CS-PQ: Cache-Friendly SIMD Product Quantization for Large-Scale ANNS Index Construction
Pith reviewed 2026-06-29 19:58 UTC · model grok-4.3
The pith
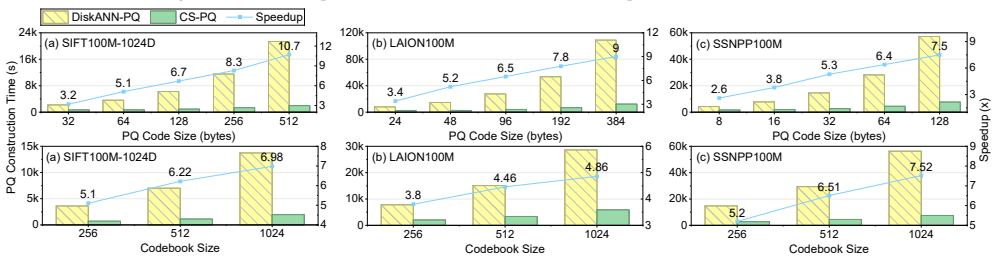
A cache-friendly SIMD framework for product quantization achieves up to 10.7 times speedup in large-scale ANNS index construction on CPUs without accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
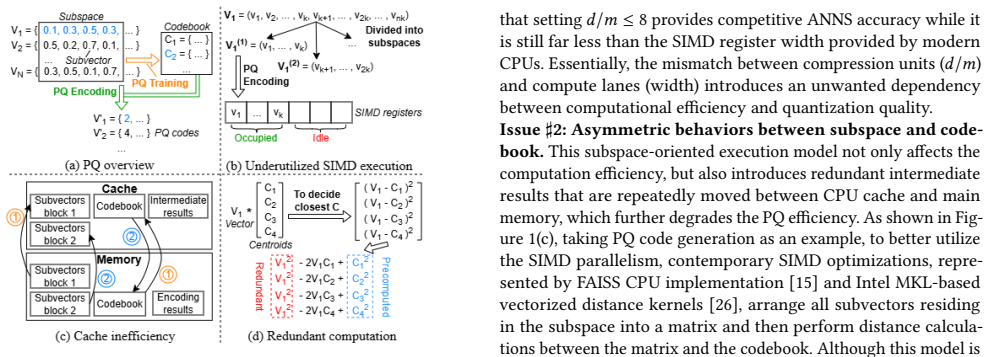
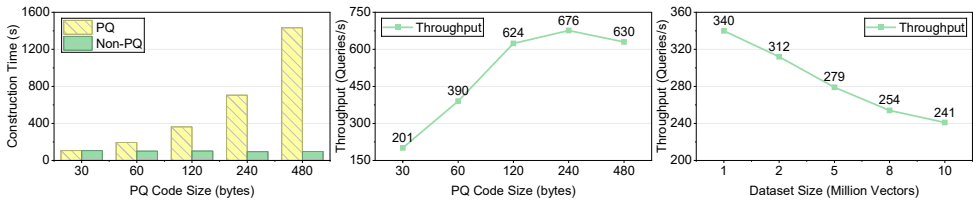
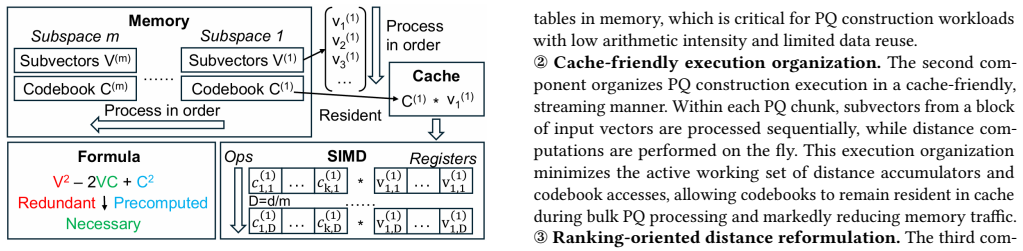
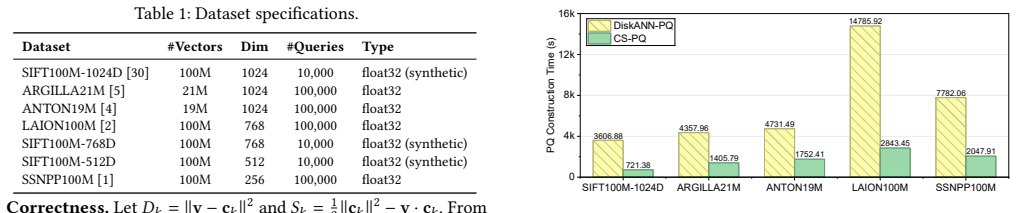
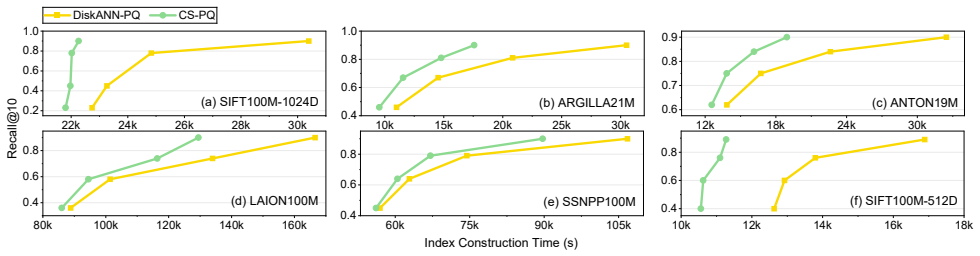
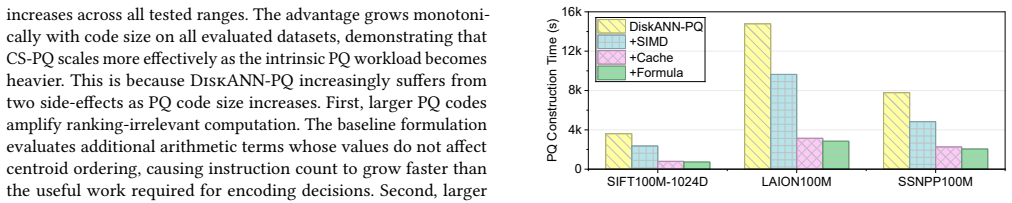
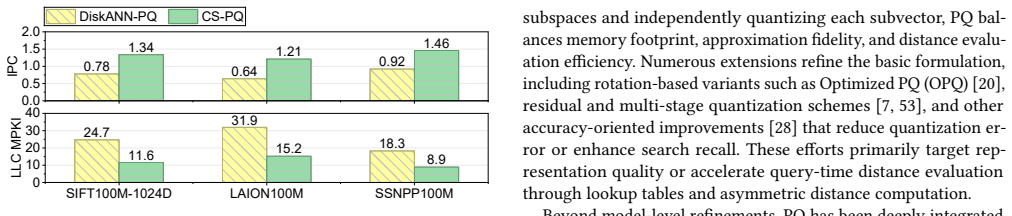
CS-PQ introduces a vector-oriented SIMD paradigm that decouples quantization granularity from SIMD width by vectorizing across PQ centroids rather than subvector dimensions. It further restructures the execution pipeline to improve cache locality and reformulates PQ computation to eliminate redundant operations while preserving correctness. Experiments on large-scale datasets show that CS-PQ achieves up to 10.7 times speedup over state-of-the-art CPU-based PQ implementations without sacrificing ANNS accuracy.
What carries the argument
The vector-oriented SIMD paradigm that vectorizes across PQ centroids rather than subvector dimensions, together with the restructured execution pipeline for cache locality and elimination of redundant operations.
If this is right
- Product quantization steps in ANNS pipelines can complete in a fraction of the previous CPU time for the same data volume.
- Existing ANNS systems can swap in the new method and retain the same recall guarantees.
- Index construction for bigger vector collections becomes practical without moving to GPU hardware.
- The exact-correctness property allows direct substitution into any PQ-dependent code without further validation.
Where Pith is reading between the lines
- The same centroid-wise vectorization pattern may apply to other subvector algorithms that currently process dimensions independently.
