Llamion Technical Report
Pith reviewed 2026-06-29 22:01 UTC · model grok-4.3
The pith
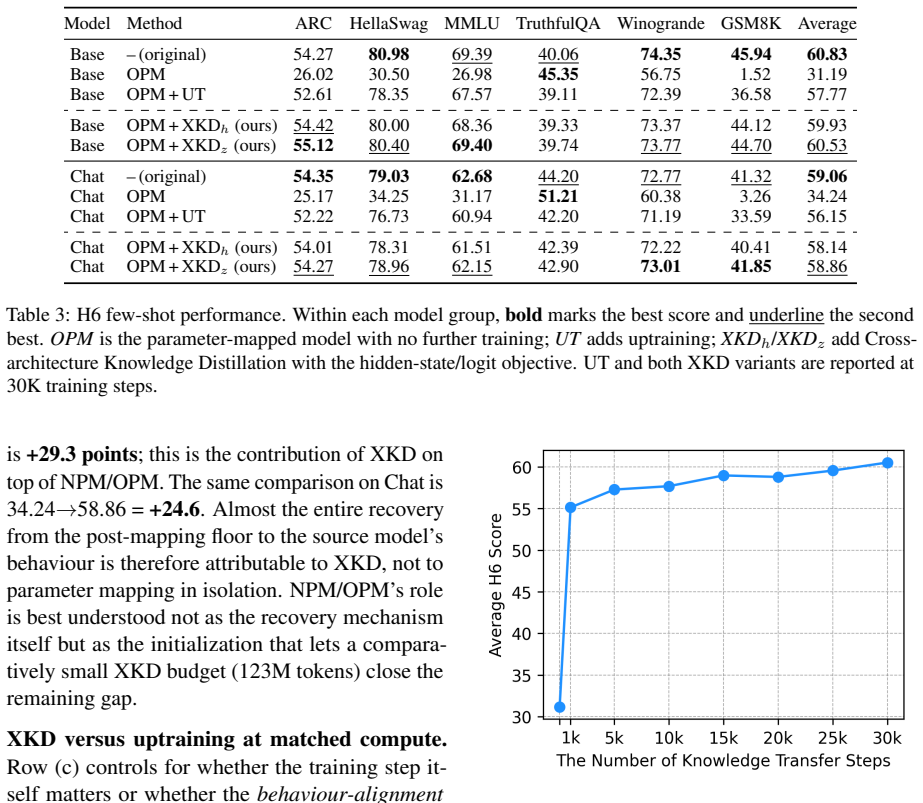
Llamion converts Orion-14B to Llama architecture via KEPT and recovers its benchmark behavior with 123M tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KEPT performs the Orion-to-Llama conversion by applying Normal Parameter Mapping to matching modules, Optimized Parameter Mapping to convert LayerNorm to RMSNorm, and Cross-architecture Knowledge Distillation from a frozen equal-size teacher, allowing the converted 14B model to match source behavior on standard benchmarks while preserving out-of-distribution skills.
What carries the argument
KEPT (Efficient Knowledge Preservation for Transformation) recipe that combines Normal Parameter Mapping, Optimized Parameter Mapping for LayerNorm-to-RMSNorm initialization, and Cross-architecture Knowledge Distillation.
If this is right
- Llamion-Base exceeds the next-best Open Ko LLM Leaderboard entry by more than 7 absolute points on KoMMLU.
- Capabilities entirely absent from the transfer corpus survive the architectural transition.
- The three released checkpoints load in Hugging Face Transformers with trust_remote_code set to false.
Where Pith is reading between the lines
- The same mapping-plus-distillation steps could be tested on other source-target architecture pairs to check whether the compute savings generalize.
- If OPM initialization proves robust across different weight-decay strengths, it may reduce the need for full retraining when swapping normalization layers.
- Long-context handling that survives the conversion suggests the method preserves positional or attention patterns beyond what the small distillation set explicitly teaches.
Load-bearing premise
That Optimized Parameter Mapping is optimal under the near-zero-mean activation regime induced by weight decay and that cross-architecture distillation will align outputs on any reasonable input distribution without degrading unseen capabilities.
What would settle it
If the converted model fails to recover Orion's scores on H6, MT-Bench, and KoMMLU after the KEPT procedure, or if Python programming and 200K-token context handling degrade despite never appearing in the transfer corpus.
