Rethinking Scribble-Guided Image Editing: Generalization, Instruction Adherence, and Multi-Tasking
Pith reviewed 2026-06-29 23:04 UTC · model grok-4.3
The pith
Instruction generalization, not image domains, limits scribble-guided editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that instruction-level generalization (across editing tasks and from single-task to multi-task) proves harder than image-domain generalization (synthetic to real or mosaicked to regular), so the bottleneck is learning diverse instructions rather than closing domain gaps. This insight motivates a Coverage-then-Realism Curriculum that first supplies large-scale synthetic instruction-rich data then adds a small real-world set for realism, Multi-Task Mosaicking that concatenates single-task examples into multi-task samples which still generalize to normal images, and an Edit-Focused Loss that weights training toward changed regions in synthetic pairs to raise editing accurac
What carries the argument
The Coverage-then-Realism Curriculum, Multi-Task Mosaicking, and Edit-Focused Loss, which together shift training emphasis from domain adaptation to instruction diversity and region-specific accuracy.
If this is right
- Synthetic data can supply the broad task coverage needed for multi-task capability without requiring equally large real multi-task collections.
- Multi-task skill learned on mosaicked images transfers directly to standard non-mosaicked images at test time.
- Focusing loss on changed regions improves both training speed and final editing precision in instruction-following models.
- Single-task and multi-task scribble editing both advance to new state-of-the-art scores on the VIBE benchmark.
Where Pith is reading between the lines
- The same curriculum-plus-mosaicking pattern could be tested on other spatially guided generation tasks such as sketch-to-image or mask-based editing.
- Public release of the synthetic instruction-rich dataset may allow separate measurement of how much instruction variety alone drives gains.
