Looped Diffusion Language Models
Pith reviewed 2026-06-29 23:10 UTC · model grok-4.3
The pith
Selectively looping early-middle transformer layers in masked diffusion models yields depth scaling without added parameters and matches performance with up to 3.3 times fewer training FLOPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
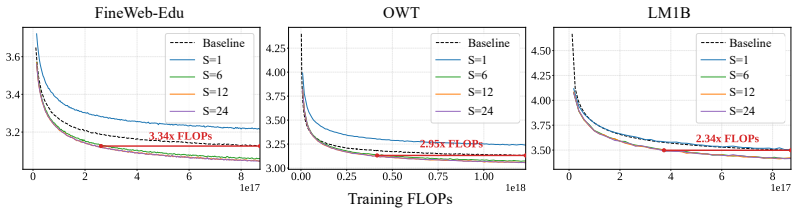
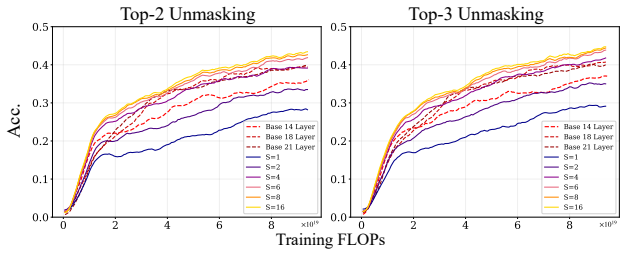
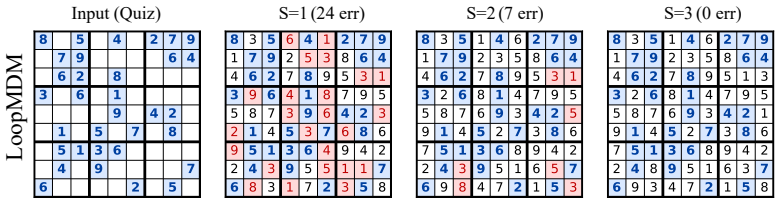
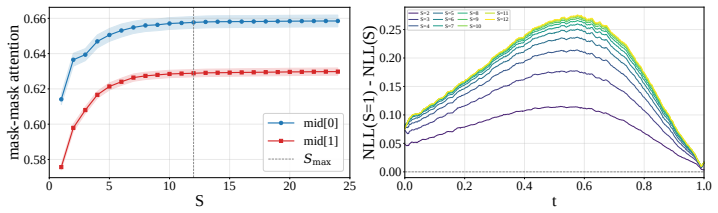
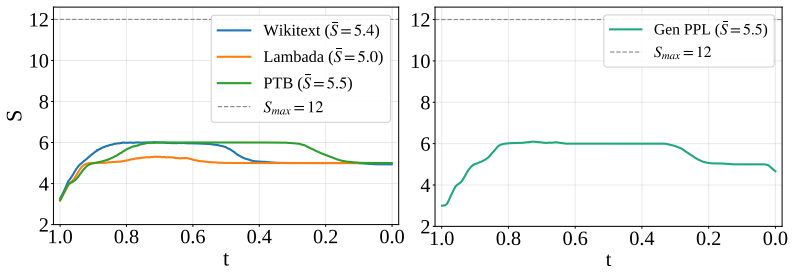
LoopMDM selectively loops the early-middle transformer layers of masked diffusion models. At training time the repeated application of those layers creates a depth-scaling effect with no extra parameters; at inference time the loop count can be increased or adapted on the fly. The resulting models match the performance of same-size non-looped MDMs with up to 3.3 times fewer training FLOPs, surpass them on reasoning benchmarks including an 8.5-point gain on GSM8K, and outperform deeper non-looped MDMs trained with comparable per-step compute. Attention analysis indicates that the looping promotes interactions among masked positions.
What carries the argument
Selective looping of early-middle transformer layers inside the MDM architecture, applied repeatedly during the forward pass to produce depth scaling.
