Personalize-then-Store: Benchmarking and Learning Personalized Memory for Long-horizon Agents
Pith reviewed 2026-06-29 21:59 UTC · model grok-4.3
The pith
Personalized memory policies deliver substantial retention gains for long-horizon agents under perfect gating, while accurate gating stays challenging.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that LLM memory systems can benefit from personalized policies by proposing PerMemBench with multi-year multi-domain histories across personas and a session-level storage gating framework, confirming substantial retention gains under perfect gating while identifying accurate gating as an open challenge.
What carries the argument
Session-level storage gating, a lightweight framework that selectively bypasses memory operations for transient sessions.
If this is right
- Retention of critical context for long-horizon tasks increases when storage decisions align with individual user personas.
- Universal static policies waste memory budget on interactions that some users would discard.
- Accurate session gating is required before personalization benefits can be realized in deployed agents.
- PerMemBench supplies a standardized testbed for comparing personalized versus non-personalized memory approaches.
Where Pith is reading between the lines
- Gating models trained on the benchmark could be tested for transfer to new domains not seen during training.
- The same personalization logic might apply to other limited-resource agent components such as tool-use logs.
- Real-world deployment would require online adaptation of gating decisions as user preferences evolve.
Load-bearing premise
The multi-year, multi-domain interaction histories in PerMemBench accurately represent real user contexts where storage decisions differ across personas and can be evaluated via retention metrics.
What would settle it
An experiment on PerMemBench in which even oracle perfect gating produces no measurable retention advantage over universal policies across the tested personas.
Figures
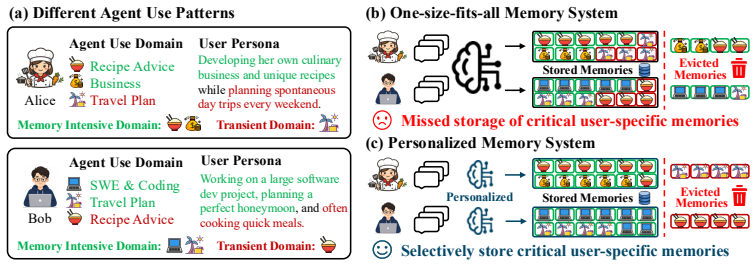


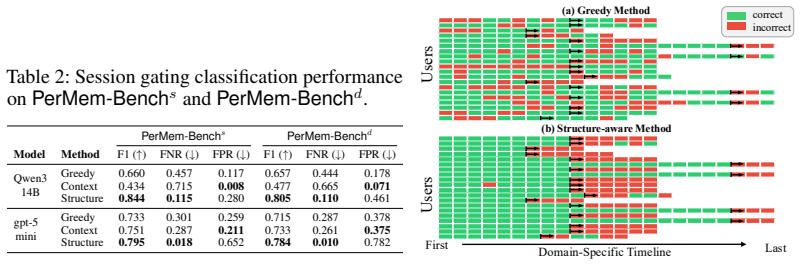

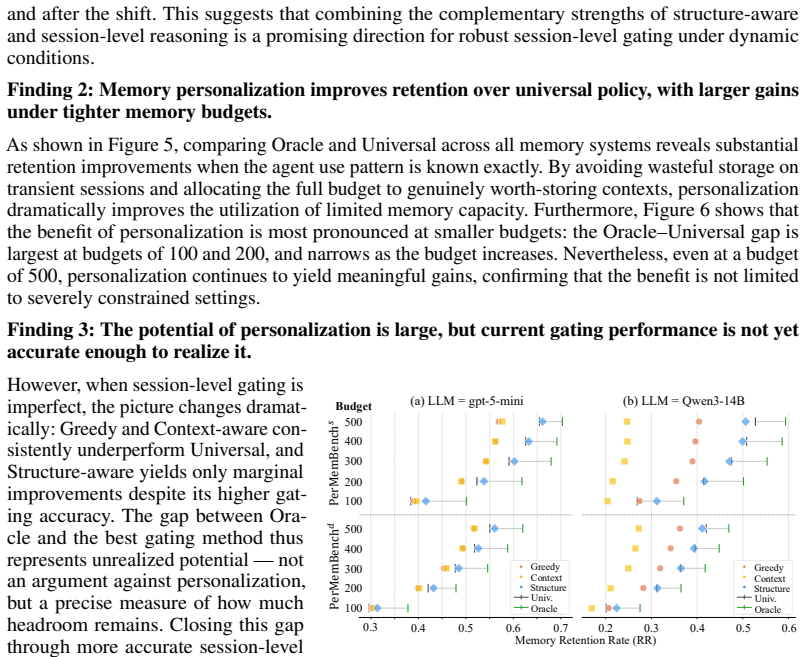
read the original abstract
Existing large language model (LLM) based memory systems apply universal, static policies that overlook a fundamental reality: the contexts that are worth storing in memory are different across users. This misalignment wastes limited memory budget on transient interactions while failing to preserve critical context for long horizon tasks. To address this gap, we investigate an underexplored question: can LLM based memory systems learn personalized memory policies? We introduce PerMemBench, the first benchmark for evaluating personalized memory systems, featuring multi year, multi domain interaction histories across diverse user personas. We further present the first empirical study of memory personalization, proposing session level storage gating, a lightweight framework that selectively bypasses memory operations for transient sessions. Our study confirms that personalization yields substantial retention gains under perfect gating, yet reveals that accurate gating remains an open and critical challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that universal memory policies in LLM agents overlook user-specific differences in what contexts merit storage, leading to wasted memory budget on transient interactions. It introduces PerMemBench, the first benchmark with multi-year, multi-domain interaction histories across diverse personas, and proposes a lightweight session-level storage gating framework. The central empirical finding is that personalization yields substantial retention gains under perfect gating, while accurate gating remains an open challenge.
