DisagFusion: Asynchronous Pipeline Parallelism and Elastic Scheduling for Disaggregated Diffusion Serving
Pith reviewed 2026-06-29 20:43 UTC · model grok-4.3
The pith
DisagFusion overlaps computation with communication via asynchronous pipelines and dynamically rebalances stage instances to serve disaggregated diffusion models at scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
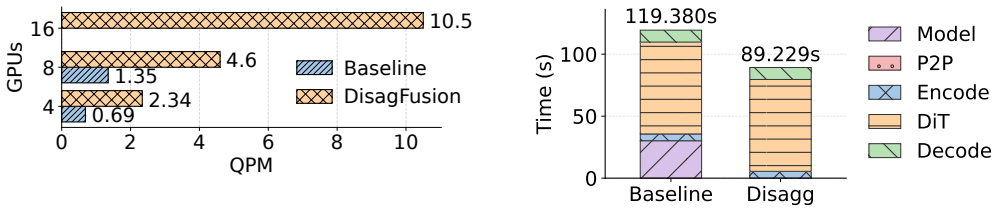
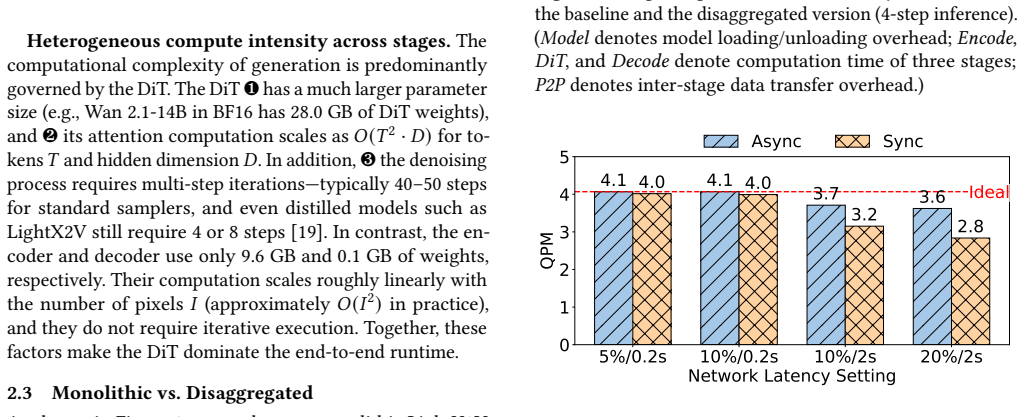
DisagFusion introduces asynchronous pipeline parallelism that overlaps computation and stage-to-stage communication to reduce pipeline bubbles and mitigate network jitter, together with a hybrid instance scheduling strategy that combines lightweight performance prediction with runtime feedback to continuously rebalance instance ratios across stages under workload shifts, enabling throughput gains of 3.4x-20.5x and end-to-end latency reductions of 18.5x versus a monolithic baseline while supporting flexible deployment on heterogeneous GPUs.
What carries the argument
asynchronous pipeline parallelism combined with hybrid instance scheduling that uses performance prediction and runtime feedback to rebalance stage instance ratios
If this is right
- Diffusion serving can be deployed cost-efficiently across mixed GPU types instead of requiring uniform high-end clusters.
- Stage handoff overheads and network jitter no longer limit pipeline throughput once computation and communication are overlapped asynchronously.
- Instance counts per stage can be adjusted on the fly without manual reprovisioning when request patterns change.
- End-to-end latency drops by more than an order of magnitude because pipeline bubbles are minimized and stages run on hardware matched to their footprints.
Where Pith is reading between the lines
- The same overlap and rebalancing ideas could apply to other multi-stage generative pipelines such as autoregressive video or audio models that also exhibit compute-memory imbalance.
- Production clusters might shift from buying homogeneous GPU fleets toward cheaper heterogeneous pools if the scheduler reliably tracks changing ratios.
- The approach suggests a general pattern for disaggregated serving of any model whose stages have mismatched resource demands, provided prediction models remain lightweight.
