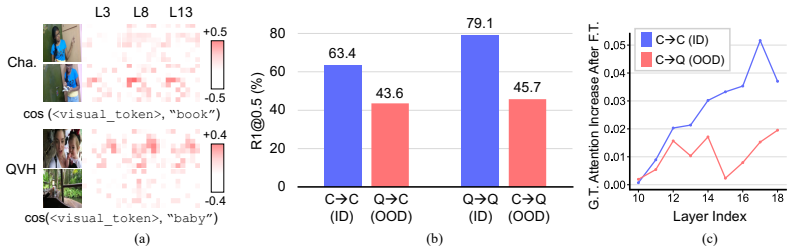
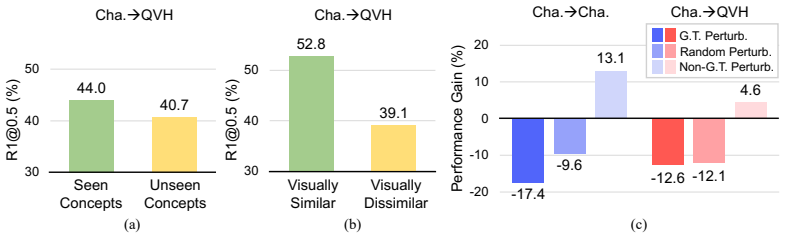
EVIDENT: Routing MLLM Adaptation through Entity-Grounded Visual Evidence for Cross-Domain Video Temporal Grounding
Pith reviewed 2026-06-29 22:25 UTC · model grok-4.3
The pith
Routing MLLM adaptation through entity-grounded visual evidence improves cross-domain video temporal grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
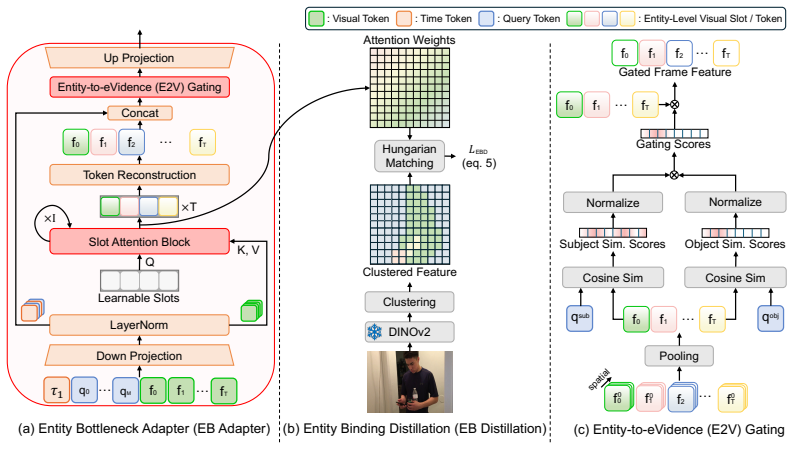
EVIDENT anchors temporal grounding in the inherent entity-attention of pre-trained MLLMs by routing VTG adaptation through explicit visual entity evidence, using an Entity Bottleneck Adapter to create compact entity-level slots, an Entity-Binding Distillation loss to instill objectness priors, and an Entity-to-eVidence gating mechanism to steer localization toward query-relevant entities, thereby enabling fine-tuning to rely on entity-grounded evidence rather than brittle dataset shortcuts.
What carries the argument
Entity Bottleneck Adapter that compresses dense visual tokens into compact entity-level slots, paired with Entity-Binding Distillation loss and Entity-to-eVidence gating to route adaptation through captured entities.
