CelerLog: Fast Log Parsing via Dynamic Routing
Pith reviewed 2026-06-29 20:18 UTC · model grok-4.3
The pith
CelerLog routes logs by statistical density so most avoid LLMs while accuracy holds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
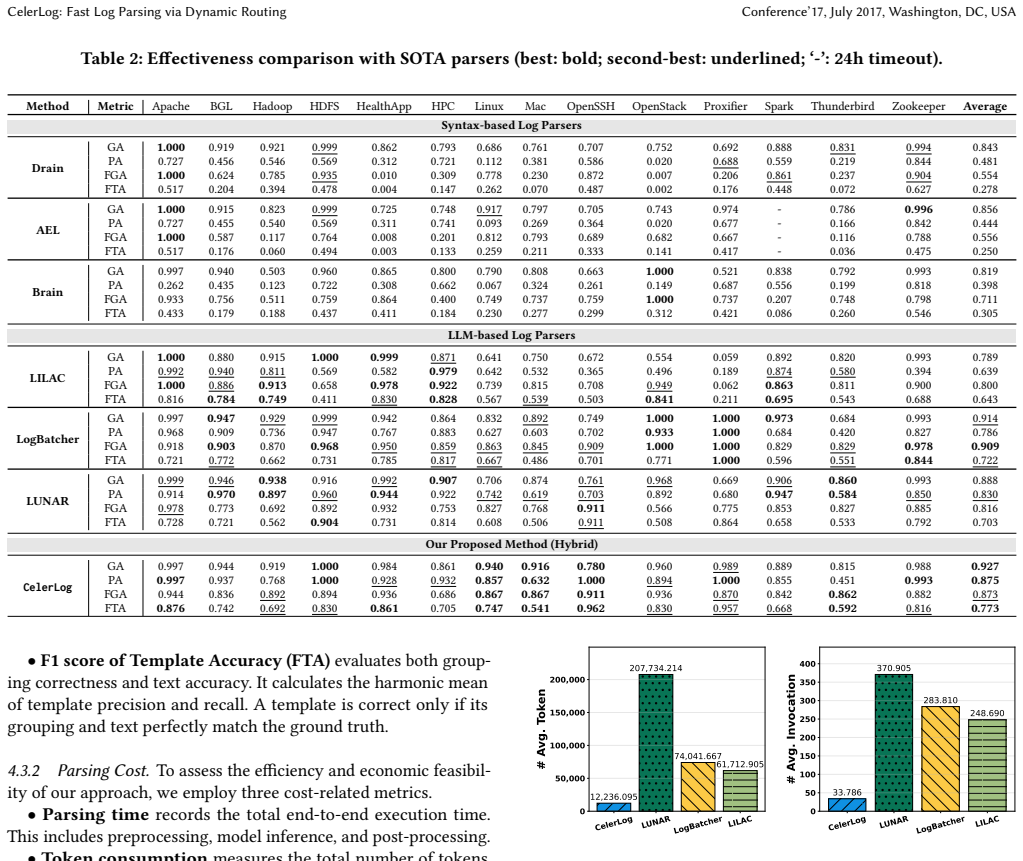
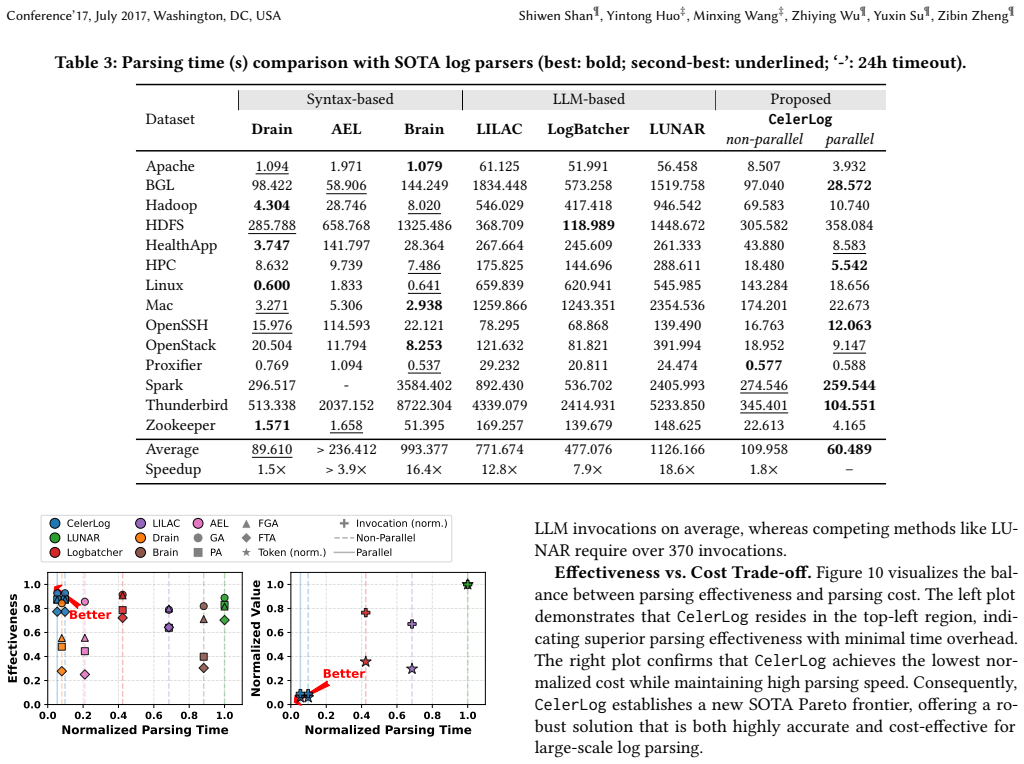
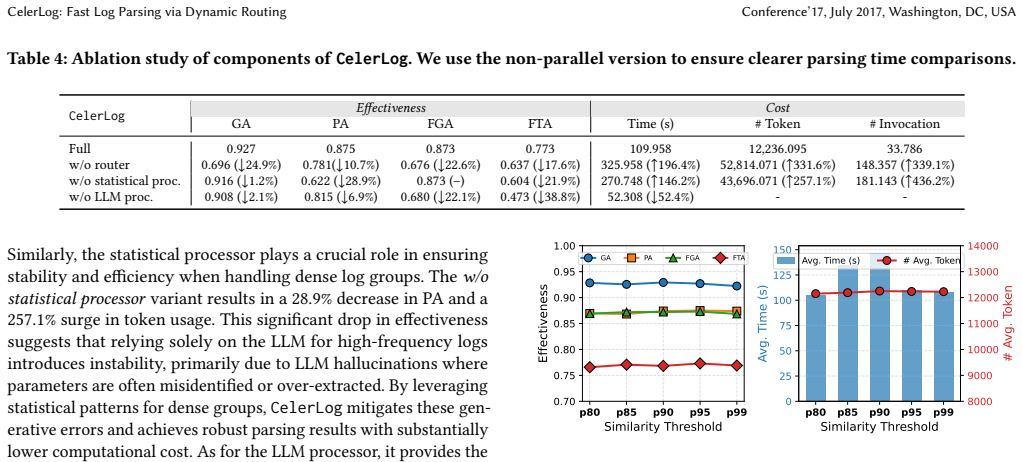
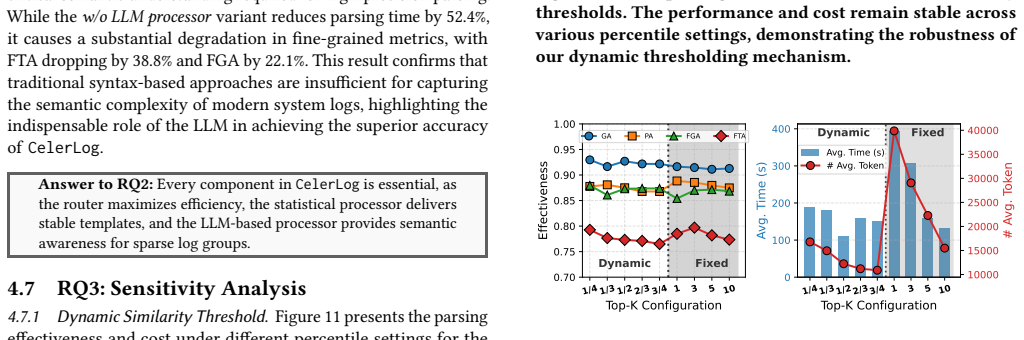
CelerLog introduces a dynamic routing mechanism to classify logs into dense and sparse groups. Logs with strong statistical patterns are processed by an efficient statistical processor while sparse groups lacking such patterns are routed to an LLM. This hybrid strategy avoids unnecessary LLM invocations and achieves leading performance over state-of-the-art baselines on 14 public datasets, with speeds 7.9x to 18.6x faster than LLM methods and up to 1.5x faster than Drain, plus token reductions of 80.2-94.1 percent and LLM invocation reductions of 86.4-90.9 percent.
