Retrieval as Reasoning: Self-Evolving Agent-Native Retrieval via LLM-Wiki
Pith reviewed 2026-06-29 21:56 UTC · model grok-4.3
The pith
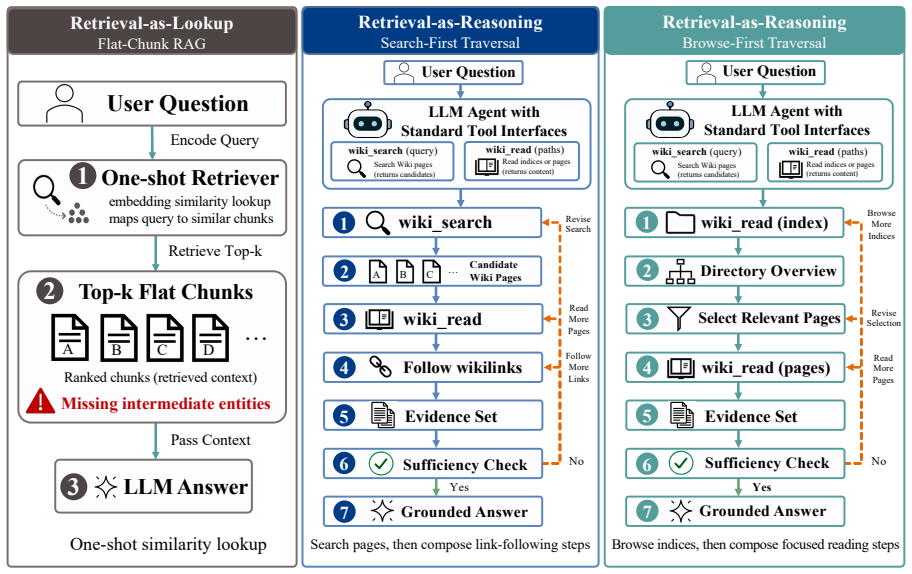
LLM-Wiki compiles documents into bidirectional-linked Wiki pages that agents navigate via tools to perform retrieval as iterative reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
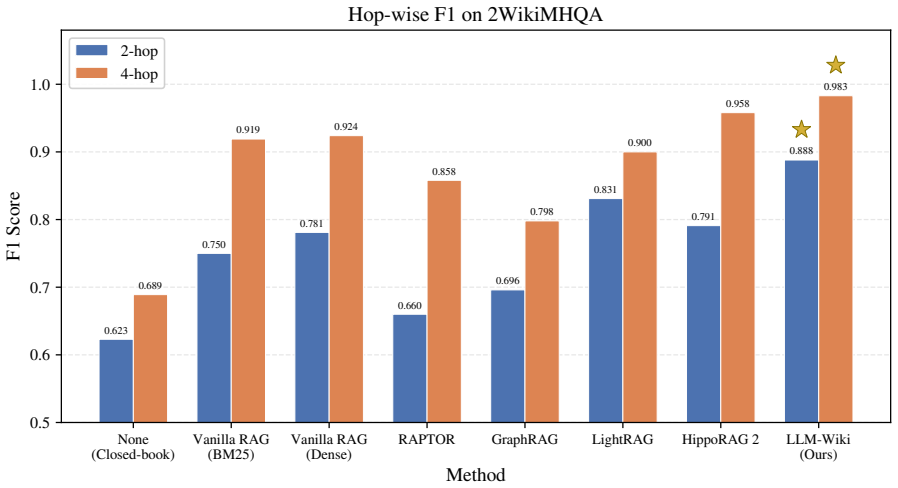
By compiling documents into Wiki pages with bidirectional links, exposing search/read/link-following through tool-calling, and maintaining an Error Book for self-correction, LLM-Wiki operationalizes retrieval as reasoning; agents thereby achieve state-of-the-art F1 scores on HotpotQA, MuSiQue, and 2WikiMultiHopQA and highest accuracy on AuthTrace, with largest gains on multi-document structured queries.
What carries the argument
LLM-Wiki, the compilation of documents into bidirectional-linked Wiki pages plus tool-calling interface and Error Book that together let agents treat retrieval as navigable reasoning steps.
If this is right
- Agents can follow links iteratively to gather evidence instead of receiving all context in one retrieval step.
- The Error Book enables persistent correction of both link structure and content semantics across sessions.
- The same compilation method improves performance on multi-document structured queries, not only chain-style multi-hop reasoning.
- Retrieval performance becomes tied to the quality of the compiled structure rather than solely to embedding similarity.
