SplitAvatar: One-shot Head Avatar with Autoregressive Gaussian Splitting
Pith reviewed 2026-06-29 22:59 UTC · model grok-4.3
The pith
An autoregressive network splits Gaussians progressively to add fine expression detail to one-shot head avatars.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
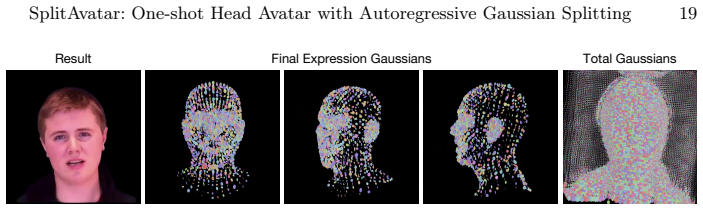
The autoregressive structure effectively improves expression representation ability by progressively splitting Gaussians. This process, enabled by the GNN-guided splitting, synthesizes more precise facial details and achieves higher reconstruction quality.
What carries the argument
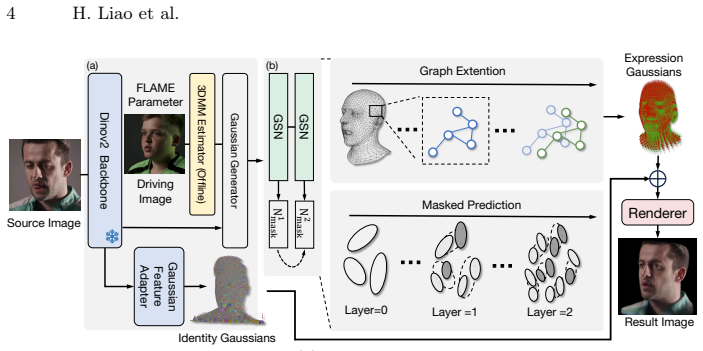
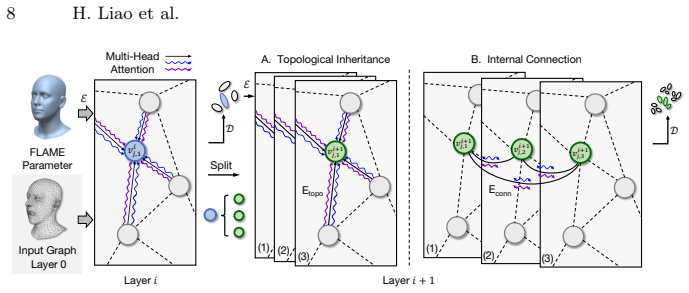
Graph splitting network that performs GNN-guided autoregressive splitting of Gaussians, paired with mesh topology extension to maintain connectivity after each split.
If this is right
- Progressive splitting captures finer facial details that fixed-count methods miss.
- Gated density control limits over-densification while preserving real-time rendering speed.
- Delayed filtering avoids repeated topology recomputation and stabilizes training.
- The resulting avatars remain animatable from a single input image.
Where Pith is reading between the lines
- The same coarse-to-fine splitting logic could be tested on full-body or dynamic scene reconstruction to check whether the GNN guidance transfers.
- Running the method on inputs with large expression changes would test whether the autoregressive steps remain stable outside the training distribution.
- If splitting improves detail without extra parameters, similar refinement stages might be added to other point-based rendering pipelines.
Load-bearing premise
The mesh topology extension successfully aligns the GNN connectivity with the new Gaussian count after each split without introducing inconsistencies or artifacts.
What would settle it
Train the model and then render a sequence of test expressions; if the split version shows no measurable gain in fine facial detail or visible artifacts appear relative to a non-split baseline, the improvement claim is falsified.
Figures



read the original abstract
3D Gaussian Splatting (3DGS) provides an efficient method for high-quality scene reconstruction using anisotropic Gaussians. Recently, 3DGS-based methods have significantly improved the rendering quality of human avatars while enabling real-time performance. However, existing methods suffer from a magnitude mismatch in the number of Gaussians generated by image-based and 3DMM-based approaches. This discrepancy results in reconstructed expressions that lack fine-grained detail. In this paper, we introduce a novel method for reconstructing an animatable head avatar from a single image. We propose a Graph splitting network to progressively generate Gaussians from coarse to fine using an autoregressive architecture. To address the graph inconsistency caused by split Gaussians, we employ a mesh topology extension method to align the GNN's connectivity with the increased Gaussian count. Furthermore, we introduce a novel density control method that includes a gating mechanism that generates soft masks for Gaussians, preventing over-densification after the splitting operation. This allows for dynamic control over Gaussian density across different facial regions. For smooth and rapid training, we employ a delayed filtering strategy to avoid re-computing the graph topology during training. Experimental results demonstrate that our autoregressive structure effectively improves expression representation ability by progressively splitting Gaussians. This process, enabled by the GNN-guided splitting, synthesizes more precise facial details and achieves higher reconstruction quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SplitAvatar, a one-shot method for reconstructing animatable head avatars from a single image via 3D Gaussian Splatting. It introduces a Graph splitting network with an autoregressive architecture that progressively generates Gaussians from coarse to fine, a mesh topology extension to maintain GNN connectivity after splits, a gating mechanism within density control to produce soft masks and avoid over-densification, and a delayed filtering strategy to enable efficient training without repeated topology recomputation. The central claim is that this autoregressive GNN-guided splitting improves expression representation by synthesizing finer facial details and yields higher reconstruction quality than prior 3DGS-based avatar methods.