What carries the argument
The dynamic routing mechanism that partitions logs into dense (statistically patterned) and sparse groups for selective statistical or LLM processing.
If this is right
- Most logs exhibit repetitive patterns that statistical methods can extract without semantic reasoning.
- Only logs lacking statistical patterns require the slower, costlier LLM path.
- Overall parsing latency and cost drop substantially while accuracy remains competitive with pure LLM or pure statistical baselines.
- The same routing principle reduces both token consumption and the number of LLM calls by more than 80 percent on standard benchmarks.
- The hybrid design outperforms both Drain and full LLM parsers on the 14 evaluated datasets.
Where Pith is reading between the lines
- If the routing decision itself stays accurate across varied log sources, the same density-based split could apply to other tasks that mix patterned and novel data.
- Lower LLM invocation rates could make high-volume log analysis practical on hardware with limited compute or budget.
- Further tuning the classifier to reduce even small routing overhead would compound the observed speed gains.
- The observed cost reductions suggest the method scales to production volumes where full LLM parsing is currently prohibitive.
Load-bearing premise
Incoming logs can be reliably and cheaply partitioned into dense and sparse groups such that classification overhead stays negligible and misrouting does not degrade end-to-end accuracy or cost savings.
What would settle it
A new log dataset on which the classifier routes a large fraction of logs to the wrong processor, producing either accuracy below current baselines or no measurable drop in LLM token use.
Figures

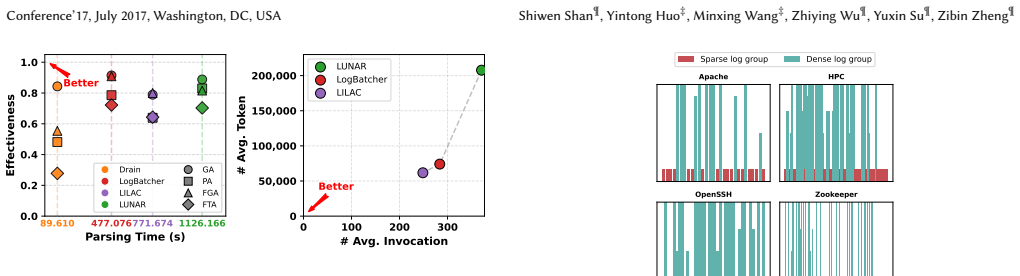
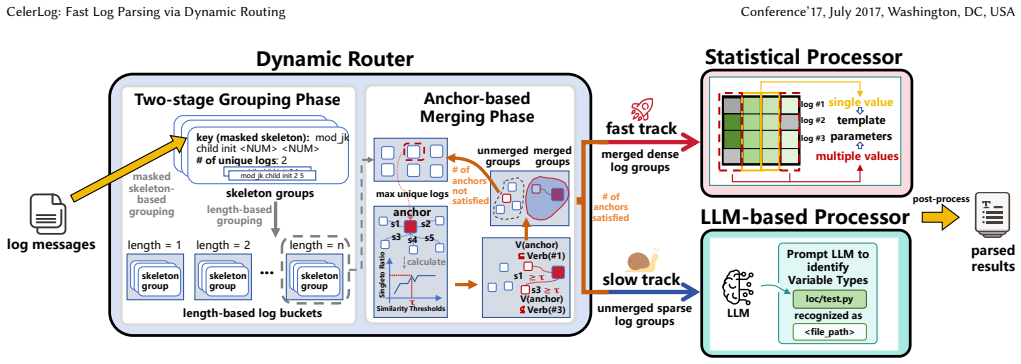
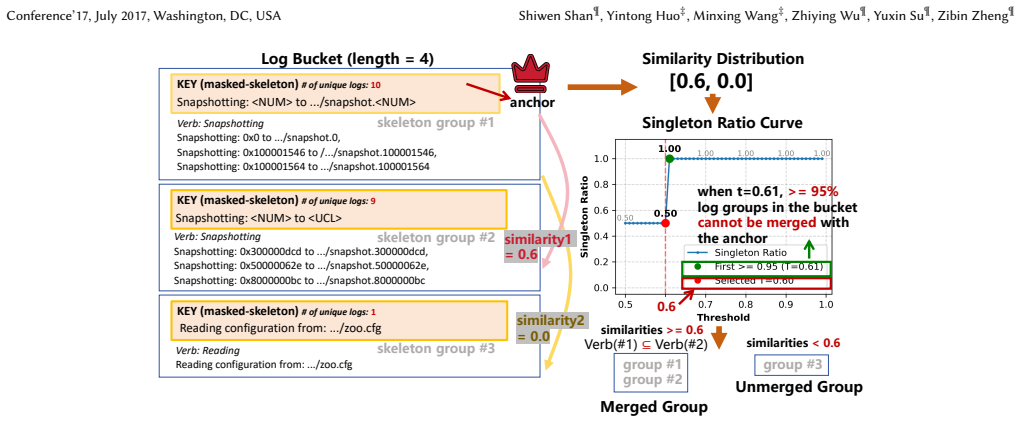

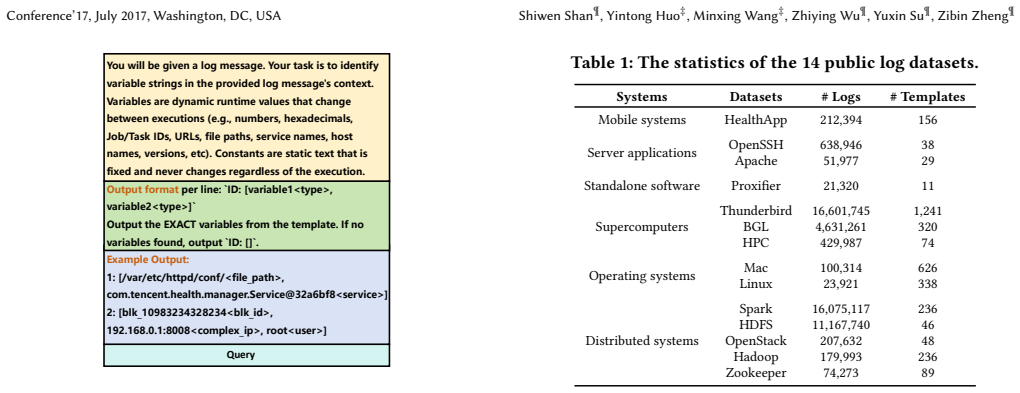
