CNNs, Transformers, Hybrid, and Vision Language Models for Skin Cancer Detection
Pith reviewed 2026-06-29 22:28 UTC · model grok-4.3
The pith
Transformer hybrids and SigLIP VLMs deliver the strongest accuracy-specificity trade-offs for skin cancer detection on PAD-UFES-20.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
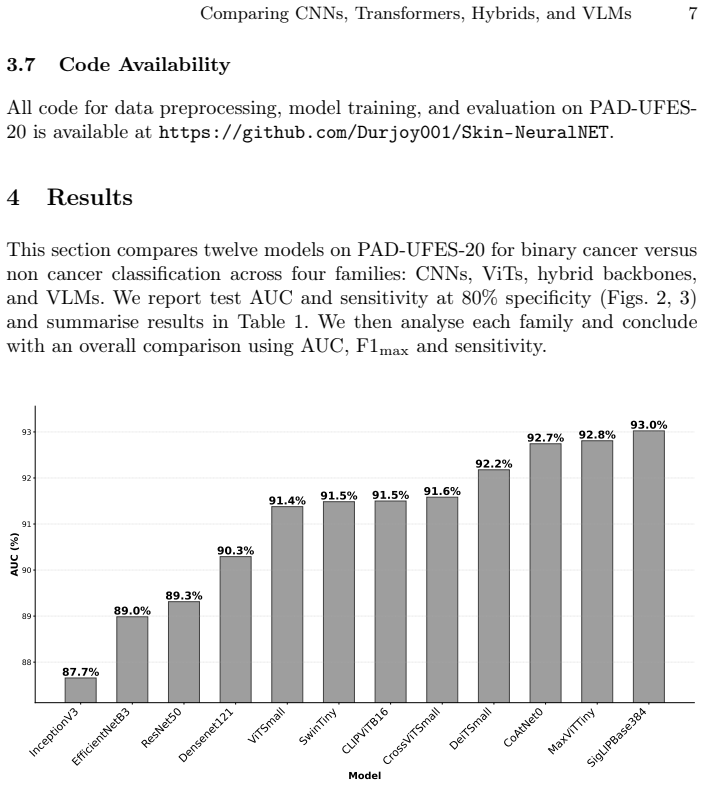
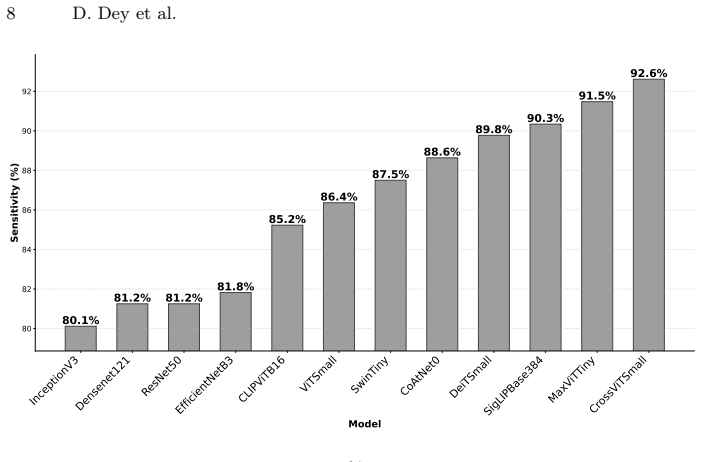
On the PAD-UFES-20 dataset for binary skin cancer detection, well tuned CNNs already provide strong baselines, but transformer based families consistently improve discrimination. Hybrid models (MaxViT Tiny, CoAtNet0) and a SigLIP based VLM achieve the best overall trade off between ranking performance and clinically relevant operating points, while CLIP based model offers high precision.
