Is Inference Mediated by Distinct Semantic Structures in LLMs? A Mechanistic Interpretation
Pith reviewed 2026-06-29 21:44 UTC · model grok-4.3
The pith
LLM representations for natural language inference encode the specific semantic operations that generate labels, not merely the labels themselves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
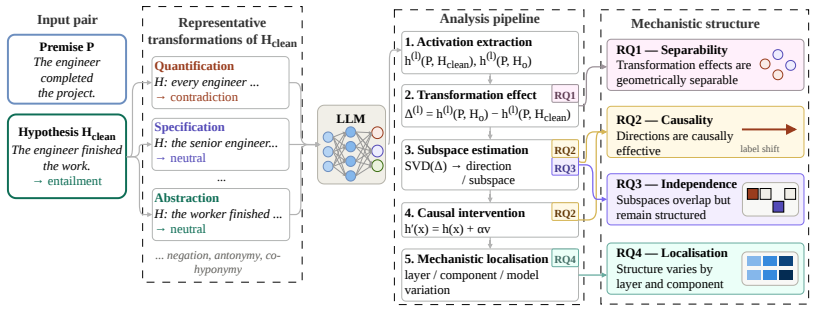
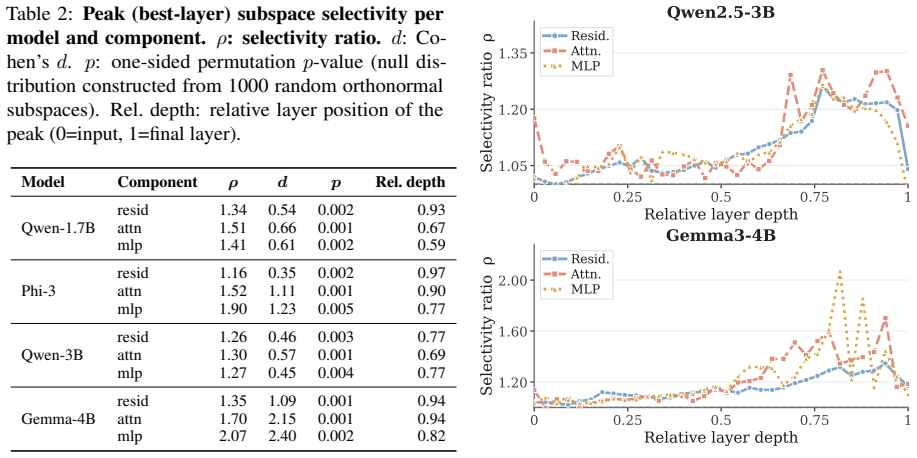
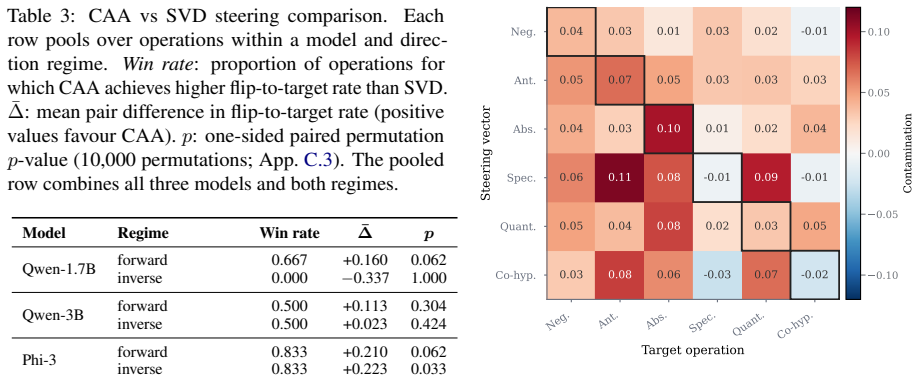
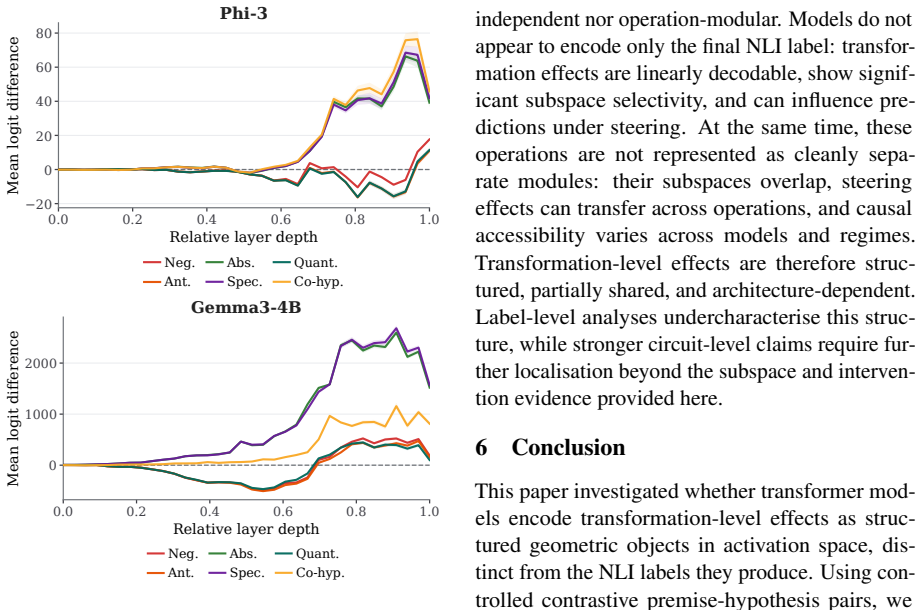
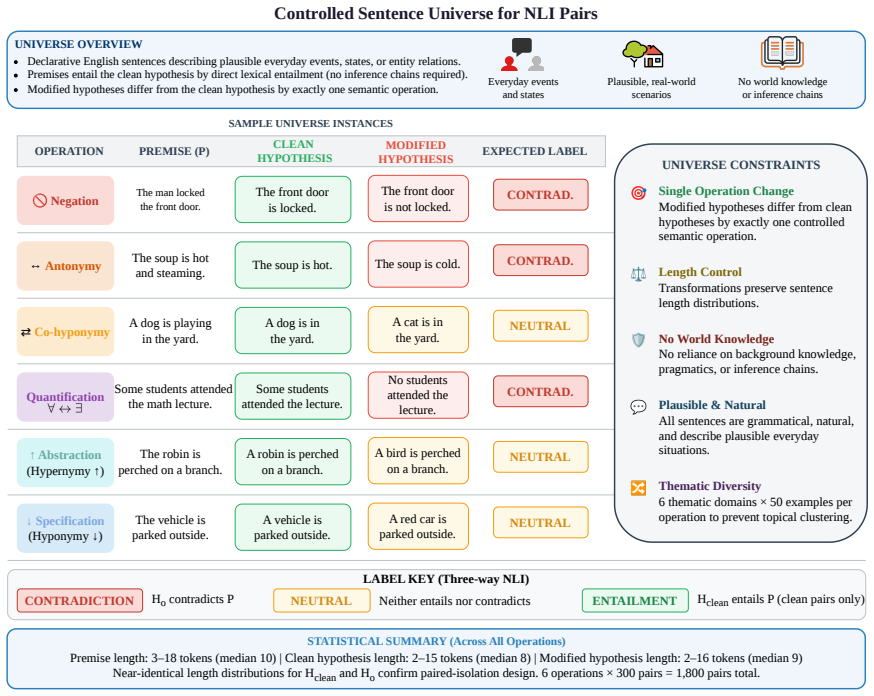
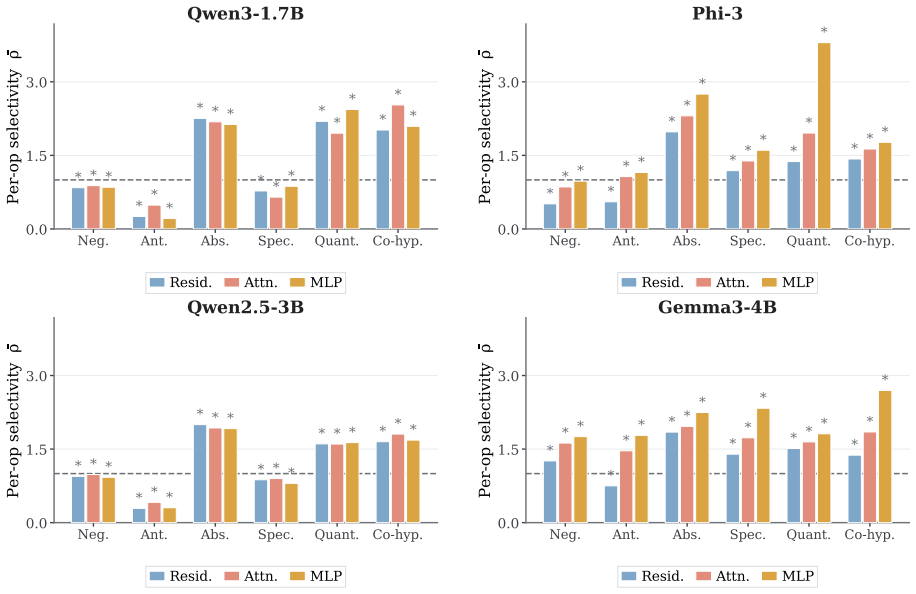
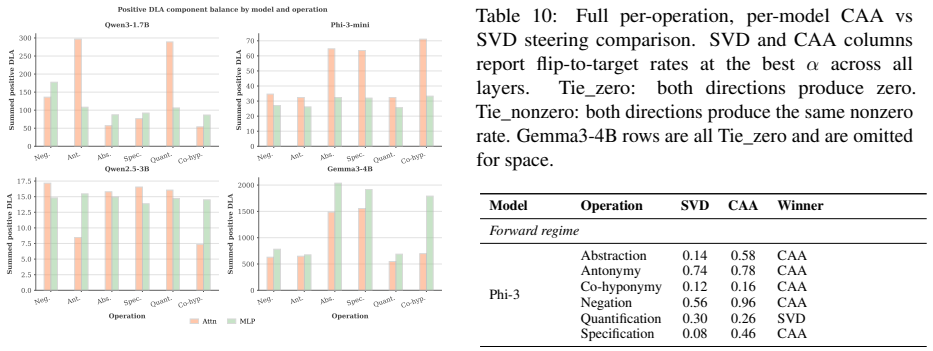
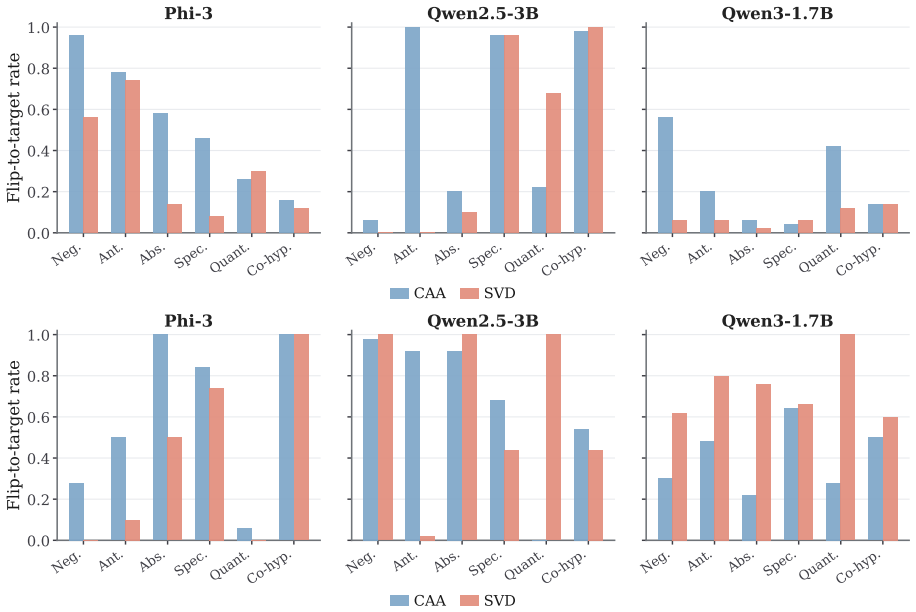
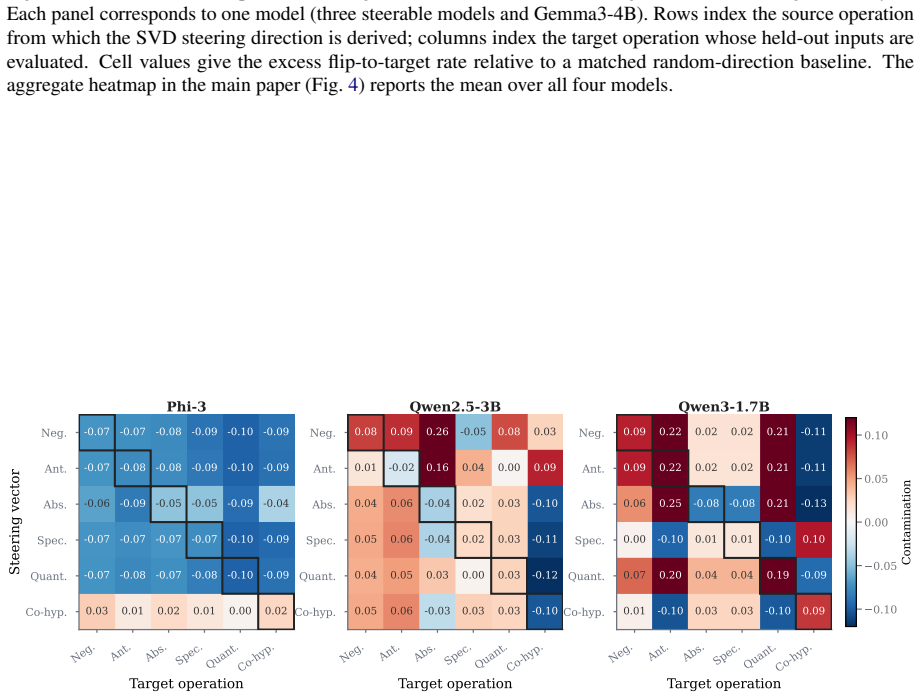
Using controlled premise-hypothesis pairs differing by a single semantic transformation, SVD-derived subspaces on layer activations recover operation-specific directions that are decodable at 84.8-99% accuracy and causally influence predictions when used for activation steering, revealing partially distinct yet overlapping subspaces whose steerability and cross-operation interference vary by model.