read the original abstract
Log parsing is a fundamental step for automated log analysis, which transforms raw log messages into structured formats. Existing syntax-based parsers struggle with complex logs because they lack semantic reasoning ability. Emerging LLM-powered semantic parsers achieve high accuracy but suffer from prohibitive latency and token costs because they apply semantic inference across all logs. Our key observation is that not all logs necessitate complex semantic understanding: a vast majority of logs exhibit repetitive patterns that can be extracted via straightforward statistical analysis. Driven by this insight, we propose CelerLog, a fast and effective log parser. CelerLog introduces a dynamic routing mechanism to classify logs into dense and sparse groups. Logs with strong statistical patterns (dense groups) are processed by an efficient statistical processor, whereas the sparse groups lacking such patterns are routed to an LLM for semantic inference. This hybrid strategy avoids unnecessary LLM invocations. Extensive experiments on 14 public datasets show that CelerLog achieves leading performance over state-of-the-art baselines and is 7.9x to 18.6x faster than LLM methods and up to 1.5x faster than Drain. Additionally, it reduces costs by decreasing token consumption by 80.2% - 94.1% and LLM invocations by 86.4% - 90.9%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CelerLog, a hybrid log parser that uses a dynamic routing mechanism to send logs exhibiting strong statistical patterns (dense groups) to an efficient statistical processor and sparse logs lacking such patterns to an LLM for semantic inference. On 14 public datasets it claims leading performance over baselines, with speedups of 7.9x–18.6x versus LLM methods and up to 1.5x versus Drain, plus token-consumption reductions of 80.2%–94.1% and LLM-invocation reductions of 86.4%–90.9%.
