Multi-Modal Building Inspection via Perceiver IO Fusion of Satellite and Street-Level Imagery
Pith reviewed 2026-06-29 22:14 UTC · model grok-4.3
The pith
Perceiver IO fusion of satellite and street-level images improves classification of roof attributes best seen from the ground.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
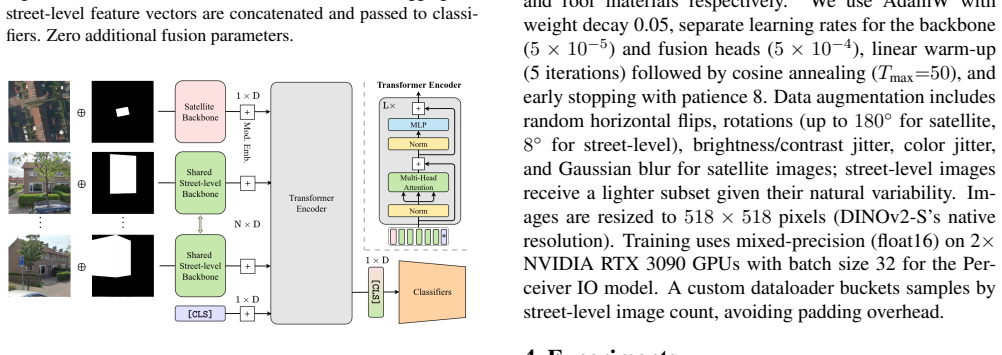
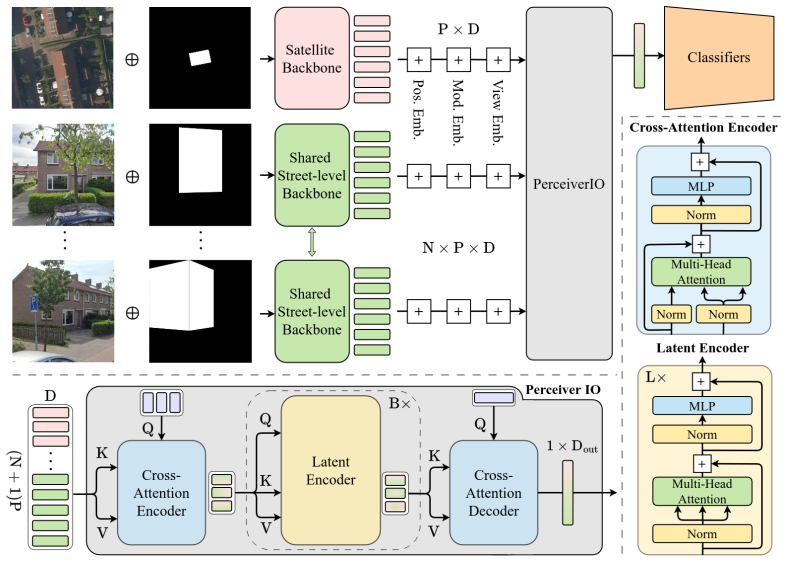
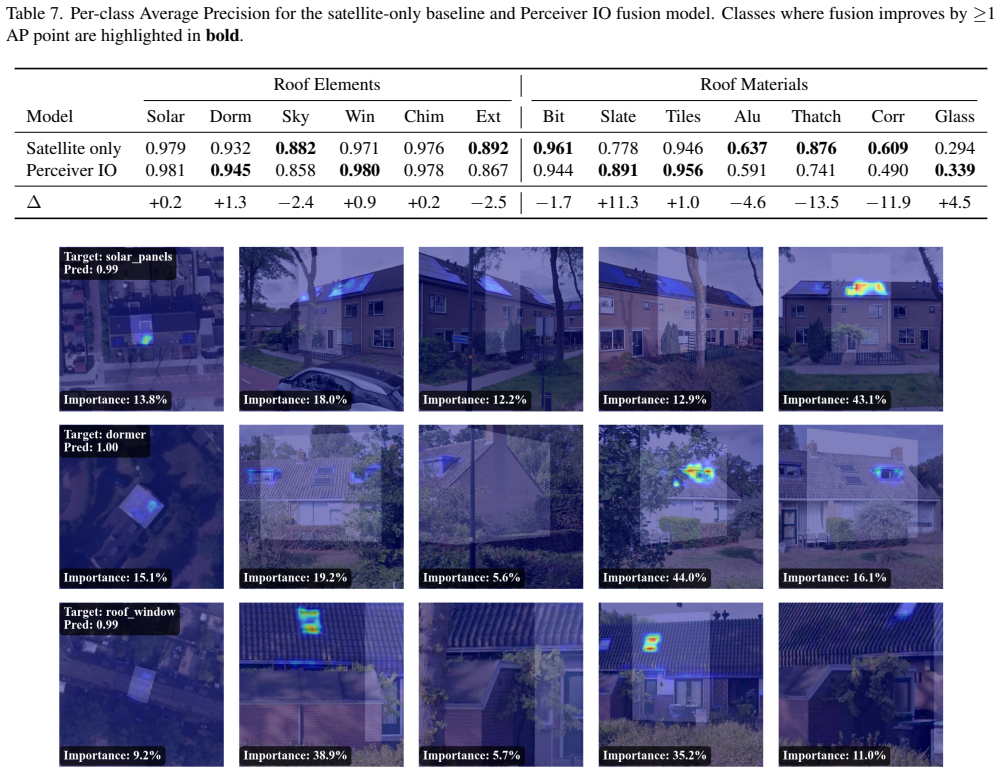
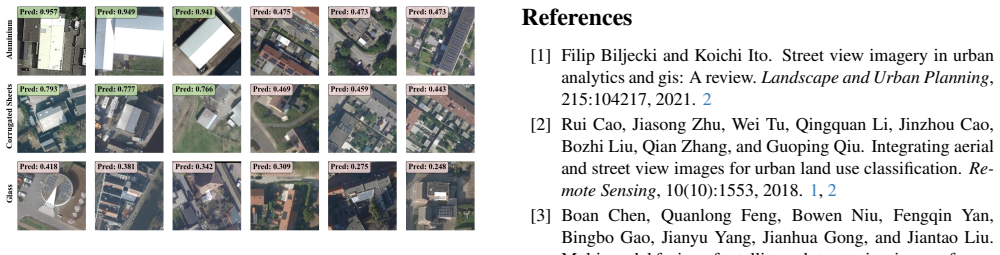
A Perceiver IO architecture that ingests spatial patch tokens from a shared DINOv2 backbone, naturally accommodates an arbitrary number of street-level views per building, and jointly predicts multi-label roof element and material classes improves over alternative fusion strategies; it produces substantial per-class gains for attributes visible from street level while the satellite-only baseline retains a slight advantage in macro-averaged mAP for classes predominantly visible from above.
What carries the argument
Perceiver IO model that processes variable-length sets of DINOv2 patch tokens from satellite and street-level images and outputs multi-label classifications without padding or fixed-size pooling.