What carries the argument
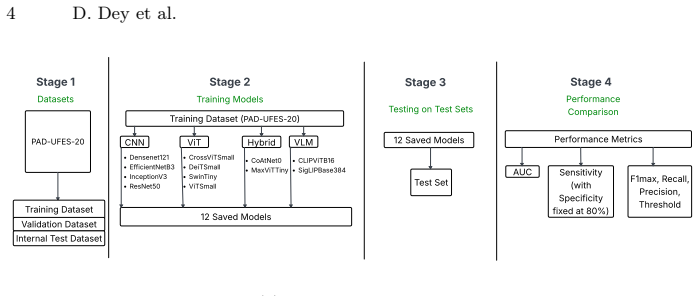
Side-by-side training and evaluation of twelve models from four families on the same PAD-UFES-20 split, scored by AUC, maximum F1, and sensitivity at 80 percent specificity.
If this is right
- Hybrid convolution-transformer models supply the most favorable balance between overall ranking and screening-oriented sensitivity.
- SigLIP-based VLMs match or exceed hybrid performance across the reported clinical thresholds.
- CLIP-based VLMs deliver the highest precision, useful when false-positive cost is high.
- Pure CNNs remain viable baselines but are outperformed once transformer components are introduced under matched conditions.
- Public release of the full training and evaluation code creates a fixed reference for future PAD-UFES-20 experiments.
Where Pith is reading between the lines
- The same families may generalize to other dermoscopic collections if the advantage is truly architectural rather than dataset-specific.
- The 80-percent-specificity sensitivity focus implies these models are intended for settings where missing a positive case carries higher clinical cost than extra referrals.
- Mobile or edge deployment of the top hybrids could reduce specialist workload in primary-care screening programs.
- Precision-oriented use of the CLIP model might be combined with a hybrid model in a cascaded system to control both false negatives and false positives.
Load-bearing premise
Any observed performance gaps between the four model families are caused by architecture rather than differences in training procedure, hyperparameter search, or test-set leakage on PAD-UFES-20.
What would settle it
Retrain all twelve models from scratch with identical hyperparameters, augmentations, and train-test splits on PAD-UFES-20; if the transformer and hybrid families no longer show consistent gains in AUC or sensitivity at 80 percent specificity, the architecture advantage claim is falsified.
Figures
read the original abstract
Skin cancer is a common and fast rising malignancy worldwide. Early detection is critical for improving outcomes. Deep learning models trained on dermoscopic and clinical images can support automated and fast triage. However, many studies evaluate only a limited set of architectures. Experimental setups also vary across studies. In this paper, we present a unified evaluation of twelve deep learning models for binary skin cancer detection on the PAD-UFES-20 dataset. The models span four families: convolutional neural networks (CNN), vision transformers (ViT), hybrid convolution transformer backbones, and vision language models (VLM). Performance is assessed using AUC, the maximum F1 score with its precision and recall, and sensitivity at 80% specificity, reflecting screening oriented requirements. Our results show that well tuned CNNs already provide strong baselines, but transformer based families consistently improve discrimination. Hybrid models (MaxViT Tiny, CoAtNet0) and a SigLIP based VLM achieve the best overall trade off between ranking performance and clinically relevant operating points, while CLIP based model offers high precision. The full codebase for all experiments is publicly released. Together, these findings offer practical guidance on which model families are most suitable for real world deployment in skin cancer screening and establish a reproducible reference point for future work on PAD-UFES-20.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a unified evaluation of twelve deep learning models spanning CNN, vision transformer, hybrid convolution-transformer, and vision-language model families for binary skin cancer detection on the PAD-UFES-20 dataset. Performance is measured via AUC, maximum F1 score (with precision/recall), and sensitivity at 80% specificity. The central claim is that well-tuned CNNs provide strong baselines but transformer-based families improve discrimination, with MaxViT Tiny, CoAtNet0, and a SigLIP-based VLM achieving the best overall trade-off and a CLIP-based model offering high precision; the full codebase is released.
Significance. If the experimental conditions prove comparable, the work supplies a reproducible reference benchmark on PAD-UFES-20 and practical guidance for model-family selection in screening-oriented skin-cancer triage. The public code release is a concrete strength that enables verification and extension by the community.
major comments (1)
- [Abstract] Abstract: the claim of a 'unified evaluation' across the twelve models is load-bearing for attributing performance differences to architecture families, yet the manuscript provides no explicit accounting of per-family hyperparameter search budgets, number of trials, augmentation pipelines, optimizer settings, early-stopping rules, or validation protocol on the fixed PAD-UFES-20 split. Without this information the observed ranking (e.g., hybrids and SigLIP over CNNs) cannot be confidently ascribed to model family rather than differential tuning effort.
minor comments (2)
- [Abstract] The abstract states metric values and rankings but does not report statistical significance tests or confidence intervals; adding these would strengthen the empirical claims without altering the central narrative.