If this is right
- LoopMDM reaches the same pre-training loss as a standard MDM while consuming up to 3.3 times fewer total training FLOPs.
- Final models outperform same-size MDMs on multiple reasoning benchmarks, with gains reaching 8.5 points on GSM8K.
- Increasing the number of loops at inference time scales compute flexibly without retraining.
- Adaptive loop counts during sampling improve compute efficiency while preserving accuracy.
- The approach outperforms naive increases in transformer depth when total per-step compute is held constant.
Where Pith is reading between the lines
- The same selective-loop pattern could be tested on autoregressive transformers or other diffusion objectives to check whether the masked-position interaction benefit is specific to MDMs.
- If the attention-map explanation holds, similar gains might appear in any masked modeling task where early layers primarily handle local context.
- Because loop count is adjustable after training, the method supplies a practical knob for trading latency against quality on a single set of weights.
Load-bearing premise
The observed gains arise specifically from looping the early-middle layers rather than from any unstated differences in training procedure, data, or hyperparameter choices.
What would settle it
Train a non-looped MDM using identical data, optimizer schedule, and every other hyperparameter as the LoopMDM run; if its final performance on GSM8K and training-FLOP efficiency match or exceed the looped version, the benefit cannot be attributed to the looping itself.
Figures



read the original abstract
Masked diffusion models (MDMs) have emerged as a promising alternative to autoregressive models for language modeling, yet the effective design of transformer architectures for MDMs remains underexplored. In this paper, we show that selectively looping the early-middle transformer layers significantly improves both training efficiency and model performance in MDMs. We call this approach LoopMDM(Looped Masked Diffusion Model), which brings two key benefits: looping layers at training-time yields a depth-scaling effect without adding parameters, while varying the number of loops at inference-time enables flexible compute scaling. Despite the simplicity, the results are striking: across multiple pre-training corpora, LoopMDM matches the performance of same-size MDMs with up to 3.3 fewer training FLOPs, while its final performance outperforms them on various reasoning benchmarks, including up to 8.5 points on GSM8K. It even surpasses deeper non-looped MDMs trained with comparable per-step compute, indicating that selective looping is more effective than naive depth scaling. Furthermore, LoopMDM can scale inference-time compute by increasing the number of loops. Adaptively adjusting the number of loops throughout the sampling process further yields additional gains in compute efficiency while maintaining performance. Lastly, with attention analysis, we provide evidence that looping is effective in MDMs by promoting interactions among masked positions. Our code and weights will be publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LoopMDM, which selectively loops early-middle transformer layers in masked diffusion models (MDMs). This is claimed to provide a depth-scaling effect without added parameters at training time and flexible compute scaling at inference by varying loop count. Across pre-training corpora, it matches same-size MDMs with up to 3.3x fewer training FLOPs, outperforms on reasoning benchmarks (up to +8.5 on GSM8K), surpasses deeper non-looped MDMs at equal per-step compute, enables further gains via adaptive looping, and is supported by attention analysis indicating promoted masked-position interactions.
Significance. If the gains are attributable to selective looping under controlled conditions, the method would offer a simple, parameter-efficient route to improved training efficiency and inference flexibility in MDMs, outperforming naive depth scaling and enabling adaptive compute.
major comments (2)
- [Abstract] Abstract: The abstract reports concrete gains versus same-size and deeper baselines, but provides no details on experimental controls, statistical significance, or exact training configurations, leaving the central claim only partially supported from available text.
- [Abstract] Abstract: The attention analysis is presented as supporting evidence for promoted masked-position interactions, but remains post-hoc correlation without an ablation that severs the loop while preserving the observed attention pattern.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below. The manuscript provides full experimental details in the body, but we agree the abstract can be clarified for better support of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports concrete gains versus same-size and deeper baselines, but provides no details on experimental controls, statistical significance, or exact training configurations, leaving the central claim only partially supported from available text.