Significance. If the routing step reliably partitions logs with negligible overhead and error, the hybrid design would materially improve the cost–accuracy trade-off for semantic log parsing, allowing LLM use to be restricted to a small minority of inputs while preserving overall accuracy.
major comments (2)
- [Abstract] Abstract: the headline speed and cost claims rest on the premise that the dynamic router correctly identifies the 'vast majority' of logs as dense and routes only true sparse cases to the LLM; yet the abstract supplies no classifier description (features, threshold, training), no routing-accuracy or misrouting-rate figures, and no ablation showing end-to-end accuracy or latency under routing mistakes. This is load-bearing: even modest misrouting would either erode the reported savings or degrade parsing quality.
- [Abstract] Abstract: only aggregate speedups and accuracy are stated across the 14 datasets; no per-dataset tables, error bars, or breakdowns of routing decisions are mentioned, preventing verification that the claimed gains are consistent rather than driven by a few favorable datasets.
minor comments (1)
- The abstract would benefit from a one-sentence description of the statistical processor employed for the dense group.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the abstract would benefit from additional context on the routing mechanism and consistency of results. We will revise the abstract accordingly. Point-by-point responses are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline speed and cost claims rest on the premise that the dynamic router correctly identifies the 'vast majority' of logs as dense and routes only true sparse cases to the LLM; yet the abstract supplies no classifier description (features, threshold, training), no routing-accuracy or misrouting-rate figures, and no ablation showing end-to-end accuracy or latency under routing mistakes. This is load-bearing: even modest misrouting would either erode the reported savings or degrade parsing quality.
Authors: We acknowledge that the provided abstract is concise and does not include a description of the classifier, routing accuracy metrics, or an ablation on misrouting effects. The full manuscript details the routing mechanism (features, threshold, and training) in Section 3. Routing accuracy and misrouting rates are reported in the experimental evaluation. We agree an explicit ablation on routing errors is warranted and will add one. We will revise the abstract to include a brief statement on routing performance. revision: yes
-
Referee: [Abstract] Abstract: only aggregate speedups and accuracy are stated across the 14 datasets; no per-dataset tables, error bars, or breakdowns of routing decisions are mentioned, preventing verification that the claimed gains are consistent rather than driven by a few favorable datasets.
Authors: We agree the abstract reports only aggregate figures. The manuscript contains per-dataset tables for accuracy, runtime, and cost metrics along with error bars and routing decision breakdowns in the experimental section. These show consistent gains. We will revise the abstract to note that improvements hold across all datasets. revision: yes
Circularity Check
No circularity; empirical system evaluated on external benchmarks
full rationale
The paper describes an engineering hybrid parser whose performance numbers (speedups, token reductions) are measured outcomes on 14 public datasets against external baselines. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the supplied text. The routing mechanism is presented as a design choice whose accuracy is asserted via experiment rather than derived from prior self-work. This is the normal non-circular case for an applied systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NLTK Project