- Server deployments of vector search could shift more index building back to CPUs, lowering the need for GPU clusters during setup phases.
- Future CPU designs might add instructions that further support grouping operations across codebook entries rather than within single vectors.
- The cache-restructuring ideas could be tested on related tasks such as residual quantization or inverted file construction.
Load-bearing premise
The vector-oriented SIMD approach and pipeline restructuring will improve cache locality and remove redundancies on modern CPUs while keeping exact quantization results.
What would settle it
Run CS-PQ and the prior best CPU PQ method on identical large-scale datasets and measure whether the speedup reaches 10.7 times or whether ANNS accuracy on the resulting indexes drops.
Figures


read the original abstract
Product Quantization (PQ) construction is deeply integrated into vector index construction for Approximate Nearest Neighbor Search (ANNS). The rapid growth in vector dimensionality and volume has significantly increased the computational cost of PQ. Existing GPU-based PQ accelerations are ill-suited for PQ construction due to its "one-to-one" execution pattern (one compute, one data load, i.e., data transfer overhead dominates). Although CPU-based solutions are prevalent, they are essentially general-purpose designs that fail to capture the intrinsic characteristics of PQ construction.In this paper, we propose CS-PQ, a Cache-friendly, SIMD-optimized PQ framework based on modern CPUs. CS-PQ introduces a vector-oriented SIMD paradigm that decouples quantization granularity from SIMD width by vectorizing across PQ centroids rather than subvector dimensions. It further restructures the execution pipeline to improve cache locality and reformulates PQ computation to eliminate redundant operations while preserving correctness. Experiments on large-scale datasets show that CS-PQ achieves up to 10.7 times speedup over state-of-the-art CPU-based PQ implementations without sacrificing ANNS accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CS-PQ, a framework for optimizing Product Quantization (PQ) construction for Approximate Nearest Neighbor Search (ANNS) on modern CPUs. It introduces a vector-oriented SIMD paradigm that vectorizes across PQ centroids to decouple from SIMD width, restructures the execution pipeline to enhance cache locality, and reformulates the computation to remove redundant operations while maintaining exact quantization correctness. The key result is an experimental demonstration of up to 10.7× speedup compared to state-of-the-art CPU-based PQ implementations on large-scale datasets, with no loss in ANNS accuracy.
Significance. Should the performance improvements be confirmed, this work would offer a valuable contribution to the field of large-scale vector indexing by providing CPU-efficient PQ construction that avoids the data transfer issues of GPU solutions and improves upon generic CPU approaches. The focus on cache locality and redundancy elimination in the PQ pipeline is a targeted optimization that could benefit many ANNS systems.
minor comments (2)
- The abstract refers to a 'one-to-one' execution pattern without further elaboration; a brief explanation or reference to a figure or section in the main text would improve clarity for readers unfamiliar with the term in this context.
