Towards Anatomically Plausible Human Image Generation via Synthetic Localized Preferences
Pith reviewed 2026-06-29 22:52 UTC · model grok-4.3
The pith
A localized degradation method creates synthetic preference pairs that align text-to-image models for better human anatomy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
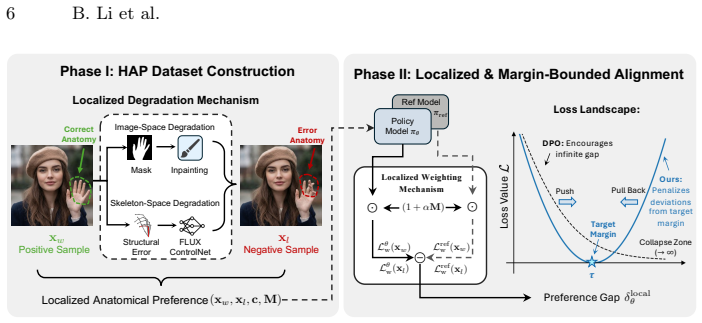
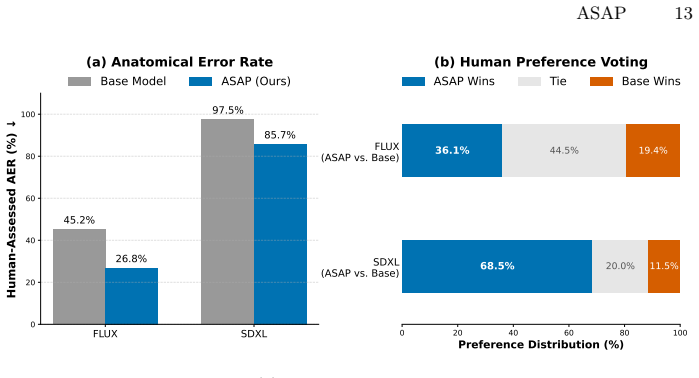
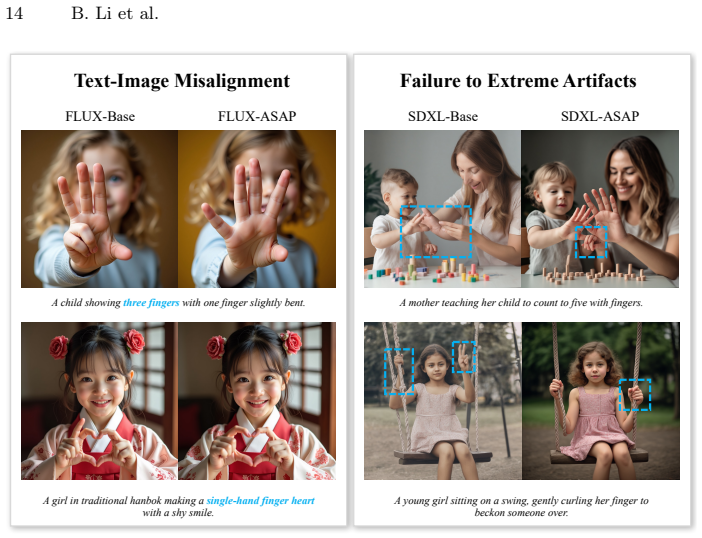
The framework of Alignment via Synthetic Anatomical Preference constructs controlled preference pairs through a localized degradation mechanism that introduces explicit anatomical errors in targeted regions of high-fidelity human images. These pairs enable a localized and margin-bounded variant of DPO to prioritize optimization in anatomical regions, resulting in reduced anatomical errors across foundation models as evaluated on the HAF-Bench using the HAP dataset.
What carries the argument
The localized degradation mechanism that performs a controlled experiment by introducing explicit anatomical errors in targeted regions while preserving the remaining content.
If this is right
- ASAP reduces anatomical errors consistently across multiple foundation models.
- The method maintains overall image quality during alignment.
- The HAP dataset of over 10K pairs enables effective anatomical alignment.
- The HAF-Bench provides a systematic way to evaluate anatomical fidelity.