- [Methods] Consider clarifying in the methods whether a single fixed train/validation/test split was used for all models or whether any model-specific data handling occurred.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the recommendation for major revision. The single major comment raises a valid point about the need for explicit documentation of experimental controls to support the 'unified evaluation' claim. We address this below and commit to revisions that strengthen the manuscript without altering its core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'unified evaluation' across the twelve models is load-bearing for attributing performance differences to architecture families, yet the manuscript provides no explicit accounting of per-family hyperparameter search budgets, number of trials, augmentation pipelines, optimizer settings, early-stopping rules, or validation protocol on the fixed PAD-UFES-20 split. Without this information the observed ranking (e.g., hybrids and SigLIP over CNNs) cannot be confidently ascribed to model family rather than differential tuning effort.
Authors: We agree that the manuscript would be strengthened by an explicit, consolidated description of the experimental protocol to make the attribution to model families more robust. The released codebase already encodes all training details (including per-model hyperparameter grids, augmentation pipelines, optimizers, and the fixed 70/15/15 split with early stopping on validation AUC), but we accept that readers should not need to inspect the code to verify fairness. In the revision we will add a dedicated 'Experimental Protocol' subsection (and an accompanying table) that reports, for each family: (i) hyperparameter search budget and number of trials, (ii) shared vs. family-specific augmentation and optimizer choices, (iii) early-stopping criterion, and (iv) confirmation that the same validation protocol was applied to all twelve models. This will allow the ranking to be confidently linked to architectural differences rather than tuning disparity. revision: yes
Circularity Check
No circularity: purely empirical model comparison on fixed dataset
full rationale
The paper conducts a unified empirical evaluation of 12 models across CNN, ViT, hybrid, and VLM families on the PAD-UFES-20 dataset, reporting AUC, max F1, and sensitivity at 80% specificity. All outcomes are direct measurements on held-out data with no equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claims to inputs by construction. The codebase release further supports reproducibility without introducing definitional loops. The assumption of comparable training conditions is an empirical claim open to verification via the released code, not a circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- model-specific hyperparameters
axioms (1)
- domain assumption The PAD-UFES-20 dataset constitutes a suitable and unbiased benchmark for comparing skin cancer detection models
Reference graph
Works this paper leans on
-
[1]
EAI Endorsed Transactions on Pervasive Health and Technology9, 1–8 (2023)
Agarwal, R., Godavarthi, D.: Skin disease classification using CNN algorithms. EAI Endorsed Transactions on Pervasive Health and Technology9, 1–8 (2023). https://doi.org/10.4108/eetpht.9.4039
-
[2]
Remote Sensing15(7), 1860 (2023).https://doi.org/10.3390/ rs15071860
Aleissaee, A.A., Kumar, A., Anwer, R.M., et al.: Transformers in remote sens- ing: A survey. Remote Sensing15(7), 1860 (2023).https://doi.org/10.3390/ rs15071860
2023
-
[3]
Sinkron: Jur- nal dan Penelitian Teknik Informatika8, 2168–2178 (2023).https://doi.org/10
Anggriandi, D., Utami, E., Ariatmanto, D.: Comparative analysis of CNN and CNN-SVM methods for classification types of human skin disease. Sinkron: Jur- nal dan Penelitian Teknik Informatika8, 2168–2178 (2023).https://doi.org/10. 33395/sinkron.v8i4.12831
2023
-
[4]
European Journal of Cancer111, 148–154 (2019).https://doi
