Small Models, Strong Priors: Architectural Inductive Bias for Parameter-Efficient Neural PDE Solvers
Pith reviewed 2026-06-29 22:12 UTC · model grok-4.3
The pith
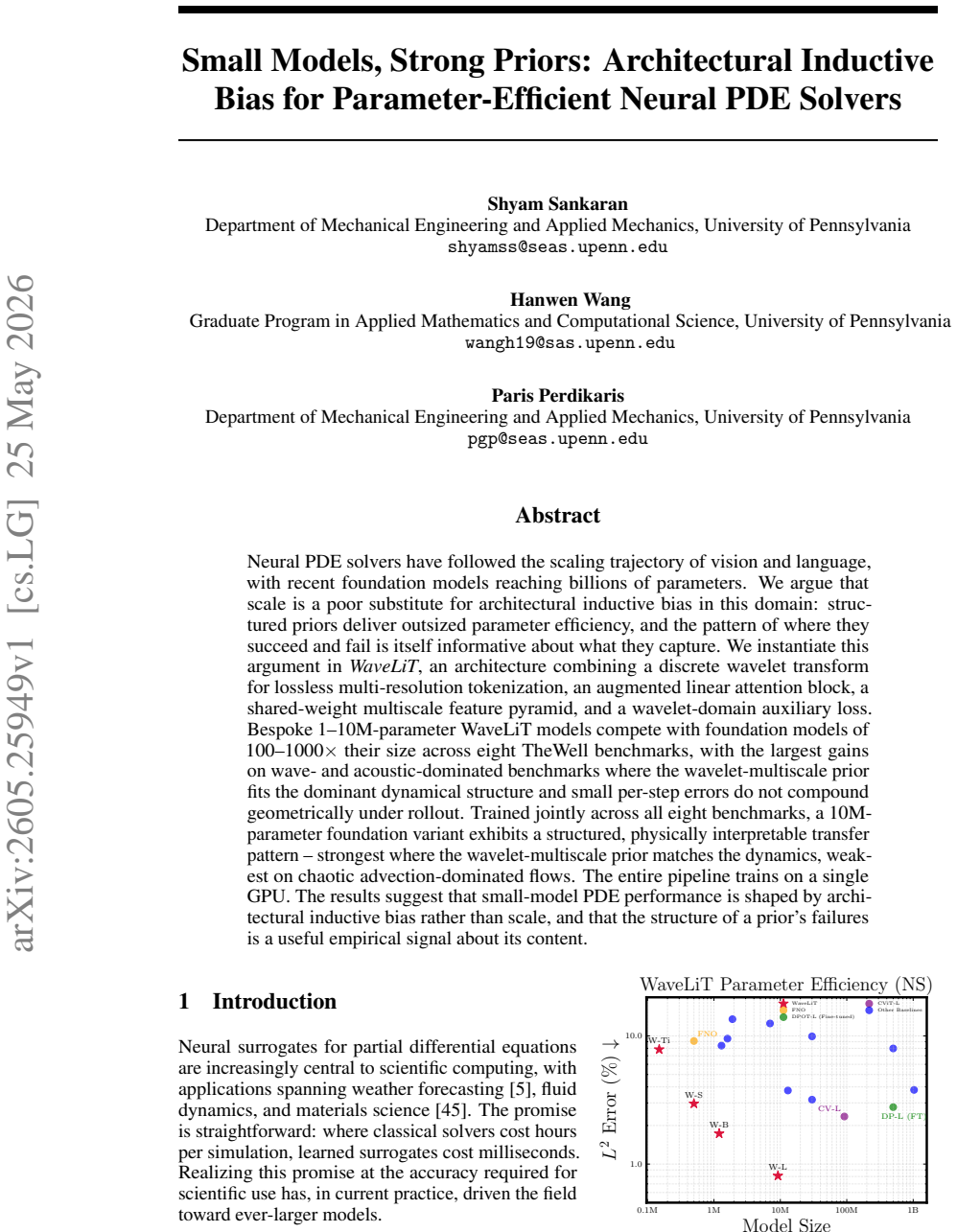
Wavelet-multiscale priors enable 1-10M parameter PDE solvers to match 100-1000x larger foundation models on wave and acoustic benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
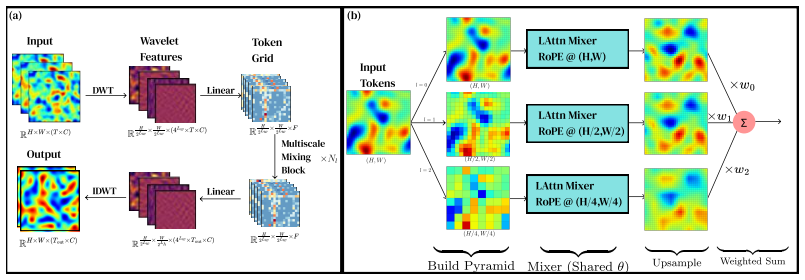
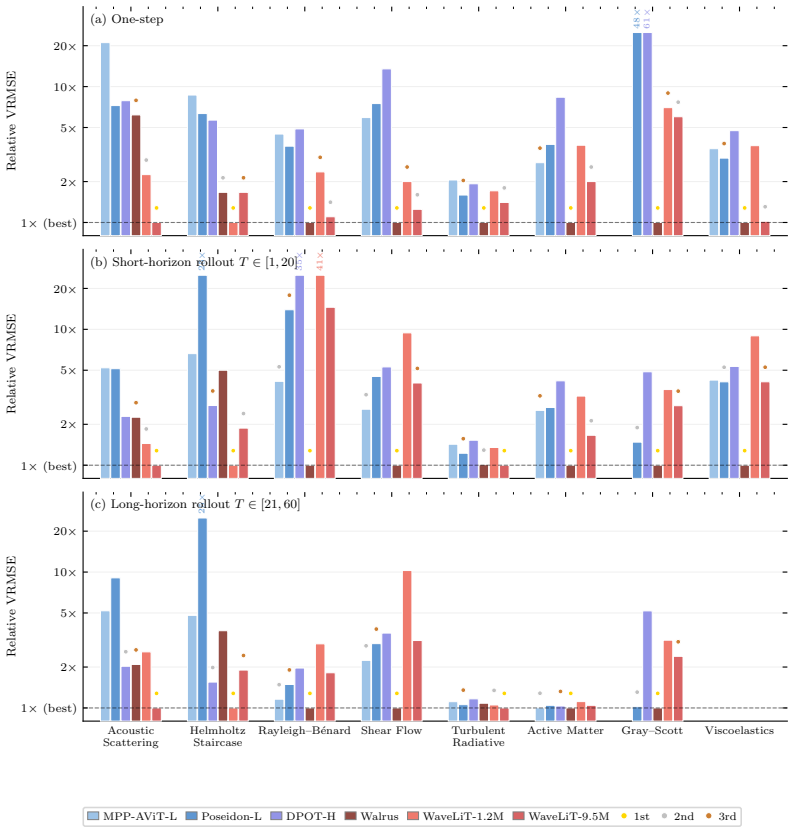
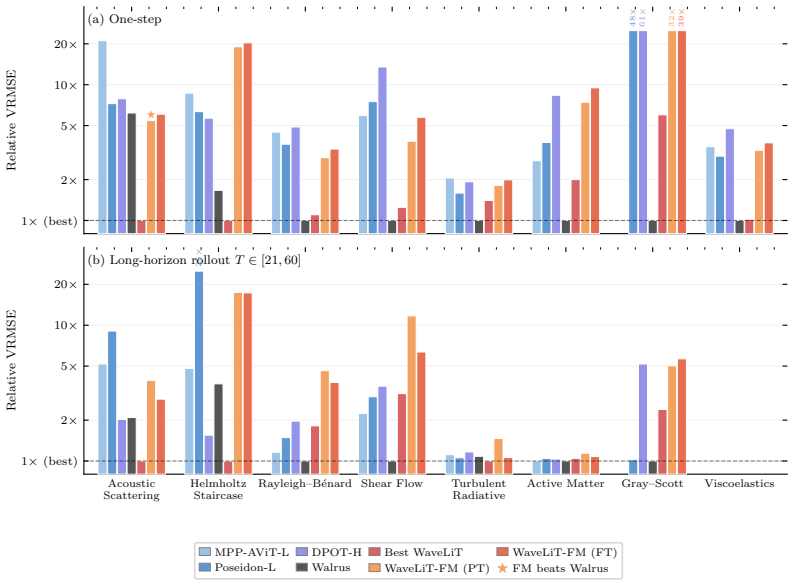
WaveLiT combines a discrete wavelet transform for lossless multi-resolution tokenization, an augmented linear attention block, a shared-weight multiscale feature pyramid, and a wavelet-domain auxiliary loss. Bespoke 1-10M-parameter WaveLiT models compete with foundation models of 100-1000× their size across eight TheWell benchmarks, with the largest gains on wave and acoustic-dominated benchmarks where the wavelet-multiscale prior fits the dominant dynamical structure and small per-step errors do not compound geometrically under rollout. Trained jointly across all eight benchmarks, a 10M-parameter foundation variant exhibits a structured, physically interpretable transfer pattern -- stronges
What carries the argument
WaveLiT architecture that performs lossless tokenization via discrete wavelet transform and enforces multiscale structure through a shared-weight feature pyramid.
