SafetyRepro: Configuration-Conditional Rank Instability on Alignment Benchmarks
Pith reviewed 2026-06-29 22:48 UTC · model grok-4.3
The pith
Harness configuration choices alone can reverse which model ranks safer on every alignment benchmark tested.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
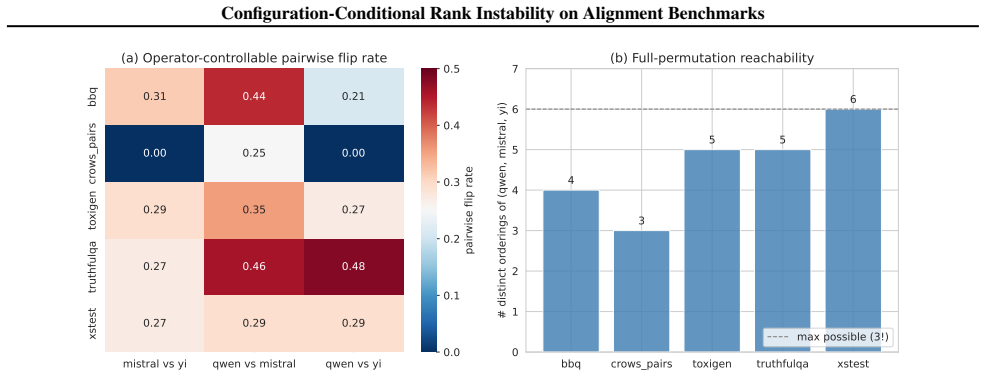
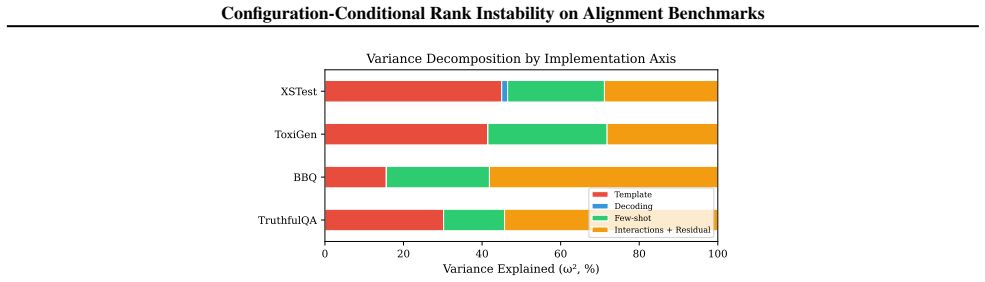
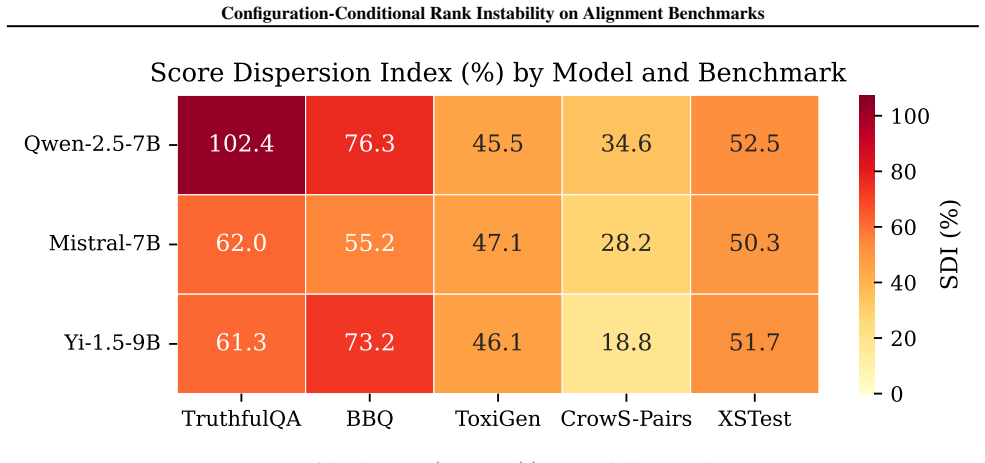
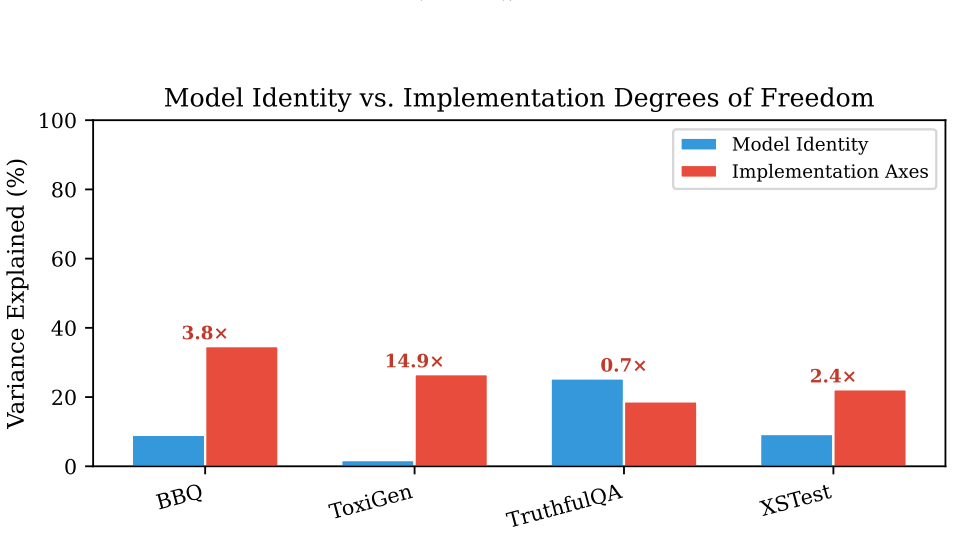
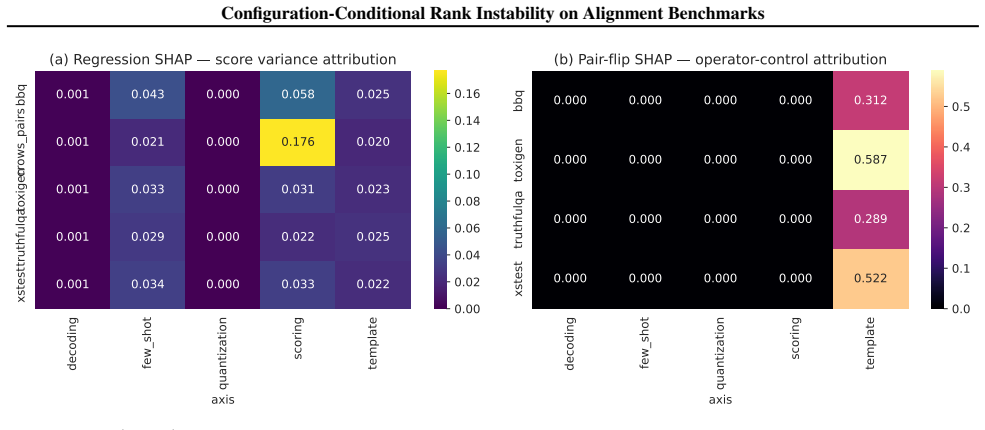
A finite-envelope proposition establishes that a measurable pairwise-disagreement rate implies the strict ordering admits a configuration-pair reversal; when this protocol is run on standard alignment benchmarks, every tested case exhibits at least one such reversal driven solely by harness configuration.
What carries the argument
The finite-envelope proposition, which connects a pairwise-disagreement rate directly to the existence of a configuration-pair reversal for the strict ordering.
If this is right
- Pairwise safety verdicts must be accompanied by explicit configuration envelopes rather than single harness runs.
- Any claim that model A is safer than model B on a given benchmark becomes conditional on the chosen configuration set.
- Reproducibility protocols for alignment evaluations require commit-stamped configuration enumeration to bound reversal risk.
- Benchmark papers that under-specify harness choices leave open the possibility that their reported orderings are not invariant.
Where Pith is reading between the lines
- The same configuration sensitivity may affect non-safety alignment tasks that rely on pairwise model comparisons.
- Future evaluation suites could report disagreement rates as a standard diagnostic alongside raw scores.
