Speculative Pre-Positioning: Decoding Stateful Sessions to the Next Decision Point Off the Critical Path
Pith reviewed 2026-06-30 07:29 UTC · model grok-4.3
The pith
Speculative pre-positioning advances stateful sessions during idle time so the next request resumes from a pre-paid entry or returns its first token from a cached distribution in one vocabulary scan.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
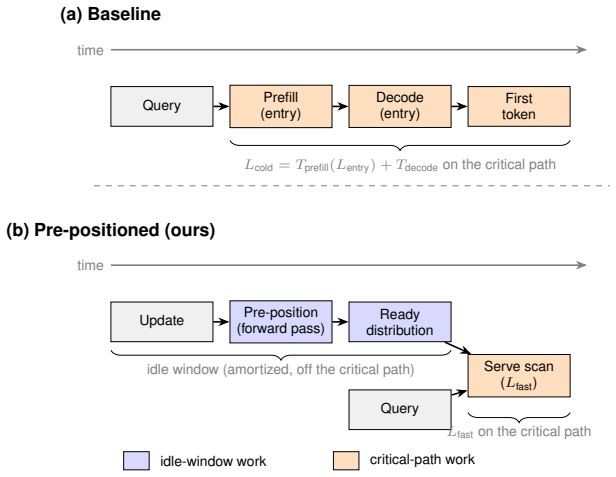
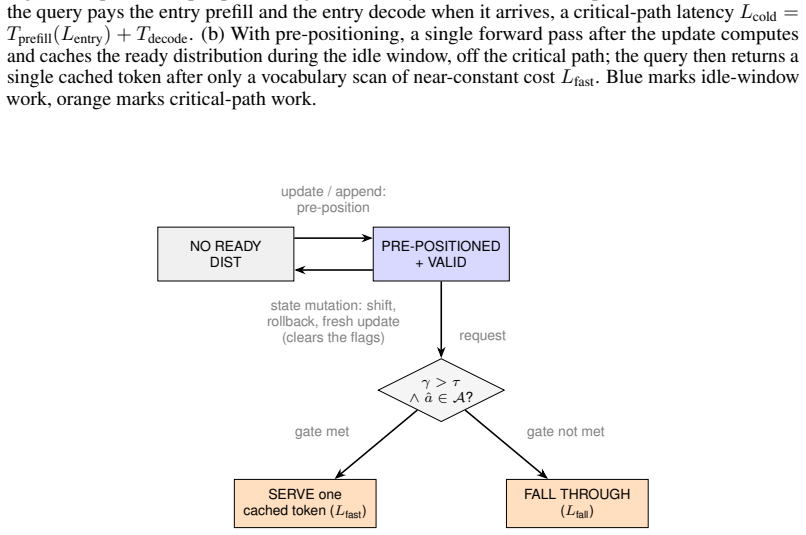
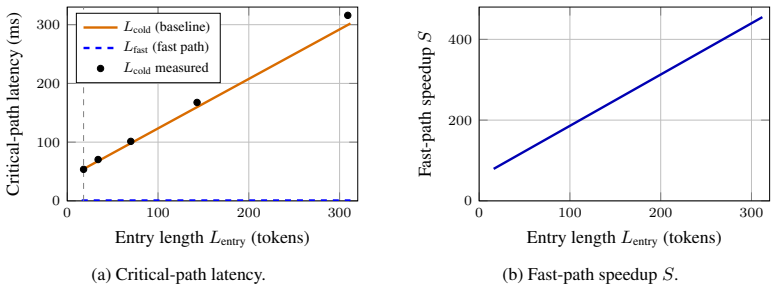
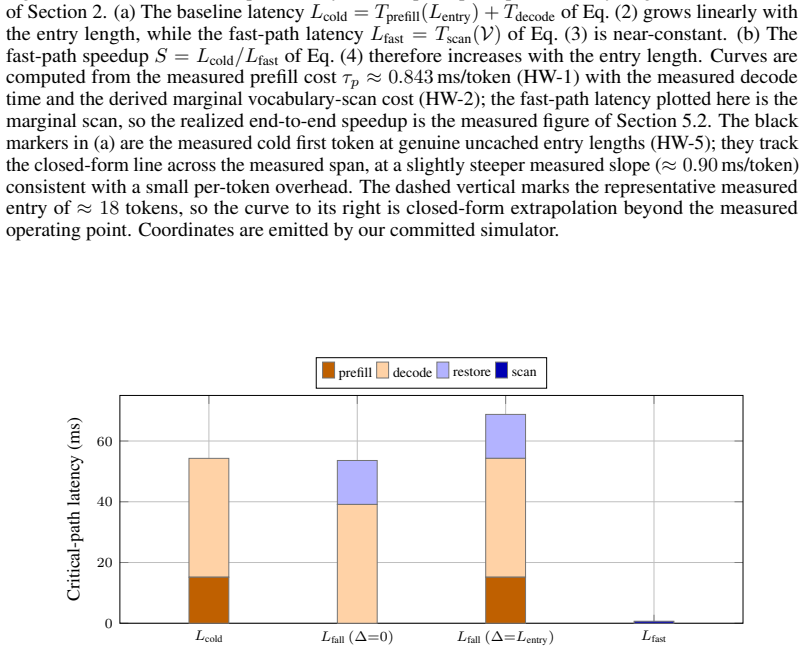
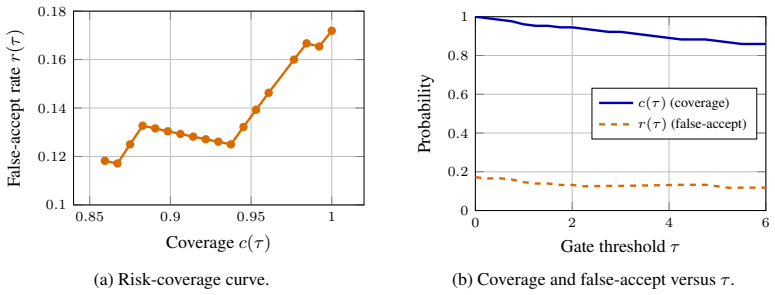
Speculative pre-positioning decodes the session forward to its next decision point with the target model's own forward pass and no draft model, moving the cross-request prefill and entry-decode off the critical path: the next request resumes from a pre-paid entry on its delta, or, when a confidence gate fires, is answered from a cached distribution in one near-constant vocabulary scan with no decode, at a cost only of energy and a rare, bounded false accept. The payoff is conditional on capability: a capable model fires the gate at near-full coverage and about 87% precision (a smaller one never clears it), returning the first token in about 1.0 ms versus the 39 ms decode a prefix cache still
What carries the argument
The confidence gate that triggers direct return of the pre-computed distribution when the target model's idle forward pass meets a precision threshold.
If this is right
- First-token latency falls from 39 ms to roughly 1 ms on successful gate firings.
- Only models large enough to clear the gate benefit; smaller models receive no speedup.
- The only added costs are energy for the idle passes and the bounded cost of rare false accepts.
- Cross-request prefill work is removed from the user-visible critical path.
Where Pith is reading between the lines
- Stateful session management becomes increasingly attractive as base model capability rises.
- The approach could be combined with existing draft-model speculative decoding for further gains on the remaining cases.