If this is right
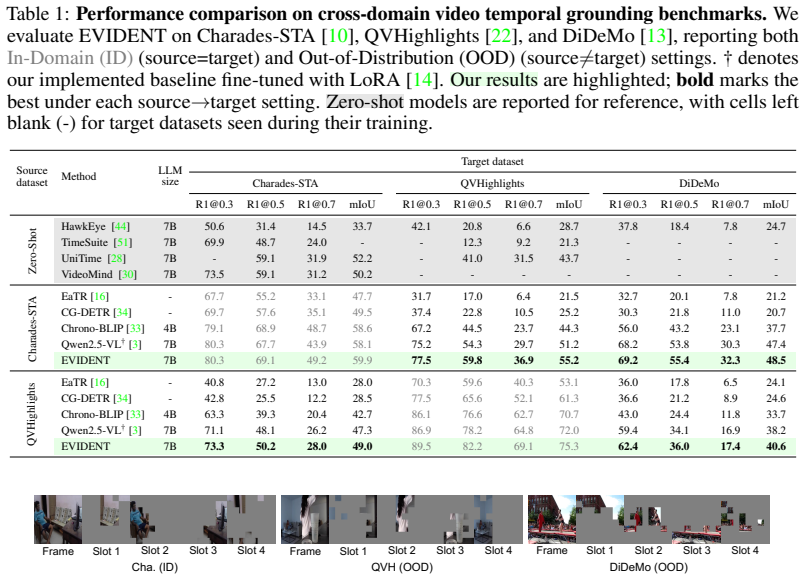
- EVIDENT raises out-of-domain robustness on cross-domain VTG benchmarks while matching in-domain performance.
- The approach adds only modest parameter overhead.
- Entity-level grounding functions as an inductive bias that supports generalizable temporal localization.
- Adaptation no longer depends on dataset shortcuts that fail under visual shift.
Where Pith is reading between the lines
- The same entity-routing idea could be tested on other multimodal tasks such as action recognition or video question answering where domain shift affects attention.
- If entity slots prove stable across more video styles, the method might reduce the need for large-scale domain-specific fine-tuning.
- Combining the entity bottleneck with other low-rank adapters might further lower the parameter cost.
Load-bearing premise
Visual domain shift is the main reason models lose the ability to couple temporal localization knowledge with their existing entity-attention, and explicit routing through entity evidence will overcome that.
What would settle it
A test set in which visual style is held constant across train and test but query concepts change, showing whether EVIDENT still improves over standard fine-tuning or whether the gain disappears when visual shift is removed.
Figures

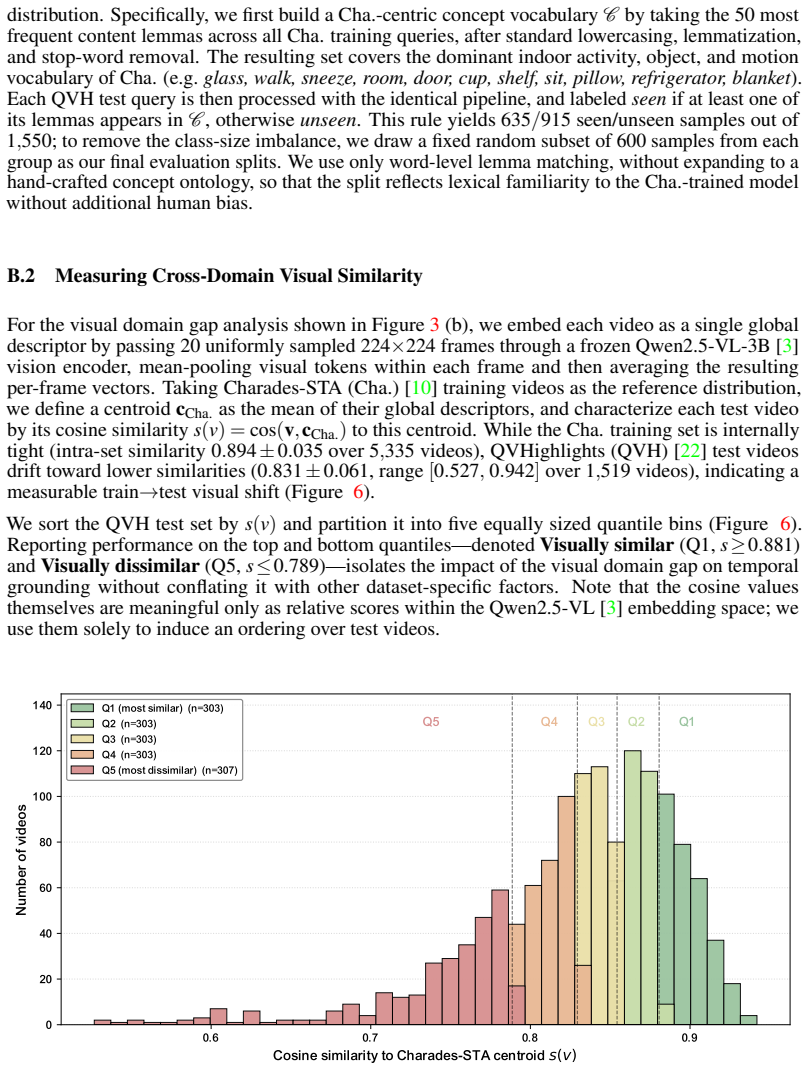

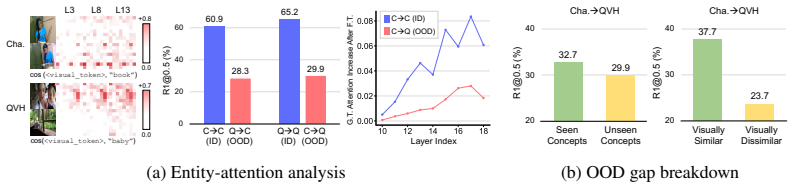



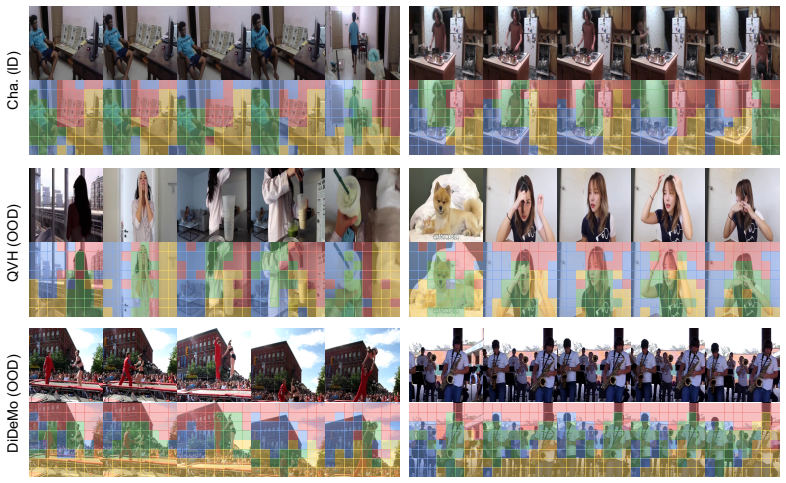
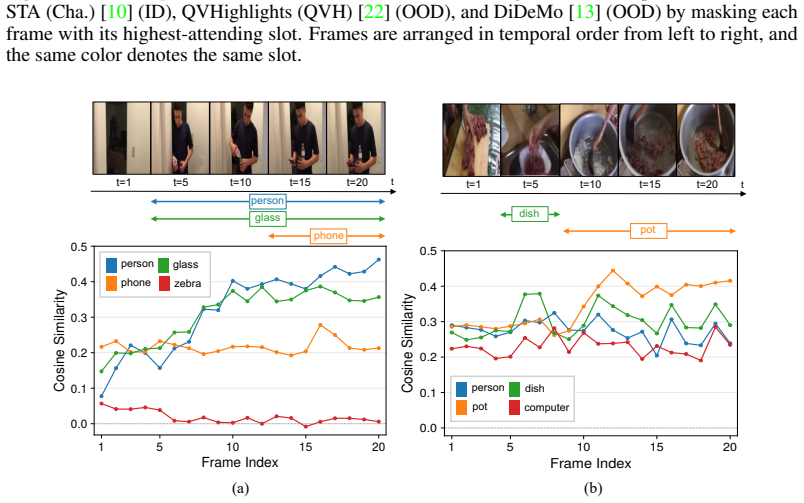
read the original abstract
Fine-tuning MLLMs for Video Temporal Grounding (VTG) often improves in-domain performance but degrades sharply under domain shift. In this work, we find that this failure is primarily driven not just by unseen query concepts, but by visual domain shift, which prevents the model from coupling its learned temporal localization knowledge with