Where Pith is reading between the lines
- This approach could be adapted to address other localized generation artifacts such as inconsistent lighting or object interactions.
- Applying the synthetic preference construction to real user feedback data might further improve transfer to practical use cases.
- Extending the margin-bounded optimization to other preference alignment domains could help avoid over-optimization in general.
Load-bearing premise
The anatomical errors created synthetically through localized degradation match the distribution of errors that naturally occur in text-to-image model outputs.
What would settle it
Running the ASAP alignment on a foundation model and measuring no decrease in anatomical error rates on the HAF-Bench compared to a baseline using standard DPO would falsify the effectiveness claim.
Figures





read the original abstract
Large-scale text-to-image foundation models have achieved remarkable visual realism, yet generating human images with correct anatomical structures remains challenging. Existing approaches enforce anatomical constraints through part-specific modules or localized loss weighting during supervised fine-tuning on high-quality human photos, but such datasets are limited and often provide ambiguous optimization signals due to confounding factors such as lighting, pose, and background. Preference-based alignment offers an alternative, but standard Direct Preference Optimization (DPO) treats all pixels equally and therefore fails to exploit the localized nature of anatomical artifacts. To address this, we propose the framework of Alignment via Synthetic Anatomical Preference (ASAP), which constructs controlled preference pairs through a localized degradation mechanism applied to high-fidelity human images. This mechanism performs a controlled experiment on images by introducing explicit anatomical errors in targeted regions while preserving the remaining content. With this mechanism, we create the Human Anatomical Preference (HAP) dataset with over 10K curated pairs for effective anatomical alignment of text-to-image human image generative models. To better leverage the locality of these controlled preference pairs, we introduce a localized and margin-bounded variant of DPO that prioritizes optimization in targeted anatomical regions while enforcing a finite preference margin to prevent over-optimization and preserve global semantics. We further introduce HAF-Bench, a benchmark for systematic evaluation of anatomical fidelity. Extensive experiments demonstrate that ASAP consistently reduces anatomical errors across multiple foundation models while maintaining overall image quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the ASAP framework to improve anatomical fidelity in text-to-image human generation. It builds the HAP dataset (>10K pairs) by applying a localized degradation mechanism to high-fidelity images that introduces explicit anatomical errors in targeted regions while preserving other content. A localized margin-bounded variant of DPO is introduced to focus optimization on those regions and avoid over-optimization. HAF-Bench is presented for systematic evaluation. The central claim is that ASAP reduces anatomical errors across foundation models while maintaining overall image quality.
Significance. If the synthetic preference pairs accurately capture the error distributions that arise naturally during T2I sampling, the approach offers a scalable route to anatomical alignment that sidesteps the scarcity and confounding factors of high-quality human photo datasets. The localized DPO formulation and the introduction of HAF-Bench are potentially reusable contributions for other localized artifact problems in generative models.
major comments (2)
- [Abstract] Abstract: the statement that the degradation mechanism 'performs a controlled experiment on images by introducing explicit anatomical errors in targeted regions' is used to ground the HAP dataset and the subsequent localized DPO, yet no argument or experiment is supplied showing that the introduced errors (isolated part distortions) match the frequency, co-occurrence, or causal structure of emergent T2I failures such as global limb-count inconsistencies or joint misalignments. This matching is load-bearing for the claim that the derived optimization signal addresses actual inference-time artifacts.
- [Abstract] Abstract (experiments paragraph): the claim of 'consistent error reduction' and 'extensive experiments' is asserted without any quantitative metrics, ablation tables, description of the degradation implementation, or definition of how HAF-Bench scores are computed, preventing verification of the central empirical claim.
minor comments (1)
- The abstract refers to 'over 10K curated pairs' and 'multiple foundation models' but supplies no breakdown by model, degradation severity, or region; these details belong in the experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the major comments point by point below. Both points identify areas where the abstract can be strengthened for clarity and verifiability, and we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that the degradation mechanism 'performs a controlled experiment on images by introducing explicit anatomical errors in targeted regions' is used to ground the HAP dataset and the subsequent localized DPO, yet no argument or experiment is supplied showing that the introduced errors (isolated part distortions) match the frequency, co-occurrence, or causal structure of emergent T2I failures such as global limb-count inconsistencies or joint misalignments. This matching is load-bearing for the claim that the derived optimization signal addresses actual inference-time artifacts.