Brinker, T.J., Hekler, A., Enk, A.H., et al.: A convolutional neural network trained with dermoscopic images performs on par with 145 dermatologists in melanoma classification. European Journal of Cancer111, 148–154 (2019).https://doi. org/10.1016/j.ejca.2019.01.011 12 D. Dey et al
- [5]
-
[6]
NIPS ’21, Curran Associates Inc., Red Hook, NY, USA (2021)
Dai, Z., Liu, H., Le, Q.V., et al.: Coatnet: marrying convolution and attention for all data sizes. NIPS ’21, Curran Associates Inc., Red Hook, NY, USA (2021)
2021
-
[7]
Dhankar, U., Jain, S., Zaidi, S., et al.: Skin disease detection using python and deep learning. International Journal of Engineering Applied Sciences and Technology8, 186–191 (2023).https://doi.org/10.33564/ijeast.2023.v08i02.027
-
[8]
Nature542(7639), 115–118 (2017).https: //doi.org/10.1038/nature21056
Esteva, A., Kuprel, B., Novoa, R.A., et al.: Dermatologist-level classification of skin cancer with deep neural networks. Nature542(7639), 115–118 (2017).https: //doi.org/10.1038/nature21056
-
[9]
International Journal of Cancer149(4), 778–789 (2021)
Ferlay, J., Colombet, M., Soerjomataram, I., et al.: Cancer statistics for the year 2020: An overview. International Journal of Cancer149(4), 778–789 (2021)
2020
-
[10]
Nature Communications12(1), 160 (2021)
Fontanillas, P., Alipanahi, B., Furlotte, N.A., et al.: Disease risk scores for skin cancers. Nature Communications12(1), 160 (2021)
2021
-
[11]
Frontiers in Medicine10, 1305954 (2024)
Furriel, B.C.R.S., Oliveira, B.D., Proã, R., et al.: Artificial intelligence for skin cancer detection and classification for clinical environment: A systematic review. Frontiers in Medicine10, 1305954 (2024)
2024
-
[12]
Hardie, R.C., Ali, R., De Silva, M.S., et al.: Skin lesion segmentation and classi- fication for isic 2018 using traditional classifiers with hand-crafted features. arXiv preprint arXiv:1807.07001 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
He, K., Zhang, X., Ren, S., et al.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 770–778 (2016).https://doi.org/10.1109/CVPR.2016.90
-
[14]
Himel, G.M.S., Islam, M.M., Al-Aff, K.A., et al.: Skin cancer segmentation and classification using vision transformer. Computational and Mathematical Methods in Medicine2024, 3022192 (2024).https://doi.org/10.1155/2024/3022192
-
[15]
In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Huang, G., Liu, Z., Van Der Maaten, L., et al.: Densely connected convolutional networks. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2261–2269 (2017).https://doi.org/10.1109/CVPR.2017.243
-
[16]
Journal of Cuta- neous Pathology37(9), e1–e20 (2010)
Hussein, M.R.A.: Skin metastasis: A pathologist’s perspective. Journal of Cuta- neous Pathology37(9), e1–e20 (2010)
2010
-
[17]
American Family Physician62(2), 357–368 (2000)
Jerant, A.F., Johnson, J.T., Sheridan, C.D., et al.: Early detection and treatment of skin cancer. American Family Physician62(2), 357–368 (2000)
2000
-
[18]
Cancer75(S2), 684–690 (1995)
Kopf, A.W., Salopek, T.G., Slade, J., et al.: Techniques of cutaneous examination for the detection of skin cancer. Cancer75(S2), 684–690 (1995)
1995
-
[19]
IEEE Access10, 123212–123224 (2022).https://doi.org/ 10.1109/ACCESS.2022.3224044
Lee, S., Lee, S., Song, B.C.: Improving vision transformers to learn small-size dataset from scratch. IEEE Access10, 123212–123224 (2022).https://doi.org/ 10.1109/ACCESS.2022.3224044
-
[20]
In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV)
Liu, Z., Lin, Y., Cao, Y., et al.: Swin transformer: Hierarchical vision transformer using shifted windows. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 9992–10002 (2021).https://doi.org/10.1109/ICCV48922. 2021.00986
-
[21]
In: Advances in Intelligent Systems and Com- puting, Lecture Notes in Computer Science, vol
Lungu-Stan, V.C., Cercel, D.C., Pop, F.: SkinDistilViT: Lightweight vision trans- former for skin lesion classification. In: Advances in Intelligent Systems and Com- puting, Lecture Notes in Computer Science, vol. 14254. Springer Nature Switzer- land (2023).https://doi.org/10.1007/978-3-031-44207-0_23