- The technique may generalize to any workload where idle accelerator time occurs between dependent inference steps.
Load-bearing premise
The target model is capable enough that its own forward passes during idle time produce a confidence gate that fires at near-full coverage with 87 percent precision.
What would settle it
Run the described confidence gate on a capable model across a realistic workload of multi-turn sessions and measure both gate coverage and precision together with the resulting first-token latency against a prefix-cache baseline.
Figures


read the original abstract
A stateless inference server (vLLM, SGLang, TensorRT-LLM) idles between requests while the accelerator waits; a stateful session reclaims that idle time. Speculative pre-positioning decodes the session forward to its next decision point with the target model's own forward pass and no draft model, moving the cross-request prefill and entry-decode off the critical path: the next request resumes from a pre-paid entry on its delta, or, when a confidence gate fires, is answered from a cached distribution in one near-constant vocabulary scan with no decode, at a cost only of energy and a rare, bounded false accept. The payoff is conditional on capability: a capable model fires the gate at near-full coverage and about 87% precision (a smaller one never clears it), returning the first token in about 1.0 ms versus the 39 ms decode a prefix cache still pays.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes speculative pre-positioning for stateful LLM inference sessions. During idle time on the accelerator, the target model performs its own forward passes to decode the session forward to the next decision point. This pre-positions the state so that an incoming request can either resume from a pre-paid entry on its delta or, when a confidence gate fires, be answered directly from a cached distribution via a single vocabulary scan. The payoff is stated to be conditional on model capability: capable models achieve near-full coverage at ~87% precision on the gate (smaller models never clear it), yielding first-token latency of ~1.0 ms versus the 39 ms paid by a prefix cache.