Authors: We agree that an explicit argument or comparison would strengthen the grounding of the HAP dataset. The degradation mechanism is intentionally designed to introduce isolated, explicit anatomical errors in targeted regions to generate clean, localized preference signals that avoid the confounding factors (lighting, pose, background) present in real human preference data. The operations target known anatomical failure modes commonly reported in T2I literature (e.g., limb distortions, joint misalignments). The full manuscript describes these operations and shows downstream error reduction on HAF-Bench. However, we did not include a direct distributional comparison between synthetic and naturally occurring errors. We will add a dedicated paragraph in the method or discussion section providing justification based on observed T2I failure modes and include qualitative side-by-side examples of synthetic versus real artifacts to address this concern. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): the claim of 'consistent error reduction' and 'extensive experiments' is asserted without any quantitative metrics, ablation tables, description of the degradation implementation, or definition of how HAF-Bench scores are computed, preventing verification of the central empirical claim.
Authors: The abstract is a high-level summary and therefore omits implementation details and full metrics, which appear in the main body (degradation implementation in Section 3, HAF-Bench definition and scoring in Section 4, quantitative results and ablations in Section 5 and the appendix). To make the central empirical claims more verifiable from the abstract itself, we will revise the experiments paragraph to include key quantitative results (e.g., error reduction percentages on HAF-Bench across models) while remaining within length constraints. revision: yes
Circularity Check
No circularity: method is data construction plus optimization with external grounding
full rationale
The paper describes a procedural pipeline: synthetic localized degradation to build the HAP preference dataset from high-fidelity images, followed by a localized margin-bounded DPO variant and evaluation on the introduced HAF-Bench. These elements are presented as explicit construction steps and an empirical optimization procedure whose inputs are external images and the standard DPO objective; no derivation, prediction, or uniqueness claim reduces by the paper's own equations or self-citations to a quantity defined in terms of the target result. The central claims rest on the empirical outcomes of this pipeline rather than tautological equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-fidelity human images exist that can serve as clean starting points for controlled degradation.
invented entities (3)
-
ASAP framework
no independent evidence
-
HAP dataset
no independent evidence
-
HAF-Bench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In:InternationalConferenceonArtificialIntelligenceandStatistics.pp.4447–4455
Azar, M.G., Guo, Z.D., Piot, B., Munos, R., Rowland, M., Valko, M., Calandriello, D.: A general theoretical paradigm to understand learning from human preferences. In:InternationalConferenceonArtificialIntelligenceandStatistics.pp.4447–4455. PMLR (2024) 8
2024
-
[2]
the method of paired comparisons
Bradley, R.A., Terry, M.E.: Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika39(3/4), 324–345 (1952) 6
1952
-
[3]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025) 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: Forty-first international conference on machine learning (2024) 1, 3
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) 1, 3
2024
-
[5]
In: European Conference on Computer Vision
Fang, G., Yan, W., Guo, Y., Han, J., Jiang, Z., Xu, H., Liao, S., Liang, X.: Human- refiner: Benchmarking abnormal human generation and refining with coarse-to-fine pose-reversible guidance. In: European Conference on Computer Vision. pp. 201–
-
[6]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., et al.: The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027 (2020) 4
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Advances in neural information processing systems33, 6840–6851 (2020) 3
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 3