- The approach suggests that many conditional image models may benefit more from scaling instruction diversity than from scaling real image domains.
Load-bearing premise
The asymmetry seen when testing one open-source model shows that instruction learning, not image domain gaps, is the main bottleneck for the whole approach.
What would settle it
A controlled test in which models trained only on diverse real-world editing instructions without the curriculum or mosaicking match or exceed the reported multi-task gains on VIBE.
Figures
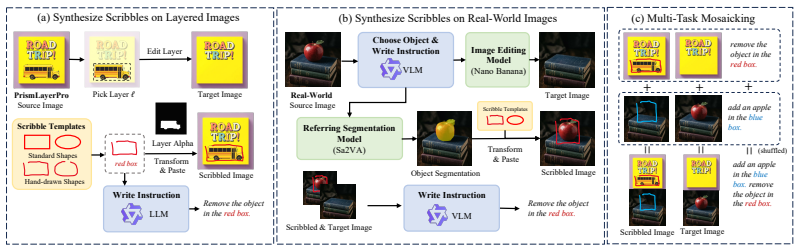
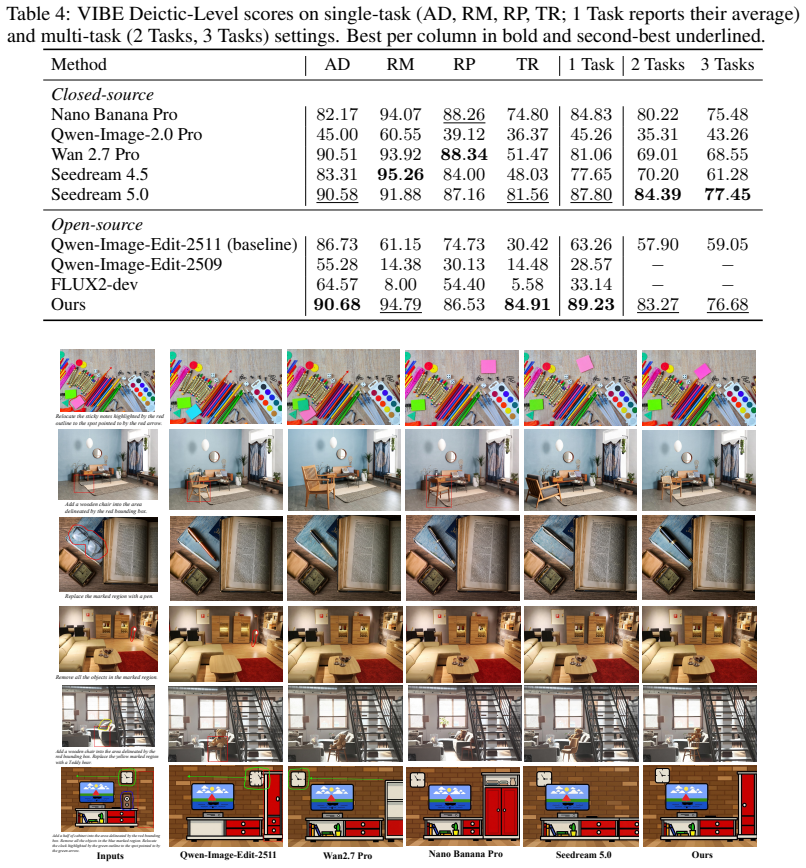
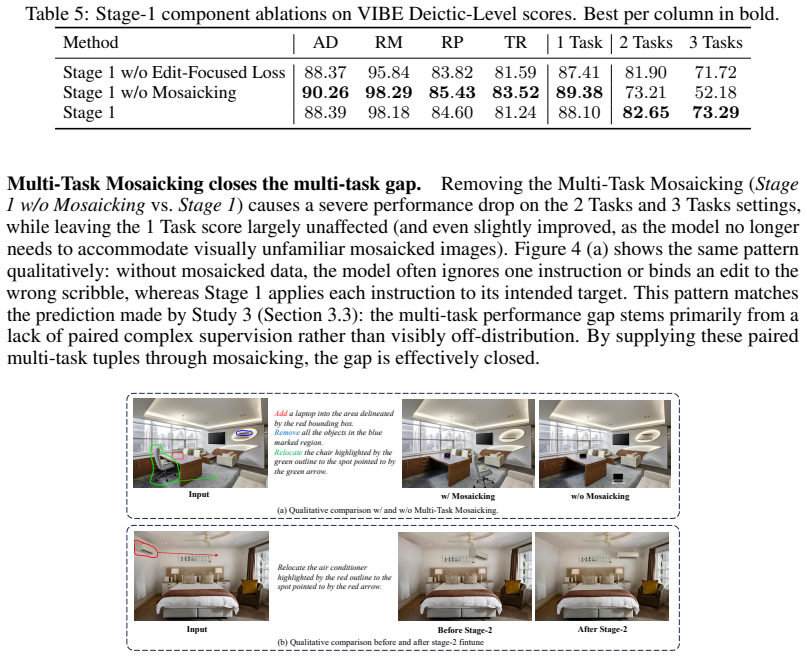
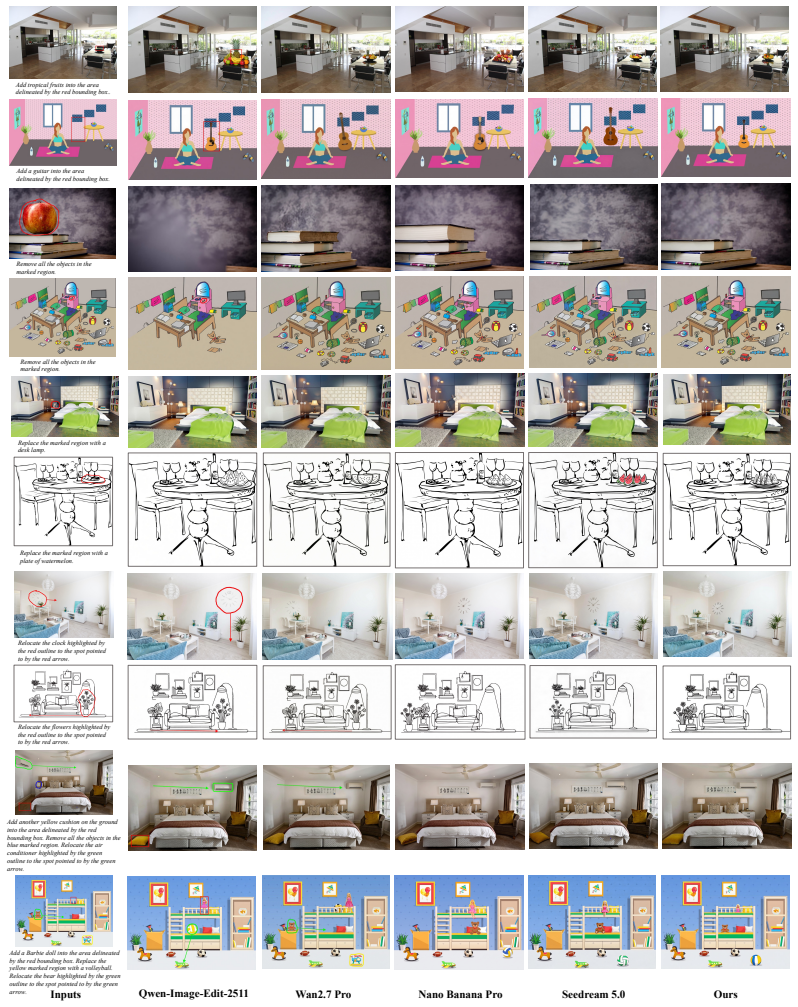

read the original abstract
Scribble-guided image editing allows users to combine simple scribble annotations with text prompts to specify both where and how an image should be edited, enabling flexible interaction with precise spatial control. However, existing models still exhibit unstable performance under this paradigm, especially in multi-task scenarios. To improve performance, we conduct empirical studies using an open-source editing model and reveal an asymmetry in generalization: instruction-level generalization, including across editing tasks and from single-task to multi-task settings, is more challenging than image-domain generalization, such as from synthetic to real-world images or from mosaicked to regular images. This suggests that the primary bottleneck lies in insufficient learning for diverse editing instructions rather than in the image domain gap. Motivated by this insight, we propose three strategies: (a) a Coverage-then-Realism Curriculum, a two-stage pipeline that first builds large-scale synthetic, instruction-rich data for broad task supervision, then curates a small set of real-world data to refine generation realism; (b) Multi-Task Mosaicking, which constructs multi-task training samples by concatenating single-task