Significance. If the PerMemBench ground-truth labels prove externally valid, the work would establish personalization as a necessary direction for long-horizon agent memory systems and would usefully isolate gating accuracy as the primary remaining bottleneck. The introduction of a multi-persona, multi-year benchmark itself supplies a concrete testbed that future work can build upon, even if the current gating results require further validation.
major comments (3)
- [§3] §3 (PerMemBench construction): The manuscript does not specify how the persona-specific ground-truth storage labels are obtained. If these labels are generated by the same LLM family later used for evaluation or are manually authored to exhibit the desired cross-persona differences, then the reported retention gains under perfect gating follow by construction and do not demonstrate generalization to externally validated user data.
- [§4–5] §4–5 (empirical study and gating results): The claim that 'accurate gating remains an open and critical challenge' is load-bearing for the paper’s narrative, yet the evaluation provides no comparison against stronger non-personalized or oracle baselines, nor any analysis of whether gating errors correlate with specific persona or domain characteristics.
- [Abstract and §5] Abstract and §5: The assumption that multi-year, multi-domain histories encode genuine cross-persona differences in 'critical context' is not tested against human annotators or real-user retention outcomes; without such validation the benchmark’s utility for measuring personalization benefits is limited.
minor comments (2)
- [Abstract] The abstract should report the number of personas, domains, and total sessions in PerMemBench to allow readers to gauge scale.
- [§2] Notation for the gating function and retention metric should be introduced once in §2 and used consistently thereafter.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (PerMemBench construction): The manuscript does not specify how the persona-specific ground-truth storage labels are obtained. If these labels are generated by the same LLM family later used for evaluation or are manually authored to exhibit the desired cross-persona differences, then the reported retention gains under perfect gating follow by construction and do not demonstrate generalization to externally validated user data.
Authors: We agree that the label generation procedure must be specified with greater precision. The revised manuscript will expand §3 to describe that ground-truth labels are produced by a deterministic, rule-based procedure derived directly from each persona’s explicitly defined long-term objectives, interaction patterns, and domain priorities. These rules are authored independently of any LLM used in the subsequent gating experiments and are provided in full in the supplementary material to support reproducibility. revision: yes
-
Referee: [§4–5] §4–5 (empirical study and gating results): The claim that 'accurate gating remains an open and critical challenge' is load-bearing for the paper’s narrative, yet the evaluation provides no comparison against stronger non-personalized or oracle baselines, nor any analysis of whether gating errors correlate with specific persona or domain characteristics.
Authors: The existing experiments already contrast personalized gating against a non-personalized universal policy and report perfect gating as an oracle upper bound. To strengthen the analysis, the revision will add two further non-personalized baselines (frequency-based and recency-based storage) and include a breakdown of gating error rates by persona and domain, highlighting any systematic patterns. revision: yes
-
Referee: [Abstract and §5] Abstract and §5: The assumption that multi-year, multi-domain histories encode genuine cross-persona differences in 'critical context' is not tested against human annotators or real-user retention outcomes; without such validation the benchmark’s utility for measuring personalization benefits is limited.