its inherent entity-attention capability. To address this, we introduce EVIDENT, a parameter-efficient adaptation framework that anchors temporal grounding in the inherent entity-attention of pre-trained MLLMs by routing VTG adaptation through explicit visual entity evidence. EVIDENT consists of three components: (i) an Entity Bottleneck Adapter that transforms dense visual tokens into compact entity-level slots, (ii) an Entity-Binding Distillation loss that instills objectness priors into the semantically unstructured MLLM visual space, guiding each slot to bind to a coherent entity, and (iii) an Entity-to-eVidence gating mechanism that leverages the captured entities as evidence, steering the model to localize moments containing query-relevant entities. Together, these components enable VTG fine-tuning to rely on entity-grounded evidence rather than brittle dataset shortcuts. Experiments on cross-domain VTG benchmarks show that EVIDENT consistently improves out-of-domain robustness while preserving competitive in-domain performance with modest parameter overhead. These results suggest that entity-level grounding is an effective inductive bias for generalizable temporal localization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-tuning MLLMs for Video Temporal Grounding (VTG) degrades under domain shift primarily due to visual domain shift blocking coupling of temporal localization knowledge with inherent entity-attention; it introduces EVIDENT, a parameter-efficient framework with an Entity Bottleneck Adapter (transforming dense tokens to entity slots), Entity-Binding Distillation loss (instilling objectness priors), and Entity-to-eVidence gating (steering localization via query-relevant entities) to enable entity-grounded adaptation, yielding improved out-of-domain robustness while preserving in-domain performance with modest overhead.