examples at nearly zero cost while enabling the learned capability to generalize to non-mosaicked images; and (c) an Edit-Focused Loss, which leverages the changed regions between input and output images in synthetic data to focus training on edited regions, improving both learning efficiency and editing accuracy. With these strategies, we substantially improve both single-task and multi-task scribble-guided editing on the VIBE benchmark, achieving state-of-the-art results. We will publicly release our dataset and model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts empirical studies on a single open-source scribble-guided editing model revealing an asymmetry where instruction-level generalization (across tasks and single-to-multi-task) is harder than image-domain generalization. Motivated by this, it proposes three strategies—Coverage-then-Realism Curriculum, Multi-Task Mosaicking, and Edit-Focused Loss—to address insufficient instruction learning. These yield substantial improvements and state-of-the-art results on the VIBE benchmark for both single-task and multi-task scribble-guided editing; the authors will release the dataset and model.
Significance. If the quantitative results hold, the work supplies concrete, low-cost training strategies that improve both single- and multi-task performance in a practically relevant setting, together with a public dataset and model release that would aid reproducibility and further research in controllable image editing.
major comments (2)
- [Abstract] Abstract: the central motivation and interpretation rest on generalization asymmetry observed exclusively on one open-source editing model; if this asymmetry is idiosyncratic to that model's training data or architecture, the claim that 'the primary bottleneck lies in insufficient learning for diverse editing instructions' does not necessarily generalize, weakening the link between the observed asymmetry and the applicability of the three proposed strategies to other models.