If this is right
- Parameter-efficient models can reach foundation-model accuracy on PDE tasks when the inductive bias matches the dominant physics.
- Gains concentrate on wave and acoustic problems because small per-step errors remain stable under long rollouts.
- Joint training across benchmarks produces transfer that is strongest for dynamics aligned with the wavelet-multiscale prior.
- The pattern of where a prior succeeds or fails supplies an empirical map of what structure it encodes.
- Single-GPU training becomes feasible once model size is reduced by two to three orders of magnitude.
Where Pith is reading between the lines
- Error-pattern analysis across tasks could be used to select or combine multiple priors for a given physical regime.
- The same wavelet tokenization approach might extend to other scientific domains that exhibit clear scale separation, such as turbulence or climate fields.
- Parameter budgets could be allocated preferentially to problems whose dynamics fit an existing strong prior rather than to uniform scaling.
- Failure signatures might serve as a diagnostic for diagnosing missing physical mechanisms in a learned solver.
Load-bearing premise
Observed performance gaps are caused by the wavelet-multiscale architectural choices rather than differences in training data, optimizer, or preprocessing between the small models and the large baselines.
What would settle it
Retraining the large foundation models under identical data splits, preprocessing, optimizer settings, and training schedules as the WaveLiT models and finding that the accuracy gap on wave benchmarks disappears.
Figures

read the original abstract
Neural PDE solvers have followed the scaling trajectory of vision and language, with recent foundation models reaching billions of parameters. We argue that scale is a poor substitute for architectural inductive bias in this domain: structured priors deliver outsized parameter efficiency, and the pattern of where they succeed and fail is itself informative about what they capture. We instantiate this argument in WaveLiT, an architecture combining a discrete wavelet transform for lossless multi-resolution tokenization, an augmented linear attention block, a shared-weight multiscale feature pyramid, and a wavelet-domain auxiliary loss. Bespoke 1-10M-parameter WaveLiT models compete with foundation models of 100-1000$\times$ their size across eight TheWell benchmarks, with the largest gains on wave and acoustic-dominated benchmarks where the wavelet-multiscale prior fits the dominant dynamical structure and small per-step errors do not compound geometrically under rollout. Trained jointly across all eight benchmarks, a 10M-parameter foundation variant exhibits a structured, physically interpretable transfer pattern -- strongest where the wavelet-multiscale prior matches the dynamics, weakest on chaotic advection-dominated flows. The entire pipeline trains on a single GPU. The results suggest that small-model PDE performance is shaped by architectural inductive bias rather than scale, and that the structure of a prior's failures is a useful empirical signal about its content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WaveLiT, a 1-10M-parameter architecture for neural PDE solvers that combines discrete wavelet transform tokenization, augmented linear attention, a shared-weight multiscale feature pyramid, and a wavelet-domain auxiliary loss. It claims these models achieve competitive performance against foundation models 100-1000× larger across eight TheWell benchmarks, with largest gains on wave- and acoustic-dominated tasks where the prior aligns with the dynamics; a jointly trained 10M-parameter variant exhibits a structured, physically interpretable transfer pattern, and the full pipeline trains on a single GPU. The results are presented as evidence that architectural inductive bias outperforms scale for this domain.