Significance. If the cross-domain gains hold with proper controls, the work establishes entity-level grounding as a practical inductive bias for generalizable temporal localization in MLLMs, directly targeting visual domain shift rather than query-concept novelty, with potential extension to other multimodal grounding tasks under distribution shift.
major comments (1)
- [Abstract] Abstract: the central claim of consistent out-of-domain improvement is asserted without any reported metrics, baselines, ablation tables, or error analysis, preventing verification of the experimental support for the entity-routing hypothesis.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. We address the single major comment below regarding the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of consistent out-of-domain improvement is asserted without any reported metrics, baselines, ablation tables, or error analysis, preventing verification of the experimental support for the entity-routing hypothesis.
Authors: We acknowledge that the abstract presents a high-level summary of the claims without embedding specific numerical metrics, baseline names, or table references, as is conventional for abstracts to remain concise. The full manuscript contains the requested experimental details, including cross-domain VTG benchmark results with quantitative comparisons, ablation studies on the three proposed components, and supporting analysis in the Experiments section. To strengthen verifiability directly in the abstract while preserving its brevity, we will revise it to include key quantitative out-of-domain gains (e.g., relative improvements over baselines) drawn from the reported tables. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents EVIDENT as an architectural framework with three explicitly described components (Entity Bottleneck Adapter, Entity-Binding Distillation loss, Entity-to-eVidence gating) that directly implement the stated inductive bias of entity-grounded routing. No equations, derivations, or parameter-fitting steps are shown that reduce the claimed cross-domain gains to quantities defined by the method itself. The central claim rests on empirical out-of-domain robustness results, which remain externally falsifiable. No self-citation chains or uniqueness theorems are invoked as load-bearing premises in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Slot-guided adaptation of pre-trained diffusion models for object-centric learning and compositional generation
Adil Kaan Akan and Yücel Yemez. Slot-guided adaptation of pre-trained diffusion models for object-centric learning and compositional generation. InICLR, 2025. 7
2025
-
[2]
DEVIAS: Learning disentangled video representations of action and scene
Kyungho Bae, Geo Ahn, Youngrae Kim, and Jinwoo Choi. DEVIAS: Learning disentangled video representations of action and scene. InECCV, 2024. 13
2024
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Learning sample importance for cross-scenario video temporal grounding
Peijun Bao and Yadong Mu. Learning sample importance for cross-scenario video temporal grounding. In ICMR, 2022. 2
2022
-
[5]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InECCV, 2020. 13
2020
-
[6]
Towards a complete benchmark on video moment localization
Jinyeong Chae, Donghwa Kim, Kwanseok Kim, Doyeon Lee, Sangho Lee, Seongsu Ha, Jonghwan Mun, Wooyoung Kang, Byungseok Roh, and Joonseok Lee. Towards a complete benchmark on video moment localization. InAISTATS, 2024. 2, 13
2024
-
[7]
Slot-MLLM: Object-Centric Visual Tokenization for Multimodal LLM
Donghwan Chi, Hyomin Kim, Yoonjin Oh, Yongjin Kim, Donghoon Lee, Daejin Jo, Jongmin Kim, Junyeob Baek, Sungjin Ahn, and Sungwoong Kim. Slot-MLLM: Object-centric visual tokenization for multimodal llm.arXiv preprint arXiv:2505.17726, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Learning phrase representations using RNN encoder–decoder for statistical machine translation