Figures



read the original abstract
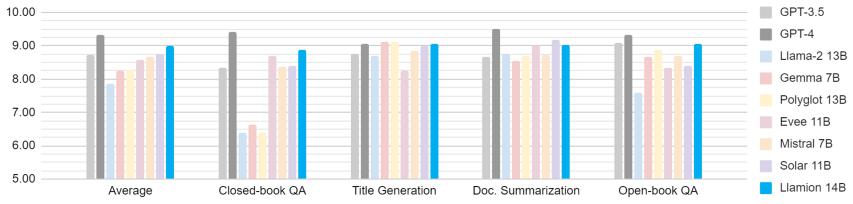
We release Llamion, a family of 14B-parameter open-weight language models obtained by transforming Orion-14B into the standardized Llama-family architecture. The transformation is performed by Efficient Knowledge Preservation for Transformation (KEPT), a recipe that combines (i) Normal Parameter Mapping (NPM) for unchanged modules, (ii) Optimized Parameter Mapping (OPM), a training-free LayerNorm-to-RMSNorm initialization we prove optimal under the near-zero-mean activation regime induced by weight decay, and (iii) Cross-architecture Knowledge Distillation (XKD), an equal-size frozen-teacher distillation that aligns the converted model's outputs with the source model's on any reasonable input distribution. Llamion recovers Orion's behaviour on H6, MT-Bench, and KoMMLU with only ~123M tokens on a single A100 in four days; Llamion-Base reaches 66.87% on KoMMLU, exceeding the next-best entry of the Open Ko LLM Leaderboard by >7.0 absolute points at submission time. Capabilities entirely absent from the transfer corpus (Python programming and 200K-token context handling) survive the architectural transition intact. We release three checkpoints (Base, Chat, LongChat) that load with trust_remote_code=False in the Hugging Face Transformers library.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Llamion, a 14B-parameter model family obtained by converting Orion-14B to Llama-family architecture via the KEPT recipe. KEPT combines Normal Parameter Mapping (NPM) for unchanged modules, Optimized Parameter Mapping (OPM) claimed as a training-free optimal LayerNorm-to-RMSNorm initialization under a near-zero-mean activation regime from weight decay, and Cross-architecture Knowledge Distillation (XKD) that aligns outputs with a frozen teacher on any reasonable distribution. The work reports recovering Orion performance on H6, MT-Bench, and KoMMLU using only ~123M tokens on one A100 over four days, with Llamion-Base reaching 66.87% on KoMMLU (exceeding the prior Open Ko LLM Leaderboard best by >7 points at submission), and claims that capabilities absent from the transfer corpus (Python programming, 200k context) survive intact. Three checkpoints are released that load without trust_remote_code in Hugging Face Transformers.
Significance. If the central claims hold after verification, the result would demonstrate a low-compute architecture-conversion technique that preserves benchmark behavior and unseen capabilities, which could be useful for adapting existing models to standardized formats. The open release of compatible checkpoints and the reported efficiency (123M tokens, single A100) are concrete strengths. The leaderboard margin on KoMMLU would be notable if supported by error bars and ablations.
major comments (3)
- [Abstract / OPM description] Abstract and OPM section: the claim that OPM is proved optimal under the near-zero-mean activation regime induced by weight decay is load-bearing for the training-free conversion assertion, yet the text provides neither the derivation/equations establishing optimality nor empirical confirmation that Orion-14B activations satisfy the near-zero-mean condition.
- [XKD description / capability preservation results] XKD and results sections: the assertion that XKD aligns outputs on any reasonable input distribution without degrading capabilities absent from the 123M-token corpus (Python, 200k context) is central to the 'intact survival' claim, but no control experiments, ablations, or before/after comparisons on those held-out tasks are described.
- [KoMMLU results] Benchmark results: the reported 66.87% KoMMLU score and >7-point lead lack error bars, multiple runs, or statistical tests; combined with the absence of ablation results noted in the abstract, this weakens confidence in the leaderboard claim and the overall performance-recovery narrative.
minor comments (2)
- [Abstract] The abstract states performance recovery on H6 and MT-Bench but does not specify the exact metrics or baselines used for 'recovers Orion's behaviour'.
- [Experimental setup] No details are given on the exact composition of the 123M-token corpus or the training hyperparameters for XKD.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our technical report. We address each major comment point-by-point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract / OPM description] Abstract and OPM section: the claim that OPM is proved optimal under the near-zero-mean activation regime induced by weight decay is load-bearing for the training-free conversion assertion, yet the text provides neither the derivation/equations establishing optimality nor empirical confirmation that Orion-14B activations satisfy the near-zero-mean condition.