Authors: We acknowledge that human or real-user validation would further strengthen external validity. The current benchmark is intentionally constructed as a controlled, multi-persona testbed to isolate the effect of personalization under known ground truth. We will revise the abstract and §5 to explicitly characterize PerMemBench as a synthetic yet diverse testbed, add a limitations paragraph noting the absence of human validation, and identify real-user studies as an important direction for follow-on work. revision: partial
Circularity Check
No circularity: empirical benchmark and framework with no derivations or self-referential reductions.
full rationale
The paper introduces PerMemBench as a new benchmark with multi-year interaction histories and proposes a session-level gating framework, with all claims resting on empirical evaluation of retention metrics rather than any equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation chain exists that reduces outputs to inputs by construction, and the abstract and provided text contain no mathematical steps or uniqueness theorems invoked from prior author work. This is a standard empirical contribution whose validity hinges on external benchmark quality, not internal definitional circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contexts worth storing in memory differ across users and this misalignment wastes memory budget on transient interactions.
Reference graph
Works this paper leans on
-
[1]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents.arXiv preprint arXiv:2506.15841, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z Pan, et al. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Plugmem: A task-agnostic plugin memory module for llm agents.arXiv preprint arXiv:2603.03296, 2026
Ke Yang, Zixi Chen, Xuan He, Jize Jiang, Michel Galley, Chenglong Wang, Jianfeng Gao, Jiawei Han, and ChengXiang Zhai. Plugmem: A task-agnostic plugin memory module for llm agents.arXiv preprint arXiv:2603.03296, 2026
-
[6]
Memgpt: towards llms as operating systems
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. Memgpt: towards llms as operating systems. 2023
2023
-
[7]
Mem-{\alpha}: Learning Memory Construction via Reinforcement Learning
Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian McAuley, and Xiao- jian Wu. Mem- {\alpha}: Learning memory construction via reinforcement learning.arXiv preprint arXiv:2509.25911, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Memory in the Age of AI Agents
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, et al. Memory in the age of ai agents.arXiv preprint arXiv:2512.13564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
In prospect and retrospect: Reflective memory management for long-term per- sonalized dialogue agents
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, et al. In prospect and retrospect: Reflective memory management for long-term per- sonalized dialogue agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8416–8439, 2025
2025
-
[10]
Alireza Rezazadeh, Zichao Li, Wei Wei, and Yujia Bao. From isolated conversations to hierarchical schemas: Dynamic tree memory representation for llms.arXiv preprint arXiv:2410.14052, 2024
-
[11]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
2024
-
[12]
Jiho Kim, Woosog Chay, Hyeonji Hwang, Daeun Kyung, Hyunseung Chung, Eunbyeol Cho, Yeonsu Kwon, Yohan Jo, and Edward Choi. Dialsim: A dialogue simulator for evaluating long-term multi-party dialogue understanding of conversational agents.arXiv preprint arXiv:2406.13144, 2024
-
[13]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Longmemeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Bowen Jiang, Zhuoqun Hao, Young-Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo J Taylor, and Dan Roth. Know me, respond to me: Benchmarking llms for dynamic user profiling and personalized responses at scale.arXiv preprint arXiv:2504.14225, 2025
-
[15]
Halumem: Evaluating hallucinations in memory systems of agents.arXiv preprint arXiv:2511.03506, 2025
Ding Chen, Simin Niu, Kehang Li, Peng Liu, Xiangping Zheng, Bo Tang, Xinchi Li, Feiyu Xiong, and Zhiyu Li. Halumem: Evaluating hallucinations in memory systems of agents.arXiv preprint arXiv:2511.03506, 2025
-
[16]
Cheng Jiayang, Dongyu Ru, Lin Qiu, Yiyang Li, Xuezhi Cao, Yangqiu Song, and Xunliang Cai. Amem- gym: Interactive memory benchmarking for assistants in long-horizon conversations.arXiv preprint arXiv:2603.01966, 2026. 10
-
[17]
Nemotron-Personas-USA: Synthetic personas aligned to real-world distribu- tions, June 2025
Yev Meyer and Dane Corneil. Nemotron-Personas-USA: Synthetic personas aligned to real-world distribu- tions, June 2025
2025
-
[18]
How people use chatgpt
Aaron Chatterji, Thomas Cunningham, David J Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. How people use chatgpt. Technical report, National Bureau of Economic Research, 2025
2025
-
[19]
Chatgpt usage and adoption patterns at work, January 2026
OpenAI. Chatgpt usage and adoption patterns at work, January 2026
2026
-
[20]
Handbook of inter-rater reliability.Gaithersburg, MD: STATAXIS Publishing Company, pages 223–246, 2001
Kilem Gwet. Handbook of inter-rater reliability.Gaithersburg, MD: STATAXIS Publishing Company, pages 223–246, 2001
2001
-
[21]
M+: Extending MemoryLLM with scalable long-term memory.arXiv preprint arXiv:2502.00592, 2025
Yu Wang, Dmitry Krotov, Yuanzhe Hu, Yifan Gao, Wangchunshu Zhou, Julian McAuley, Dan Gutfreund, Rogerio Feris, and Zexue He. M+: Extending memoryllm with scalable long-term memory.arXiv preprint arXiv:2502.00592, 2025. 11 A Benchmark Construction Details A.1 Domain Pool Construction To ensure representative coverage of real-world usage, we employ a data-d...
