What Gets Cited: Competitive GEO in AI Answer Engines
Pith reviewed 2026-06-29 22:09 UTC · model grok-4.3
The pith
Topical relevance and list position are the biggest drivers of which source AI answer engines cite first.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In paired trials where exactly two sources compete inside the model context, statistical models attribute the largest share of variance in first-citation likelihood to how closely a source matches the query topic and where it sits in the supplied list, with the addition of concrete price figures and up-to-date timestamps producing reliable secondary gains.
What carries the argument
The two-document RAG testbed that inserts exactly two candidate sources per trial and records the source of the first citation marker, run under a full factorial design over 18 content factors with brand anonymization and counterbalanced order.
If this is right
- Topical relevance produces the largest increase in first-citation probability.
- Higher list position raises the chance a source is cited first.
- Including explicit price information improves citation likelihood across models.
- Adding a recent timestamp yields consistent citation gains.
- Formatting-only changes produce negligible effects on citation order.
Where Pith is reading between the lines
- Content teams could run similar paired tests on their own material to rank which edits to implement first.
- The protocol may scale to three or more competing documents to check whether the same factors dominate in larger contexts.
- The checklist could be adapted to measure citation share rather than binary first-citation outcome in production systems.
- The findings imply that freshness and specificity signals may matter more for AI answers than for traditional search rankings.
Load-bearing premise
The controlled two-document RAG testbed with brand anonymization and counterbalanced source order isolates content effects from position bias in a way that generalizes to real-world AI answer engines.
What would settle it
If the same content variations are tested inside a live multi-source AI answer engine and citation rates show no consistent relationship with topical relevance scores or list position, the central claim would be falsified.
Figures

read the original abstract
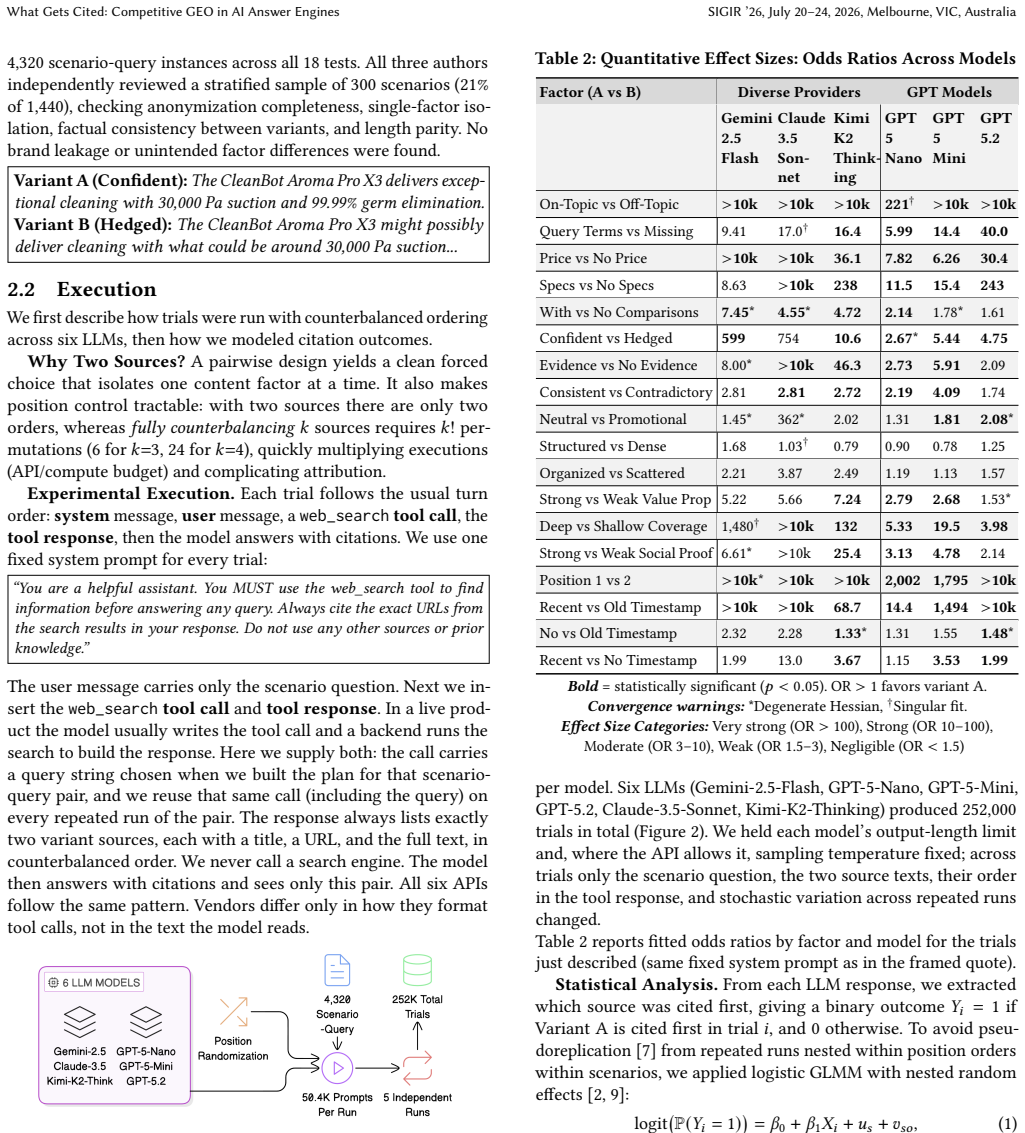
AI answer engines generate answers from retrieved pages but cite only a few sources. This makes visibility depend not just on ranking, but on being cited. We study competitive Generative Engine Optimization (GEO): when two retrieved candidates compete, what makes one more likely to be cited first? We build a controlled two-document retrieval-augmented generation (RAG) testbed that injects exactly two candidate sources into the model context and measures which source is referenced by the first citation marker in the output. Across six LLMs we execute 252,000 trials, repeated paired comparisons under one factorial program over 18 content factors. In each trial the two sources differ in exactly one factor; we use brand anonymization and counterbalanced source order to separate content effects from position bias. Mixed-effects models show that topical relevance and list position are the biggest drivers of being cited first. Including explicit price information and a recent timestamp also helps consistently. Completeness and trust cues add smaller gains, while formatting-only edits have little impact. We release a reproducible evaluation protocol and a prioritized GEO checklist for practitioners, and we exercised it in an early internal pilot at Sprinklr, where teams reported positive qualitative feedback on workflow usability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in a controlled two-document RAG testbed with 252,000 trials across six LLMs, mixed-effects models identify topical relevance and list position as the primary drivers of a source being cited first in AI answer engines, with explicit price information and recent timestamps providing consistent benefits, while completeness/trust cues add smaller gains and formatting edits have little impact. The study uses brand anonymization, counterbalanced order, and a factorial design over 18 content factors, and releases a reproducible protocol plus a prioritized GEO checklist.