-
[22]
Pacal, I., Alaftekin, M., Zengul, F.: Enhancing skin cancer diagnosis using swin transformer with hybrid shifted window-based multi-head self-attention and Comparing CNNs, Transformers, Hybrids, and VLMs 13 swiglu-based mlp. Journal of Imaging Informatics in Medicine37, 3174–3192 (2024).https://doi.org/10.1007/s10278-024-01140-8
-
[23]
Data in Brief32(2020).https://doi.org/10.1016/j.dib.2020.106221
Pacheco, A.G.C., Lima, G.R., da Silva Salomão, A., et al.: Pad-ufes-20: A skin lesion dataset composed of patient data and clinical images collected from smart- phones. Data in Brief32(2020).https://doi.org/10.1016/j.dib.2020.106221
-
[24]
In: Proceedings of the 38th International Con- ference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., et al.: Learning transferable visual models from natural language supervision. In: Proceedings of the 38th International Con- ference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 8748–8763. PMLR (2021)
2021
-
[25]
Szegedy, C., Vanhoucke, V., Ioffe, S., et al.: Rethinking the inception architecture for computer vision (06 2016).https://doi.org/10.1109/CVPR.2016.308
-
[26]
In: Chaudhuri, K., Salakhutdinov, R
Tan, M., Le, Q.: EfficientNet: Rethinking model scaling for convolutional neural networks. In: Chaudhuri, K., Salakhutdinov, R. (eds.) Proceedings of the 36th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 97, pp. 6105–6114. PMLR (09–15 Jun 2019)
2019
-
[27]
In: Meila, M., Zhang, T
Touvron,H.,Cord,M.,Douze,M.,etal.:Trainingdata-efficientimagetransformers & distillation through attention. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 10347–10357. PMLR (18–24 Jul 2021)
2021
-
[28]
Nature Medicine26(8), 1229–1234 (2020).https://doi.org/ 10.1038/s41591-020-0942-0
Tschandl, P., Rinner, C., Apalla, Z., et al.: Human–computer collaboration for skin cancer recognition. Nature Medicine26(8), 1229–1234 (2020).https://doi.org/ 10.1038/s41591-020-0942-0
-
[29]
In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T
Tu, Z., Talebi, H., Zhang, H., et al.: Maxvit: Multi-axis vision transformer. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision – ECCV 2022. Lecture Notes in Computer Science, vol. 13684, pp. 459–479. Springer, Cham (2022).https://doi.org/10.1007/978-3-031-20053-3_27
-
[30]
In: Walters, K.A
Walters, K.A., Roberts, M.S.: The structure and function of skin. In: Walters, K.A. (ed.) Dermatological and Transdermal Formulations, pp. 19–58. CRC Press (2002)
2002
-
[31]
arXiv preprint arXiv:2501.14685 (2025), under review for MIDL 2025
Wu, F., Papiez, B.W.: Rethinking foundation models for medical image classifica- tion through a benchmark study on medmnist. arXiv preprint arXiv:2501.14685 (2025), under review for MIDL 2025
-
[32]
Ye, C., Li, J., Shuai, Q.: Evaluating the performance and clinical applications of multiclass deep learning models for skin cancer pathology diagnosis (isic): A comparative analysis of cnn, vit, and vlm. In: Proceedings of the 2025 10th In- ternational Conference on Intelligent Information Technology (ICIIT 2025). pp. 92–103. Association for Computing Mac...
-
[33]
Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion
Zhai, X., Mustafa, B., Kolesnikov, A., et al.: Sigmoid loss for language image pre-training. In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 11941–11952 (2023).https://doi.org/10.1109/ICCV51070.2023. 01100
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (2022)
Zhang, J., Liu, X., Wang, Y., et al.: Medclip: Contrastive learning from un- paired images and text for medical visual representations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (2022)
2022
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, P., Li, X., Hu, X., Yang, J., et al.: Vinvl: Revisiting visual representa- tions in vision–language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5579–5588 (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.