- If reversals prove widespread, aggregate leaderboards may need to shift from point estimates to configuration-robust intervals.
Load-bearing premise
The finite-envelope proposition accurately connects a measurable disagreement rate to the possibility of a strict ordering reversal without extra assumptions about how configurations or outputs are distributed.
What would settle it
A single alignment benchmark on which no pair of harness configurations produces a reversal of the reported strict model ordering, or a counter-example showing the proposition fails to tie disagreement rate to reversal existence.
Figures




read the original abstract
Pairwise model comparisons drawn from foundation-model benchmarks ("A is safer than B") are read as quantitative verdicts but hinge on harness choices benchmark papers under-specify. We close one theory-benchmark loop on this primitive: a finite-envelope proposition tying a measurable pairwise-disagreement rate to whether the strict ordering admits a configuration-pair reversal, paired with a commit-stamped evaluation protocol that operationalises it on widely cited alignment benchmarks. On every benchmark we test, configuration choice alone can flip the pairwise verdict; the proposition isolates this strict-reversal failure mode.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a finite-envelope proposition that connects an observable pairwise-disagreement rate on alignment benchmarks to the existence of a configuration-pair reversal in the strict model ordering. It pairs this with a commit-stamped evaluation protocol and reports that, across every benchmark examined, harness configuration choices alone suffice to flip pairwise safety verdicts between models.
Significance. If the finite-envelope proposition is tight and the empirical protocol reproducible, the result would demonstrate a concrete, previously under-quantified source of instability in safety benchmark rankings, with direct implications for how pairwise comparisons are interpreted in alignment research.
major comments (1)
- [finite-envelope proposition (§3)] The finite-envelope proposition (abstract and §3): the claimed link from measurable pairwise-disagreement rate to guaranteed existence of a strict-reversal configuration pair is asserted to hold without further assumptions on harness distributions or output correlations. In finite samples this implication is not automatic; disagreement can arise from sampling variance or cross-configuration dependence even when no single pair reverses the ordering. The empirical claim that flips occur on every benchmark therefore depends on the proposition being distribution-free in the stated sense; the manuscript does not supply the missing uniformity or independence condition that would convert rate into guaranteed reversal.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for identifying the need to clarify the conditions of the finite-envelope proposition. We address the comment below and will revise the manuscript accordingly to improve clarity.
read point-by-point responses
-
Referee: The finite-envelope proposition (abstract and §3): the claimed link from measurable pairwise-disagreement rate to guaranteed existence of a strict-reversal configuration pair is asserted to hold without further assumptions on harness distributions or output correlations. In finite samples this implication is not automatic; disagreement can arise from sampling variance or cross-configuration dependence even when no single pair reverses the ordering. The empirical claim that flips occur on every benchmark therefore depends on the proposition being distribution-free in the stated sense; the manuscript does not supply the missing uniformity or independence condition that would convert rate into guaranteed reversal.
Authors: The finite-envelope proposition is a deterministic, combinatorial result that applies directly to any finite set of observed evaluation outcomes under the commit-stamped protocol. It does not invoke probabilistic assumptions on harness distributions, output correlations, or sampling; instead, it derives the existence of a reversing configuration pair from the structure of the observed pairwise disagreements via the envelope construction. Because each configuration is evaluated to a fixed, reproducible outcome (via commit-stamping), there is no residual sampling variance in the reported disagreement rates. Cross-configuration dependence is irrelevant to the implication, as the proposition concerns only the realized verdicts. We will add a paragraph in §3 explicitly stating the deterministic character of the result and confirming that no distributional assumptions are required. revision: yes
Circularity Check
No circularity: finite-envelope proposition presented as independent theoretical link
full rationale
The paper's central device is a finite-envelope proposition that mathematically connects an observable pairwise-disagreement rate to the existence of a configuration-pair reversal for strict orderings. No equation or definition in the provided text reduces this link to a fitted parameter, self-referential definition, or self-citation chain; the proposition is stated as holding without further distributional assumptions and is then operationalized via an evaluation protocol on external benchmarks. The empirical observation that flips occur on every tested benchmark is presented as a consequence of applying the proposition, not as input that defines it. This satisfies the default expectation of a self-contained derivation with no load-bearing reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The finite-envelope proposition accurately maps pairwise-disagreement rate to the possibility of strict ordering reversal under configuration changes.