Authors: We acknowledge that the submitted manuscript states the optimality claim for OPM but does not include the explicit derivation or equations. The proof proceeds from the near-zero-mean activation assumption (induced by weight decay) to show that the RMSNorm initialization derived from LayerNorm parameters minimizes the output discrepancy in closed form. We will add a dedicated subsection in the revised OPM description containing the full mathematical derivation, supporting equations, and an empirical check of activation statistics on Orion-14B samples to confirm the regime holds. revision: yes
-
Referee: [XKD description / capability preservation results] XKD and results sections: the assertion that XKD aligns outputs on any reasonable input distribution without degrading capabilities absent from the 123M-token corpus (Python, 200k context) is central to the 'intact survival' claim, but no control experiments, ablations, or before/after comparisons on those held-out tasks are described.
Authors: The manuscript bases the 'any reasonable distribution' alignment claim on the equal-size frozen-teacher XKD objective and reports post-conversion performance on held-out capabilities. We agree that explicit ablations isolating XKD's contribution and direct before/after comparisons on Python and long-context tasks are absent. We will expand the results section to include a limitations paragraph noting the lack of such controls and will add any feasible additional analysis of capability preservation that can be performed within the revision timeline. revision: partial
-
Referee: [KoMMLU results] Benchmark results: the reported 66.87% KoMMLU score and >7-point lead lack error bars, multiple runs, or statistical tests; combined with the absence of ablation results noted in the abstract, this weakens confidence in the leaderboard claim and the overall performance-recovery narrative.
Authors: The reported KoMMLU score reflects a single evaluation run, consistent with common practice for leaderboard submissions at the time. We agree that error bars, multiple runs, or statistical tests would strengthen the claim. In revision we will explicitly state the single-run nature as a limitation, clarify the leaderboard context, and note that the >7-point margin is reported as observed at submission time without additional variance estimates. revision: yes
Circularity Check
No circularity: derivation chain remains self-contained
full rationale
The paper presents OPM as a training-free mapping proved optimal under an explicitly stated near-zero-mean activation regime, and XKD as an alignment procedure whose preservation of absent capabilities is asserted as an empirical outcome after limited-token training. No equations, fitted parameters, or self-citations are shown that would make the optimality claim, alignment guarantee, or benchmark recoveries reduce by construction to the method's own inputs or prior author work. The reported KoMMLU gains and capability survival are therefore independent empirical results rather than tautological restatements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GQA: Training generalized multi-query trans- former models from multi-head checkpoints. InPro- ceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 4895– 4901, Singapore. Association for Computational Lin- guistics. Jimmy Ba and Rich Caruana. 2014. Do deep nets really need to be deep?Advances in neural information p...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. DeepSeek-AI. 2024. DeepSeek-V3 technical report. Preprint, arXiv:2412.19437. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, and 1 others. 2024. The llama 3 herd of models.Preprint, arXiv:2407.21783. Leo Gao, Jonathan Tow, Baber Abbasi, Stella Bider- man, Sid Bl...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Distilling the Knowledge in a Neural Network
Measuring massive multitask language under- standing. InInternational Conference on Learning Representations. Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. Preprint, arXiv:1503.02531. 9 Albert Q. Jiang, Alexandre Sablayrolles, Arthur Men- sch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, F...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[4]
Linearizing large language models.arXiv preprint arXiv:2405.06640, 2024
Linearizing large language models.Preprint, arXiv:2405.06640. Chanjun Park, Hyeonwoo Kim, Dahyun Kim, Seongh- wan Cho, Sanghoon Kim, Sukyung Lee, Yungi Kim, and Hwalsuk Lee. 2024. Open ko-llm leaderboard: Evaluating large language models in korean with ko- h5 benchmark. InACL Main. Qwen Team. 2024. Qwen2.5 technical report.Preprint, arXiv:2412.15115. Keis...
-
[5]
A Survey on Knowledge Distillation of Large Language Models
Baize: An open-source chat model with parameter-efficient tuning on self-chat data. InPro- ceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 6268– 6278, Singapore. Association for Computational Lin- guistics. Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, and Tianyi ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Ming Zhong, Chenxin An, Weizhu Chen, Jiawei Han, and Pengcheng He
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Pro- cessing Systems, 36. Ming Zhong, Chenxin An, Weizhu Chen, Jiawei Han, and Pengcheng He. 2024. Seeking neural nuggets: Knowledge transfer in large language models from a parametric perspective. InThe Twelfth International Conference on Learning Representations. 11 A ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.