If this is right
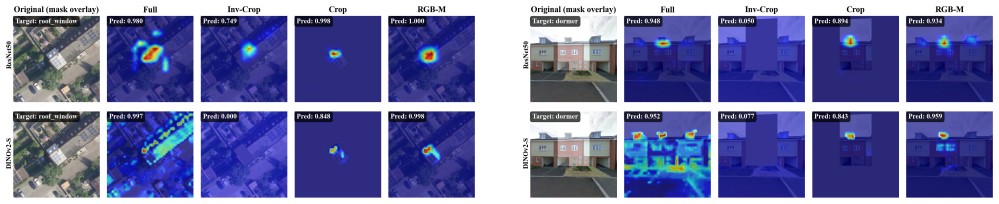
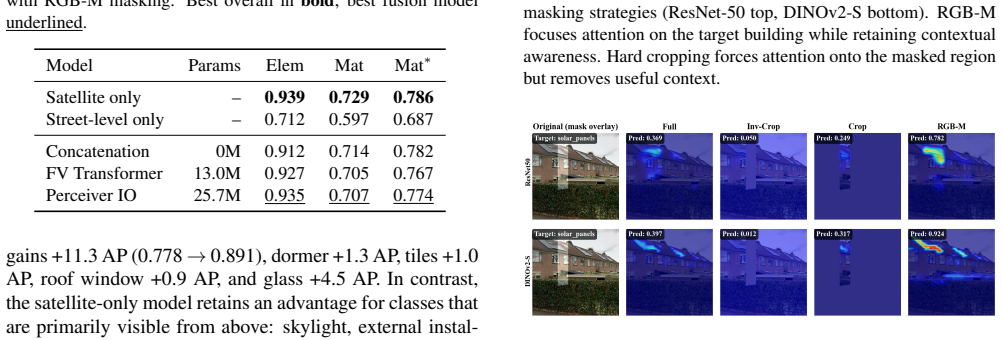
- RGB-M masking that adds the building footprint as a fourth channel outperforms hard cropping on both modalities.
- Per-class average precision rises by 11.3 points for slate and 1.3 points for dormers when street-level views are fused.
- The architecture scales to heterogeneous inputs and multiple output tasks without requiring fixed view counts.
- Satellite-only remains competitive or superior for roof attributes that are mainly visible from above.
- The same fusion strategy can be applied to other building-inspection tasks that combine overhead and ground-level imagery.
Where Pith is reading between the lines
- The variable-view handling could be tested on tasks such as facade damage detection where the number of available street photos also varies.
- The RGB-M masking prior might transfer to other multi-modal settings that need soft spatial focus without explicit cropping.
- The ten-country dataset could serve as a starting benchmark for studying domain shift when models are trained on one region and tested on another.
- Extending the fusion to include temporal sequences of street views could reveal whether change detection benefits from the same Perceiver IO design.
Load-bearing premise
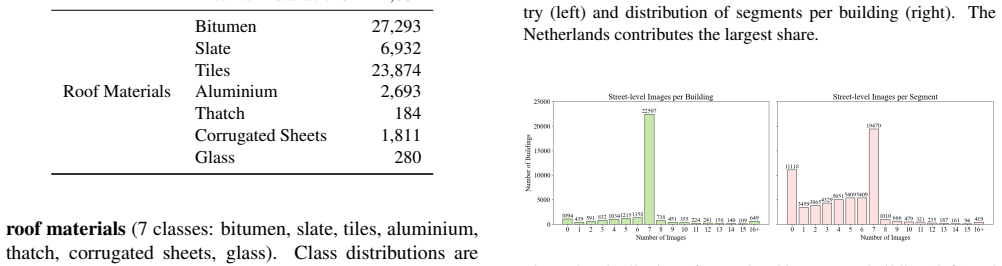
The constructed dataset of 32,135 buildings with paired satellite and street-level images and labels supplies an unbiased test of multi-modal performance without significant labeling errors or domain shift.
What would settle it
Retraining and evaluating the same Perceiver IO model on a fresh set of buildings from additional countries or with independently verified labels, then checking whether the reported per-class gains for street-visible attributes disappear or reverse.
Figures











read the original abstract
We present a multi-modal classification framework that fuses satellite and street-level imagery through a Perceiver IO architecture operating on spatial patch tokens from a shared DINOv2 backbone. The design naturally handles a variable number of street-level views per building without padding or fixed-size pooling, and jointly predicts multi-label roof element and roof material classes. We construct a large-scale dataset of 32,135 buildings (61,672 segments) spanning ten countries, pairing satellite images with up to eight street-level views per segment and evaluating four masking strategies for isolating the target building. We propose an RGB-M masking strategy that appends the building footprint mask as a fourth input channel, providing a soft spatial prior that outperforms hard cropping across both modalities. The Perceiver IO fusion model improves over all other fusion strategies and yields substantial per-class gains for attributes visible from street level (e.g., +11.3 AP for slate, +1.3 AP for dormers), though the satellite-only baseline retains a slight advantage in macro-averaged mAP for classes that are predominantly visible from above. These results establish a scalable, flexible architecture for multi-modal building inspection that can accommodate heterogeneous inputs and multiple output tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a Perceiver IO architecture that fuses spatial patch tokens from a shared DINOv2 backbone applied to satellite and variable numbers of street-level images for multi-label classification of roof elements and roof materials. It introduces a dataset of 32,135 buildings (61,672 segments) across ten countries, evaluates four masking strategies including a proposed RGB-M channel, and reports that the Perceiver IO fusion model outperforms other fusion baselines with notable per-class AP gains for street-visible attributes (e.g., +11.3 AP for slate) while satellite-only remains competitive on macro mAP for overhead-visible classes.