-
[22]
Ground in the persona’s life
-
[23]
Respect project sequentiality within each domain
-
[24]
Interleave domains realistically
-
[25]
Assign concrete month numbers
-
[26]
Flag cross-domain links. [User] ## User Persona {persona} ## Domain Life Skeletons {skeleton_summary} ## Events to Place (all must appear exactly once) {domain | project_id | event_id | event_title} ## Requirements - Every event must appear exactly once. - Assign realistic month (1–{max_month}) to each session. - Identify anchor life events triggering mul...
-
[27]
3.New transient domain: one new transient domain is optionally added from the unused pool
New longitudinal domain: one new memory-required domain is sampled from the unused pool. 3.New transient domain: one new transient domain is optionally added from the unused pool. Domains are sampled with frequency-weighted probability (whigh = 3, wmedium = 2, wlow = 1) and each persona receives a deterministic seed derived from the global seed and its UU...
-
[28]
DEMOTED to occasional use: {mem_to_oneoff_name}
-
[29]
NEW longitudinal domain: {added_mem_name}
-
[30]
The demoted domain is treated as a transient domain and generates one-off events instead
NEW one-off domain: {added_oneoff_name} Output: JSON with{name, description} Life Skeleton Generation after the Shift.Using the transition narrative, Phase 2 skeletons are generated for each domain with two variants:added(new domains starting from scratch) andretained 15 (existing domains continuing into Phase 2 with new projects). The demoted domain is t...
-
[31]
A key design challenge is preventing the user simulator from explicitly declaring reference memory facts upfront, which would make the resulting dialogues artificially unnatural
provide the user simulator with the event description and reference memory items from the life skeleton, while transient sessions (mp,d = 0) provide only the event description with no reference memory, terminating once the one-off need is met. A key design challenge is preventing the user simulator from explicitly declaring reference memory facts upfront,...
-
[32]
Domain-level choices are generally persona-grounded
-
[33]
There are no major logical contradictions
-
[34]
use/memory_required/frequency are mostly coherent with each other
-
[35]
verdict":
Reasons are mostly plausible and consistent with the persona. Judge "NO" if there are clear invalid/unreasonable patterns such as: - repeated persona-irrelevant domains marked as use=true without evidence, - frequent inconsistency (e.g., use=false but memory/frequency not null), - clearly implausible frequency/memory decisions for many domains, - major co...
-
[36]
persona_alignment: - Are projects/events grounded in this persona’s background, constraints, habits, and goals?
-
[37]
project_event_structure: - Are project scopes and event granularity reasonable for real life? - Do events represent natural moments when user would open an AI agent?
-
[38]
timeline_coherence: - Is there believable progression across projects/events? - Do durations and ordering feel coherent over 1-2 years?
-
[39]
YES" only if all 4 criteria are mostly satisfied and no major contradiction exists. - Return overall_verdict =
realism_plausibility: - Do scenarios feel realistic rather than template-like or contrived? - Are there major logical contradictions? ## Verdict rule - Return overall_verdict = "YES" only if all 4 criteria are mostly satisfied and no major contradiction exists. - Return overall_verdict = "NO" if one or more criteria fail clearly. ## Output format (STRICT ...
-
[40]
skeleton_alignment (1-5): - Does the dialogue align with the session’s project/event context? - Is the user request trajectory consistent with event_description?
-
[41]
YES" only if all three scores are at least 4 and there is no critical issue. - Otherwise overall_verdict must be
gt_memory_revelation (1-5): - Do relevant gt_memory facts surface naturally in conversation? - Avoid penalizing if only truly irrelevant facts are not surfaced. - Penalize forced, list-like, or unnatural fact dumping. ## Additional rule - overall_verdict must be "YES" only if all three scores are at least 4 and there is no critical issue. - Otherwise over...
-
[42]
Group sessions belonging to the same ongoing project
-
[43]
Self-contained one-off sessions go inisolated_sessions
-
[44]
Previously isolated sessions MAY be reassigned to a project if new evidence connects them
-
[45]
projects
Every session_id must appear in exactly one place. Respond ONLY with the updated note: { "projects": [ {"project_id": "P1", "label": "...", "core_topic": "...", "session_ids": [...], "status": "ongoing"|"completed"} ], "isolated_sessions": [...] } 22 NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accura...
-
[46]
• Depending on the country in which research is conducted, IRB approval (or equivalent) may be required for any human subjects research
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.