Kyunghyun Cho, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder–decoder for statistical machine translation. InEMNLP, 2014. 6
2014
-
[9]
Why can’t i dance in the mall? learning to mitigate scene bias in action recognition
Jinwoo Choi, Chen Gao, Joseph CE Messou, and Jia-Bin Huang. Why can’t i dance in the mall? learning to mitigate scene bias in action recognition. InNeurIPS, 2019. 13 10
2019
-
[10]
Tall: Temporal activity localization via language query
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. Tall: Temporal activity localization via language query. InICCV, 2017. 3, 4, 8, 9, 13, 14, 15, 16, 17, 18, 20, 21
2017
-
[11]
TRACE: Temporal grounding video llm via causal event modeling.arXiv preprint arXiv:2410.05643, 2024
Yongxin Guo, Jingyu Liu, Mingda Li, Xiaoying Tang, Qingbin Liu, and Xi Chen. TRACE: Temporal grounding video llm via causal event modeling.arXiv preprint arXiv:2410.05643, 2024. 2, 3
-
[12]
Can shuffling video benefit temporal bias problem: A novel training framework for temporal grounding
Jiachang Hao, Haifeng Sun, Pengfei Ren, Jingyu Wang, Qi Qi, and Jianxin Liao. Can shuffling video benefit temporal bias problem: A novel training framework for temporal grounding. InECCV, 2022. 2, 13
2022
-
[13]
Localizing moments in video with natural language
Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing moments in video with natural language. InICCV, 2017. 3, 8, 9, 17, 18, 20, 21
2017
-
[14]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InICLR, 2022. 7, 8, 9, 10, 18, 19
2022
-
[15]
Vtimellm: Empower llm to grasp video moments
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. Vtimellm: Empower llm to grasp video moments. InCVPR, 2024. 2, 3
2024
-
[16]
Knowing where to focus: Event-aware transformer for video grounding
Jinhyun Jang, Jungin Park, Jin Kim, Hyeongjun Kwon, and Kwanghoon Sohn. Knowing where to focus: Event-aware transformer for video grounding. InICCV, 2023. 8, 9, 13
2023
-
[17]
Transferable video moment localization by moment-guided query prompting
Hao Jiang, Yang Yizhang, and Yadong Mu. Transferable video moment localization by moment-guided query prompting. InAAAI, 2024. 2
2024
-
[18]
Map the flow: Revealing hidden pathways of information in videollms
Minji Kim, Taekyung Kim, and Bohyung Han. Map the flow: Revealing hidden pathways of information in videollms. InICLR, 2026. 4, 7, 19
2026
-
[19]
Conditional object-centric learning from video
Thomas Kipf, Gamaleldin F Elsayed, Aravindh Mahendran, Austin Stone, Sara Sabour, Georg Heigold, Rico Jonschkowski, Alexey Dosovitskiy, and Klaus Greff. Conditional object-centric learning from video. InICLR, 2022. 3
2022
-
[20]
The hungarian method for the assignment problem.Naval research logistics quarterly, 2 (1-2):83–97, 1955
Harold W Kuhn. The hungarian method for the assignment problem.Naval research logistics quarterly, 2 (1-2):83–97, 1955. 7
1955
-
[21]
Curriculum multi-negative augmentation for debiased video grounding
Xiaohan Lan, Yitian Yuan, Hong Chen, Xin Wang, Zequn Jie, Lin Ma, Zhi Wang, and Wenwu Zhu. Curriculum multi-negative augmentation for debiased video grounding. InAAAI, 2023. 13
2023
-
[22]
Detecting moments and highlights in videos via natural language queries
Jie Lei, Tamara L Berg, and Mohit Bansal. Detecting moments and highlights in videos via natural language queries. InNeurIPS, 2021. 2, 3, 4, 8, 9, 13, 14, 15, 16, 17, 18, 20, 21
2021
-
[23]
Revealing single frame bias for video-and-language learning
Jie Lei, Tamara Berg, and Mohit Bansal. Revealing single frame bias for video-and-language learning. In ACL, 2023. 13
2023
-
[24]
CORE: Compact object-centric representations as a new paradigm for token merging in lvlms
Jingyu Lei, Gaoang Wang, and Der-Horng Lee. CORE: Compact object-centric representations as a new paradigm for token merging in lvlms. InCVPR, 2026. 2, 3