Significance. If the empirical results are reliable, the work demonstrates a flexible multi-modal architecture that naturally accommodates heterogeneous inputs without fixed pooling or padding, together with a large-scale multi-country dataset that could support further research on building attribute prediction. The concrete per-class gains for street-visible attributes and the comparison across masking strategies provide a useful empirical baseline for multi-modal fusion in remote sensing.
major comments (2)
- [Dataset section] Dataset section (abstract and § on data construction): the 32,135-building dataset is central to all reported AP improvements, yet the manuscript supplies no description of the labeling process (expert, crowdsourced, or automated), inter-annotator agreement, or cross-country consistency checks. Without these details it is impossible to rule out systematic annotation bias or noise that could inflate the claimed +11.3 AP gain for slate and the fusion-vs-baseline comparisons.
- [Results and training sections] Experimental protocol (results and training sections): the abstract reports concrete AP numbers and masking-strategy comparisons, but no information is given on training hyperparameters, data splits, optimizer settings, or statistical testing of the observed differences. This absence directly limits verification of the central claim that Perceiver IO fusion is superior.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to incorporate the requested details where they are available.
read point-by-point responses
-
Referee: [Dataset section] Dataset section (abstract and § on data construction): the 32,135-building dataset is central to all reported AP improvements, yet the manuscript supplies no description of the labeling process (expert, crowdsourced, or automated), inter-annotator agreement, or cross-country consistency checks. Without these details it is impossible to rule out systematic annotation bias or noise that could inflate the claimed +11.3 AP gain for slate and the fusion-vs-baseline comparisons.
Authors: We agree that the absence of labeling methodology details limits assessment of dataset quality. In the revised manuscript we will add a dedicated paragraph in the data construction section describing the annotation process (including whether labels were expert-annotated or otherwise obtained), any inter-annotator agreement figures that were computed, and the procedures used to ensure cross-country label consistency. If certain agreement statistics were not collected during dataset creation, we will explicitly state this. revision: yes
-
Referee: [Results and training sections] Experimental protocol (results and training sections): the abstract reports concrete AP numbers and masking-strategy comparisons, but no information is given on training hyperparameters, data splits, optimizer settings, or statistical testing of the observed differences. This absence directly limits verification of the central claim that Perceiver IO fusion is superior.