Significance. If the results hold, the work could advance one-shot avatar reconstruction by providing a mechanism to dynamically increase Gaussian density in expression-critical regions through progressive splitting, addressing the noted mismatch between image-based and 3DMM-based Gaussian counts. The integration of autoregressive refinement with GNN guidance and gated density control represents a potentially useful architectural direction for controllable facial detail.
major comments (2)
- Abstract: The claim that 'our autoregressive structure effectively improves expression representation ability by progressively splitting Gaussians' and that 'GNN-guided splitting synthesizes more precise facial details' is unsupported by any quantitative results, ablation studies, or implementation details. Without these, it is impossible to verify whether the progressive splitting delivers measurable gains in expression fidelity or reconstruction quality.
- Abstract: The manuscript provides no description of the mesh topology extension algorithm, no proof or analysis that it preserves GNN connectivity without inconsistencies or artifacts after each split, and no ablation isolating its effect. This is load-bearing for the central claim, as unreliable GNN messages would undermine the autoregressive refinement process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the presentation of results and algorithmic details.
read point-by-point responses
-
Referee: [—] Abstract: The claim that 'our autoregressive structure effectively improves expression representation ability by progressively splitting Gaussians' and that 'GNN-guided splitting synthesizes more precise facial details' is unsupported by any quantitative results, ablation studies, or implementation details. Without these, it is impossible to verify whether the progressive splitting delivers measurable gains in expression fidelity or reconstruction quality.
Authors: The abstract summarizes findings whose supporting evidence appears in the experimental section, which reports quantitative comparisons against prior 3DGS avatar methods and ablation studies on the autoregressive splitting component. To make this link explicit and address the concern directly, we will revise the abstract to reference the relevant quantitative metrics and ablation results, and we will expand the implementation details subsection for clarity. revision: yes
-
Referee: [—] Abstract: The manuscript provides no description of the mesh topology extension algorithm, no proof or analysis that it preserves GNN connectivity without inconsistencies or artifacts after each split, and no ablation isolating its effect. This is load-bearing for the central claim, as unreliable GNN messages would undermine the autoregressive refinement process.
Authors: We agree that the mesh topology extension requires explicit documentation. In the revised manuscript we will add a dedicated subsection with the full algorithm description (including pseudocode), a connectivity-preservation argument, and an ablation study that isolates its contribution to reconstruction quality. This will directly support the central claim. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces a novel autoregressive Graph splitting network, mesh topology extension, gating-based density control, and delayed filtering on top of 3DGS. The central claim that progressive splitting improves expression detail is presented as an empirical outcome of these new architectural choices rather than a reduction to fitted parameters, self-citations, or renamed inputs. No equations or steps in the abstract or described method reduce by construction to prior results from the same authors; the topology extension and GNN guidance are described as independent engineering solutions without load-bearing self-referential justification.