Significance. If the central empirical findings hold and generalize, the work offers a large-scale, factorial empirical basis for understanding citation selection in generative engines, with explicit credit due to the 252k trial count, use of mixed-effects models for repeated paired comparisons, and release of a reproducible evaluation protocol. These elements strengthen the contribution beyond typical small-scale GEO studies.
major comments (2)
- [Abstract] Abstract: the central claim that topical relevance, list position, price information, and timestamp are the biggest drivers 'in AI answer engines' rests on a two-document testbed; the manuscript provides no evidence or discussion that these effect rankings survive when retrieval sets contain 10–50+ documents with variable context lengths and synthesis interactions, which is load-bearing for external validity.
- [Abstract] Abstract: the abstract states that mixed-effects models were used to identify the drivers but reports no model specifications, random effects structure, exclusion criteria, or error-handling procedures; without these details the reported effect rankings cannot be independently assessed or reproduced from the 252k trials.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that topical relevance, list position, price information, and timestamp are the biggest drivers 'in AI answer engines' rests on a two-document testbed; the manuscript provides no evidence or discussion that these effect rankings survive when retrieval sets contain 10–50+ documents with variable context lengths and synthesis interactions, which is load-bearing for external validity.
Authors: We agree the study is restricted to a controlled two-document RAG testbed, selected specifically to enable precise isolation of 18 factors via 252k paired trials with brand anonymization and counterbalancing. The manuscript frames its contribution as identifying drivers in competitive two-source citation selection rather than claiming generalizability. We will revise the abstract to explicitly delimit the two-document scope and add a limitations subsection noting that extension to larger retrieval sets with synthesis interactions is an important direction for future research. revision: yes
-
Referee: [Abstract] Abstract: the abstract states that mixed-effects models were used to identify the drivers but reports no model specifications, random effects structure, exclusion criteria, or error-handling procedures; without these details the reported effect rankings cannot be independently assessed or reproduced from the 252k trials.
Authors: The full model specifications—including random effects (intercepts for LLM and trial pair), exclusion criteria for malformed outputs, and error-handling—are reported in Section 3.3 and Appendix B. The abstract is a high-level summary. We will add a sentence in the abstract directing readers to the Methods and supplementary materials for complete reproducibility details. revision: yes
Circularity Check
No circularity: empirical study with direct experimental measurements
full rationale
This is a purely empirical paper that constructs a controlled two-document RAG testbed, executes 252,000 factorial trials across six LLMs while varying one content factor at a time with brand anonymization and counterbalanced order, then fits mixed-effects models to the resulting citation outcomes. All reported drivers (topical relevance, list position, price information, timestamp) are statistical associations measured from the data rather than any derivation, prediction, or first-principles result that reduces to its own inputs by construction. No self-citation chains, ansatzes, uniqueness theorems, or renamings of known results appear in the load-bearing steps; the analysis is self-contained against external benchmarks because it rests on direct, reproducible measurements.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mixed-effects models can isolate the effects of individual content factors when sources differ in exactly one variable at a time.