- [Abstract] Abstract: the manuscript states that the strategies achieve 'state-of-the-art results' on VIBE but supplies no quantitative metrics, baseline numbers, ablation tables, or error analysis in the provided text; without these, it is impossible to verify whether the data actually support the central performance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating where we agree revisions are warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central motivation and interpretation rest on generalization asymmetry observed exclusively on one open-source editing model; if this asymmetry is idiosyncratic to that model's training data or architecture, the claim that 'the primary bottleneck lies in insufficient learning for diverse editing instructions' does not necessarily generalize, weakening the link between the observed asymmetry and the applicability of the three proposed strategies to other models.
Authors: We acknowledge that the empirical studies were performed on a single open-source model, as explicitly stated in the manuscript. This choice was made because the model is publicly available and representative of current approaches. We cannot rule out that the observed asymmetry is model-specific without further experiments on other architectures or training regimes. The proposed strategies are general training techniques (curriculum, mosaicking, and focused loss) intended to improve instruction learning, and we demonstrate their benefits on VIBE. We will add an explicit limitations paragraph noting the single-model scope and softening the generalization claim. revision: yes
-
Referee: [Abstract] Abstract: the manuscript states that the strategies achieve 'state-of-the-art results' on VIBE but supplies no quantitative metrics, baseline numbers, ablation tables, or error analysis in the provided text; without these, it is impossible to verify whether the data actually support the central performance claim.
Authors: The abstract is a concise summary constrained by length limits and does not include detailed numbers. The full manuscript provides quantitative metrics, baseline comparisons, ablation tables, and error analysis in the experiments section and tables. These support the SOTA claim on VIBE for both single- and multi-task settings. revision: no
- Whether the observed generalization asymmetry is idiosyncratic to the single open-source model studied
Circularity Check
No circularity: empirical observation on external model motivates heuristic strategies validated on independent benchmark
full rationale
The paper conducts empirical studies on a single open-source editing model to observe an asymmetry between instruction-level and image-domain generalization. This observation directly motivates three heuristic strategies (curriculum learning, multi-task mosaicking, edit-focused loss) without any equations, fitted parameters, or mathematical derivations. No self-citations are invoked as load-bearing uniqueness theorems or to smuggle in ansatzes. The claimed improvements are measured against the external VIBE benchmark, rendering the work self-contained. The model-specific nature of the asymmetry is a potential limitation on generalizability but does not constitute circularity in the derivation chain, as the strategies are not forced by definition or prior self-referential results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Blended diffusion for text-driven editing of natural images.arXiv preprint arXiv:2111.14818, 2021
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images.arXiv preprint arXiv:2111.14818, 2021
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs. Flux.1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
FLUX.2: Frontier visual intelligence
Black Forest Labs. FLUX.2: Frontier visual intelligence. https://bfl.ai/blog/flux-2, November
-
[5]
Accessed: 2026-05-07
2026
-
[6]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18392–18402, 2023
2023
-
[7]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
ByteDance Seed Team. Seedream 4.0: Toward next-generation multimodal image generation.arXiv preprint arXiv:2509.20427, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Deeper thinking, more accurate generation | in- troducing seedream 5.0 lite
ByteDance Seed Team. Deeper thinking, more accurate generation | in- troducing seedream 5.0 lite. https://seed.bytedance.com/en/blog/ deeper-thinking-more-accurate-generation-introducing-seedream-5-0-lite , 2026. Accessed: 2026-05-07
2026
-
[9]
Prismlayers: Open data for high-quality multi-layer transparent image generative models