Axiom & Free-Parameter Ledger
free parameters (1)
- splitting and gating thresholds
axioms (1)
- domain assumption 3D Gaussian Splatting provides an efficient base for high-quality scene and avatar reconstruction
Reference graph
Works this paper leans on
-
[1]
Cgs-gan: 3d consistent gaus- sian splatting gans for high resolution human head synthesis
Barthel, F., Morgenstern, W., Hinzer, P., Hilsmann, A., Eisert, P.: Cgs-gan: 3d consistent gaussian splatting gans for high resolution human head synthesis. arXiv preprint arXiv:2505.17590 (2025)
-
[2]
In: ICCV (2017)
Bulat, A., Tzimiropoulos, G.: How far are we from solving the 2d & 3d face align- ment problem?(and a dataset of 230,000 3d facial landmarks). In: ICCV (2017)
2017
-
[3]
Muse: Text-to-image generation via masked generative transformers
Chang, H., Zhang, H., Barber, J., Maschinot, A., Lezama, J., Jiang, L., Yang, M.H., Murphy, K., Freeman, W.T., Rubinstein, M., et al.: Muse: Text-to-image generation via masked generative transformers. arXiv preprint arXiv:2301.00704 (2023)
-
[4]
In: CVPR (2022)
Chang, H., Zhang, H., Jiang, L., Liu, C., Freeman, W.T.: Maskgit: Masked gener- ative image transformer. In: CVPR (2022)
2022
-
[5]
In: ICLR (2020)
Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Luan, D., Sutskever, I.: Gener- ative pretraining from pixels. In: ICLR (2020)
2020
-
[6]
NeurIPS (2024)
Chu, X., Harada, T.: Generalizable and animatable gaussian head avatar. NeurIPS (2024)
2024
-
[7]
In: ICLR (2024)
Chu, X., Li, Y., Zeng, A., Yang, T., Lin, L., Liu, Y., Harada, T.: Gpavatar: Gen- eralizable and precise head avatar from image (s). In: ICLR (2024)
2024
-
[8]
NeurIPS (2015)
Courbariaux, M., Bengio, Y., David, J.P.: Binaryconnect: Training deep neural networks with binary weights during propagations. NeurIPS (2015)
2015
-
[9]
Vision Transformers Need Registers
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need reg- isters. arXiv preprint arXiv:2309.16588 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
In: CVPR (2019)
Deng, J., Guo, J., Xue, N., Zafeiriou, S.: Arcface: Additive angular margin loss for deep face recognition. In: CVPR (2019)
2019
-
[11]
In: CVPR (2024)
Deng, Y., Wang, D., Ren, X., Chen, X., Wang, B.: Portrait4d: Learning one-shot 4d head avatar synthesis using synthetic data. In: CVPR (2024)
2024
-
[12]
In: ECCV (2024)
Deng, Y., Wang, D., Wang, B.: Portrait4d-v2: Pseudo multi-view data creates better 4d head synthesizer. In: ECCV (2024)
2024
-
[13]
In: CVPR Workshops (2019)
Deng, Y., Yang, J., Xu, S., Chen, D., Jia, Y., Tong, X.: Accurate 3d face reconstruc- tion with weakly-supervised learning: From single image to image set. In: CVPR Workshops (2019)
2019
-
[14]
In: CVPR (2021)
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: CVPR (2021)
2021
-
[15]
In: SIGGRAPH (2025)
He, Y., Gu, X., Ye, X., Xu, C., Zhao, Z., Dong, Y., Yuan, W., Dong, Z., Bo, L.: Lam: large avatar model for one-shot animatable gaussian head. In: SIGGRAPH (2025)
2025
-
[16]
In: CVPR (2024)
Hu, L., Zhang, H., Zhang, Y., Zhou, B., Liu, B., Zhang, S., Nie, L.: Gaussianavatar: Towards realistic human avatar modeling from a single video via animatable 3d gaussians. In: CVPR (2024)
2024
-
[17]
NeurIPS (2024)
Hyun, S., Heo, J.P.: Gsgan: Adversarial learning for hierarchical generation of 3d gaussian splats. NeurIPS (2024)
2024
-
[18]
In: ECCV (2016)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: ECCV (2016)
2016
-
[19]
TOG42(4), 139–1 (2023) 16 H
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. TOG42(4), 139–1 (2023) 16 H. Liao et al
2023
-
[20]
In: ECCV (2022)
Khakhulin, T., Sklyarova, V., Lempitsky, V., Zakharov, E.: Realistic one-shot mesh-based head avatars. In: ECCV (2022)
2022
-
[21]
Adam: A Method for Stochastic Optimization
Kingma, D.P.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[22]
In: CVPR (2025)
Kumbong, H., Liu, X., Lin, T.Y., Liu, M.Y., Liu, X., Liu, Z., Fu, D.Y., Re, C., Romero, D.W.: Hmar: Efficient hierarchical masked auto-regressive image genera- tion. In: CVPR (2025)
2025
-
[23]
In: ECCV (2024)
Li, J., Zhang, J., Bai, X., Zheng, J., Ning, X., Zhou, J., Gu, L.: Talkinggaussian: Structure-persistent 3d talking head synthesis via gaussian splatting. In: ECCV (2024)