Authors: We acknowledge that full experimental details are required for reproducibility and verification. The revised manuscript will include a new subsection under the training or experimental protocol heading that specifies the train/validation/test splits, optimizer, learning-rate schedule, batch size, number of epochs, and any other hyperparameters. We will also report whether statistical significance tests were performed on the AP differences and, if so, the results; if no such tests were conducted we will state this explicitly. revision: yes
Circularity Check
No circularity: purely empirical evaluation on newly constructed dataset
full rationale
The paper reports experimental results from training and evaluating a Perceiver IO fusion model on a newly assembled dataset of 32,135 buildings. No equations, predictions, or uniqueness claims are present that reduce reported gains (e.g., +11.3 AP) to quantities defined by fitted parameters, self-citations, or ansatzes imported from prior author work. All comparisons are external benchmarks against other fusion strategies on held-out data, making the derivation chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- maximum number of street-level views
axioms (1)
- domain assumption DINOv2 provides suitable spatial patch tokens for both satellite and street-level imagery
Reference graph
Works this paper leans on
-
[1]
Street view imagery in urban analytics and gis: A review.Landscape and Urban Planning, 215:104217, 2021
Filip Biljecki and Koichi Ito. Street view imagery in urban analytics and gis: A review.Landscape and Urban Planning, 215:104217, 2021. 2
2021
-
[2]
Integrating aerial and street view images for urban land use classification.Re- mote Sensing, 10(10):1553, 2018
Rui Cao, Jiasong Zhu, Wei Tu, Qingquan Li, Jinzhou Cao, Bozhi Liu, Qian Zhang, and Guoping Qiu. Integrating aerial and street view images for urban land use classification.Re- mote Sensing, 10(10):1553, 2018. 1, 2
2018
-
[3]
Boan Chen, Quanlong Feng, Bowen Niu, Fengqin Yan, Bingbo Gao, Jianyu Yang, Jianhua Gong, and Jiantao Liu. Multi-modal fusion of satellite and street-view images for ur- ban village classification based on a dual-branch deep neural network.International Journal of Applied Earth Observa- tion and Geoinformation, 109:102794, 2022. 2
2022
-
[4]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 3
2016
-
[5]
Energy performance of build- ings directive.https : / / energy
European Commission. Energy performance of build- ings directive.https : / / energy . ec . europa . eu / topics / energy - efficiency / energy - efficient- buildings/energy- performance- buildings-directive_en, 2024. 1
2024
-
[6]
Runyu Fan, Jun Li, Fengpeng Li, Wei Han, and Lizhe Wang. Multilevel spatial-channel feature fusion network for urban village classification by fusing satellite and streetview im- ages.IEEE Transactions on Geoscience and Remote Sens- ing, 60:1–13, 2022. 2
2022
-
[7]
Automatic detection of building ty- pology using deep learning methods on street level images
Daniela Gonzalez, Diego Rueda-Plata, Ana B Acevedo, Juan C Duque, Ra ´ul Ramos-Poll ´an, Alejandro Betancourt, and Sebastian Garc ´ıa. Automatic detection of building ty- pology using deep learning methods on street level images. Building and Environment, 177:106805, 2020. 2
2020
-
[8]
Fusion of satellite and street view data for urban traffic accident hotspot identi- fication.International Journal of Applied Earth Observation and Geoinformation, 130:103853, 2024
Wentong Guo, Cheng Xu, and Sheng Jin. Fusion of satellite and street view data for urban traffic accident hotspot identi- fication.International Journal of Applied Earth Observation and Geoinformation, 130:103853, 2024. 2
2024
-
[9]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 4
2016
-
[10]
Urban neighbourhood environ- ment assessment based on street view image processing: A review of research trends.Environmental Challenges, 4: 100090, 2021
Nan He and Guanghao Li. Urban neighbourhood environ- ment assessment based on street view image processing: A review of research trends.Environmental Challenges, 4: 100090, 2021. 1, 2
2021
-
[11]
Model fusion for building type classification from aerial and street view images.Remote Sensing, 11(11):1259, 2019