What carries the argument
Operation-level subspaces extracted via SVD on layer activations and tested for causality through activation steering.
If this is right
- Mechanistic analysis of inference should target semantic operations rather than predicted labels.
- Activation steering at operation subspaces offers a route to targeted control of inference behavior.
- Cross-operation interference patterns can be used to map how different semantic transformations interact inside the model.
Where Pith is reading between the lines
- If operation subspaces generalize across tasks, similar extraction methods could apply to other reasoning domains such as arithmetic or causal inference.
- The observed dissociation between subspace selectivity and cross-operation independence suggests that models may maintain both shared and private directions for related operations.
Load-bearing premise
The premise-hypothesis pairs differ by exactly one semantic transformation and the SVD subspaces isolate only the intended operation rather than label or surface information.
What would settle it
A controlled experiment in which the same steering vectors are applied after randomizing the transformation identity across pairs and the effect on accuracy disappears or becomes indistinguishable from random directions.
Figures





read the original abstract
Predicting a label correctly does not necessarily require representing the operation that produces it. Transformer representations are known to carry label-level information, but whether they encode semantic operations producing those labels is unclear. We investigate this in Natural Language Inference using controlled premise-hypothesis pairs that differ by a single semantic transformation. Using layer-wise activations, we estimate operation-level subspaces via SVD and test their causal relevance through activation steering in four open-weight decoder models. Transformation effects are decodable with $84.8$-$99\%$ accuracy and occupy partially distinct but overlapping subspaces, exceeding random-subspace baselines. Steering experiments show that these directions causally influence predictions, though steerability varies across models; cross-operation steering further reveals structured interference and a dissociation between subspace selectivity and cross-operation independence. These findings indicate that the models encode not only that a hypothesis relates to a premise but also, in part, how it does so, implying that mechanistic analysis and control should operate at the level of semantic operations rather than predicted labels alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs encode not only NLI labels but also the specific semantic operations producing them (e.g., negation, entailment direction) in partially distinct subspaces of layer activations. Using controlled premise-hypothesis pairs differing by one transformation, SVD-derived subspaces yield 84.8-99% decoding accuracy across four open-weight decoder models; activation steering demonstrates causal influence on predictions, with findings on cross-operation interference and a dissociation between selectivity and independence, implying mechanistic work should target operations rather than labels.
Significance. If the subspaces isolate operation-specific directions, the work would strengthen mechanistic interpretability by moving beyond label encoding to semantic structure, with direct implications for targeted control. The causal steering experiments and multi-model evaluation are strengths that go beyond purely observational decoding.
major comments (2)
- [Abstract / Methods] Abstract and Methods: The central claim that SVD subspaces reflect the semantic transformation itself (rather than downstream label or surface-form correlations) is load-bearing for the conclusion that models encode 'how' a relation holds. However, the reported setup does not describe an ablation that holds the predicted NLI label fixed while varying the operation (or vice versa), leaving open the possibility that principal components align with known label-predictive directions.
- [Results (steering)] Steering experiments (implied in Results): While steering shows causal effects and cross-operation interference, the abstract provides no quantitative details on effect sizes, variance across layers, or statistical comparison to random-subspace or label-matched baselines, making it difficult to evaluate whether the dissociation between subspace selectivity and cross-operation independence is robust.
minor comments (2)
- [Abstract] The decoding accuracy range (84.8-99%) should be broken down by operation and model for interpretability.