Significance. If the comparisons hold under controlled conditions, the work provides concrete evidence that domain-specific priors can yield substantial parameter efficiency in scientific ML, with practical benefits for single-GPU training. The structured transfer pattern across benchmarks offers a useful empirical diagnostic for what a prior captures, which is a novel contribution beyond raw performance numbers. The emphasis on where the model succeeds and fails is a methodological strength that could inform future architecture choices.
major comments (2)
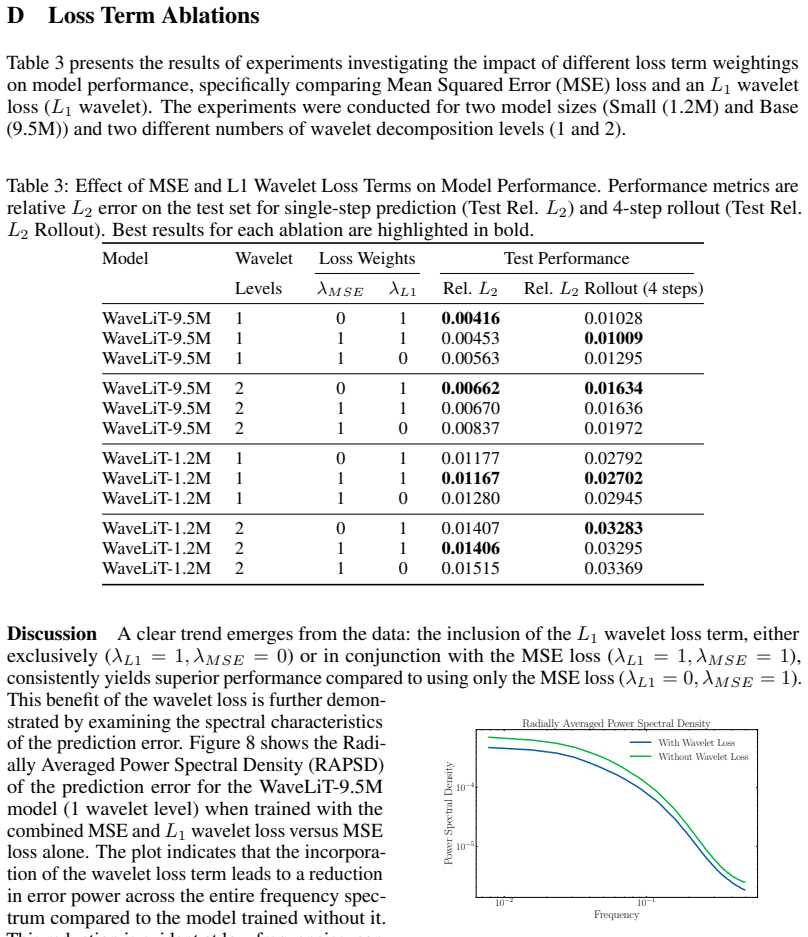
- [Experimental section / abstract] The central claim that performance gains are attributable to the wavelet-multiscale inductive bias (rather than training disparities) is load-bearing and requires explicit confirmation that foundation-model baselines were trained under identical protocols. The abstract attributes gains to 'where the wavelet-multiscale prior fits the dominant dynamical structure' without stating that baselines were re-trained with the same optimizer, learning-rate schedule, batch size, data normalization, number of steps, or rollout length; this must be addressed in the experimental section with a dedicated protocol-matching table or statement.
- [Results / Tables] Quantitative support for the competitive performance claim is referenced in the abstract (eight benchmarks, largest gains on wave/acoustic tasks) but the provided text lacks tables, error bars, or rollout lengths; the full experimental results must include these details (e.g., per-benchmark MSE or rollout error curves) to allow verification that post-hoc selection or training differences do not drive the reported gaps.
minor comments (2)
- [Abstract] The abstract would be strengthened by a brief parenthetical reference to the specific table or figure containing the main quantitative comparison.
- [Introduction] Clarify whether 'TheWell benchmarks' are drawn from a prior public dataset and provide the citation in the introduction or methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing experimental rigor. We agree that explicit protocol details and full quantitative results are essential to support the central claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental section / abstract] The central claim that performance gains are attributable to the wavelet-multiscale inductive bias (rather than training disparities) is load-bearing and requires explicit confirmation that foundation-model baselines were trained under identical protocols. The abstract attributes gains to 'where the wavelet-multiscale prior fits the dominant dynamical structure' without stating that baselines were re-trained with the same optimizer, learning-rate schedule, batch size, data normalization, number of steps, or rollout length; this must be addressed in the experimental section with a dedicated protocol-matching table or statement.