2001. NLTK Project. https://www.nltk.org/howto/wordnet.html. Oneline; Accessed: 2026-03-16
2001
-
[2]
Industrial-Strength Natural Language Processing
2016. Industrial-Strength Natural Language Processing. https://spacy.io/. Online; Accessed: 2026-03-16
2016
-
[3]
OpenAI API
2026. OpenAI API. https://openai.com/blog/openai-api. Online; Accessed: 2026-03-16
2026
- [4]
-
[5]
O’Reilly Media, Inc
Steven Bird, Ewan Klein, and Edward Loper. 2009.Natural language processing with Python: analyzing text with the natural language toolkit. " O’Reilly Media, Inc. "
2009
-
[6]
Boyuan Chen, Jian Song, Peng Xu, Xing Hu, and Zhen Ming Jiang. 2018. An automated approach to estimating code coverage measures via execution logs. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering. 305–316
2018
- [7]
-
[8]
Tianyu Cui, Ruowei Fu, Changchang Liu, Yuhe Ji, Wenwei Gu, Shenglin Zhang, Yongqian Sun, and Dan Pei. 2025. AetherLog: Log-based Root Cause Analysis by Integrating Large Language Models with Knowledge Graphs. In2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 49–60
2025
-
[9]
Hetong Dai, Heng Li, Che-Shao Chen, Weiyi Shang, and Tse-Hsun Chen. 2020. Logram: Efficient Log Parsing Using 𝑛 n-Gram Dictionaries.IEEE Transactions on Software Engineering (TSE)48, 3 (2020), 879–892
2020
-
[10]
Hetong Dai, Yiming Tang, Heng Li, and Weiyi Shang. 2023. PILAR: Studying and Mitigating the Influence of Configurations on Log Parsing. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 818–829
2023
-
[11]
Min Du, Feifei Li, Guineng Zheng, and Vivek Srikumar. 2017. Deeplog: Anomaly detection and diagnosis from system logs through deep learning. InProceedings of the 2017 ACM SIGSAC conference on computer and communications security. 1285–1298
2017
-
[12]
Qiang Fu, Jian-Guang Lou, Yi Wang, and Jiang Li. 2009. Execution anomaly detection in distributed systems through unstructured log analysis. In2009 ninth IEEE international conference on data mining (ICDM). IEEE, 149–158
2009
-
[13]
Hossein Hamooni, Biplob Debnath, Jianwu Xu, Hui Zhang, Guofei Jiang, and Abdullah Mueen. 2016. Logmine: Fast pattern recognition for log analytics. InProceedings of the 25th ACM International on Conference on Information and Knowledge Management (CIKM). 1573–1582
2016
-
[14]
Minghua He, Tong Jia, Chiming Duan, Huaqian Cai, Ying Li, and Gang Huang
-
[15]
In2025 IEEE/ACM 47th International Conference on Soft- ware Engineering (ICSE)
Weakly-supervised log-based anomaly detection with inexact labels via multi-instance learning. In2025 IEEE/ACM 47th International Conference on Soft- ware Engineering (ICSE). IEEE, 2918–2930
-
[16]
Pinjia He, Jieming Zhu, Shilin He, Jian Li, and Michael R Lyu. 2016. An evaluation study on log parsing and its use in log mining. In2016 46th annual IEEE/IFIP international conference on dependable systems and networks (DSN). IEEE, 654– 661
2016
-
[17]
Pinjia He, Jieming Zhu, Zibin Zheng, and Michael R Lyu. 2017. Drain: An online log parsing approach with fixed depth tree. In2017 IEEE international conference on web services (ICWS). IEEE, 33–40
2017
-
[18]
Junjie Huang, Zhihan Jiang, Zhuangbin Chen, and Michael Lyu. 2025. No more labelled examples? an unsupervised log parser with llms.Proceedings of the ACM on Software Engineering2, FSE (2025), 2406–2429
2025
-
[19]
Yintong Huo, Yuxin Su, Cheryl Lee, and Michael R Lyu. 2023. Semparser: A semantic parser for log analytics. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 881–893
2023
-
[20]
Zhihan Jiang, Jinyang Liu, Zhuangbin Chen, Yichen Li, Junjie Huang, Yintong Huo, Pinjia He, Jiazhen Gu, and Michael R Lyu. 2024. Lilac: Log parsing using llms with adaptive parsing cache.Proceedings of the ACM on Software Engineering 1, FSE (2024), 137–160
2024
-
[21]
Zhihan Jiang, Jinyang Liu, Junjie Huang, Yichen Li, Yintong Huo, Jiazhen Gu, Zhuangbin Chen, Jieming Zhu, and Michael R Lyu. 2024. A large-scale evaluation for log parsing techniques: How far are we?. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 223–234
