, Abhay Puri, Shubham Agarwal, Issam H
Juan A. Rodriguez, Abhay Puri, Shubham Agarwal, Issam H. Laradji, Pau Rodriguez, Sai Rajeswar, David Vazquez, Christopher Pal, and Marco Pedersoli. Starvector: Generating scalable vector graphics code from images and text.arXiv preprint arXiv:2312.11556, 2023
-
[11]
Juan A. Rodriguez, Haotian Zhang, Abhay Puri, Rishav Pramanik, Aarash Feizi, Pascal Wich- mann, Arnab Kumar Mondal, Mohammad Reza Samsami, Rabiul Awal, Perouz Taslakian, Span- dana Gella, Sai Rajeswar, David Vazquez, Christopher Pal, and Marco Pedersoli. Rendering- aware reinforcement learning for vector graphics generation. InThe Thirty-ninth Annual Conf...
2026
-
[12]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024
2024
-
[13]
Feiyu Wang, Jiayuan Yang, Zhiyuan Zhao, Da Zhang, Bingyu Li, Peng Liu, and Junyu Gao. Introsvg: Learning from rendering feedback for text-to-svg generation via an introspective generator-critic framework.arXiv preprint arXiv:2603.09312, 2026
-
[14]
Feiyu Wang, Zhiyuan Zhao, Yuandong Liu, Da Zhang, Junyu Gao, Hao Sun, and Xuelong Li. Svgen: Interpretable vector graphics generation with large language models.arXiv preprint arXiv:2508.09168, 2025. 10
-
[15]
Haomin Wang, Qi Wei, Qianli Ma, Shengyuan Ding, Jinhui Yin, Kai Chen, and Hongjie Zhang. Reliable reasoning in svg-llms via multi-task multi-reward reinforcement learning.arXiv preprint arXiv:2603.16189, 2026
-
[16]
Ximing Xing, Juncheng Hu, Guotao Liang, Jing Zhang, Dong Xu, and Qian Yu. Empowering llms to understand and generate complex vector graphics.arXiv preprint arXiv:2412.11102, 2024
-
[17]
Reason-svg: Enhancing structured reasoning for vector graphics generation with reinforcement learning, 2026
Ximing Xing, Ziteng Xue, Yandong Guan, Jing Zhang, Dong Xu, and Qian Yu. Reason-svg: Enhancing structured reasoning for vector graphics generation with reinforcement learning, 2026
2026
-
[18]
Omnisvg: A unified scalable vector graphics generation model.arXiv preprint arXiv:2504.06263, 2025
Yiying Yang, Wei Cheng, Sijin Chen, Xianfang Zeng, Fukun Yin, Jiaxu Zhang, Liao Wang, Gang Yu, Xingjun Ma, and Yu-Gang Jiang. Omnisvg: A unified scalable vector graphics generation model.arXiv preprint arXiv:2504.06263, 2025
-
[19]
Structural evaluation metrics for svg generation via leave-one-out analysis, 2026
Haonan Zhu, Adrienne Deganutti, Elad Hirsch, and Purvanshi Mehta. Structural evaluation metrics for svg generation via leave-one-out analysis, 2026
2026
-
[20]
Autofigure: Generating and refining publication-ready scientific illustrations
Minjun Zhu, Zhen Lin, Yixuan Weng, Panzhong Lu, Qiujie Xie, Yifan Wei, Sifan Liu, Qiyao Sun, and Yue Zhang. Autofigure: Generating and refining publication-ready scientific illustrations. arXiv preprint arXiv:2602.03828, 2026
-
[21]
Svgauge: Towards human-aligned evaluation for svg generation, 2025
Leonardo Zini, Elia Frigieri, Sebastiano Aloscari, Marcello Generali, Lorenzo Dodi, Robert Dosen, and Lorenzo Baraldi. Svgauge: Towards human-aligned evaluation for svg generation, 2025. 11 A Implementation Details A.1 Base Model The SVG generator is initialized from Qwen2.5-Coder-7B-Instruct, a pretrained autoregressive code model with 7B parameters. Thi...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.