On Reliability of Efficient Membership Inference Vulnerability Evaluation
Pith reviewed 2026-06-29 23:10 UTC · model grok-4.3
The pith
Concatenating membership inference scores across samples fails to produce calibrated per-sample false positive rates at low thresholds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
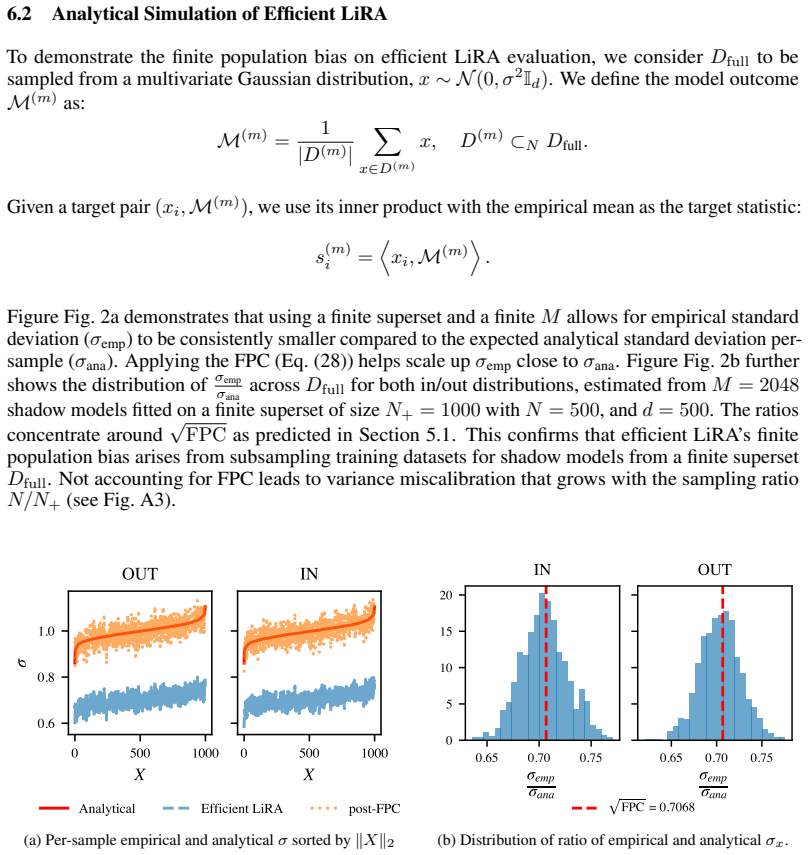
Evaluating the TPR based on MIA scores concatenated across multiple individuals is not calibrated across the per-sample FPRs. This makes the approach unreliable as a tool for auditing differential privacy. In addition, the commonly used efficient LiRA implementation carries a finite-population bias that produces a positive bias in per-sample vulnerability estimates. A post-processing calibration procedure restores consistent per-sample FPRs when scores from different individuals are combined.
What carries the argument
A post-processing calibration procedure that adjusts pooled MIA scores so that a single decision threshold yields the intended false-positive rate for each individual sample.
If this is right
- Differential privacy audits that rely on uncalibrated concatenated scores can misrepresent the actual leakage at low false-positive rates.
- The finite-population bias in efficient LiRA means that previously reported per-sample vulnerabilities are systematically inflated.
- Applying the proposed post-processing step produces TPR estimates that correctly reflect per-sample behavior even when scores are pooled for efficiency.
- Any vulnerability comparison across models or training methods must either use per-sample calibration or account for the bias introduced by pooling.
Where Pith is reading between the lines
- Prior published privacy evaluations that used the uncalibrated concatenation method may need re-examination with the corrected procedure.
- The calibration step could be added to existing membership-inference toolkits without changing the underlying attack models.
- Similar finite-population corrections might apply to other efficient attack implementations that reuse the same reference models across many targets.
Load-bearing premise
Per-sample false positive rates remain correctly calibrated when attack scores from different individuals and models are pooled or concatenated.
What would settle it
Compute the empirical FPR for each sample separately on a large collection of target models, then compare that value to the FPR obtained from the single concatenated score distribution at the same nominal threshold; a systematic mismatch would confirm the calibration failure.
Figures

read the original abstract
Membership inference attacks (MIAs) are popular methods for empirically assessing the leakage of sensitive information in the training data through models or statistics learned from the data. The MIA vulnerability is often evaluated through false positive rate (FPR) and true positive rate (TPR) of a binary classifier that tries to predict whether a particular sample was in the training data. However, in order to reliably estimate the TPR especially for low FPR values, a lot of observations are needed, which in case of MIA translates to many target models, leading to large computational cost. To avoid excessive compute requirements, the MIA scores are often averaged over multiple individuals and multiple targeted models. We demonstrate two key weaknesses in this efficient MIA evaluation pipeline. First, we show that evaluating the TPR based on MIA scores concatenated across multiple individuals, commonly used to study vulnerabilities in the very low FPR regime, is not calibrated across the per-sample FPRs. This makes it unreliable as a tool for auditing differential privacy. To solve this, we propose a post-processing method to effectively calibrate the FPR across different samples. Second, we identify a finite population bias in the commonly used efficient likelihood-ratio attack (LiRA) implementation proposed by Carlini et al. 2022, leading to a positive bias in the per-sample vulnerability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that concatenating MIA scores across multiple individuals to estimate TPR at low FPR is not calibrated across per-sample FPRs, rendering it unreliable for auditing differential privacy, and proposes a post-processing calibration method to address this. It also identifies a finite population bias in the efficient LiRA implementation that produces a positive bias in per-sample vulnerability estimates.