Junwen Chen, Heyang Jiang, Yanbin Wang, Keming Wu, Ji Li, Chao Zhang, Keiji Yanai, Dong Chen, and Yuhui Yuan. Prismlayers: Open data for high-quality multi-layer transparent image generative models. arXiv preprint arXiv:2505.22523, 2025
-
[10]
Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based semantic image editing with mask guidance.arXiv preprint arXiv:2210.11427, 2022
-
[11]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis.arXiv preprint arXiv:2403.03206, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Nano banana pro (gemini 3 pro image)
Google DeepMind. Nano banana pro (gemini 3 pro image). https://deepmind.google/models/ gemini-image/pro/, 2025. Released November 2025
2025
-
[13]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to- prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6007–6017, 2023
2023
-
[16]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22511–22521, 2023. 10
2023
-
[17]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
2023
-
[18]
Wan-Image: Pushing the Boundaries of Generative Visual Intelligence
Chaojie Mao, Chen-Wei Xie, Chongyang Zhong, Haoyou Deng, Jiaxing Zhao, Jie Xiao, Jinbo Xing, Jingfeng Zhang, Jingren Zhou, Jingyi Zhang, et al. Wan-image: Pushing the boundaries of generative visual intelligence.arXiv preprint arXiv:2604.19858, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Qi Mao, Lan Chen, Yuchao Gu, Zhen Fang, and Mike Zheng Shou. Mag-edit: Localized image editing in complex scenarios via mask-based attention-adjusted guidance.arXiv preprint arXiv:2312.11396, 2023
-
[20]
Weihang Mao, Bo Han, and Zihao Wang. Sketchffusion: Sketch-guided image editing with diffusion model.arXiv preprint arXiv:2304.03174, 2023
-
[21]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6038–6047, 2023
2023
-
[22]
T2i- adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models
Chong Mou, Xintao Wang, Liangbin Xie, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i- adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI Conference on Artificial Intelligence, 2024
2024
-
[23]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, 2023
2023
-
[24]
Tianyuan Qu, Lei Ke, Xiaohang Zhan, Longxiang Tang, Yuqi Liu, Bohao Peng, Bei Yu, Dong Yu, and Jiayi Jia. Replan: Reasoning-guided region planning for complex instruction-based image editing.arXiv preprint arXiv:2512.16864, 2025
-
[25]
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, and Dacheng Tao. A survey of multimodal-guided image editing with text-to-image diffusion models.arXiv preprint arXiv:2406.14555, 2024
-
[26]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Dreamomni3: Scribble-based editing and generation.arXiv preprint arXiv:2512.22525, 2025
Bin Xia, Bohao Peng, Jiyang Liu, Sitong Wu, Jingyao Li, Junjia Huang, Xu Zhao, Yitong Wang, Ruihang Chu, Bei Yu, et al. Dreamomni3: Scribble-based editing and generation.arXiv preprint arXiv:2512.22525, 2025
-
[28]
InProceedings of the SIGGRAPH Asia 2025 Conference Papers (SA Conference Papers ’25)
Jinheng Xie, Yuexiang Li, Yawen Huang, Haozhe Liu, Wentian Zhang, Yefeng Zheng, and Mike Zheng Shou. Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 7418–7427. IEEE, 2023. doi: 10.1109/ICCV51070.2023.00685. URL https://...
-
[29]
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Haobo Yuan, Xiangtai Li, Tao Zhang, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Jiashi Feng, and Ming-Hsuan Yang. Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos.arXiv preprint arXiv:2501.04001, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Huanyu Zhang, Xuehai Bai, Chengzu Li, Chen Liang, Haochen Tian, Haodong Li, Ruichuan An, Yifan Zhang, Anna Korhonen, Zhang Zhang, et al. How well do models follow visual instructions? vibe: A systematic benchmark for visual instruction-driven image editing.arXiv preprint arXiv:2602.01851, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, 2023
2023
-
[32]
Yudi Zhang, Yeming Geng, and Lei Zhang. Scribblesense: Generative scribble-based texture editing with intent prediction.arXiv preprint arXiv:2601.22455, 2026
-
[33]
Uni-controlnet: All-in-one control to text-to-image diffusion models
Shihao Zhao, Dongdong Chen, Yen-Chun Chen, Jianmin Bao, Shaozhe Hao, and Lu Yuan. Uni-controlnet: All-in-one control to text-to-image diffusion models. InAdvances in Neural Information Processing Systems, 2023. 11 A Full Experimental Results Table 7 reports the full VIBE Deictic-Level results corresponding to Table 4 in the main paper, including the mean ...