2024
- [22]
-
[23]
Zhen Ming Jiang, Ahmed E Hassan, Parminder Flora, and Gilbert Hamann. 2008. Abstracting execution logs to execution events for enterprise applications (short paper). In2008 The Eighth International Conference on Quality Software. IEEE, 181–186
2008
-
[24]
Van-Hoang Le and Hongyu Zhang. 2021. Log-based anomaly detection with- out log parsing. In2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 492–504
2021
- [25]
-
[26]
Xiaoyun Li, Hongyu Zhang, Van-Hoang Le, and Pengfei Chen. 2024. Logshrink: Effective log compression by leveraging commonality and variability of log data. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–12
2024
-
[27]
Jinyang Liu, Jieming Zhu, Shilin He, Pinjia He, Zibin Zheng, and Michael R Lyu. 2019. Logzip: Extracting hidden structures via iterative clustering for log compression. In2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 863–873
2019
-
[28]
Yudong Liu, Xu Zhang, Shilin He, Hongyu Zhang, Liqun Li, Yu Kang, Yong Xu, Minghua Ma, Qingwei Lin, Yingnong Dang, et al. 2022. Uniparser: A unified log parser for heterogeneous log data. InProceedings of the ACM Web Conference 2022 (WWW). 1893–1901
2022
-
[29]
Jian-Guang Lou, Qiang Fu, Shenqi Yang, Ye Xu, and Jiang Li. 2010. Mining invariants from console logs for system problem detection. In2010 USENIX annual technical conference (USENIX ATC 10)
2010
- [30]
-
[31]
Adetokunbo AO Makanju, A Nur Zincir-Heywood, and Evangelos E Milios. 2009. Clustering event logs using iterative partitioning. InProceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining (KDD). 1255–1264
2009
-
[32]
Weibin Meng, Ying Liu, Yichen Zhu, Shenglin Zhang, Dan Pei, Yuqing Liu, Yihao Chen, Ruizhi Zhang, Shimin Tao, Pei Sun, et al. 2019. Loganomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs.. InIjcai, Vol. 19. 4739–4745
2019
-
[33]
Suphakit Niwattanakul, Jatsada Singthongchai, Ekkachai Naenudorn, and Su- pachanun Wanapu. 2013. Using of Jaccard coefficient for keywords similarity. InProceedings of the international multiconference of engineers and computer scientists, Vol. 1. 380–384
2013
-
[34]
Paolo Notaro, Soroush Haeri, Jorge Cardoso, and Michael Gerndt. 2023. LogRule: Efficient Structured Log Mining for Root Cause Analysis.IEEE Transactions on Network and Service Management(2023)
2023
-
[35]
David Ohana. 2020. A blog about Drain usage in IBM Cloud. https://developer.ibm.com/blogs/how-mining-log-templates-can-help-ai- ops-in-cloud-scale-data-centers/. Online; Accessed: 2026-03-16
2020
-
[36]
OpenAI. [n. d.]. GPT-5.2. https://platform.openai.com/docs/models/gpt-5.2. One- line; Accessed: 2026-03-16
2026
-
[37]
Daan Schipper, Maurício Aniche, and Arie van Deursen. 2019. Tracing back log data to its log statement: from research to practice. In2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR). IEEE, 545–549
2019
-
[38]
Issam Sedki, Abdelwahab Hamou-Lhadj, Otmane Ait-Mohamed, and Mo- hammed A Shehab. 2022. An Effective Approach for Parsing Large Log Files. In2022 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 1–12
2022
-
[39]
Shiwen Shan, Yintong Huo, Yuxin Su, Yichen Li, Dan Li, and Zibin Zheng. 2024. Face it yourselves: An llm-based two-stage strategy to localize configuration errors via logs. InProceedings of the 33rd ACM SIGSOFT international symposium on software testing and analysis. 13–25
2024
-
[40]
Keiichi Shima. 2016. Length matters: Clustering system log messages using length of words.arXiv preprint arXiv:1611.03213(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[41]
Donghwan Shin, Zanis Ali Khan, Domenico Bianculli, and Lionel Briand. 2021. A theoretical framework for understanding the relationship between log pars- ing and anomaly detection. InInternational Conference on Runtime Verification. Springer, 277–287