- The description of the vector-oriented SIMD paradigm would benefit from explicit mention of the target SIMD instruction sets (e.g., AVX2 or AVX-512) and widths used, to support reproducibility of the claimed cache and redundancy improvements.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments appear in the report.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical engineering contribution: a cache-friendly SIMD framework for PQ construction that vectorizes across centroids, restructures the pipeline, and eliminates redundancy while claiming to preserve exact quantization results. The load-bearing claim is a measured 10.7x speedup on large-scale datasets with unchanged ANNS accuracy. No equations, fitted parameters, self-citations, or uniqueness theorems are invoked that would reduce any result to its own inputs by construction. The work is self-contained as a practical implementation whose correctness and performance are externally verifiable through reproduction on the stated datasets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Billion-Scale Approximate Nearest Neighbor Search Challenge: NeurIPS’21 Competition Track
2021. Billion-Scale Approximate Nearest Neighbor Search Challenge: NeurIPS’21 Competition Track. https://big-ann-benchmarks.com/neurips21.html. Accessed January 7, 2026
2021
-
[2]
The LAION2B and Projections
2024. The LAION2B and Projections. https://sisap-challenges.github.io/2024/ datasets/. Accessed January 7, 2026
2024
-
[3]
Frédéric André et al. 2019. Quicker ADC: Unlocking the Hidden Potential of Product Quantization with SIMD.IEEE TPAMI(2019)
2019
-
[4]
anton-l. 2024. wiki-embed-mxbai-embed-large-v1. https://huggingface.co/ datasets/anton-l/wiki-embed-mxbai-embed-large-v1. Accessed January 7, 2026
2024
-
[5]
Argilla Warehouse. 2024. Personahub FineWeb-Edu 4 Embeddings. https://huggingface.co/datasets/argilla-warehouse/personahub-fineweb- 12 edu-4-embeddings. Accessed January 7, 2026
2024
-
[6]
Ilias Azizi, Karima Echihabi, and Themis Palpanas. 2025. Graph-Based Vector Search: An Experimental Evaluation of the State-of-the-Art.Proc. ACM Manag. Data3, 1, Article 43 (2025), 31 pages
2025
-
[7]
Artem Babenko and Victor Lempitsky. 2014. Additive Quantization for Extreme Vector Compression. InCVPR
2014
-
[8]
Lempitsky
Artem Babenko and Victor S. Lempitsky. 2014. Additive Quantization for Extreme Vector Compression. InConference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, USA, 931–938
2014
-
[9]
Babenko, Artem and Lempitsky, Victor. 2015. The Inverted Multi-Index.IEEE Transactions on Pattern Analysis and Machine Intelligence37, 6 (2015), 1247–1260
2015
-
[10]
Jon Louis Bentley. 1975. Multidimensional binary search trees used for associative searching.Commun. ACM18, 9 (1975), 509–517
1975
-
[11]
Nolwenn Bernard and Krisztian Balog. 2025. A Systematic Review of Fairness, Accountability, Transparency, and Ethics in Information Retrieval.ACM Comput. Surv.57, 6 (2025), 29
2025
-
[12]
Bing Tian and Haikun Liu and Yuhang Tang and Shihai Xiao and Zhuohui Duan and Xiaofei Liao and Hai Jin and Xuecang Zhang and Junhua Zhu and Yu Zhang
-
[13]
InUSENIX Conference on File and Storage Technologies (FAST)
Towards High-throughput and Low-latency Billion-scale Vector Search via CPU/GPU Collaborative Filtering and Re-ranking. InUSENIX Conference on File and Storage Technologies (FAST). USENIX Association, USA, 171–185
-
[14]
Cheng Chen, Chenzhe Jin, Yunan Zhang, Sasha Podolsky, Chun Wu, Szu- Po Wang, Eric Hanson, Zhou Sun, Robert Walzer, and Jianguo Wang. 2024. Singlestore-v: An Integrated Vector Database System in Singlestore.Proc. VLDB Endow.17, 12 (2024), 3772–3785
2024
-
[15]
Jia Chen, Qian Dong, Haitao Li, Xiaohui He, Yan Gao, Shaosheng Cao, Yi Wu, Ping Yang, Chen Xu, Yao Hu, Qingyao Ai, and Yiqun Liu. 2025. Qilin: A Multimodal Information Retrieval Dataset with APP-level User Sessions. InInternational Conference on Research and Development in Information Retrieval (SIGIR). ACM, USA, 3670–3680
2025
-
[16]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library.CoRRabs/2401.08281 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Fu, Cong and Xiang, Chao and Wang, Changxu and Cai, Deng. 2019. Fast approximate nearest neighbor search with the navigating spreading-out graph. Proc. VLDB Endow.12, 5 (2019), 461–474
2019
-
[18]
Fiona Fui-Hoon Nah, Ruilin Zheng, Jingyuan Cai, Keng Siau, and Langtao Chen
-
[19]
, 277–304 pages