Authors: We agree this confirmation is required for the claim to hold. The original submission's experimental section described our training setup but did not explicitly compare protocols with the cited foundation-model baselines. In the revision we will add a dedicated 'Training Protocol Equivalence' subsection containing a table that lists optimizer, learning-rate schedule, batch size, data normalization, number of steps, and rollout length for both WaveLiT and the re-trained baselines, confirming they are identical. revision: yes
-
Referee: [Results / Tables] Quantitative support for the competitive performance claim is referenced in the abstract (eight benchmarks, largest gains on wave/acoustic tasks) but the provided text lacks tables, error bars, or rollout lengths; the full experimental results must include these details (e.g., per-benchmark MSE or rollout error curves) to allow verification that post-hoc selection or training differences do not drive the reported gaps.
Authors: We acknowledge that the submitted manuscript text did not contain the requested tables or error bars. The revision will expand the results section with a new table reporting per-benchmark MSE (with standard deviations across three seeds), rollout error curves for all eight TheWell tasks, and explicit rollout lengths. This will allow direct verification of the performance gaps and the pattern of gains on wave/acoustic-dominated benchmarks. revision: yes
Circularity Check
No circularity; empirical benchmark comparisons with no derivation reducing to inputs by construction
full rationale
The paper presents an architecture (WaveLiT) and reports direct empirical results on eight TheWell benchmarks, attributing relative performance to the wavelet-multiscale prior based on observed patterns. No mathematical derivation chain, first-principles prediction, or fitted parameter is invoked that reduces to its own inputs. No self-citations, uniqueness theorems, or ansatzes are used to justify core claims. The transfer pattern is described as an observed outcome of joint training, not a prediction forced by the model equations. This is a standard empirical comparison paper whose central claims remain independent of any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
John Wiley & Sons, 2004
Tinku Acharya and Ping-Sing Tsai.JPEG2000 standard for image compression: concepts, algorithms and VLSI architectures. John Wiley & Sons, 2004
2004
-
[3]
Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and Vahab Mirrokni. It’s all connected: A journey through test-time memorization, attentional bias, retention, and online optimization. arXiv preprint arXiv:2504.13173, 2025
-
[4]
Small Language Models are the Future of Agentic AI
Peter Belcak, Greg Heinrich, Shizhe Diao, Yonggan Fu, Xin Dong, Saurav Muralidharan, Yingyan Celine Lin, and Pavlo Molchanov. Small language models are the future of agentic ai. arXiv preprint arXiv:2506.02153, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Aurora: A foundation model of the atmosphere.arXiv preprint arXiv:2405.13063, 2024
Cristian Bodnar, Wessel P Bruinsma, Ana Lucic, Megan Stanley, Johannes Brandstetter, Patrick Garvan, Maik Riechert, Jonathan Weyn, Haiyu Dong, Anna Vaughan, et al. Aurora: A foundation model of the atmosphere.arXiv preprint arXiv:2405.13063, 2024
-
[6]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018
2018
-
[7]
Conditional positional encodings for vision transformers.arXiv preprint arXiv:2102.10882, 2021
Xiangxiang Chu, Zhi Tian, Bo Zhang, Xinlong Wang, and Chunhua Shen. Conditional positional encodings for vision transformers.arXiv preprint arXiv:2102.10882, 2021
-
[8]
Linear attention with global context: A multipole attention mechanism for vision and physics
Alex Colagrande, Paul Caillon, Eva Feillet, and Alexandre Allauzen. Linear attention with global context: A multipole attention mechanism for vision and physics. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3099–3108, 2025
2025
-
[9]
Unsupervised cross-lingual representation learning at scale
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wen- zek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross-lingual representation learning at scale. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 8440–8451, 2020
2020
-
[10]
jax-wavelets: The 2D discrete wavelet transform for JAX, 2022
Katherine Crowson. jax-wavelets: The 2D discrete wavelet transform for JAX, 2022
2022
-
[11]
Cswin transformer: A general vision transformer backbone with cross-shaped windows