Load-bearing premise
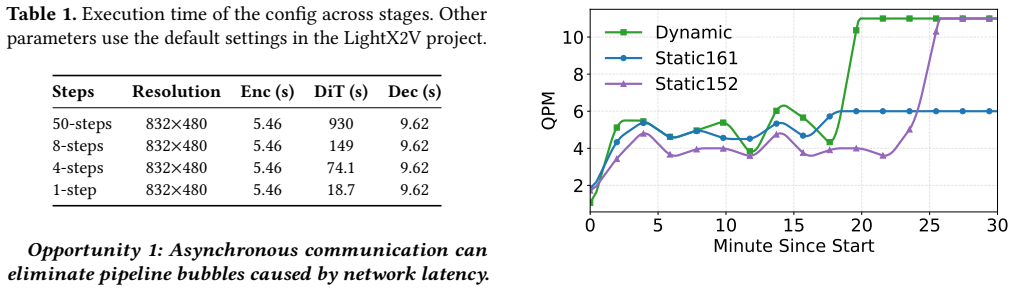
Lightweight performance prediction combined with runtime feedback can continuously rebalance instance ratios across stages under fast-changing workloads without introducing new overheads that offset the reported gains.
What would settle it
Run the system on a workload that rapidly alternates between high-resolution and low-resolution prompts at varying batch sizes and measure whether the observed throughput and latency improvements hold or whether scheduling overheads erase them.
Figures




read the original abstract
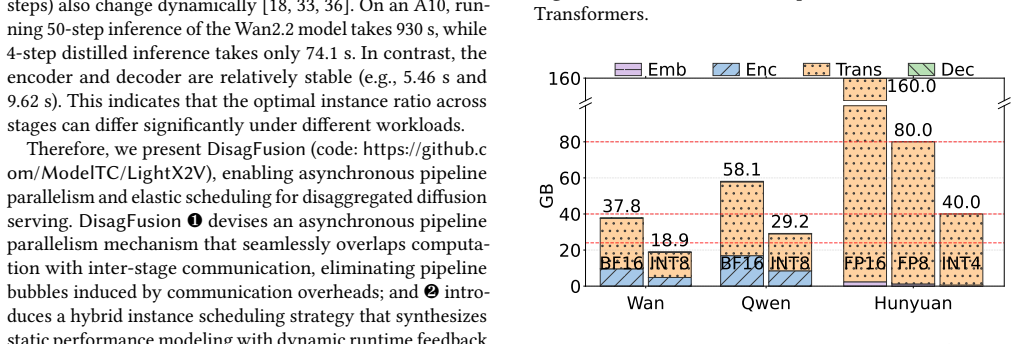
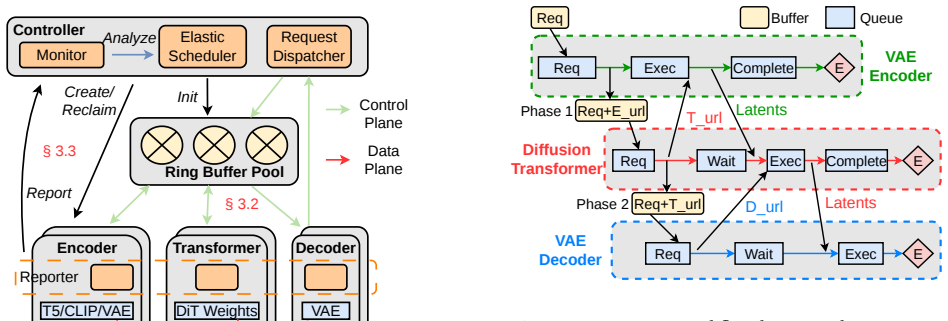
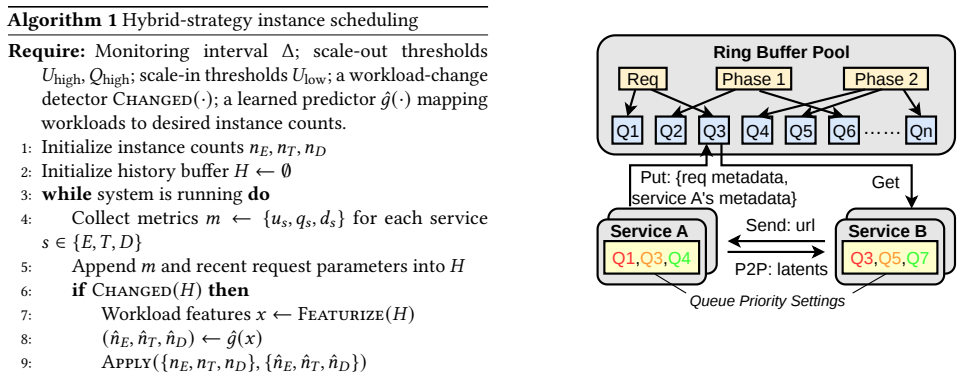
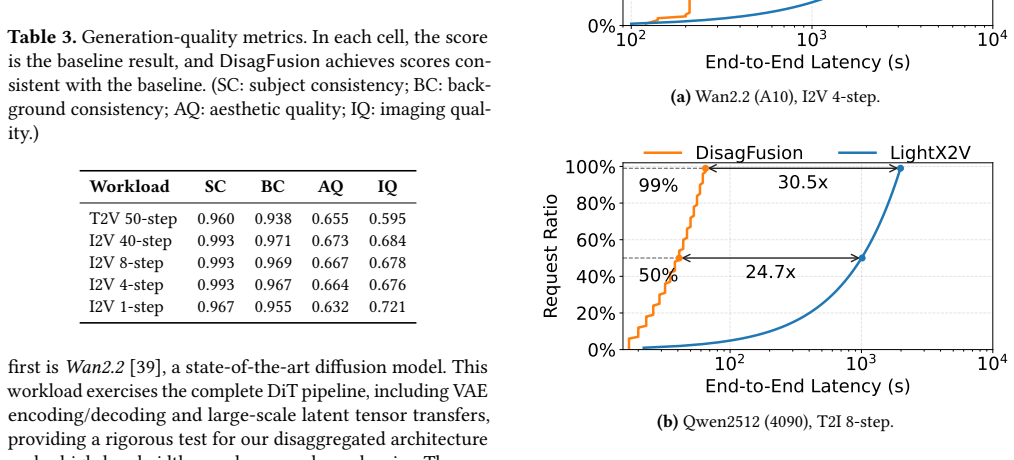
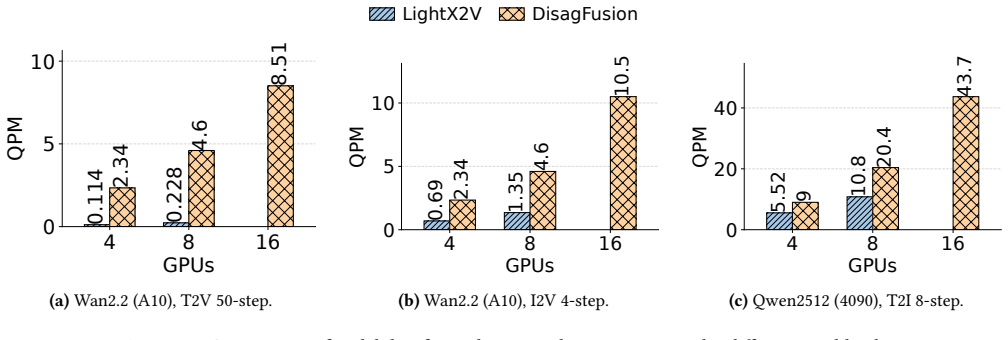
Diffusion-based generation is increasingly powering production content pipelines; however, deploying these models at scale remains a significant challenge. Model weights frequently exceed the memory capacity of commodity GPUs, while the encoder, diffusion transformer (DiT), and decoder stages exhibit highly imbalanced computational and memory footprints. A natural remedy is disaggregated serving-running stages as separate services on heterogeneous GPUs-yet this introduces new bottlenecks, including stage handoff overheads and fast-changing workloads that make cross-stage provisioning and scheduling brittle. This paper presents DisagFusion, enabling asynchronous pipeline parallelism and elastic scheduling for disaggregated diffusion serving. First, DisagFusion introduces asynchronous pipeline parallelism that overlaps computation and stage-to-stage communication to reduce pipeline bubbles and mitigate network jitter. Second, DisagFusion employs a hybrid instance scheduling strategy that combines lightweight performance prediction with runtime feedback to continuously rebalance instance ratio across stages under workload shifts. We implement DisagFusion and evaluate it with modern diffusion models. Compared to a monolithic baseline, DisagFusion improves throughput by 3.4x-20.5x and reduces end-to-end latency by 18.5x, while enabling flexible, cost-efficient deployment across heterogeneous GPUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DisagFusion for disaggregated diffusion model serving. It proposes asynchronous pipeline parallelism to overlap computation with stage-to-stage communication and reduce bubbles/jitter, plus a hybrid scheduling strategy that combines lightweight performance prediction with runtime feedback to dynamically rebalance instance ratios across encoder/DiT/decoder stages under shifting workloads. The central empirical claim is that this yields 3.4x–20.5x higher throughput and 18.5x lower end-to-end latency versus a monolithic baseline while supporting cost-efficient heterogeneous GPU deployments.