2024
-
[24]
In: CVPR (2023)
Li, T., Chang, H., Mishra, S., Zhang, H., Katabi, D., Krishnan, D.: Mage: Masked generative encoder to unify representation learning and image synthesis. In: CVPR (2023)
2023
-
[25]
TOG36(6), 194–1 (2017)
Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4d scans. TOG36(6), 194–1 (2017)
2017
-
[26]
NeurIPS (2023)
Li, X., De Mello, S., Liu, S., Nagano, K., Iqbal, U., Kautz, J.: Generalizable one- shot 3d neural head avatar. NeurIPS (2023)
2023
-
[27]
In: WACV (2024)
Ma, H., Zhang, T., Sun, S., Yan, X., Han, K., Xie, X.: Cvthead: One-shot control- lable head avatar with vertex-feature transformer. In: WACV (2024)
2024
-
[28]
In: SIGGRAPH (2024)
Ma, S., Weng, Y., Shao, T., Zhou, K.: 3d gaussian blendshapes for head avatar animation. In: SIGGRAPH (2024)
2024
-
[29]
In: CVPR (2023)
Ma, Z., Zhu, X., Qi, G.J., Lei, Z., Zhang, L.: Otavatar: One-shot talking face avatar with controllable tri-plane rendering. In: CVPR (2023)
2023
-
[30]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
In: CVPR (2024)
Qian, Z., Wang, S., Mihajlovic, M., Geiger, A., Tang, S.: 3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting. In: CVPR (2024)
2024
-
[33]
NeurIPS (2019)
Razavi, A., Van den Oord, A., Vinyals, O.: Generating diverse high-fidelity images with vq-vae-2. NeurIPS (2019)
2019
-
[34]
In: ICCV (2021)
Ren, Y., Li, G., Chen, Y., Li, T.H., Liu, S.: Pirenderer: Controllable portrait image generation via semantic neural rendering. In: ICCV (2021)
2021
-
[35]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
NeurIPS (2024)
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scalable image generation via next-scale prediction. NeurIPS (2024)
2024
-
[37]
NeurIPS (2017)
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. NeurIPS (2017)
2017
-
[38]
In: ICLR (2018)
Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., Bengio, Y.: Graph attention networks. In: ICLR (2018)
2018
-
[39]
In: CVPR (2025)
Wang, C., Kang, D., Sun, H., Qian, S., Wang, Z., Bao, L., Zhang, S.H.: Mega: Hybrid mesh-gaussian head avatar for high-fidelity rendering and head editing. In: CVPR (2025)
2025
-
[40]
TIP13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. TIP13(4), 600–612 (2004)
2004
-
[41]
In: AAAI (2025) SplitAvatar: One-shot Head Avatar with Autoregressive Gaussian Splitting 17
Wei, X., Chen, P., Lu, M., Chen, H., Tian, F.: Graphavatar: Compact head avatars with gnn-generated 3d gaussians. In: AAAI (2025) SplitAvatar: One-shot Head Avatar with Autoregressive Gaussian Splitting 17
2025
-
[42]
In: CVPR (2022)
Xie, L., Wang, X., Zhang, H., Dong, C., Shan, Y.: Vfhq: A high-quality dataset and benchmark for video face super-resolution. In: CVPR (2022)
2022
-
[43]
In: CVPR (2020)
Xu, S., Yang, J., Chen, D., Wen, F., Deng, Y., Jia, Y., Tong, X.: Deep 3d portrait from a single image. In: CVPR (2020)
2020
-
[44]
In: CVPR (2024)
Xu, Y., Chen, B., Li, Z., Zhang, H., Wang, L., Zheng, Z., Liu, Y.: Gaussian head avatar: Ultra high-fidelity head avatar via dynamic gaussians. In: CVPR (2024)
2024
-
[45]
arXiv preprint arXiv:2401.08503 (2024)
Ye, Z., Zhong, T., Ren, Y., Yang, J., Li, W., Huang, J., Jiang, Z., He, J., Huang, R., Liu, J., et al.: Real3d-portrait: One-shot realistic 3d talking portrait synthesis. arXiv preprint arXiv:2401.08503 (2024)
-
[46]
In: ECCV (2022)
Yin, F., Zhang, Y., Cun, X., Cao, M., Fan, Y., Wang, X., Bai, Q., Wu, B., Wang, J., Yang, Y.: Styleheat: One-shot high-resolution editable talking face generation via pre-trained stylegan. In: ECCV (2022)
2022
-
[48]
In: CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
2018
-
[49]
NeurIPS (2024)
Zhang, S., Fei, X., Liu, F., Song, H., Duan, Y.: Gaussian graph network: Learn- ing efficient and generalizable gaussian representations from multi-view images. NeurIPS (2024)
2024
-
[50]
Zhang, Z., Li, L., Ding, Y., Fan, C.: Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In: CVPR (2021) 18 H. Liao et al. A More Details on Experiments A.1 Implementation The Gaussian feature adapter comprises two trainable Vision Transformers [31], both configured with depth= 12and heads= 8. We extract features fro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.