Eike Jens Hoffmann, Yuanyuan Wang, Martin Werner, Jian Kang, and Xiao Xiang Zhu. Model fusion for building type classification from aerial and street view images.Remote Sensing, 11(11):1259, 2019. 1, 2
2019
-
[12]
Com- prehensive urban space representation with varying numbers of street-level images.Computers, Environment and Urban Systems, 106:102043, 2023
Yingjing Huang, Fan Zhang, Yong Gao, Wei Tu, Fabio Duarte, Carlo Ratti, Diansheng Guo, and Yu Liu. Com- prehensive urban space representation with varying numbers of street-level images.Computers, Environment and Urban Systems, 106:102043, 2023. 2 10
2023
-
[13]
Extensive exposure mapping in urban areas through deep analysis of street-level pictures for floor count determination.Urban Science, 1(2):16, 2017
Gianni Cristian Iannelli and Fabio Dell’Acqua. Extensive exposure mapping in urban areas through deep analysis of street-level pictures for floor count determination.Urban Science, 1(2):16, 2017. 2
2017
-
[14]
Attention-based deep multiple instance learning
Maximilian Ilse, Jakub Tomczak, and Max Welling. Attention-based deep multiple instance learning. InInter- national conference on machine learning, pages 2127–2136. PMLR, 2018. 4
2018
-
[15]
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Kop- pula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver io: A general architecture for structured inputs & outputs.arXiv preprint arXiv:2107.14795, 2021. 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Shunping Ji, Shiqing Wei, and Meng Lu. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set.IEEE Transactions on geoscience and remote sensing, 57(1):574–586, 2018. 2
2018
-
[17]
A scale robust con- volutional neural network for automatic building extraction from aerial and satellite imagery.International journal of remote sensing, 40(9):3308–3322, 2019
Shunping Ji, Shiqing Wei, and Meng Lu. A scale robust con- volutional neural network for automatic building extraction from aerial and satellite imagery.International journal of remote sensing, 40(9):3308–3322, 2019. 2
2019
-
[18]
Navjot Kaur, Cheng-Chun Lee, Ali Mostafavi, and Ali Mahdavi-Amiri. Large-scale building damage assessment using a novel hierarchical transformer architecture on satel- lite images.Computer-Aided Civil and Infrastructure Engi- neering, 38(15):2072–2091, 2023. 2
2072
-
[19]
Cnn algorithm for roof detection and material classi- fication in satellite images.Electronics, 10(13):1592, 2021
Jonguk Kim, Hyansu Bae, Hyunwoo Kang, and Suk Gyu Lee. Cnn algorithm for roof detection and material classi- fication in satellite images.Electronics, 10(13):1592, 2021. 2
2021
-
[20]
Enhanced facade parsing for street-level images using convolutional neural networks
Gefei Kong and Hongchao Fan. Enhanced facade parsing for street-level images using convolutional neural networks. IEEE Transactions on Geoscience and Remote Sensing, 59 (12):10519–10531, 2020. 2
2020
-
[21]
Dominik Laupheimer, Patrick Tutzauer, Norbert Haala, and Marc Spicker. Neural networks for the classification of build- ing use from street-view imagery.ISPRS Annals of the Pho- togrammetry, Remote Sensing and Spatial Information Sci- ences, 4:177–184, 2018. 2
2018
-
[22]
Take a look around: using street view and satellite images to estimate house prices.ACM Transactions on Intelligent Systems and Technology (TIST), 10(5):1–19, 2019
Stephen Law, Brooks Paige, and Chris Russell. Take a look around: using street view and satellite images to estimate house prices.ACM Transactions on Intelligent Systems and Technology (TIST), 10(5):1–19, 2019. 1, 2
2019
-
[23]
Hao Li, Zhendong Yuan, Gabriel Dax, Gefei Kong, Hongchao Fan, Alexander Zipf, and Martin Werner. Semi- supervised learning from street-view images and open- streetmap for automatic building height estimation.arXiv preprint arXiv:2307.02574, 2023. 2
-
[24]
Vision foundation models in remote sensing: A survey.IEEE Geoscience and Remote Sensing Magazine, 2025
Siqi Lu, Junlin Guo, James R Zimmer-Dauphinee, Jordan M Nieusma, Xiao Wang, Steven A Wernke, Yuankai Huo, et al. Vision foundation models in remote sensing: A survey.IEEE Geoscience and Remote Sensing Magazine, 2025. 2
2025
-
[25]