2026
-
[25]
Compositional temporal grounding with structured variational cross-graph correspondence learning
Juncheng Li, Junlin Xie, Long Qian, Linchao Zhu, Siliang Tang, Fei Wu, Yi Yang, Yueting Zhuang, and Xin Eric Wang. Compositional temporal grounding with structured variational cross-graph correspondence learning. InCVPR, 2022. 2
2022
-
[26]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InICML, 2023. 8
2023
-
[27]
Resound: Towards action recognition without representation bias
Yingwei Li, Yi Li, and Nuno Vasconcelos. Resound: Towards action recognition without representation bias. InECCV, 2018. 13
2018
-
[28]
Universal video temporal grounding with generative multi-modal large language models
Zeqian Li, Shangzhe Di, Zhonghua Zhai, Weilin Huang, Yanfeng Wang, and Weidi Xie. Universal video temporal grounding with generative multi-modal large language models. InNeurIPS, 2025. 3, 5, 8, 9
2025
-
[29]
Univtg: Towards unified video-language temporal grounding
Kevin Qinghong Lin, Pengchuan Zhang, Joya Chen, Shraman Pramanick, Difei Gao, Alex Jinpeng Wang, Rui Yan, and Mike Zheng Shou. Univtg: Towards unified video-language temporal grounding. InICCV,
-
[30]
VideoMind: A chain-of-lora agent for temporal-grounded video reasoning
Ye Liu, Kevin Qinghong Lin, Chang Wen Chen, and Mike Zheng Shou. VideoMind: A chain-of-lora agent for temporal-grounded video reasoning. InICLR, 2026. 3, 8, 9
2026
-
[31]
Object-centric learning with slot attention
Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. Object-centric learning with slot attention. InNeurIPS,
-
[32]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019. 18 11
2019
-
[33]
Chrono: A simple blueprint for representing time in mllms
Boris Meinardus, Hector Rodriguez, Anil Batra, Anna Rohrbach, and Marcus Rohrbach. Chrono: A simple blueprint for representing time in mllms. InICCVW, 2025. 2, 3, 5, 8, 9, 18
2025
-
[34]
WonJun Moon, Sangeek Hyun, SuBeen Lee, and Jae-Pil Heo. Correlation-guided query-dependency calibration for video temporal grounding.arXiv preprint arXiv:2311.08835, 2023. 8, 9, 13
-
[35]
Query-dependent video representation for moment retrieval and highlight detection
WonJun Moon, Sangeek Hyun, SangUk Park, Dongchan Park, and Jae-Pil Heo. Query-dependent video representation for moment retrieval and highlight detection. InCVPR, 2023. 2, 13
2023
-
[36]
Interventional video grounding with dual contrastive learning
Guoshun Nan, Rui Qiao, Yao Xiao, Jun Liu, Sicong Leng, Hao Zhang, and Wei Lu. Interventional video grounding with dual contrastive learning. InCVPR, 2021. 13
2021
-
[37]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Laba...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Mayu Otani, Yuta Nakashima, Esa Rahtu, and Janne Heikkilä. Uncovering hidden challenges in query- based video moment retrieval.arXiv preprint arXiv:2009.00325, 2020. 2, 13
-
[39]
Bias-conflict sample synthesis and adversarial removal debias strategy for temporal sentence grounding in video
Zhaobo Qi, Yibo Yuan, Xiaowen Ruan, ShuHui Wang, Weigang Zhang, and QingMing Huan. Bias-conflict sample synthesis and adversarial removal debias strategy for temporal sentence grounding in video. In AAAI, 2024. 2, 13
2024
-
[40]
Timechat: A time-sensitive multimodal large language model for long video understanding
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. Timechat: A time-sensitive multimodal large language model for long video understanding. InCVPR, 2024. 2, 3
2024
-
[41]
Bridging the gap to real-world object-centric learning
Maximilian Seitzer, Max Horn, Andrii Zadaianchuk, Dominik Zietlow, Tianjun Xiao, Carl-Johann Simon- Gabriel, Tong He, Zheng Zhang, Bernhard Schölkopf, Thomas Brox, et al. Bridging the gap to real-world object-centric learning. InICLR, 2023. 3, 7
2023
-
[42]