Significance. If the performance numbers and negligible-overhead assumption hold under realistic traces, the work would be a meaningful practical contribution to scalable diffusion serving, directly addressing memory-capacity limits and stage imbalance that currently hinder production deployment. The hybrid prediction+feedback scheduler and async pipeline are concrete engineering advances that could influence disaggregated inference systems more broadly.
major comments (2)
- [Evaluation section (performance claims and scheduler description)] The headline speedups rest on the unquantified claim that the hybrid scheduling loop (lightweight prediction + runtime feedback for rebalancing) adds negligible overhead relative to the 3.4x–20.5x gains. No ablation, no measured rebalancing latency, and no breakdown of feedback cost versus pipeline-stall or bandwidth overhead appear in the evaluation; this is load-bearing for the central claim because rapid workload shifts could make the rebalancing loop itself the dominant cost.
- [Evaluation section] The abstract states that the strategy 'continuously rebalance[s] instance ratio across stages under workload shifts' but supplies no concrete workload traces, shift frequencies, or sensitivity analysis showing that the prediction model remains accurate enough to avoid conservative over-provisioning that would shrink the reported deltas.
minor comments (2)
- The abstract would be strengthened by naming the specific diffusion models, input resolutions, and heterogeneous GPU configurations used for the 3.4x–20.5x and 18.5x numbers.
- Notation for 'instance ratio' and the exact formulation of the lightweight performance predictor should be defined earlier and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the evaluation section. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation section (performance claims and scheduler description)] The headline speedups rest on the unquantified claim that the hybrid scheduling loop (lightweight prediction + runtime feedback for rebalancing) adds negligible overhead relative to the 3.4x–20.5x gains. No ablation, no measured rebalancing latency, and no breakdown of feedback cost versus pipeline-stall or bandwidth overhead appear in the evaluation; this is load-bearing for the central claim because rapid workload shifts could make the rebalancing loop itself the dominant cost.
Authors: We agree the manuscript lacks explicit ablations and measurements of rebalancing overhead. The design uses lightweight prediction to keep costs low, but without quantified data the claim is under-supported. In revision we will add an ablation isolating the feedback loop, measured rebalancing latencies under varying shift rates, and a breakdown versus pipeline and bandwidth costs. revision: yes
-
Referee: [Evaluation section] The abstract states that the strategy 'continuously rebalance[s] instance ratio across stages under workload shifts' but supplies no concrete workload traces, shift frequencies, or sensitivity analysis showing that the prediction model remains accurate enough to avoid conservative over-provisioning that would shrink the reported deltas.
Authors: The current evaluation demonstrates rebalancing under shifts but does not include the requested traces, frequencies, or sensitivity results. We will add representative workload traces, quantified shift frequencies, and sensitivity analysis of the prediction model in the revised evaluation to substantiate accuracy and rule out over-provisioning effects. revision: yes
Circularity Check
No significant circularity; claims rest on empirical implementation and evaluation
full rationale
The paper presents a systems design for disaggregated diffusion serving using asynchronous pipeline parallelism and a hybrid scheduling strategy (lightweight prediction plus runtime feedback). All headline performance numbers (3.4x-20.5x throughput, 18.5x latency) are stated as results of implementing the system and measuring it against a monolithic baseline. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the provided text; the scheduling approach is described at the architectural level without any reduction of outputs to inputs by construction. The derivation chain is therefore self-contained empirical measurement rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. arXiv preprint arXiv:2403.02310.https://doi.org/ 10.48550/arXiv.2403.02310