- [Methods] Additional details on pair construction (e.g., lexical controls, exact transformation definitions) would help confirm that pairs differ by exactly one semantic operation.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important points for strengthening the claims about operation-specific subspaces. We respond to each below and outline revisions.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The central claim that SVD subspaces reflect the semantic transformation itself (rather than downstream label or surface-form correlations) is load-bearing for the conclusion that models encode 'how' a relation holds. However, the reported setup does not describe an ablation that holds the predicted NLI label fixed while varying the operation (or vice versa), leaving open the possibility that principal components align with known label-predictive directions.
Authors: The single-transformation design controls for many surface and lexical confounds by construction, and the high decoding accuracies (84.8-99%) together with the observed partial overlap between subspaces already suggest operation-specific structure beyond label prediction. Nevertheless, we agree that an explicit ablation holding the downstream NLI label fixed while varying the operation would provide stronger causal evidence against label-based explanations. We will add this analysis, including quantitative comparison of subspace directions under label-matched conditions. revision: yes
-
Referee: [Results (steering)] Steering experiments (implied in Results): While steering shows causal effects and cross-operation interference, the abstract provides no quantitative details on effect sizes, variance across layers, or statistical comparison to random-subspace or label-matched baselines, making it difficult to evaluate whether the dissociation between subspace selectivity and cross-operation independence is robust.
Authors: The full Results section already reports layer-wise steering effect sizes, variance, and statistical comparisons against random and label-matched baselines. To make these findings more immediately accessible, we will expand the abstract with concise quantitative summaries of the key steering metrics (e.g., average prediction shift magnitudes and significance levels relative to baselines) while preserving the overall length constraints. revision: yes
Circularity Check
No significant circularity; empirical mechanistic analysis is self-contained
full rationale
The paper conducts an empirical investigation of LLM representations in NLI using controlled premise-hypothesis pairs differing by one semantic transformation. It applies SVD to layer activations to identify subspaces, measures decodability (84.8-99% accuracy), and tests causal effects via activation steering, benchmarking against random-subspace baselines. No equations or claims reduce a derived quantity to its inputs by construction, no fitted parameters are relabeled as predictions, and no self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central findings rest on observable intervention outcomes and accuracy metrics external to any definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SVD on layer activations yields subspaces that isolate semantic operations
Reference graph
Works this paper leans on
-
[1]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Where do LLMs compose meaning? a layerwise analysis of compositional robustness. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4622–4646, Rabat, Morocco. As- sociation for Computational Linguistics. Anthropic. 2025. Claude claude-sonnet-4-5. https: //www.anthrop...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InProceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, 9 pages 163–173, Online
Neural natural language inference models par- tially embed theories of lexical entailment and negation. InProceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, 9 pages 163–173, Online. Association for Computational Linguistics. Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R. Bowman, ...
-
[3]
Annotation artifacts in natural language inference data. InProceedings of the 2018 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 107–112, New Orleans, Louisiana. Association for Computational Linguistics. Evan Hernandez, Arnab Sen Sharma, Tal Haklay,...
2018
-
[4]
Association for Computa- tional Linguistics
What does BERT learn about the structure of language? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3651–3657, Florence, Italy. Association for Computa- tional Linguistics. Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. 2023. Inference-time intervention: Eliciting truthf...
2023
-
[5]
Estimating the causal effects of natural logic fea- tures in transformer-based NLI models. InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 6319–6329, Torino, Italia. ELRA and ICCL. Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
The goal was to produce paired examples in which the clean pair expressed entailment and the modified pair differed from it by exactly one controlled semantic transforma- tion
under a structured prompt with operation- specific constraints. The goal was to produce paired examples in which the clean pair expressed entailment and the modified pair differed from it by exactly one controlled semantic transforma- tion. As the main analysed quantity is ∆(l) o = h(l)(P, Ho)−h (l)(P, Hclean), the dataset must min- imise all variation be...
2009
-
[7]
Both clean and modified hypotheses are gram- matical and natural English sentences
-
[8]
Both describe plausible real-world situations
-
[9]
The clean hypothesis is unambiguously entailed by the premise
-
[10]
The modified hypothesis bears the target non- entailment label
-
[11]
The modified hypothesis does not accidentally remain entailed by the premise
-
[12]
id": "neg_0042
The transformation involves exactly one seman- tic change, with no additional lexical or syntac- tic modifications if not necessary. Self-filtering.Generation included an explicit self-check stage: the model was instructed to dis- card and regenerate any example failing any of the above conditions. Low-margin examples, those for which a competent reader m...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.