2021
-
[42]
Risto Vaarandi. 2003. A data clustering algorithm for mining patterns from event logs. InProceedings of the 3rd IEEE Workshop on IP Operations & Management (IPOM)(IEEE Cat. No. 03EX764). Ieee, 119–126
2003
-
[43]
Risto Vaarandi and Mauno Pihelgas. 2015. Logcluster-a data clustering and pattern mining algorithm for event logs. In2015 11th International conference on network and service management (CNSM). IEEE, 1–7. Conference’17, July 2017, Washington, DC, USA Shiwen Shan ¶, Yintong Huo ‡, Minxing Wang‡, Zhiying Wu ¶, Yuxin Su ¶, Zibin Zheng ¶
2015
-
[44]
Lingzhi Wang, Nengwen Zhao, Junjie Chen, Pinnong Li, Wenchi Zhang, and Kaixin Sui. 2020. Root-cause metric location for microservice systems via log anomaly detection. In2020 IEEE international conference on web services (ICWS). IEEE, 142–150
2020
-
[45]
Teng Wang, Xiaodong Liu, Shanshan Li, Xiangke Liao, Wang Li, and Qing Liao
-
[46]
In2018 IEEE International Conference on Software Quality, Reliability and Security (QRS)
MisconfDoctor: diagnosing misconfiguration via log-based configuration testing. In2018 IEEE International Conference on Software Quality, Reliability and Security (QRS). IEEE, 1–12
-
[47]
Thorsten Wittkopp, Philipp Wiesner, and Odej Kao. 2024. Logrca: Log-based root cause analysis for distributed services. InEuropean Conference on Parallel Processing. Springer, 362–376
2024
-
[48]
Pei Xiao, Tong Jia, Chiming Duan, Minghua He, Weijie Hong, Xixuan Yang, Yihan Wu, Ying Li, and Gang Huang. 2025. Clslog: Collaborating large and small models for log-based anomaly detection. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 686–690
2025
-
[49]
Yi Xiao, Van-Hoang Le, and Hongyu Zhang. 2024. free: Towards more practical log parsing with large language models. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 153–165
2024
- [50]
-
[51]
Siyu Yu, Pinjia He, Ningjiang Chen, and Yifan Wu. 2023. Brain: Log parsing with bidirectional parallel tree.IEEE Transactions on Services Computing16, 5 (2023), 3224–3237
2023
-
[52]
Siyu Yu, Yifan Wu, Ying Li, and Pinjia He. 2024. Unlocking the power of numbers: Log compression via numeric token parsing. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 919–930
2024
-
[53]
Ding Yuan, Haohui Mai, Weiwei Xiong, Lin Tan, Yuanyuan Zhou, and Shankar Pasupathy. 2010. Sherlog: error diagnosis by connecting clues from run-time logs. InProceedings of the fifteenth International Conference on Architectural support for programming languages and operating systems. 143–154
2010
-
[54]
Chenbo Zhang, Wenying Xu, Jinbu Liu, Lu Zhang, Guiyang Liu, Jihong Guan, Qi Zhou, and Shuigeng Zhou. 2025. SemanticLog: Towards Effective and Efficient Large-Scale Semantic Log Parsing.IEEE Transactions on Software Engineering (2025)
2025
-
[55]
Xu Zhang, Yong Xu, Qingwei Lin, Bo Qiao, Hongyu Zhang, Yingnong Dang, Chunyu Xie, Xinsheng Yang, Qian Cheng, Ze Li, et al. 2019. Robust log-based anomaly detection on unstable log data. InProceedings of the 2019 27th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering. 807–817
2019
-
[56]
Xiang Zhou, Xin Peng, Tao Xie, Jun Sun, Chao Ji, Dewei Liu, Qilin Xiang, and Chuan He. 2019. Latent error prediction and fault localization for microservice applications by learning from system trace logs. InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (...
2019
-
[57]
Jieming Zhu, Shilin He, Pinjia He, Jinyang Liu, and Michael R Lyu. 2023. Loghub: A large collection of system log datasets for ai-driven log analytics. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 355–366
2023
-
[58]
Jieming Zhu, Shilin He, Jinyang Liu, Pinjia He, Qi Xie, Zibin Zheng, and Michael R Lyu. 2019. Tools and benchmarks for automated log parsing. In2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE, 121–130
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.