-
[2]
Andreas Blattmann et al . 2023. VideoLDM: Latent Video Diffu- sion Models for High-Fidelity Video Generation.arXiv preprint arXiv:2304.08818(2023).https://doi.org/10.48550/arXiv.2304.08818
-
[3]
Language Models are Few-Shot Learners
Tom B. Brown et al. 2020. Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165(2020).https://doi.org/10.48550/arXiv .2005.14165
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2020
-
[4]
Patrick H Coppock, Brian Zhang, Eliot H Solomon, Vasilis Kypriotis, Leon Yang, Bikash Sharma, Dan Schatzberg, Todd C Mowry, and Dimitrios Skarlatos. 2025. LithOS: An operating system for efficient machine learning on GPUs. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 1–17
2025
-
[5]
Daniel Crankshaw et al. 2020. InferLine: Latency-aware Provisioning and Scaling for Prediction Serving Pipelines. InProceedings of the 2020 ACM Symposium on Operating Systems Principles (SOSP 20)
2020
-
[6]
Yuwei Guo et al. 2023. AnimateDiff: Animate Your Personalized Text- to-Image Diffusion Models without Specific Tuning.arXiv preprint arXiv:2307.04725(2023).https://doi.org/10.48550/arXiv.2307.04725
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.04725 2023
-
[7]
Jonathan Ho et al. 2022. Imagen Video: High Definition Video Gener- ation with Diffusion Models.arXiv preprint arXiv:2210.02303(2022). https://doi.org/10.48550/arXiv.2210.02303
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.02303 2022
-
[8]
Jonathan Ho, William Chan, Chitwan Saharia, et al . 2022. Video Diffusion Models.arXiv preprint arXiv:2204.03458(2022).https: //doi.org/10.48550/arXiv.2204.03458
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.03458 2022
-
[9]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models.arXiv preprint arXiv:2006.11239(2020).https: //doi.org/10.48550/arXiv.2006.11239
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2006.11239 2020
-
[10]
Xiaoxiao Jiang, Suyi Li, Lingyun Yang, Tianyu Feng, Zhipeng Di, Weiyi Lu, Guoxuan Zhu, Xiu Lin, Kan Liu, Yinghao Yu, et al. 2026. FlashPS: Efficient Generative Image Editing with Mask-aware Caching and Scheduling. InProceedings of the 21st European Conference on Computer Systems. 2109–2125
2026
-
[11]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica
-
[12]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Efficient Memory Management for Large Language Model Serving with PagedAttention. arXiv preprint arXiv:2309.06180.https: //doi.org/10.48550/arXiv.2309.06180
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.06180
-
[13]
Suyi Li, Lingyun Yang, Xiaoxiao Jiang, Hanfeng Lu, Dakai An, Zhipeng Di, Weiyi Lu, Jiawei Chen, Kan Liu, Yinghao Yu, et al . 2025. Katz: Efficient workflow serving for diffusion models with many adapters. In2025 USENIX Annual Technical Conference (USENIX ATC 25). 1037– 1052
2025
-
[14]
Yifan Li, Zhaoyang Zhang, Haoyang Wu, Zhenhua Zheng, Hao Zhang, and Kaiming Chen. 2024. SwiftDiffusion: Efficient Diffusion Model Serving with Add-on Modules.arXiv preprint arXiv:2407.02031(2024). https://doi.org/10.48550/arXiv.2407.02031
-
[15]
Zhen Li, Chen Feng, Yuhang Yang, Zongyi Wang, Yuxuan Zhang, and Wei Chen. 2024. DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2024
-
[16]
Gonzalez, and Ion Stoica
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). USENIX Association, 663–679
2023
-
[17]
Yanying Lin, Shuaipeng Wu, Shutian Luo, Hong Xu, Haiying Shen, Chong Ma, Min Shen, Le Chen, Chengzhong Xu, Lin Qu, et al. 2025. Understanding Diffusion Model Serving in Production: A Top-Down Analysis of Workload, Scheduling, and Resource Efficiency. InPro- ceedings of the 2025 ACM Symposium on Cloud Computing. 1–15
2025
-
[18]
Yuan Liu, Jinyang Zhang, Ming Xu, Wei Li, Kai Chen, and Hao Zhang
-
[19]
LegoDiffusion: Micro-Serving Text-to-Image Diffusion Workflows
LegoDiffusion: Modular Diffusion Models with Pluginable Adapters. arXiv preprint arXiv:2604.08123.https://doi.org/10.4 8550/arXiv.2604.08123
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Michael Luo, Aaron Hao, Zhengxu Yan, Chengkun Cao, and Quang Luong Nhat Nguyen. 2025. DiT-Serve: An Efficient Serving Engine for Diffusion Transformers. arXiv preprint. To appear
2025
-
[21]
ModelTC. 2025. LightX2V. GitHub repository.https://github.com/M odelTC/LightX2V
2025
-
[22]