Authors: The abstract is a concise summary constrained by length limits. Full details on experimental controls (model sizes, training corpora, hyperparameters, and per-step compute matching), statistical significance (multiple random seeds with standard deviations), and configurations appear in Section 3 and the results tables. The central claims are supported by those sections and tables. We will revise the abstract to include a short clause noting 'under matched training configurations and multiple runs' to address this. revision: partial
-
Referee: [Abstract] Abstract: The attention analysis is presented as supporting evidence for promoted masked-position interactions, but remains post-hoc correlation without an ablation that severs the loop while preserving the observed attention pattern.
Authors: We acknowledge the analysis in Section 4.3 is correlational. The primary evidence for the method's effectiveness comes from controlled performance comparisons (looped vs. non-looped models at equal parameters and compute). We will add explicit discussion of this limitation and note that a targeted ablation preserving the attention pattern while removing loops is non-trivial to design, as looping directly modifies the computation graph. This will be framed as a direction for future work rather than claiming full causality from attention alone. revision: partial
Circularity Check
No significant circularity; results are empirical comparisons
full rationale
The paper introduces LoopMDM as an architectural modification to masked diffusion models and supports its claims exclusively through direct empirical benchmarks against non-looped baselines on pre-training corpora and downstream tasks such as GSM8K. No equations, uniqueness theorems, fitted parameters relabeled as predictions, or self-citation chains appear in the derivation of the performance gains; the attention analysis is presented as post-hoc supporting evidence rather than a load-bearing logical step. The central assertions therefore rest on falsifiable experimental outcomes rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of loops
Reference graph
Works this paper leans on
-
[1]
Path independent equilibrium models can better exploit test-time computation.Advances in Neural Information Processing Systems, 35:7796–7809, 2022
Cem Anil, Ashwini Pokle, Kaiqu Liang, Johannes Treutlein, Yuhuai Wu, Shaojie Bai, J Zico Kolter, and Roger B Grosse. Path independent equilibrium models can better exploit test-time computation.Advances in Neural Information Processing Systems, 35:7796–7809, 2022
2022
-
[2]
Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
2021
-
[3]
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, et al. Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation.arXiv preprint arXiv:2507.10524, 2025
-
[4]
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, et al. Llada2. 0: Scaling up diffusion language models to 100b.arXiv preprint arXiv:2512.15745, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
$S^3$: Stratified Scaling Search for Test-Time in Diffusion Language Models
Ahsan Bilal, Muhammad Ahmed Mohsin, Muhammad Umer, Asad Aali, Muhammad Usman Khanzada, Muhammad Usman Rafique, Zihao He, Emily Fox, and Dean F Hougen. s3: Strati- fied scaling search for test-time in diffusion language models.arXiv preprint arXiv:2604.06260, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Piqa: Reasoning about phys- ical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about phys- ical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
2020
-
[7]
Chen-Hao Chao, Wei-Fang Sun, Hanwen Liang, Chun-Yi Lee, and Rahul G Krishnan. Be- yond masked and unmasked: Discrete diffusion models via partial masking.arXiv preprint arXiv:2505.18495, 2025
-
[8]
One billion word benchmark for measuring progress in statistical lan- guage modeling
Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One billion word benchmark for measuring progress in statistical lan- guage modeling. InProceedings of the 15th Annual Conference of the International Speech Communication Association (INTERSPEECH), pages 615–621, 2014
2014
-
[9]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), ...
2019
-
[10]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
A discourse-aware attention model for abstractive summarization of long documents
Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. A discourse-aware attention model for abstractive summarization of long documents. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers...