Generative AI and ChatGPT: Applications, challenges, and AI-human collaboration. , 277–304 pages
-
[20]
Gao, Yunfan and Xiong, Yun and Gao, Xinyu and Jia, Kangxiang and Pan, Jinliu and Bi, Yuxi and Dai, Yi and Sun, Jiawei and Wang, Haofen and Wang, Haofen
-
[21]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-Augmented Generation for Large Language Models: A survey. arXiv preprint arXiv:2312.109972 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2013. Optimized Product Quan- tization for Approximate Nearest Neighbor Search. InConference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, USA, 2946–2953
2013
-
[23]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2013. Optimized Product Quantization for Approximate Nearest Neighbor Search. InCVPR
2013
-
[24]
Kazushige Goto and Robert van de Geijn. 2008. Anatomy of High-Performance Matrix Multiplication.ACM TOMS(2008)
2008
-
[25]
van de Geijn
Kazushige Goto and Robert A. van de Geijn. 2008. Anatomy of High-Performance Matrix Multiplication.ACM Trans. Math. Software34, 3 (2008), 12:1–12:25
2008
-
[26]
Groh, Fabian and Ruppert, Lukas and Wieschollek, Patrick and Lensch, Hendrik P. A. 2023. GGNN: Graph-Based GPU Nearest Neighbor Search.IEEE Transactions on Big Data9, 1 (2023), 267–279
2023
-
[27]
Emrul Hasan, Mizanur Rahman, Chen Ding, Jimmy Xiangji Huang, and Shaina Raza. 2025. Review-based Recommender Systems: A Survey of Approaches, Challenges and Future Perspectives.ACM Comput. Surv.58, 1 (2025), 41
2025
-
[28]
2023.Intel®64 and IA-32 Architec- tures Optimization Reference Manual
Intel Corporation. 2023.Intel®64 and IA-32 Architec- tures Optimization Reference Manual. Available at: https://www.intel.com/content/www/us/en/developer/articles/technical/intel- sdm.html
2023
-
[29]
2023.Intel®oneAPI Math Ker- nel Library Developer Guide
Intel Corporation. 2023.Intel®oneAPI Math Ker- nel Library Developer Guide. Available at: https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html
2023
-
[30]
Jayaram Subramanya, Suhas and Devvrit, Fnu and Simhadri, Harsha Vardhan and Krishnawamy, Ravishankar and Kadekodi, Rohan. 2019. Diskann: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node. InAnnual Conference on Neural Information Processing Systems (NeurIPS), Vol. 32. MIT Press, Canada
2019
-
[31]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product Quantization for Nearest Neighbor Search. InIEEE TPAMI
2010
-
[32]
Hervé Jégou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Trans. Pattern Anal. Mach. Intell.33, 1 (2011), 117–128
2011
-
[33]
Hervé Jégou, Romain Tavenard, Matthijs Douze, and Laurent Amsaleg. 2011. Searching in One Billion Vectors: Re-Rank with Source Coding. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 861–864
2011
-
[34]
Haodi Jiang, Hao Guo, Minhui Xie, Jiwu Shu, and Youyou Lu. 2025. High- Throughput, Cost-Effective Billion-Scale Vector Search with a Single GPU.Proc. ACM Manag. Data3, 6 (2025), 27
2025
-
[35]
Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi- Yu, Yiming Yang, Jamie Callan, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi- Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active Retrieval Augmented Generation. InConference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Singpore, 7969– 7992
2023
- [36]
-
[37]
Monica Lam, Edward Rothberg, and Michael Wolf. 1991. The Cache Performance and Optimizations of Blocked Algorithms. InASPLOS
1991
-
[38]
Stuart P. Lloyd. 1982. Least squares quantization in PCM.IEEE Trans. Inf. Theory 28, 2 (1982), 129–136
1982
-
[39]
Malkov and Dmitry A
Yury A. Malkov and Dmitry A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs.IEEE Trans. Pattern Anal. Mach. Intell.42, 4 (2020), 824–836
2020
-
[40]
Malkov, Yury and Ponomarenko, Alexander and Logvinov, Andrey and Krylov, Vladimir. 2014. Approximate Nearest Neighbor Algorithm based on Navigable Small World Graphs.Information Systems45 (2014), 61–68
2014
-