Mooncake Project. 2025. Mooncake Transfer Engine Design. Online documentation.https://kvcache-ai.github.io/mooncake/docs/transfe r-engine.html
2025
-
[23]
Deepak Narayanan et al. 2020. Clockwork: Predictable Performance for Unpredictable Workloads. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20)
2020
-
[24]
NVIDIA. 2024. GPUDirect RDMA (NVIDIA Documentation). NVIDIA Developer Documentation.https://docs.nvidia.com/cuda/gpudirect- rdma/
2024
-
[25]
William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Transformers. arXiv preprint arXiv:2212.09748.https://doi.org/ 10.48550/arXiv.2212.09748
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.09748 2023
-
[26]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Heyi Tang, Feng Ren, Teng Ma, Shangming Cai, Yineng Zhang, Mingxing Zhang, et al. 2024. Mooncake: A kvcache-centric disaggregated architecture for llm serv- ing.ACM Transactions on Storage(2024)
2024
- [27]
-
[28]
Qwen Team. 2024. Qwen-Image-2512 (Hugging Face model card). Hugging Face.https://huggingface.co/Qwen/Qwen-Image-2512
2024
-
[29]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis with La- tent Diffusion Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
2022
-
[30]
Chitwan Saharia, William Chan, Saurabh Saxena, et al. 2022. Photore- alistic Text-to-Image Diffusion Models with Deep Language Under- standing.arXiv preprint arXiv:2205.11487(2022).https://doi.org/10.4 8550/arXiv.2205.11487
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
SGLang Project. 2025. SGLang Diffusion Documentation. Online documentation.https://docs.sglang.ai/en/latest/diffusion/
2025
-
[32]
SGLang Team. 2025. SGLang Diffusion: Serving Diffusion Models with SGLang. Blog post.https://lmsys.org/blog/2025-04-21-sglang- diffusion/ 13
2025
-
[33]
Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y. Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. 2023. FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU.arXiv preprint arXiv:2303.06865(2023).https://doi.org/10.48550/ar...
-
[34]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, J. Zohar, et al . 2022. Make-A-Video: Text-to-Video Generation without Text-Video Data.arXiv preprint arXiv:2209.14792(2022).https://doi.org/10.48550/arXiv.2209.14792
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.14792 2022
-
[35]
SoPrompts. 2026. Sora vs Runway vs Pika: Comparison. Blog post. https://soprompts.com/blog/sora-vs-runway-vs-pika
2026
-
[36]
Stability AI et al. 2023. Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets.arXiv preprint arXiv:2311.15127 (2023).https://doi.org/10.48550/arXiv.2311.15127
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.15127 2023
-
[37]
Tencent. 2024. HunyuanVideo (GitHub repository). GitHub.https: //github.com/Tencent/HunyuanVideo
2024
-
[38]
Vidwave. 2026. Pika Labs vs Stable Diffusion Video: Quality Test Results. Blog post.https://vidwave.ai/pika-labs-vs-stable-diffusion- video-quality-test-results
2026
-
[39]
Ruben Villegas et al . 2022. Phenaki: Variable Length Video Gen- eration from Open Domain Textual Descriptions.arXiv preprint arXiv:2210.02399(2022).https://doi.org/10.48550/arXiv.2210.02399
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.02399 2022
-
[40]
Wan-AI. 2024. Wan2.1-T2V-14B (Hugging Face model card). Hugging Face.https://huggingface.co/Wan-AI/Wan2.1-T2V-14B
2024
-
[41]
Wan-Video. 2025. Wan2.2 (GitHub repository). GitHub.https: //github.com/Wan-Video/Wan2.2
2025
-
[42]
Ziyu Wang, Zhe Li, Yao Xu, Yuxuan Zhang, Le Chen, and Hao Zhang
-
[43]
DiffServe: Efficiently Serving Text-to-Image Diffusion Models with Query-Aware Model Scaling.arXiv preprint arXiv:2411.15381 (2024).https://doi.org/10.48550/arXiv.2411.15381
-
[44]
Jay Zhangjie Wu, Yixiao Ge, et al . 2023. Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation.arXiv preprint arXiv:2212.11565(2023).https://doi.org/10.48550/arXiv.2212. 11565
-
[45]
Zhewei Yao et al. 2022. DeepSpeed Inference: Enabling Efficient Infer- ence of Transformer Models at Scale. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC)
2022
-
[46]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Association, 521–538
2022
-
[47]
ZeroMQ Community. 2026. ZeroMQ. Project website.https://zero mq.org/
2026
-
[48]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, 193–210. 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.