Xiaoyi Dong, Jianmin Bao, Dongdong Chen, Weiming Zhang, Nenghai Yu, Lu Yuan, Dong Chen, and Baining Guo. Cswin transformer: A general vision transformer backbone with cross-shaped windows. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12124–12134, 2022
2022
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
Towards multi-spatiotemporal-scale generalized pde modeling.arXiv preprint arXiv:2209.15616, 2022
Jayesh K Gupta and Johannes Brandstetter. Towards multi-spatiotemporal-scale generalized pde modeling.arXiv preprint arXiv:2209.15616, 2022
-
[14]
Demystify mamba in vision: A linear attention perspective
Dongchen Han, Ziyi Wang, Zhuofan Xia, Yizeng Han, Yifan Pu, Chunjiang Ge, Jun Song, Shiji Song, Bo Zheng, and Gao Huang. Demystify mamba in vision: A linear attention perspective. arXiv preprint arXiv:2405.16605, 2024
-
[15]
Zhongkai Hao, Chang Su, Songming Liu, Julius Berner, Chengyang Ying, Hang Su, Anima Anandkumar, Jian Song, and Jun Zhu. Dpot: Auto-regressive denoising operator transformer for large-scale pde pre-training.arXiv preprint arXiv:2403.03542, 2024
-
[16]
Flax: A neural network library and ecosystem for JAX, 2024
Jonathan Heek, Anselm Levskaya, Avital Oliver, Marvin Ritter, Bertrand Rondepierre, Andreas Steiner, and Marc van Zee. Flax: A neural network library and ecosystem for JAX, 2024. 10
2024
-
[17]
Poseidon: Efficient foundation models for pdes
Maximilian Herde, Bogdan Raonic, Tobias Rohner, Roger Käppeli, Roberto Molinaro, Em- manuel de Bézenac, and Siddhartha Mishra. Poseidon: Efficient foundation models for pdes. Advances in Neural Information Processing Systems, 37:72525–72624, 2024
2024
-
[18]
CRC press, 1996
Eugenio Hernández and Guido Weiss.A first course on wavelets. CRC press, 1996
1996
-
[19]
Psychology press, 2014
Geoffrey E Hinton and James A Anderson.Parallel models of associative memory: updated edition. Psychology press, 2014
2014
-
[20]
simple diffusion: End-to-end diffusion for high resolution images
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. simple diffusion: End-to-end diffusion for high resolution images. InInternational Conference on Machine Learning, pages 13213– 13232. PMLR, 2023
2023
-
[21]
Wavelet diffusion neural operator.arXiv preprint arXiv:2412.04833, 2024
Peiyan Hu, Rui Wang, Xiang Zheng, Tao Zhang, Haodong Feng, Ruiqi Feng, Long Wei, Yue Wang, Zhi-Ming Ma, and Tailin Wu. Wavelet diffusion neural operator.arXiv preprint arXiv:2412.04833, 2024
-
[22]
Less is More: Recursive Reasoning with Tiny Networks
Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks.arXiv preprint arXiv:2510.04871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[24]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational conference on machine learning, pages 5156–5165. PMLR, 2020
2020
-
[25]
Neural operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023
2023
-
[26]
Operator learning: Algorithms and analysis.arXiv preprint arXiv:2402.15715, 2024
Nikola B Kovachki, Samuel Lanthaler, and Andrew M Stuart. Operator learning: Algorithms and analysis.arXiv preprint arXiv:2402.15715, 2024
-
[27]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differen- tial equations.arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
Neural Operator: Graph Kernel Network for Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations.arXiv preprint arXiv:2003.03485, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[29]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017
2017
-
[30]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Learning nonlinear operators via deeponet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3(3):218–229, 2021
2021
-
[32]
A theory for multiresolution signal decomposition: the wavelet repre- sentation.IEEE transactions on pattern analysis and machine intelligence, 11(7):674–693, 1989
Stephane G Mallat. A theory for multiresolution signal decomposition: the wavelet repre- sentation.IEEE transactions on pattern analysis and machine intelligence, 11(7):674–693, 1989
1989
-
[33]
Multiple physics pretraining for physical surrogate models.arXiv preprint arXiv:2310.02994, 2023
Michael McCabe, Bruno Régaldo-Saint Blancard, Liam Holden Parker, Ruben Ohana, Miles Cranmer, Alberto Bietti, Michael Eickenberg, Siavash Golkar, Geraud Krawezik, Francois Lanusse, et al. Multiple physics pretraining for physical surrogate models.arXiv preprint arXiv:2310.02994, 2023. 11
-
[34]
Walrus: A cross-domain foundation model for continuum dynamics.arXiv preprint arXiv:2511.15684, 2025
