Stateful Inference for Low-Latency Multi-Agent Tool Calling
Pith reviewed 2026-06-29 22:36 UTC · model grok-4.3
The pith
A persistent KV cache across turns reduces multi-agent tool-calling cost from full-prompt reprocessing to only the new tokens each step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
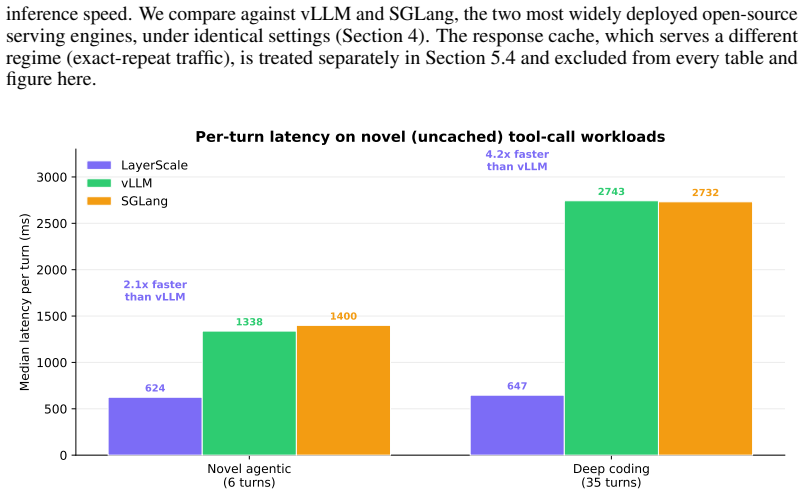
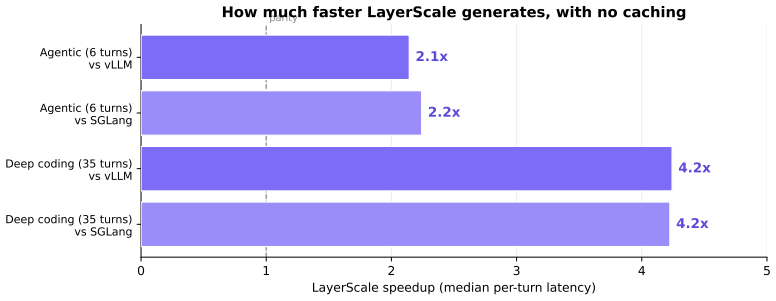
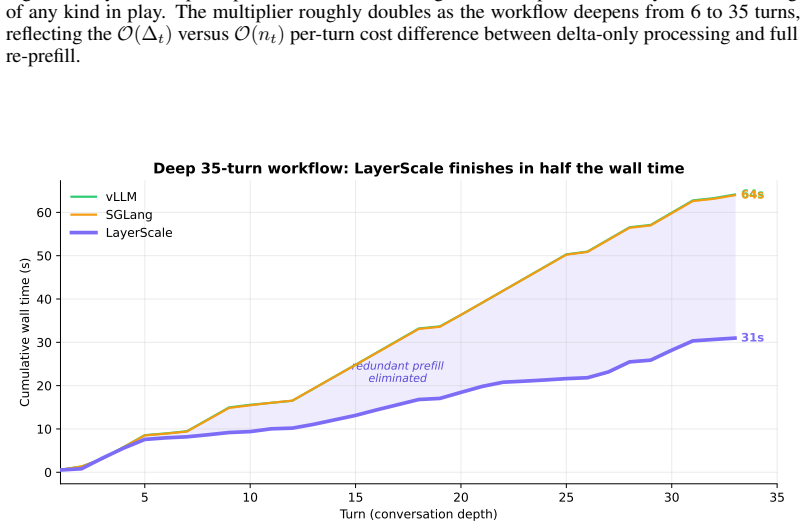
The central claim is that a stateful inference architecture converts the O(n_t) per-turn cost of conventional serving into an O(Δ_t) delta-only cost. A persistent KV cache lives across turns and advances by ingesting only the new tokens, while a radix prefix cache extends this across interleaved multi-agent traffic and a prompt-lookup speculative decoder accelerates structured output. Against vLLM and SGLang on novel fully-generated workloads the reference implementation is 2.1 times faster per turn on a 6-turn agentic workflow and 4.2 times on the median turn of a 35-turn one, with the advantage coming from stateful reuse and speculation rather than caching.