Where Pith is reading between the lines
- The bidirectional links could surface cross-document connections that embedding similarity alone would miss, allowing agents to discover implicit relations during traversal.
- A natural extension would be to let the agent itself trigger partial recompilation of affected Wiki pages when new documents arrive, rather than full re-indexing.
- The tool-calling interface could be standardized across agent frameworks so any LLM agent can use the same Wiki navigation primitives without custom integration.
Load-bearing premise
That giving agents tool access to a compiled Wiki with bidirectional links and an Error Book will produce meaningfully better iterative reasoning than flat embedding retrieval on the same tasks.
What would settle it
A controlled test in which agents equipped with the LLM-Wiki tools show no accuracy advantage over identical agents using standard embedding-based chunk retrieval on the same multi-hop and structured-query benchmarks.
Figures

read the original abstract
LLM agents require retrieval to behave less like one-shot context fetching and more like reasoning: searching, reading, traversing, and deciding when evidence is sufficient. Yet current Retrieval-Augmented Generation (RAG) systems organize external knowledge as flat chunks retrieved by embedding similarity, exposing a retrieval-as-lookup interface ill-suited to iterative reasoning agents. We propose LLM-Wiki, an agent-native retrieval system that operationalizes the Retrieval-as-Reasoning paradigm by treating external knowledge as a compilable, composable, and self-evolving structure rather than a static retrieval index. LLM-Wiki compiles documents into structured Wiki pages with bidirectional links, exposes search, read, and link-following operations through standard tool-calling interfaces, and introduces an Error Book for persistent structural and semantic self-correction. LLM-Wiki achieves state-of-the-art results on HotpotQA, MuSiQue, and 2WikiMultiHopQA, outperforming HippoRAG 2, LightRAG, and GraphRAG by 2.0-8.1 F1 points. On AuthTrace, LLM-Wiki achieves the best overall accuracy, with especially strong gains on multi-document structured queries, confirming that compilation-based retrieval generalizes beyond chain-style multi-hop reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LLM-Wiki, an agent-native retrieval system that compiles documents into structured Wiki pages with bidirectional links, exposes search/read/link-following via tool-calling interfaces, and introduces an Error Book for persistent self-correction. It claims state-of-the-art results on HotpotQA, MuSiQue, and 2WikiMultiHopQA (outperforming HippoRAG 2, LightRAG, and GraphRAG by 2.0-8.1 F1 points) and best overall accuracy on AuthTrace, with particular gains on multi-document structured queries.
Significance. If substantiated, the shift from flat embedding-based RAG to a compilable, traversable, self-evolving Wiki structure could support more iterative reasoning in LLM agents. The Error Book mechanism for structural and semantic correction is a distinctive element that, if shown to drive the gains, would strengthen the case for retrieval-as-reasoning paradigms.
major comments (1)
- [Abstract] Abstract: the claim of specific F1 gains and SOTA status is presented without any experimental details, baseline implementations, error analysis, statistical significance tests, or ablation studies; the full text absence prevents verification of whether the results support the central claim that the Wiki structure and Error Book produce meaningfully better iterative reasoning than flat retrieval.
Simulated Author's Rebuttal
We thank the referee for their review. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of specific F1 gains and SOTA status is presented without any experimental details, baseline implementations, error analysis, statistical significance tests, or ablation studies; the full text absence prevents verification of whether the results support the central claim that the Wiki structure and Error Book produce meaningfully better iterative reasoning than flat retrieval.
Authors: The abstract is a concise summary following standard conventions; detailed experimental information is provided in the full manuscript. Section 4 describes baseline implementations and experimental setup, Section 5.3 contains error analysis, Tables 2-4 and Appendix B report statistical significance tests, and Section 4.3 plus Table 3 present ablation studies. These sections substantiate that the Wiki structure and Error Book drive gains in iterative reasoning over flat retrieval. The full text was submitted with the manuscript; if access was unavailable during review, we can resupply it. revision: no
Circularity Check
No significant circularity; empirical system proposal with no derivations
full rationale
The provided text consists solely of the abstract describing a proposed retrieval system (LLM-Wiki) and its empirical benchmark results. No equations, first-principles derivations, fitted parameters presented as predictions, or load-bearing self-citations appear. Performance claims are framed as experimental outcomes on HotpotQA, MuSiQue, 2WikiMultiHopQA, and AuthTrace without any reduction to inputs by construction. The full manuscript is referenced but not supplied here, and the abstract contains no technical steps amenable to circularity analysis. This is the expected non-finding for a system-description paper lacking mathematical claims.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
AuthTrace: Diagnosing Evidence Construction in Thematically Dense Single-Author Corpora
AuthTrace is a diagnostic benchmark that annotates fan-in gradients in single-author corpora to measure evidence recall, precision, and answer correctness across eight systems in retrieval, memory, graph, and structur...