2018
-
[13]
Recurrent stacking of layers for compact neural machine translation models
Raj Dabre and Atsushi Fujita. Recurrent stacking of layers for compact neural machine translation models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6292–6299, 2019. 10
2019
-
[14]
Inference-Time Scaling of Diffusion Language Models via Trajectory Refinement
Meihua Dang, Jiaqi Han, Minkai Xu, Kai Xu, Akash Srivastava, and Stefano Ermon. Inference- time scaling of diffusion language models with particle gibbs sampling.arXiv preprint arXiv:2507.08390, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Uni- versal transformers.arXiv preprint arXiv:1807.03819, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460, 2023
Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, and Stuart Shieber. Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460, 2023
-
[17]
Partition generative modeling: Masked modeling without masks.arXiv preprint arXiv:2505.18883, 2025
Justin Deschenaux, Lan Tran, and Caglar Gulcehre. Partition generative modeling: Masked modeling without masks.arXiv preprint arXiv:2505.18883, 2025
-
[18]
Looped transformers for length generalization.arXiv preprint arXiv:2409.15647, 2024
Ying Fan, Yilun Du, Kannan Ramchandran, and Kangwook Lee. Looped transformers for length generalization.arXiv preprint arXiv:2409.15647, 2024
-
[19]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartold- son, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Looped transformers as programmable computers
Angeliki Giannou, Shashank Rajput, Jy-yong Sohn, Kangwook Lee, Jason D Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers. InInternational Conference on Machine Learning, pages 11398–11442. PMLR, 2023
2023
-
[21]
Openwebtext corpus
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus. http://Skylion007.github.io/ OpenWebTextCorpus, 2019
2019
-
[22]
Diffucoder: Understanding and improving masked diffusion models for code generation
Shansan Gong, Ruixiang ZHANG, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, and Yizhe Zhang. Diffucoder: Understanding and improving masked diffusion models for code generation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[23]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[24]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Reasoning with latent tokens in diffusion language models.arXiv preprint arXiv:2602.03769, 2026
Andre He, Sean Welleck, and Daniel Fried. Reasoning with latent tokens in diffusion language models.arXiv preprint arXiv:2602.03769, 2026
-
[26]
Diffusionbert: Improving generative masked language models with diffusion models
Zhengfu He, Tianxiang Sun, Qiong Tang, Kuanning Wang, Xuan-Jing Huang, and Xipeng Qiu. Diffusionbert: Improving generative masked language models with diffusion models. In Proceedings of the 61st annual meeting of the association for computational linguistics (ACL), volume 1, pages 4521–4534, 2023
2023
-
[27]
Unifying Masked Diffusion Models with Various Generation Orders and Beyond
Chunsan Hong, Sanghyun Lee, and Jong Chul Ye. Unifying masked diffusion models with various generation orders and beyond.arXiv preprint arXiv:2602.02112, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Argmax flows and multinomial diffusion: Learning categorical distributions
Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions. volume 34, pages 12454– 12465, 2021
2021
-
[29]
Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413,
Daniel Israel, Guy Van den Broeck, and Aditya Grover. Accelerating diffusion llms via adaptive parallel decoding.arXiv preprint arXiv:2506.00413, 2025
-
[30]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[31]
Stop Training for the Worst: Progressive Unmasking Accelerates Masked Diffusion Training
Jaeyeon Kim, Jonathan Geuter, David Alvarez-Melis, Sham Kakade, and Sitan Chen. Stop training for the worst: Progressive unmasking accelerates masked diffusion training.arXiv preprint arXiv:2602.10314, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Jaeyeon Kim, Seunggeun Kim, Taekyun Lee, David Z
Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. Train for the worst, plan for the best: Understanding token ordering in masked diffusions.arXiv preprint arXiv:2502.06768, 2025
-
[33]
Race: Large-scale reading comprehension dataset from examinations
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. Race: Large-scale reading comprehension dataset from examinations. InProceedings of the 2017 conference on empirical methods in natural language processing, pages 785–794, 2017
2017
-