Forward citations
Cited by 2 Pith papers
-
When AUC 0.998 Is Not Enough: A Candidate Evaluation Protocol for Hidden-State Probes of Indirect Prompt Injection in Multimodal Computer-Use Agents
High AUC from linear probes on model activations for indirect prompt injection does not license an unqualified claim of malicious-content detection, per a Qwen2.5-VL-7B case study with text and visual controls.
-
Chains That See, Answers That Don't: A Multi-Aspect Evaluation Recipe for Forced Chain-of-Thought on Video-MME
Forced CoT produces video-dependent reasoning chains but does not improve MCQ accuracy on Qwen2.5-VL with Video-MME and causes a small drop on the 7B variant.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Yi-1.5-9B-Chat model card
01.AI . Yi-1.5-9B-Chat model card. Hugging Face: https://huggingface.co/01-ai/Yi-1.5-9B-Chat, 2024
2024
-
[3]
Yi: Open Foundation Models by 01.AI
01.AI , Young, A., Chen, B., Li, C., Huang, C., Zhang, G., Zhang, G., Li, H., Zhu, J., Chen, J., Chang, J., et al. Yi : Open foundation models by 01. AI . arXiv:2403.04652, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
and Hochberg, Y
Benjamini, Y. and Hochberg, Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. Journal of the Royal Statistical Society, Series B, 57 0 (1): 0 289--300, 1995
1995
-
[5]
Lessons from the Trenches on Reproducible Evaluation of Language Models
Biderman, S., Schoelkopf, H., Sutawika, L., Gao, L., Tow, J., Abbasi, B., Aji, A. F., Ammanamanchi, P. S., Black, S., Clive, J., et al. Lessons from the trenches on reproducible evaluation of language models. arXiv preprint arXiv:2405.14782, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
L., Lopez, G., Olteanu, A., Sim, R., and Wallach, H
Blodgett, S. L., Lopez, G., Olteanu, A., Sim, R., and Wallach, H. Stereotyping N orwegian salmon: An inventory of pitfalls in fairness benchmark datasets. In Proc.\ Annual Meeting of the Association for Computational Linguistics (ACL), 2021
2021
-
[7]
E., Michalski, V., Serdyuk, D., Arbel, T., Pal, C., Varoquaux, G., and Vincent, P
Bouthillier, X., Delaunay, P., Bronzi, M., Trofimov, A., Nichyporuk, B., Szeto, J., Sepah, N., Raff, E., Madan, K., Voleti, V., Kahou, S. E., Michalski, V., Serdyuk, D., Arbel, T., Pal, C., Varoquaux, G., and Vincent, P. Accounting for variance in machine learning benchmarks. In Proc.\ Conference on Machine Learning and Systems (MLSys), 2021. arXiv:2103.0...