Tr-detr: Task-reciprocal transformer for joint moment retrieval and highlight detection
Hao Sun, Mingyao Zhou, Wenjing Chen, and Wei Xie. Tr-detr: Task-reciprocal transformer for joint moment retrieval and highlight detection. InAAAI, 2024. 2
2024
-
[43]
Time-R1: Post-training large vision language model for temporal video grounding
Ye Wang, Ziheng Wang, Boshen Xu, Yang Du, Kejun Lin, Zihan Xiao, Zihao Yue, Jianzhong Ju, Liang Zhang, Dingyi Yang, Xiangnan Fang, Zewen He, Zhenbo Luo, Wenxuan Wang, Junqi Lin, Jian Luan, and Qin Jin. Time-R1: Post-training large vision language model for temporal video grounding. InNeurIPS,
-
[44]
HawkEye: Training video-text llms for grounding text in videos.arXiv preprint arXiv:2403.10228, 2024
Yueqian Wang, Xiaojun Meng, Jianxin Liang, Yuxuan Wang, Qun Liu, and Dongyan Zhao. HawkEye: Training video-text llms for grounding text in videos.arXiv preprint arXiv:2403.10228, 2024. 2, 8, 9
-
[45]
Slotformer: Unsupervised visual dynamics simulation with object-centric models
Ziyi Wu, Nikita Dvornik, Klaus Greff, Thomas Kipf, and Animesh Garg. Slotformer: Unsupervised visual dynamics simulation with object-centric models. InICLR, 2023. 3
2023
-
[46]
Slot-VLM: Object-event slots for video-language modeling
Jiaqi Xu, Cuiling Lan, Wenxuan Xie, Xuejin Chen, and Yan Lu. Slot-VLM: Object-event slots for video-language modeling. InNeurIPS, 2024. 2, 3
2024
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 7, 16, 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
AIM: Adapting image models for efficient video understanding
Taojiannan Yang, Yi Zhu, Yusheng Xie, Aston Zhang, Chen Chen, and Mu Li. AIM: Adapting image models for efficient video understanding. InICLR, 2023. 7
2023
-
[49]
Deconfounded video moment retrieval with causal intervention
Xun Yang, Fuli Feng, Wei Ji, Meng Wang, and Tat-Seng Chua. Deconfounded video moment retrieval with causal intervention. InACM SIGIR, 2021. 13
2021
-
[50]
A closer look at temporal sentence grounding in videos: Dataset and metric
Yitian Yuan, Xiaohan Lan, Xin Wang, Long Chen, Zhi Wang, and Wenwu Zhu. A closer look at temporal sentence grounding in videos: Dataset and metric. InACM MM Workshop, 2021. 13
2021
-
[51]
TimeSuite: Improving MLLMs for long video understanding via grounded tuning
Xiangyu Zeng, Kunchang Li, Chenting Wang, Xinhao Li, Tianxiang Jiang, Ziang Yan, Songze Li, Yansong Shi, Zhengrong Yue, Yi Wang, Yali Wang, Yu Qiao, and Limin Wang. TimeSuite: Improving MLLMs for long video understanding via grounded tuning. InICLR, 2025. 2, 3, 8, 9
2025
-
[52]
Timelens: Rethinking video temporal grounding with multimodal llms
Jun Zhang, Teng Wang, Yuying Ge, Yixiao Ge, Xinhao Li, Ying Shan, and Limin Wang. Timelens: Rethinking video temporal grounding with multimodal llms. InCVPR, 2026. 5
2026
-
[53]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Yuchen Duan, Hao Tian, Weijie Su, Jie Shao, et al. InternVL3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 3, 4, 15, 16 12 Appendix In this appendix, we provide extended related work, comprehensive analyses...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Return a JSON list containing up to 2 strings
-
[55]
Subject:
Each string MUST start with"Subject:"or"Object:"
-
[56]
If the Subject is interacting with a physical item, you MUST extract it as an Object
-
[57]
Ignore verbs, scenes, abstract concepts, and meta-descriptions
-
[58]
Keep the nouns extremely concise (1–2 words)
-
[59]
a person opens the refrigerator in the kitchen
Return ONLY a valid JSON list. Examples: Query: “a person opens the refrigerator in the kitchen” JSON list:["Subject: person", "Object: refrigerator"] Query: “The girl dances around the room.” JSON list:["Subject: girl"] Query: {query} JSON list: Assistant JSON list of extracted concepts Figure 9: Zero-shot prompt used with Qwen3-4B-Instruct-2507 [47] for...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.