Significance. If the empirical claims are substantiated, the approach would demonstrate a method to reclaim idle accelerator time in existing inference servers without introducing a separate draft model or additional parameters, offering a capability-dependent route to sub-millisecond first-token responses for stateful workloads. The absence of any parameter-free derivation or machine-checked component is noted; the result would rest entirely on the reported measurements.
major comments (1)
- [Abstract] Abstract: the central claims of 87% precision at near-full coverage for the confidence gate, together with the 1.0 ms vs. 39 ms latency comparison, are presented as measured outcomes with no definition of the gate (threshold on max-probability, entropy, or other statistic), no description of the models, tasks, or datasets, and no experimental protocol or error bars. Because these numbers are the sole quantitative support for the conditional payoff, their lack of grounding renders the primary assertion unverifiable from the manuscript.
Simulated Author's Rebuttal
We thank the referee for identifying the lack of grounding in the abstract. We agree the quantitative claims require explicit context to be verifiable and will revise the abstract accordingly while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 87% precision at near-full coverage for the confidence gate, together with the 1.0 ms vs. 39 ms latency comparison, are presented as measured outcomes with no definition of the gate (threshold on max-probability, entropy, or other statistic), no description of the models, tasks, or datasets, and no experimental protocol or error bars. Because these numbers are the sole quantitative support for the conditional payoff, their lack of grounding renders the primary assertion unverifiable from the manuscript.
Authors: We accept this observation. The abstract was written at a high level to emphasize the core idea and conditional payoff, but it does not define the gate (a max-probability threshold), name the models (capable vs. smaller), specify tasks/datasets, or reference the protocol/error bars. These elements appear in the experimental section of the manuscript, yet the referee is correct that the abstract itself must stand alone for the central claims. We will revise the abstract to include a brief definition of the gate, the model classes evaluated, the stateful session benchmarks used, and a note on the measurement protocol with error bars. This change will make the reported 87% precision, coverage, and latency figures directly verifiable from the abstract. revision: yes
Circularity Check
No derivation chain or equations; claims are empirical assertions only.
full rationale
The provided text contains no equations, derivations, fitted parameters, self-citations, or ansatzes that could reduce any result to its inputs by construction. All reported outcomes (87% precision, 1.0 ms latency, 39 ms baseline, coverage conditional on capability) are presented as measured results without any visible mechanism, fitting process, or definitional loop. The paper therefore has no load-bearing derivation step to analyze for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C.H., Gonzalez, J., Zhang, H., and Stoica, I. Efficient Memory Management for Large Language Model Serving with PagedAttention. Proceedings of the 29th Symposium on Operating Systems Principles, 2023
2023
-
[2]
SGLang: Efficient Execution of Structured Language Model Programs
Zheng, L., Yin, L., Xie, Z., Huang, J., Sun, C., Yu, C.H., Cao, S., Kober, C., Sheng, Y., et al. SGLang: Efficient Execution of Structured Language Model Programs. arXiv preprint arXiv:2312.07104, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Orca: A Distributed Serving System for Transformer-Based Generative Models
Yu, G.I., Jeong, J.S., Kim, G.W., Kim, S., and Chun, B.G. Orca: A Distributed Serving System for Transformer-Based Generative Models. OSDI, 2022
2022
-
[4]
Fast Inference from Transformers via Speculative Decoding
Leviathan, Y., Kalman, M., and Matias, Y. Fast Inference from Transformers via Speculative Decoding. ICML, 2023
2023
-
[5]
Prompt Lookup Decoding
Saxena, A. Prompt Lookup Decoding. https://github.com/apoorvumang/prompt-lookup-decoding, 2023
2023
-
[6]
Accelerating Large Language Model Decoding with Speculative Sampling
Chen, C., et al. Accelerating Large Language Model Decoding with Speculative Sampling. arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Prompt Cache: Modular Attention Reuse for Low-Latency Inference
Gim, I., et al. Prompt Cache: Modular Attention Reuse for Low-Latency Inference. Proceedings of Machine Learning and Systems (MLSys), 2024
2024
-
[8]
Confident Adaptive Language Modeling
Schuster, T., et al. Confident Adaptive Language Modeling. Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[9]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Chen, L., Zaharia, M., and Zou, J. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance. arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
and Wiener, Y
El-Yaniv, R. and Wiener, Y. On the Foundations of Noise-free Selective Classification. Journal of Machine Learning Research, 11:1605--1641, 2010
2010
-
[11]
Attention Once Is All You Need: Efficient Streaming Inference with Stateful Transformers
Norgren, V. Attention Once Is All You Need: Efficient Streaming Inference with Stateful Transformers. arXiv preprint arXiv:2605.13784, 2026. https://arxiv.org/abs/2605.13784
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Stateful Inference for Low-Latency Multi-Agent Tool Calling
Norgren, V. Stateful Inference for Low-Latency Multi-Agent Tool Calling. arXiv preprint arXiv:2605.26289, 2026. https://arxiv.org/abs/2605.26289
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.