2020
-
[8]
ICLR1(2), 3 (2022) 10
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR1(2), 3 (2022) 10
2022
-
[9]
arXiv preprint arXiv:2505.22002 (2025) 5
Hu, Z., Zhang, F., Kuang, K.: D-fusion: Direct preference optimization for aligning diffusion models with visually consistent samples. arXiv preprint arXiv:2505.22002 (2025) 5
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Huang, Q., Chan, L., Liu, J., He, W., Jiang, H., Song, M., Song, J.: Patchdpo: Patch-level dpo for finetuning-free personalized image generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18369–18378 (2025) 4
2025
-
[11]
ACM Computing Surveys56(11), 1–39 (2024) 2, 3 16 B
Jia, Z., Zhang, Z., Wang, L., Tan, T.: Human image generation: A comprehensive survey. ACM Computing Surveys56(11), 1–39 (2024) 2, 3 16 B. Li et al
2024
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Ju, X., Zeng, A., Zhao, C., Wang, J., Zhang, L., Xu, Q.: Humansd: A native skeleton-guided diffusion model for human image generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15988–15998 (2023) 2
2023
-
[13]
Advances in neural information processing systems36, 36652–36663 (2023) 4, 10
Kirstain,Y.,Polyak,A.,Singer,U.,Matiana,S.,Penna,J.,Levy,O.:Pick-a-pic:An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems36, 36652–36663 (2023) 4, 10
2023
-
[14]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024) 1, 3, 5, 9
2024
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, S., Fu, J., Liu, K., Wang, W., Lin, K.Y., Wu, W.: Cosmicman: A text-to-image foundation model for humans. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6955–6965 (2024) 2, 4
2024
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liang, Y., He, J., Li, G., Li, P., Klimovskiy, A., Carolan, N., Sun, J., Pont-Tuset, J., Young, S., Yang, F., et al.: Rich human feedback for text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19401–19411 (2024) 4
2024
-
[17]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
arXiv preprint arXiv:2310.08579 (2023) 2
Liu, X., Ren, J., Siarohin, A., Skorokhodov, I., Li, Y., Lin, D., Liu, X., Liu, Z., Tulyakov, S.: Hyperhuman: Hyper-realistic human generation with latent struc- tural diffusion. arXiv preprint arXiv:2310.08579 (2023) 2
-
[19]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022) 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
In: The Fourteenth International Conference on Learning Representations 8
Liu, X., Li, M., Lyu, Z., Shang, Y., Chen, C.: Learning from noisy preferences: A semi-supervised learning approach to direct preference optimization. In: The Fourteenth International Conference on Learning Representations 8
-
[21]
arXiv preprint arXiv:2508.03789 (2025) 4, 5, 10
Ma, Y., Shui, Y., Wu, X., Sun, K., Li, H.: Hpsv3: Towards wide-spectrum human preference score. arXiv preprint arXiv:2508.03789 (2025) 4, 5, 10
-
[22]
IEEE Robotics & automation magazine19(2), 98–100 (2012) 4
Mori, M., MacDorman, K.F., Kageki, N.: The uncanny valley [from the field]. IEEE Robotics & automation magazine19(2), 98–100 (2012) 4
2012
-
[23]
In: Proceedings of the Computer Vision and Pattern Recog- nition Conference
Na, S., Kim, Y., Lee, H.: Boost your human image generation model via direct pref- erence optimization. In: Proceedings of the Computer Vision and Pattern Recog- nition Conference. pp. 23551–23562 (2025) 2
2025
-
[24]
Advances in neural information processing sys- tems35, 27730–27744 (2022) 4
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing sys- tems35, 27730–27744 (2022) 4
2022
-
[25]
Penedo, G., Malartic, Q., Hesslow, D., Cojocaru, R., Cappelli, A., Alobeidli, H., Pannier, B., Almazrouei, E., Launay, J.: The refinedweb dataset for falcon llm: outperforming curated corpora with web data, and web data only. arXiv preprint arXiv:2306.01116 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023) 1, 3, 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Advances in neural information processing systems36, 53728–53741 (2023) 2, 4, 5, 6
Rafailov, R., Sharma, A., Mitchell, E., Manning, C.D., Ermon, S., Finn, C.: Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems36, 53728–53741 (2023) 2, 4, 5, 6
2023
-
[28]
Journal of machine learning research21(140), 1–67 (2020) 4 ASAP 17
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research21(140), 1–67 (2020) 4 ASAP 17