Significance. If the central claims hold, the work would strengthen empirical privacy evaluation practices by correcting miscalibration in pooled MIA evaluations used for low-FPR analysis and by flagging a bias in a widely adopted LiRA variant. The proposed calibration method represents a constructive, fixable contribution that could be adopted for more reliable DP auditing.
major comments (2)
- [Section describing the concatenation weakness and calibration method] The claim that pooled TPR estimation via concatenation is uncalibrated across per-sample FPRs is load-bearing for the unreliability conclusion in DP auditing. The manuscript should include an explicit derivation or counter-example (e.g., in the section introducing the calibration method) showing how heterogeneous per-sample score distributions produce a pooled operating point at nominal low FPR that differs from the average per-sample TPR at that FPR.
- [Section on LiRA finite population bias] The finite-population bias in the efficient LiRA implementation is presented as leading to positive bias in per-sample vulnerability. To support this as a practical concern, the paper should quantify the bias magnitude as a function of the number of target models (or provide the exact implementation detail from Carlini et al. 2022 that induces it) in the relevant experimental or theoretical section.
minor comments (2)
- [Abstract] The abstract states the two weaknesses and the calibration proposal but supplies no equations, experimental details, or error analysis; a one-sentence summary of the calibration method's effect on low-FPR TPR would improve the abstract.
- Notation for MIA scores, per-sample FPR, and pooled ROC should be introduced consistently before the first use of the calibration procedure to avoid ambiguity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which will help strengthen the clarity and empirical grounding of our claims. We address each major point below and will incorporate the requested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Section describing the concatenation weakness and calibration method] The claim that pooled TPR estimation via concatenation is uncalibrated across per-sample FPRs is load-bearing for the unreliability conclusion in DP auditing. The manuscript should include an explicit derivation or counter-example (e.g., in the section introducing the calibration method) showing how heterogeneous per-sample score distributions produce a pooled operating point at nominal low FPR that differs from the average per-sample TPR at that FPR.
Authors: We agree that an explicit counter-example would make the uncalibration claim more transparent. In the revised manuscript we will add a short counter-example (with two heterogeneous score distributions) immediately before the calibration method, demonstrating that the pooled threshold at nominal FPR=10^{-3} yields a TPR that deviates from the average per-sample TPR at the same per-sample FPR. This will be placed in the section introducing the calibration procedure. revision: yes
-
Referee: [Section on LiRA finite population bias] The finite-population bias in the efficient LiRA implementation is presented as leading to positive bias in per-sample vulnerability. To support this as a practical concern, the paper should quantify the bias magnitude as a function of the number of target models (or provide the exact implementation detail from Carlini et al. 2022 that induces it) in the relevant experimental or theoretical section.
Authors: We will add both the requested quantification and the precise implementation detail. In the revised version we include (i) the exact line from the Carlini et al. 2022 code that produces the finite-population bias (the reuse of the same shadow-model logits without leave-one-out adjustment) and (ii) a new plot and accompanying analysis showing bias magnitude versus number of target models (for 10, 50, 100, and 500 models) on the same datasets used in the paper. This will appear in the LiRA-bias section. revision: yes
Circularity Check
No significant circularity
full rationale
The paper critiques existing MIA evaluation pipelines by identifying two statistical issues: (1) uncalibrated TPR at low FPR when scores are concatenated across samples due to heterogeneous per-sample distributions, and (2) finite-population bias in the LiRA estimator from Carlini et al. 2022. These follow from direct analysis of ROC operating points and bias in likelihood ratios, without any fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations. The proposed post-processing calibration is an explicit correction derived from the identified mismatch, not a renaming or ansatz smuggled via prior work. The derivation chain is self-contained against external benchmarks and does not reduce claims to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aerni, J
M. Aerni, J. Zhang, and F. Tramèr. Evaluations of Machine Learning Privacy Defenses are Misleading. InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security, (CCS), pages 1271–1284,
2024
-
[3]
Carlini, S
N. Carlini, S. Chien, M. Nasr, S. Song, A. Terzis, and F. Tramèr. Membership Inference Attacks From First Principles. In43rd IEEE Symposium on Security and Privacy, SP, pages 1897–1914,
1914
-
[4]
S. Garg, D. Tsipras, P. Liang, and G. Valiant. What Can Transformers Learn In-Context? A Case Study of Simple Function Classes. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS,
2022
-
[5]
DOI: https://doi.org/10.24432/C5NC77. N. Hollmann, S. Müller, L. Purucker, A. Krishnakumar, M. Körfer, S. B. Hoo, R. T. Schirrmeister, and F. Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637 (8044):319–326,
-
[6]
Keinan, M
A. Keinan, M. Shenfeld, and K. Ligett. How Well Can Differential Privacy Be Audited in One Run? InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2025, NeurIPS,
2025
-
[7]
Y . Liu, Z. Zhao, M. Backes, and Y . Zhang. Membership Inference Attacks by Exploiting Loss Trajec- tory. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, CCS, pages 2085–2098,
2022
- [8]
-
[9]
Srivastava, G
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting.Journal of Machine Learning Research, 15(56): 1929–1958,
1929
-
[10]
Steinke, M
T. Steinke, M. Nasr, and M. Jagielski. Privacy Auditing with One (1) Training Run. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS,
2023
-
[11]
Zarifzadeh, P
S. Zarifzadeh, P. Liu, and R. Shokri. Low-cost High-power Membership Inference Attacks. In Forty-first International Conference on Machine Learning, ICML 2024,
2024
-
[12]
A Appendix A.1 MIA Evaluation With Oracle Access In this setting, the attacker uses all 4095 models except the target model to compute per-sample statistics for Sout x and Sin x against M target models. It helps isolate the behavior of the MIA evaluation procedure from finite-M estimation error of the in- and out-distributions. In particular, it lets us s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.