Planet dump re- trieved from https://planet.osm.org .https : //www.openstreetmap.org, 2025
OpenStreetMap contributors. Planet dump re- trieved from https://planet.osm.org .https : //www.openstreetmap.org, 2025. 3
2025
-
[26]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Using google street view to audit neighborhood environ- ments.American journal of preventive medicine, 40(1):94– 100, 2011
Andrew G Rundle, Michael DM Bader, Catherine A Richards, Kathryn M Neckerman, and Julien O Teitler. Using google street view to audit neighborhood environ- ments.American journal of preventive medicine, 40(1):94– 100, 2011. 1
2011
-
[28]
Self-supervised vision transformers for land- cover segmentation and classification
Linus Scheibenreif, Jo ¨elle Hanna, Michael Mommert, and Damian Borth. Self-supervised vision transformers for land- cover segmentation and classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1422–1431, 2022. 2
2022
-
[29]
Understanding urban landuse from the above and ground perspectives: A deep learning, multimodal solution.Remote sensing of environment, 228:129–143, 2019
Shivangi Srivastava, John E Vargas-Munoz, and Devis Tuia. Understanding urban landuse from the above and ground perspectives: A deep learning, multimodal solution.Remote sensing of environment, 228:129–143, 2019. 2
2019
-
[30]
Esra Suel, Samir Bhatt, Michael Brauer, Seth Flaxman, and Majid Ezzati. Multimodal deep learning from satellite and street-level imagery for measuring income, overcrowding, and environmental deprivation in urban areas.Remote Sens- ing of Environment, 257:112339, 2021. 2
2021
-
[31]
Hierar- chynet: Hierarchical cnn-based urban building classification
Salma Taoufiq, Bal ´azs Nagy, and Csaba Benedek. Hierar- chynet: Hierarchical cnn-based urban building classification. Remote Sensing, 12(22):3794, 2020. 2
2020
-
[32]
Improving facade parsing with vi- sion transformers and line integration.Advanced Engineer- ing Informatics, 60:102463, 2024
Bowen Wang, Jiaxin Zhang, Ran Zhang, Yunqin Li, Liangzhi Li, and Yuta Nakashima. Improving facade parsing with vi- sion transformers and line integration.Advanced Engineer- ing Informatics, 60:102463, 2024. 2
2024
-
[33]
Building extraction with vision transformer.IEEE Transac- tions on Geoscience and Remote Sensing, 60:1–11, 2022
Libo Wang, Shenghui Fang, Xiaoliang Meng, and Rui Li. Building extraction with vision transformer.IEEE Transac- tions on Geoscience and Remote Sensing, 60:1–11, 2022. 2
2022
-
[34]
Segformer: Simple and efficient design for semantic segmentation with transform- ers.Advances in neural information processing systems, 34: 12077–12090, 2021
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transform- ers.Advances in neural information processing systems, 34: 12077–12090, 2021. 3
2021
-
[35]
Flood vulnerability assess- ment of urban buildings based on integrating high-resolution remote sensing and street view images.Sustainable Cities and Society, 92:104467, 2023
Ziyao Xing, Shuai Yang, Xuli Zan, Xinrui Dong, Yu Yao, Zhe Liu, and Xiaodong Zhang. Flood vulnerability assess- ment of urban buildings based on integrating high-resolution remote sensing and street view images.Sustainable Cities and Society, 92:104467, 2023. 2
2023
-
[36]
Joseph Z Xu, Wenhan Lu, Zebo Li, Pranav Khaitan, and Va- leriya Zaytseva. Building damage detection in satellite im- agery using convolutional neural networks.arXiv preprint arXiv:1910.06444, 2019. 2
-
[37]
Deep cnn-based methods to evalu- ate neighborhood-scale urban valuation through street scenes perception
Junhan Zhao, Xiang Liu, Yanqun Kuang, Yingjie Victor Chen, and Baijian Yang. Deep cnn-based methods to evalu- ate neighborhood-scale urban valuation through street scenes perception. In2018 IEEE third international conference on data science in cyberspace (dsc), pages 20–27. IEEE, 2018. 2
2018
-
[38]
Building extraction from satellite images using mask r-cnn with building boundary regularization
Kang Zhao, Jungwon Kang, Jaewook Jung, and Gunho Sohn. Building extraction from satellite images using mask r-cnn with building boundary regularization. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 247–251, 2018. 2 11
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.