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. https://openreview.net/forum?id=hSyW5go0v8 Self- RAG : Learning to retrieve, generate, and critique through self-reflection . In Proceedings of the Twelfth International Conference on Learning Representations (ICLR)
2024
-
[4]
Howard Chen, Ramakanth Pasunuru, Jason Weston, and Asli Celikyilmaz. 2023. https://doi.org/10.48550/arXiv.2310.05029 Walking down the memory maze: Beyond context limit through interactive reading . Preprint, arXiv:2310.05029
-
[5]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. https://doi.org/10.48550/arXiv.2404.16130 From local to global: A graph RAG approach to query-focused summarization . Preprint, arXiv:2404.16130
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.16130 2024
-
[6]
GLM-5-Team . 2026. https://doi.org/10.48550/arXiv.2602.15763 GLM-5 : from vibe coding to agentic engineering . Preprint, arXiv:2602.15763
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.15763 2026
-
[7]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.568 L ight RAG : Simple and fast retrieval-augmented generation . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 10746--10761, Suzhou, China. Association for Computational Linguistics
-
[8]
Bernal Jim \'e nez Guti \'e rrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. 2024. https://doi.org/10.52202/079017-1902 HippoRAG : Neurobiologically inspired long-term memory for large language models . In Advances in Neural Information Processing Systems, volume 37
-
[9]
Bernal Jim \'e nez Guti \'e rrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. 2025. https://proceedings.mlr.press/v267/gutierrez25a.html From RAG to memory: Non-parametric continual learning for large language models . In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages ...
2025
-
[10]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. https://doi.org/10.18653/v1/2020.coling-main.580 Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps . In Proceedings of the 28th International Conference on Computational Linguistics, pages 6609--6625. International Committee on Computational Linguistics
-
[11]
Andrej Karpathy. 2026. https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f LLM Wiki . GitHub Gist. Accessed: 2026-05-19
2026
-
[12]
Vladimir Karpukhin, Barlas O g uz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.550 Dense passage retrieval for open-domain question answering . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769--6781, Online. A...
-
[13]
J. Richard Landis and Gary G. Koch. 1977. https://doi.org/10.2307/2529310 The measurement of observer agreement for categorical data . Biometrics, 33(1):159--174
-
[14]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. 2020. https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html Retrieval-augmented generation for knowledge-intensive NLP ...
2020
-
[15]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/hash/91edff07232fb1b55a505a9e9f6c0ff3-Abs...
2023
-
[16]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. https://openreview.net/forum?id=GN921JHCRw RAPTOR : Recursive abstractive processing for tree-organized retrieval . In Proceedings of the Twelfth International Conference on Learning Representations (ICLR)
2024
-
[17]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/hash/1b44b878bb782e6954cd888628510e90-Abstract-Conference.html Reflexion: Language agents with verbal reinforcement learning . In Advances in Neural Information Processing Systems, volume 36
2023
-
[18]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. https://doi.org/10.1162/tacl_a_00475 MuSiQue : Multihop questions via single-hop question composition . Transactions of the Association for Computational Linguistics, 10:539--554
-
[19]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2023. https://doi.org/10.18653/v1/2023.acl-long.557 Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10014...
-
[20]
Xiaoqing Wu, Feifei Li, Haoliang Ming, and Wenhui Que. 2026. https://arxiv.org/abs/2605.25382 AuthTrace : Diagnosing evidence construction in thematically dense single-author corpora . Preprint, arXiv:2605.25382
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. https://doi.org/10.18653/v1/D18-1259 HotpotQA : A dataset for diverse, explainable multi-hop question answering . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369--2380, Brussel...
-
[22]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. https://openreview.net/forum?id=WE_vluYUL-X ReAct : Synergizing reasoning and acting in language models . In Proceedings of the Eleventh International Conference on Learning Representations (ICLR)
2023
-
[23]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. https://doi.org/10.48550/arXiv.2506.05176 Qwen3 Embedding : Advancing text embedding and reranking through foundation models . Preprint, arXiv:2506.05176
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[24]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/91f18a1287b398d378ef22505bf41832-Paper-Datasets_and_Benchmarks.pdf Judging LLM -as-a-judge with MT -bench and ch...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.