-
[8]
Bradley, R. A. and Terry, M. E. Rank analysis of incomplete block designs: I . the method of paired comparisons. Biometrika, 39 0 (3/4): 0 324--345, 1952
1952
-
[9]
Brennan, R. L. Generalizability Theory. Springer, 2001
2001
-
[10]
Campbell, D. T. and Fiske, D. W. Convergent and discriminant validation by the multitrait-multimethod matrix. Psychological Bulletin, 56 0 (2): 0 81--105, 1959
1959
-
[11]
Cronbach, L. J. and Meehl, P. E. Construct validity in psychological tests. Psychological Bulletin, 52 0 (4): 0 281--302, 1955
1955
-
[12]
J., Gleser, G
Cronbach, L. J., Gleser, G. C., Nanda, H., and Rajaratnam, N. The Dependability of Behavioral Measurements: Theory of Generalizability for Scores and Profiles. Wiley, 1972
1972
-
[13]
QLoRA: Efficient Finetuning of Quantized LLMs
Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L. QLoRA : Efficient finetuning of quantized LLMs . In Advances in Neural Information Processing Systems (NeurIPS), 2023. arXiv:2305.14314, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [14]
-
[15]
and Tibshirani, R
Efron, B. and Tibshirani, R. J. An Introduction to the Bootstrap. Chapman & Hall/CRC, 1993
1993
-
[16]
lm-evaluation-harness : Version v0.4.5
EleutherAI . lm-evaluation-harness : Version v0.4.5. Zenodo: https://zenodo.org/records/13905736, 2024. Software release used in this paper
-
[17]
and Loken, E
Gelman, A. and Loken, E. The garden of forking paths: Why multiple comparisons can be a problem, even when there is no ``fishing expedition'' or ``p-hacking'' and the research hypothesis was posited ahead of time. Technical report, Department of Statistics, Columbia University, 2013
2013
-
[18]
Grattafiori, A., Dubey, A., et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
ToxiGen : A large-scale machine-generated dataset for adversarial and implicit hate speech detection
Hartvigsen, T., Gabriel, S., Palangi, H., Sap, M., Ray, D., and Kamar, E. ToxiGen : A large-scale machine-generated dataset for adversarial and implicit hate speech detection. In Proc.\ Association for Computational Linguistics (ACL), 2022. arXiv:2203.09509, 2022
-
[20]
Hays, W. L. Statistics. Harcourt Brace, 5th edition, 1994
1994
-
[21]
A simple sequentially rejective multiple test procedure
Holm, S. A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics, 6 0 (2): 0 65--70, 1979
1979
-
[22]
Jacobs, A. Z. and Wallach, H. Measurement and fairness. In Proc.\ ACM Conference on Fairness, Accountability, and Transparency (FAccT), 2021
2021
-
[23]
Mrag-suite: A diagnostic evaluation platform for visual retrieval-augmented generation
Ji, Y., Lan, W., and NG, P. Mrag-suite: A diagnostic evaluation platform for visual retrieval-augmented generation. arXiv preprint arXiv:2509.24253, 2025 a
-
[24]
M., Li, Z., Wu, X., Visweswaran, S., and Wang, Y
Ji, Y., Ma, W., Sivarajkumar, S., Zhang, H., Sadhu, E. M., Li, Z., Wu, X., Visweswaran, S., and Wang, Y. Mitigating the risk of health inequity exacerbated by large language models. npj Digital Medicine, 8 0 (1): 0 246, 2025 b . ISSN 2398-6352. doi:10.1038/s41746-025-01576-4. URL https://doi.org/10.1038/s41746-025-01576-4
-
[25]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. Mistral 7 B . arXiv:2310.06825, 2023. Base model technical report; Mistral-7B-Instruct-v0.3 is a later release in the same family
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Lightgbm: A highly efficient gradient boosting decision tree
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., and Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[27]
S., Reid, M., Matsuo, Y., and Iwasawa, Y
Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iwasawa, Y. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022
2022
-
[28]
Attention consistency for LLM s explanation
Lan, T., Xu, J., He, X., Hwang, J.-N., and Li, L. Attention consistency for LLM s explanation. In Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 1736--1750, Suzhou, China, 2025. Association for Computational Linguistics. doi:10.18653/v1/2025.findings-emnlp.91. URL https://aclanthology.org/2025.findings-emnlp.91/
-
[29]
Anova for unbalanced data: Use T ype II instead of T ype III sums of squares
Langsrud, . Anova for unbalanced data: Use T ype II instead of T ype III sums of squares. Statistics and Computing, 13 0 (2): 0 163--167, 2003
2003
-
[30]
Holistic evaluation of language models
Liang, P., Bommasani, R., Lee, T., et al. Holistic evaluation of language models. Transactions on Machine Learning Research (TMLR), 2023
2023
-