[41]
Ootomo, Hiroyuki and Naruse, Akira and Nolet, Corey and Wang, Ray and Feher, Tamas and Wang, Yong. 2024. CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs. InInternational Conference on Data Engineering (ICDE). IEEE, Netherlands, 4236–4247
2024
-
[42]
James Jie Pan, Jianguo Wang, and Guoliang Li. 2024. Vector Database Manage- ment Techniques and Systems. InInternational Conference on Management of Data (SIGMOD). ACM, USA, 597–604
2024
-
[43]
Pan, James Jie and Wang, Jianguo and Li, Guoliang. 2024. Survey of vector database management systems.The VLDB Journal33, 5 (2024), 1591–1615
2024
-
[44]
Qin, Ruoyu and Li, Zheming and He, Weiran and Cui, Jialei and Ren, Feng and Zhang, Mingxing and Wu, Yongwei and Zheng, Weimin and Xu, Xinran. 2025. Mooncake: Trading More Storage for Less Computation—A KVCache-centric Architecture for Serving LLM Chatbot. InUSENIX Conference on File and Storage Technologies (FAST). USENIX Association, USA, 155–170
2025
-
[45]
Amit Sharma, Hua Li, Xue Li, and Jian Jiao. 2024. Optimizing Novelty of Top-k Recommendations using Large Language Models and Reinforcement Learning. InACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). ACM, Spain, 5669–5679
2024
-
[46]
Ji Sun, Guoliang Li, James Pan, Jiang Wang, Yongqing Xie, Ruicheng Liu, and Wen Nie. 2025. GaussDB-Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications.Proc. VLDB Endow.18, 12 (2025), 4951–4963
2025
-
[47]
Toni Taipalus. 2024. Vector database management systems: Fundamental con- cepts, use-cases, and current challenges.Cognitive Systems Research85 (2024), 101216
2024
-
[48]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Information Processing Systems, I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30. Curran Associates, Inc., USA
2017
-
[49]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2021. A Com- prehensive Survey and Experimental Comparison of Graph-Based Approximate Nearest Neighbor Search.Proc. VLDB Endow.14, 11 (2021), 1964–1978
2021
-
[50]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2022. Manu: a Cloud Native Vector Database Management System.Proc. VLDB Endow.15, 12 (2022), 3548–3561
2022
-
[51]
Wang, Jianguo and Yi, Xiaomeng and Guo, Rentong and Jin, Hai and Xu, Peng and Li, Shengjun and Wang, Xiangyu and Guo, Xiangzhou and Li, Chengming and Xu, Xiaohai and others. 2021. Milvus: A purpose-built vector data management system. InACM International Conference on Management of Data (SIGMOD). ACM, China, 2614–2627
2021
-
[52]
Wang, Mengzhao and Xu, Weizhi and Yi, Xiaomeng and Wu, Songlin and Peng, Zhangyang and Ke, Xiangyu and Gao, Yunjun and Xu, Xiaoliang and Guo, Ren- tong and Xie, Charles. 2024. Starling: An I/O-Efficient Disk-Resident Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment. Proc. ACM Manag. Data2, 1, Article 14 (March 2024), 27 pages
2024
-
[53]
Mingyu Yang, Wentao Li, Jiabao Jin, Xiaoyao Zhong, Xiangyu Wang, Zhitao Shen, Wei Jia, and Wei Wang. 2025. Effective and General Distance Computation for Approximate Nearest Neighbor Search. InInternational Conference on Data Engineering (ICDE). IEEE, Hong Kong, 1098–1110
2025
-
[54]
Yang, Xiwang and Steck, Harald and Guo, Yang and Liu, Yong. 2012. On Top-K Recommendation Using Social Networks. InACM Conference on Recommender Systems (RecSys). ACM, Ireland, 67–74
2012
- [55]
-
[56]
Ting Zhang, Chao Du, and Jingdong Wang. 2014. Composite Quantization for Approximate Nearest Neighbor Search. InICML
2014
-
[57]
Zhao, Weijie and Tan, Shulong and Li, Ping. 2020. SONG: Approximate Nearest Neighbor Search on GPU. InInternational Conference on Data Engineering (ICDE). IEEE, USA, 1033–1044
2020
-
[58]
Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Haonan Chen, Zheng Liu, Zhicheng Dou, and Ji-Rong Wen. 2025. Large Language Models for Information Retrieval: A Survey.ACM Trans. Inf. Syst.44, 1 (2025), 54. 14
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.