2020
-
[29]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159 (2024) 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 3, 5
2022
-
[31]
Advances in neural information processing systems35, 25278–25294 (2022) 4, 10
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022) 4, 10
2022
-
[32]
1-dev-ControlNet-Union-Pro-2.0(2025) 6, 7
Shakker-Labs: Controlnet-union.https://huggingface.co/Shakker-Labs/FLUX. 1-dev-ControlNet-Union-Pro-2.0(2025) 6, 7
2025
-
[33]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020) 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[34]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020) 3
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S., Naik, N.: Diffusion model alignment using direct preference optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8228–8238 (2024) 2, 4, 5, 6
2024
-
[36]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, B., Zhou, J., Bai, J., Yang, Y., Chen, W., Wang, F., Lei, Z.: Realishuman: A two-stage approach for refining malformed human parts in generated images. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 7509–7517 (2025) 4
2025
-
[37]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Wang, J., Sun, Z., Tan, Z., Chen, X., Chen, W., Li, H., Zhang, C., Song, Y.: To- wards effective usage of human-centric priors in diffusion models for text-based human image generation. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 8446–8455 (2024) 2, 4, 8
2024
-
[38]
arXiv preprint arXiv:2502.06812 (2025) 4
Wang, S., Tang, H., Dou, Z., Xiong, C.: Harness local rewards for global benefits: Effective text-to-video generation alignment with patch-level reward models. arXiv preprint arXiv:2502.06812 (2025) 4
-
[39]
arXiv preprint arXiv:2507.02714 (2025) 2, 4
Wang, Y., Cao, T., Zhang, H., He, Z., Liang, K., Ma, Z.: Fairhuman: Boosting hand and face quality in human image generation with minimum potential delay fairness in diffusion models. arXiv preprint arXiv:2507.02714 (2025) 2, 4
-
[40]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025) 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wu, X., Sun, K., Zhu, F., Zhao, R., Li, H.: Human preference score: Better aligning text-to-image models with human preference. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2096–2105 (2023) 4, 10
2096
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xing, X., Saha, A., He, J., Hao, S., Vicol, P., Ryu, M., Li, G., Singla, S., Young, S., Li, Y., et al.: Focus-n-fix: Region-aware fine-tuning for text-to-image generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18486–18496 (2025) 4 18 B. Li et al
2025
-
[44]
Advances in Neural Information Processing Systems36, 15903–15935 (2023) 4, 5, 10
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems36, 15903–15935 (2023) 4, 5, 10
2023
-
[45]
In: The Fourteenth International Conference on Learning Representations 8
Yang, X., Yang, M., JIA, G., Qin, L., Tan, Z., Li, H.: Dual-ipo: Dual-iterative pref- erence optimization for text-to-video generation. In: The Fourteenth International Conference on Learning Representations 8
-
[46]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yang, Z., Zeng, A., Yuan, C., Li, Y.: Effective whole-body pose estimation with two-stages distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4210–4220 (2023) 6
2023
-
[47]
In: Proceedings of the IEEE international conference on computer vi- sion
Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., Metaxas, D.N.: Stack- gan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In: Proceedings of the IEEE international conference on computer vi- sion. pp. 5907–5915 (2017) 4
2017
-
[48]
Advances in Neural Information Processing Systems37, 29354–29386 (2024) 2, 4
Zhu, J., Chen, Y., Ding, M., Luo, P., Wang, L., Wang, J.: Mole: Enhancing human- centric text-to-image diffusion via mixture of low-rank experts. Advances in Neural Information Processing Systems37, 29354–29386 (2024) 2, 4
2024
-
[49]
arXiv preprint arXiv:2512.10264 (2025) 4, 5, 6
Ziv, A., Chen, S., Tjandra, A., Adi, Y., Hsu, W.N., Shi, B.: Mr-flowdpo: Multi- reward direct preference optimization for flow-matching text-to-music generation. arXiv preprint arXiv:2512.10264 (2025) 4, 5, 6
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.