[34]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations.arXiv preprint arXiv:1909.11942, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[35]
Sanghyun Lee, Seungryong Kim, Jongho Park, and Dongmin Park. Lookahead unmasking elicits accurate decoding in diffusion language models.arXiv preprint arXiv:2511.05563, 2025
-
[36]
Sanghyun Lee, Sunwoo Kim, Seungryong Kim, Jongho Park, and Dongmin Park. Effective test- time scaling of discrete diffusion through iterative refinement.arXiv preprint arXiv:2511.05562, 2025
-
[37]
Tinygsm: achieving> 80% on gsm8k with small language models
Bingbin Liu, Sebastien Bubeck, Ronen Eldan, Janardhan Kulkarni, Yuanzhi Li, Anh Nguyen, Rachel Ward, and Yi Zhang. Tinygsm: achieving> 80% on gsm8k with small language models. arXiv preprint arXiv:2312.09241, 2023
-
[38]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. 2024
2024
-
[39]
Plan for Speed: Dilated Scheduling for Masked Diffusion Language Models
Omer Luxembourg, Haim Permuter, and Eliya Nachmani. Plan for speed: Dilated scheduling for masked diffusion language models.arXiv preprint arXiv:2506.19037, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Building a large annotated corpus of english: The penn treebank.Computational linguistics, 19(2):313–330, 1993
Mitch Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of english: The penn treebank.Computational linguistics, 19(2):313–330, 1993
1993
-
[41]
Sean McLeish, Ang Li, John Kirchenbauer, Dayal Singh Kalra, Brian R Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum. Teach- ing pretrained language models to think deeper with retrofitted recurrence.arXiv preprint arXiv:2511.07384, 2025
-
[42]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[43]
Exact expressive power of transformers with padding
William Merrill and Ashish Sabharwal. Exact expressive power of transformers with padding. arXiv preprint arXiv:2505.18948, 2025
-
[44]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2381–2391, 2018
2018
-
[45]
Amirkeivan Mohtashami, Matteo Pagliardini, and Martin Jaggi. Cotformer: A chain-of- thought driven architecture with budget-adaptive computation cost at inference.arXiv preprint arXiv:2310.10845, 2023
-
[46]
Scaling up masked diffusion models on text.arXiv preprint arXiv:2410.18514, 2024
Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li. Scaling up masked diffusion models on text.arXiv preprint arXiv:2410.18514, 2024
-
[47]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. 2025
2025
-
[48]
Your absorbing discrete diffusion secretly models the conditional distributions of clean data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. 2025. 12
2025
-
[49]
The lambada dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc-Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset: Word prediction requiring a broad discourse context. InProceedings of the 54th annual meeting of the association for computational linguistics (volume 1: Long papers), pages 1525–...
2016
-
[50]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. pages 4195– 4205, 2023
2023
-
[51]
The fineweb datasets: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems, 37:30811–30849, 2024
Guilherme Penedo, Hynek Kydlíˇcek, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, Thomas Wolf, et al. The fineweb datasets: Decanting the web for the finest text data at scale.Advances in Neural Information Processing Systems, 37:30811–30849, 2024
2024
-
[52]
Path planning for masked diffusion model sampling.arXiv preprint arXiv:2502.03540, 2025
Fred Zhangzhi Peng, Zachary Bezemek, Sawan Patel, Jarrid Rector-Brooks, Sherwood Yao, Avishek Joey Bose, Alexander Tong, and Pranam Chatterjee. Path planning for masked diffusion model sampling.arXiv preprint arXiv:2502.03540, 2025
-
[53]
Fred Zhangzhi Peng, Zachary Bezemek, Jarrid Rector-Brooks, Shuibai Zhang, Anru R Zhang, Michael Bronstein, Alexander Tong, and Avishek Joey Bose. Planner aware path learning in diffusion language models training.arXiv preprint arXiv:2509.23405, 2025
-
[54]
Let’s think dot by dot: Hidden computation in transformer language models
Jacob Pfau, William Merrill, and Samuel R Bowman. Let’s think dot by dot: Hidden computation in transformer language models. InFirst Conference on Language Modeling, 2024
2024
-
[55]
Parcae: Scaling Laws For Stable Looped Language Models
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y Fu. Parcae: Scaling laws for stable looped language models.arXiv preprint arXiv:2604.12946, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Language models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019