Michael McCabe, Payel Mukhopadhyay, Tanya Marwah, Bruno Regaldo-Saint Blancard, Fran- cois Rozet, Cristiana Diaconu, Lucas Meyer, Kaze WK Wong, Hadi Sotoudeh, Alberto Bietti, et al. Walrus: A cross-domain foundation model for continuum dynamics.arXiv preprint arXiv:2511.15684, 2025
-
[35]
Physix: A foundation model for physics simulations.arXiv preprint arXiv:2506.17774, 2025
Tung Nguyen, Arsh Koneru, Shufan Li, and Aditya Grover. Physix: A foundation model for physics simulations.arXiv preprint arXiv:2506.17774, 2025
-
[36]
The well: a large-scale collection of diverse physics simulations for machine learning.Advances in Neural Information Processing Systems, 37:44989–45037, 2024
Ruben Ohana, Michael McCabe, Lucas Meyer, Rudy Morel, Fruzsina Agocs, Miguel Beneitez, Marsha Berger, Blakesly Burkhart, Stuart Dalziel, Drummond Fielding, et al. The well: a large-scale collection of diverse physics simulations for machine learning.Advances in Neural Information Processing Systems, 37:44989–45037, 2024
2024
-
[37]
Nomad: Nonlinear manifold decoders for operator learning.Advances in Neural Information Processing Systems, 35:5601–5613, 2022
Jacob Seidman, Georgios Kissas, Paris Perdikaris, and George J Pappas. Nomad: Nonlinear manifold decoders for operator learning.Advances in Neural Information Processing Systems, 35:5601–5613, 2022
2022
-
[38]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[39]
The lifting scheme: A construction of second generation wavelets.SIAM journal on mathematical analysis, 29(2):511–546, 1998
Wim Sweldens. The lifting scheme: A construction of second generation wavelets.SIAM journal on mathematical analysis, 29(2):511–546, 1998
1998
-
[40]
Tapas Tripura and Souvik Chakraborty. Wavelet neural operator: a neural operator for parametric partial differential equations.arXiv preprint arXiv:2205.02191, 2022
-
[41]
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Johannes von Oswald, Nino Scherrer, Seijin Kobayashi, Luca Versari, Songlin Yang, Max- imilian Schlegel, Kaitlin Maile, Yanick Schimpf, Oliver Sieberling, Alexander Meulemans, et al. Mesanet: Sequence modeling by locally optimal test-time training.arXiv preprint arXiv:2506.05233, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Feng Wang, Yaodong Yu, Guoyizhe Wei, Wei Shao, Yuyin Zhou, Alan Yuille, and Cihang Xie. Scaling laws in patchification: An image is worth 50,176 tokens and more.arXiv preprint arXiv:2502.03738, 2025
-
[43]
Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical reasoning model.arXiv preprint arXiv:2506.21734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Ke Alexander Wang, Jiaxin Shi, and Emily B Fox. Test-time regression: a unifying framework for designing sequence models with associative memory.arXiv preprint arXiv:2501.12352, 2025
-
[45]
Sifan Wang, Tong-Rui Liu, Shyam Sankaran, and Paris Perdikaris. Micrometer: Micromechan- ics transformer for predicting mechanical responses of heterogeneous materials.arXiv preprint arXiv:2410.05281, 2024
-
[46]
Sifan Wang, Shyam Sankaran, and Paris Perdikaris. Respecting causality is all you need for training physics-informed neural networks.arXiv preprint arXiv:2203.07404, 2022
-
[47]
Cvit: Continuous vision transformer for operator learning.arXiv preprint arXiv:2405.13998, 2024
Sifan Wang, Jacob H Seidman, Shyam Sankaran, Hanwen Wang, George J Pappas, and Paris Perdikaris. Cvit: Continuous vision transformer for operator learning.arXiv preprint arXiv:2405.13998, 2024
-
[48]
mt5: A massively multilingual pre-trained text-to-text trans- former
Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mt5: A massively multilingual pre-trained text-to-text trans- former. InProceedings of the 2021 conference of the North American chapter of the association for computational linguistics: Human language technologies, pages 483–498, 2021
2021
-
[49]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule.arXiv preprint arXiv:2412.06464, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Scaling vision transform- ers
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transform- ers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12104–12113, 2022. 12
2022
-
[51]
Zhenhai Zhu and Radu Soricut. Wavelet-based image tokenizer for vision transformers.arXiv preprint arXiv:2405.18616, 2024. 13 A Linear Attention and the Ridge Regression View From softmax to linear attention.Standard attention computes Attn(Q, K, V) = softmax(QK ⊤/ √ d)V , whose QK ⊤ matrix is N×N and makes both memory and compute scale quadratically with...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.