[31]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Lin, S., Hilton, J., and Evans, O. TruthfulQA : Measuring how models mimic human falsehoods. In Proc.\ Association for Computational Linguistics (ACL), 2022. arXiv:2109.07958, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Lundberg, S. M. and Lee, S.-I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[33]
Agentauditor: Human-level safety and security evaluation for LLM agents
Luo, H., Dai, S., Ni, C., Li, X., Zhang, G., Wang, K., Liu, T., and Salam, H. Agentauditor: Human-level safety and security evaluation for LLM agents. In Advances in Neural Information Processing Systems 38 (NeurIPS 2025), 2025
2025
-
[34]
BiasIG: Benchmarking Multi-dimensional Social Biases in Text-to-Image Models
Luo, H., Huang, Z., Huang, H., Deng, Z., Chen, R., Li, X., Liu, Z., and Salam, H. Biasig: Benchmarking multi-dimensional social biases in text-to-image models. arXiv preprint arXiv:2604.11934, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Validity
Messick, S. Validity. In Linn, R. L. (ed.), Educational Measurement, pp.\ 13--103. American Council on Education / Macmillan, 3rd edition, 1989
1989
-
[36]
Mistral-7B-Instruct-v0.3 model card
Mistral AI . Mistral-7B-Instruct-v0.3 model card. Hugging Face: https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3, 2024
2024
-
[37]
State of what art? A call for multi-prompt LLM evaluation
Mizrahi, M., Kaplan, G., Malkin, D., Dror, R., Shahaf, D., and Stanovsky, G. State of what art? A call for multi-prompt LLM evaluation. Transactions of the Association for Computational Linguistics, 2024. First appeared 2023; arXiv:2401.00595
- [38]
-
[39]
BBQ: A Hand-Built Bias Benchmark for Question Answering
Parrish, A., Chen, A., Nangia, N., Padmakumar, V., Phang, J., Thompson, J., Htut, P. M., and Bowman, S. R. BBQ : A hand-built bias benchmark for question answering. In Findings of the Association for Computational Linguistics (ACL), 2022. arXiv:2110.08193, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Qwen2.5-7B-Instruct model card
Qwen Team . Qwen2.5-7B-Instruct model card. Hugging Face: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct, 2024
2024
-
[41]
Qwen Team , Yang, A., Yang, B., Zhang, B., Hui, B., et al. Qwen2.5 technical report. arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
and Paullada, Amandalynne and Denton, Emily and Hanna, Alex , month = nov, year =
Raji, I. D., Denton, E., Bender, E. M., Hanna, A., and Paullada, A. AI and the everything in the whole wide world benchmark. In Proc.\ NeurIPS Datasets and Benchmarks Track, 2021. arXiv:2111.15366, 2021
-
[43]
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models
R \"o ttger, P., Kirk, H. R., Vidgen, B., Attanasio, G., Bianchi, F., and Hovy, D. XSTest : A test suite for identifying exaggerated safety behaviours in large language models. In Proc.\ NAACL, 2024. arXiv:2308.01263, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Sclar, M., Choi, Y., Tsvetkov, Y., and Suhr, A. Quantifying language models' sensitivity to spurious features in prompt design or: H ow i learned to start worrying about prompt formatting. In Proc.\ International Conference on Learning Representations (ICLR), 2024. arXiv:2310.11324, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Scaling law for time series forecasting
Shi, J., Ma, Q., Ma, H., and Li, L. Scaling law for time series forecasting. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[46]
P., Nelson, L
Simmons, J. P., Nelson, L. D., and Simonsohn, U. False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science, 22 0 (11): 0 1359--1366, 2011
2011
-
[47]
crfm-helm : Version 0.5.5
Stanford CRFM . crfm-helm : Version 0.5.5. PyPI: https://pypi.org/project/crfm-helm/0.5.5/, 2025. Software release; HELM-lite 0.5.5+ used in this paper
2025
-
[48]
inspect-ai : Version 0.3.21
UK AI Safety Institute . inspect-ai : Version 0.3.21. PyPI: https://pypi.org/project/inspect-ai/0.3.21/, 2024. Software release used in this paper (release date 2024-08-07)
2024
-
[49]
Inspect: An open-source framework for large language model evaluations
UK AI Security Institute . Inspect: An open-source framework for large language model evaluations. https://inspect.aisi.org.uk/, 2024. Software, version 0.3.21 used in this paper
2024
-
[50]
H., Le, Q
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E. H., Le, Q. V., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9,...
2022
-
[51]
Large language models are not robust multiple choice selectors
Zheng, C., Zhou, H., Meng, F., Zhou, J., and Huang, M. Large language models are not robust multiple choice selectors. In Proc.\ International Conference on Learning Representations (ICLR), 2024. arXiv:2309.03882, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.