2019
-
[57]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
2020
-
[58]
On the constant-depth complexity of k-clique
Benjamin Rossman. On the constant-depth complexity of k-clique. InProceedings of the fortieth annual ACM symposium on Theory of computing, pages 721–730, 2008
2008
-
[59]
Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
Subham S Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
2024
-
[60]
The diffusion duality
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin Chiu, and V olodymyr Kuleshov. The diffusion duality. 2025
2025
-
[61]
Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
2021
-
[62]
Social iqa: Commonsense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Commonsense reasoning about social interactions. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 4463–4473, 2019
2019
-
[63]
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J Reddi. Reasoning with latent thoughts: On the power of looped transformers.arXiv preprint arXiv:2502.17416, 2025
-
[64]
How Much Is One Recurrence Worth? Iso-Depth Scaling Laws for Looped Language Models
Kristian Schwethelm, Daniel Rueckert, and Georgios Kaissis. How much is one recurrence worth? iso-depth scaling laws for looped language models.arXiv preprint arXiv:2604.21106, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Simplified and generalized masked diffusion for discrete data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data. volume 37, pages 103131–103167, 2024. 13
2024
-
[66]
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, et al. Seed diffusion: A large-scale diffusion language model with high-speed inference.arXiv preprint arXiv:2508.02193, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
On the Reasoning Abilities of Masked Diffusion Language Models
Anej Svete and Ashish Sabharwal. On the reasoning abilities of masked diffusion language models.arXiv preprint arXiv:2510.13117, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Lessons on parameter sharing across layers in transformers
Sho Takase and Shun Kiyono. Lessons on parameter sharing across layers in transformers. In Proceedings of The Fourth Workshop on Simple and Efficient Natural Language Processing (SustaiNLP), pages 78–90, 2023
2023
-
[69]
Remasking discrete diffusion models with inference-time scaling.arXiv preprint arXiv:2503.00307,
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Remasking discrete diffusion models with inference-time scaling.arXiv preprint arXiv:2503.00307, 2025
-
[70]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[71]
Dream-coder 7b: An open diffusion language model for code, 2025
Zhihui Xie, Jiacheng Ye, Lin Zheng, Jiahui Gao, Jingwei Dong, Zirui Wu, Xueliang Zhao, Shansan Gong, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream-coder 7b: An open diffusion language model for code, 2025
2025
-
[72]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2 technical report, 2024a.URL https://arxiv. org/abs/2407.10671, 6, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[73]
Improving Sampling for Masked Diffusion Models via Information Gain
Kaisen Yang, Jayden Teoh, Kaicheng Yang, Yitong Zhang, and Alex Lamb. Improving sampling for masked diffusion models via information gain.arXiv preprint arXiv:2602.18176, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[74]
Looped Transformers are Better at Learning Learning Algorithms.arXiv, 2023
Liu Yang, Kangwook Lee, Robert Nowak, and Dimitris Papailiopoulos. Looped transformers are better at learning learning algorithms.arXiv preprint arXiv:2311.12424, 2023
-
[75]
Jiacheng Ye, Jiahui Gao, Shansan Gong, Lin Zheng, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Beyond autoregression: Discrete diffusion for complex reasoning and planning.arXiv preprint arXiv:2410.14157, 2024
-
[76]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
2019
-
[78]
Core: Context-robust remasking for diffusion language models.arXiv preprint arXiv:2602.04096, 2026
Kevin Zhai, Sabbir Mollah, Zhenyi Wang, and Mubarak Shah. Core: Context-robust remasking for diffusion language models.arXiv preprint arXiv:2602.04096, 2026
-
[79]
Character-level convolutional networks for text classification.Advances in neural information processing systems, 28, 2015
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification.Advances in neural information processing systems, 28, 2015
2015
-
[80]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models.arXiv preprint arXiv:2505.19223, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.