What carries the argument
Persistent KV cache that lives across turns and advances by ingesting only the new tokens
If this is right
- End-to-end wall time for multi-turn agentic workflows is halved.
- The relative speedup increases with workflow length because the unchanged prefix is never recomputed.
- Structured outputs incur lower overhead once the context is already cached.
- Interleaved traffic from multiple agents can share prefix computations without duplication.
Where Pith is reading between the lines
- The same delta-only pattern could apply to any accumulating context session such as long chats or iterative planning loops.
- Production agent deployments could support deeper or longer-running workflows once marginal cost per turn drops.
- Workflow designers might deliberately increase turn count if they know recomputation is avoided.
Load-bearing premise
Existing inference frameworks always treat each tool call as an independent request and re-process the full conversation from scratch.
What would settle it
Running the reference implementation head-to-head with vLLM or SGLang on the 35-turn workload and observing that median per-turn latency is not at least 4 times lower.
Figures
read the original abstract
Multi-agent tool calling is becoming the dominant interaction pattern for LLM-based systems, yet existing inference frameworks treat each tool call as an independent request, re-processing the entire conversation from scratch even though 85-95% of the prompt is unchanged from the previous turn. We present a stateful inference architecture that converts the $O(n_t)$ per-turn cost of conventional serving into an $O(\Delta_t)$ delta-only cost: a persistent KV cache lives across turns and advances by ingesting only the new tokens, while a radix prefix cache extends this across interleaved multi-agent traffic and a prompt-lookup speculative decoder accelerates structured output. Against vLLM and SGLang on novel, fully-generated workloads, the reference implementation is $2.1\times$ faster per turn on a 6-turn agentic workflow and $4.2\times$ on the median turn of a 35-turn one, halving end-to-end wall time. The advantage comes from stateful reuse and speculation, not caching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that conventional inference frameworks re-process full conversation histories for each tool call in multi-agent settings despite 85-95% prompt reuse across turns. It introduces a stateful architecture using a persistent KV cache that advances only on new tokens (O(Δ_t) cost), a radix prefix cache for interleaved multi-agent traffic, and a prompt-lookup speculative decoder for structured outputs. On novel fully-generated workloads, the implementation reports 2.1× per-turn speedup versus vLLM/SGLang on 6-turn workflows and 4.2× on the median turn of 35-turn workflows, halving end-to-end time, with gains attributed to stateful reuse and speculation rather than caching alone.
Significance. If the O(Δ_t) conversion and speedups hold under broader conditions, the work could meaningfully reduce latency in production multi-agent tool-calling systems by exploiting conversation statefulness. The combination of persistent KV, radix caching, and speculation is a concrete engineering contribution that distinguishes the approach from standard prefix caching.
major comments (2)
- [Evaluation] Evaluation section (workloads description): experiments are restricted to 'novel, fully-generated workloads' engineered to exhibit the 85-95% unchanged-prompt property. No results are shown for organic multi-agent traces with variable tool-response lengths, branching contexts, or lower reuse rates; this leaves the practical O(Δ_t) advantage and the 'not caching' distinction unverified for realistic deployments.
- [§3] §3 (Architecture): the claim that the radix prefix cache 'extends this across interleaved multi-agent traffic' is central to handling concurrent agents, yet no ablation isolates its contribution versus the persistent KV cache alone, nor quantifies hit rates under the reported workloads.
minor comments (2)
- [Abstract] Abstract and §2: the notation O(n_t) and O(Δ_t) is used without an explicit definition of n_t or Δ_t in terms of token counts or cache operations; a short formalization would improve clarity.
- [Figures] Figure captions (throughout): several figures comparing against vLLM and SGLang lack error bars or mention of the number of runs, making it hard to assess variability of the 2.1×/4.2× speedups.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below with clarifications on the evaluation design and architecture, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (workloads description): experiments are restricted to 'novel, fully-generated workloads' engineered to exhibit the 85-95% unchanged-prompt property. No results are shown for organic multi-agent traces with variable tool-response lengths, branching contexts, or lower reuse rates; this leaves the practical O(Δ_t) advantage and the 'not caching' distinction unverified for realistic deployments.