2023
-
[34]
Visual Instruction Localization Correctness Did the main edit occur on the text target explicitly indicated by the visual instruction on the Input Image (The second image)?
-
[35]
Visual Operator Type Compliance Was the type of edit consistent with the operation implied by the visual instruction?
-
[36]
Textual Action Semantic Compliance Did the model execute the core textual action specified in the Text Prompt?
-
[37]
score": an integer value of 0 or 1. -
Text Re-layout Compliance When the requested text edit changes the amount, size, or placement of text, did the model adjust the affected line, paragraph, or text block layout appropriately? - Judge whether the new layout looks reasonable and natural for the affected line, paragraph, or text block. - The result should not leave obvious blank gaps, squeezed...
-
[38]
- Ignore content missing only due to cropping
Cropping rule - If the output is cropped, only compare the overlapping visible region. - Ignore content missing only due to cropping
-
[39]
- Do NOT list differences caused only by: - minor blur or softness, - small texture or color shifts, - pixel-level noise, - slight position or alignment offsets
Difference listing (what counts as a difference) - List ONLY meaningful differences in: - text content (characters, words), - text order (line order, word order), - typography (font family, size, weight, color, emphasis, case), - non-text visual entities (objects, background). - Do NOT list differences caused only by: - minor blur or softness, - small tex...
-
[40]
Target rule - Identify the intended edit target based ONLY on: (a) the visual instruction marks, and (b) the text prompt
-
[41]
- Failed or awkward reflow inside the affected block is NOT judged here
Re-layout scope rule - Reasonable line wrapping, spacing changes, and local repositioning INSIDE the affected text block are IN_TARGET when they are a consequence of the requested edit, even if nearby unedited words shift to new line positions inside that same affected block. - Failed or awkward reflow inside the affected block is NOT judged here. - This ...
-
[42]
- OUT_OF_TARGET: - any change to unrelated objects or regions, - any addition or removal of unrelated semantic entities, - any structural damage to non-target objects
Classification rule - IN_TARGET: - any change within the intended target, - OR any imperfect attempt to edit the target (including misplacement, offset, scale error, or incomplete coverage). - OUT_OF_TARGET: - any change to unrelated objects or regions, - any addition or removal of unrelated semantic entities, - any structural damage to non-target objects
-
[43]
Text_Contextual_Preservation
Scoring - Score = 1 if NO OUT_OF_TARGET differences exist. - Score = 0 if ANY OUT_OF_TARGET difference exists. - If unsure, score = 0. Output format: First provide a brief analysis with these sections: - ## Differences - ## Target - ## Classification - ## Decision Then output the final JSON as the last part of your response: { "Text_Contextual_Preservatio...
-
[44]
- Score 0 if it introduces a noticeably different from the surrounding source text
Text Style Consistency Did the edited text region adopt the same visual text style as the surrounding or corresponding source text (e.g., font family, font size, weight, color, perspective, rotation, curvature, and surface deformation)? Scoring: - Score 1 if the edited / added text clearly belongs to the same visual text domain and matches the surrounding...
-
[45]
Scoring: - Score 1 if the edited text integrates seamlessly with its immediate surrounding layout
Text Layout Seamlessness Is the edited text visually integrated with the surrounding text line, paragraph, surface, or document layout, with no obvious local discontinuity? Focus on clear local layout discontinuities such as: - unnatural seams or hard boundaries around the edited text, - overlapping characters or visibly broken character spacing within th...
-
[46]
score": an integer value of 0 or 1. -
Artifact-Free Text Generation Does the Output Image avoid obvious text-specific or general generative artifacts? Consider artifacts such as: - unreadable, garbled, melted, duplicated, or malformed glyphs in the edited text, - broken or inconsistent strokes, - ghost text or leftover erased text under the edit, - unintended blur, pixelation, warping, or ren...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.