Reference graph
Works this paper leans on
-
[1]
Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, and Ameet Deshpande. 2024. Generative Engine Opti- mization. InProc. 30th ACM SIGKDD Conf. on Knowledge Discovery and Data Mining (KDD ’24). doi:10.1145/3637528.3671900
-
[2]
Douglas Bates, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting Linear Mixed-Effects Models Using lme4.Journal of Statistical Software67, 1 (2015). doi:10.18637/jss.v067.i01
-
[3]
Sergey Brin and Lawrence Page. 1998. The Anatomy of a Large-Scale Hyper- textual Web Search Engine.Computer Networks and ISDN Systems30, 1 (1998). doi:10.1016/S0169-7552(98)00110-X
-
[4]
Miles Efron and Gene Golovchinsky. 2011. Estimation Methods for Ranking Re- cent Information. InProc. 34th Int’l ACM SIGIR Conf. on Research and Development in Information Retrieval (SIGIR ’11). doi:10.1145/2009916.2009984
-
[5]
Kamil Fijorek and Andrzej Sokolowski. 2012. Separation-Resistant and Bias- Reduced Logistic Regression: STATISTICA Macro.Journal of Statistical Software, Code Snippets47, 2 (2012). doi:10.18637/jss.v047.c02
-
[6]
Nan Hu, Paul A. Pavlou, and Jennifer Zhang. 2006. Can Online Reviews Reveal a Product’s True Quality? Empirical Findings and Analytical Modeling of Online Word-of-Mouth Communication. InProc. 7th ACM Conf. on Electronic Commerce (EC ’06). doi:10.1145/1134707.1134743
-
[7]
Stuart H. Hurlbert. 1984. Pseudoreplication and the Design of Ecological Field Experiments.Ecological Monographs54, 2 (1984). doi:10.2307/1942661
-
[8]
Ken Hyland. 1994. Hedging in academic writing and EAP textbooks.English for Specific Purposes13, 3 (1994). doi:10.1016/0889-4906(94)90004-3
-
[9]
T. Florian Jaeger. 2008. Categorical data analysis: Away from ANOVAs (transfor- mation or not) and towards logit mixed models.Journal of Memory and Language 59, 4 (2008). doi:10.1016/j.jml.2007.11.007
-
[10]
Mahammed Kamruzzaman, Hieu Minh Nguyen, and Gene Louis Kim. 2024. “Global is Good, Local is Bad?”: Understanding Brand Bias in LLMs. InProc. 2024 Conf. on Empirical Methods in Natural Language Processing. ACL, Miami, FL, USA. doi:10.18653/v1/2024.emnlp-main.707
-
[11]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProc. 2020 Conf. on Empirical Methods in Natural Language Processing (EMNLP). doi:10.18653/v1/2020.emnlp-main.550
-
[12]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval- Augmented Generation for Knowledge-Intensive NLP Tasks. InProc. 34th Int’l Conf. on Neural Information Processing Systems(Vancouver, BC, Canada) (Neur...
2020
-
[13]
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Trans. ACL12 (2024). doi:10.1162/tacl_a_00638
-
[14]
Miriam J. Metzger and Andrew J. Flanagin. 2013. Credibility and trust of in- formation in online environments: The use of cognitive heuristics.Journal of Pragmatics59 (2013). doi:10.1016/j.pragma.2013.07.012
-
[15]
Benjamin Reichman and Larry Heck. 2024. Dense Passage Retrieval: Is it Retriev- ing?. InFindings of ACL: EMNLP 2024. doi:10.18653/v1/2024.findings-emnlp.791
-
[16]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (2009). doi:10.1561/ 1500000019
2009
-
[17]
Patrick Schilcher, Dominik Karasin, Michael Schöpf, Haisam Saleh, Antonela Tommasel, and Markus Schedl. 2025. Characterizing Positional Bias in Large Language Models: A Multi-Model Evaluation of Prompt Order Effects. InFindings of ACL: EMNLP 2025. doi:10.18653/v1/2025.findings-emnlp.1124
-
[18]
Magdalena Szumilas. 2010. Explaining Odds Ratios.Journal of the Canadian Academy of Child and Adolescent Psychiatry19, 3 (2010). https://pmc.ncbi.nlm. nih.gov/articles/PMC2938757/
2010
-
[19]
Richard Y. Wang and Diane M. Strong. 1996. Beyond Accuracy: What Data Quality Means to Data Consumers.Journal of Management Information Systems 12, 4 (1996). doi:10.1080/07421222.1996.11518099
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.