Authors: The generated workloads were constructed specifically to isolate and measure the O(Δ_t) delta cost under the stated 85-95% reuse condition, allowing precise attribution of speedups to stateful reuse rather than other factors. This controlled setting demonstrates the architectural conversion from O(n) to O(Δ) when the reuse property holds, which is the core claim. We agree that organic traces with variable lengths, branching, and lower reuse would be needed to fully verify practical gains in arbitrary deployments. We will revise the evaluation section to discuss expected behavior under reduced reuse and explicitly note the limitation regarding organic data. revision: partial
-
Referee: [§3] §3 (Architecture): the claim that the radix prefix cache 'extends this across interleaved multi-agent traffic' is central to handling concurrent agents, yet no ablation isolates its contribution versus the persistent KV cache alone, nor quantifies hit rates under the reported workloads.
Authors: A persistent KV cache alone maintains state per conversation but does not efficiently share prefixes across interleaved agents with overlapping histories; the radix structure enables that sharing for concurrent multi-agent traffic. The reported workloads include such interleaving, so the speedups reflect the combined system. We will add text in §3 clarifying this necessity and the distinction from standard per-request prefix caching. However, the manuscript does not contain a separate ablation or hit-rate numbers, so we cannot add quantitative isolation without new experiments. revision: partial
- Empirical results on organic multi-agent traces with variable tool-response lengths, branching contexts, or lower reuse rates
- Quantitative ablation isolating the radix prefix cache contribution versus persistent KV cache alone, including hit rates
Circularity Check
No significant circularity detected
full rationale
The paper describes an engineering architecture (persistent KV cache + radix prefix cache + prompt-lookup speculative decoder) that by design converts per-turn cost from O(n_t) to O(Δ_t). No mathematical derivation, fitted parameters, self-citations, or ansatzes are invoked; the central claims rest on direct empirical timing against external baselines (vLLM, SGLang) on the stated workloads. No step reduces to a self-referential definition or input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 85-95% of the prompt is unchanged from the previous turn in multi-agent tool calling
Forward citations
Cited by 1 Pith paper
-
Speculative Pre-Positioning: Decoding Stateful Sessions to the Next Decision Point Off the Critical Path
Speculative pre-positioning decodes stateful sessions ahead with the target model to enable near-constant-time responses from cached distributions or pre-paid deltas at 87% precision for capable models.
Reference graph
Works this paper leans on
-
[1]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C.H., Gonzalez, J., Zhang, H., and Stoica, I. Efficient Memory Management for Large Language Model Serving with PagedAttention. Proceedings of the 29th Symposium on Operating Systems Principles, 2023
2023
-
[2]
SGLang: Efficient Execution of Structured Language Model Programs
Zheng, L., Yin, L., Xie, Z., Huang, J., Sun, C., Yu, C.H., Cao, S., Kober, C., Sheng, Y., et al. SGLang: Efficient Execution of Structured Language Model Programs. arXiv preprint arXiv:2312.07104, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Prompt Caching
Anthropic. Prompt Caching. Documentation, 2024
2024
-
[4]
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
Zhong, Y., Liu, S., Chen, J., Hu, J., Zhu, Y., Liu, X., Jin, X., and Zhang, H. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. OSDI, 2024
2024
-
[5]
Orca: A Distributed Serving System for Transformer-Based Generative Models
Yu, G.I., Jeong, J.S., Kim, G.W., Kim, S., and Chun, B.G. Orca: A Distributed Serving System for Transformer-Based Generative Models. OSDI, 2022
2022
-
[6]
Fast Inference from Transformers via Speculative Decoding
Leviathan, Y., Kalman, M., and Matias, Y. Fast Inference from Transformers via Speculative Decoding. ICML, 2023
2023
-
[7]
Prompt Lookup Decoding
Saxena, A. Prompt Lookup Decoding. https://github.com/apoorvumang/prompt-lookup-decoding, 2023
2023
-
[8]
Attention Once Is All You Need: Efficient Streaming Inference with Stateful Transformers
Norgren, V. Attention Once Is All You Need: Efficient Streaming Inference with Stateful Transformers. arXiv preprint arXiv:2605.13784, 2026. https://arxiv.org/abs/2605.13784
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.