Sparse-LiDAR Prompting of Monocular Geometry Foundations: An Empirical Study Toward Long-Range Driving Depth
Pith reviewed 2026-06-29 18:50 UTC · model grok-4.3
The pith
Sparse LiDAR injection into MoGe-2 cuts absolute relative depth error by 39-51% at 100-150 meters on simulated driving scenes
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
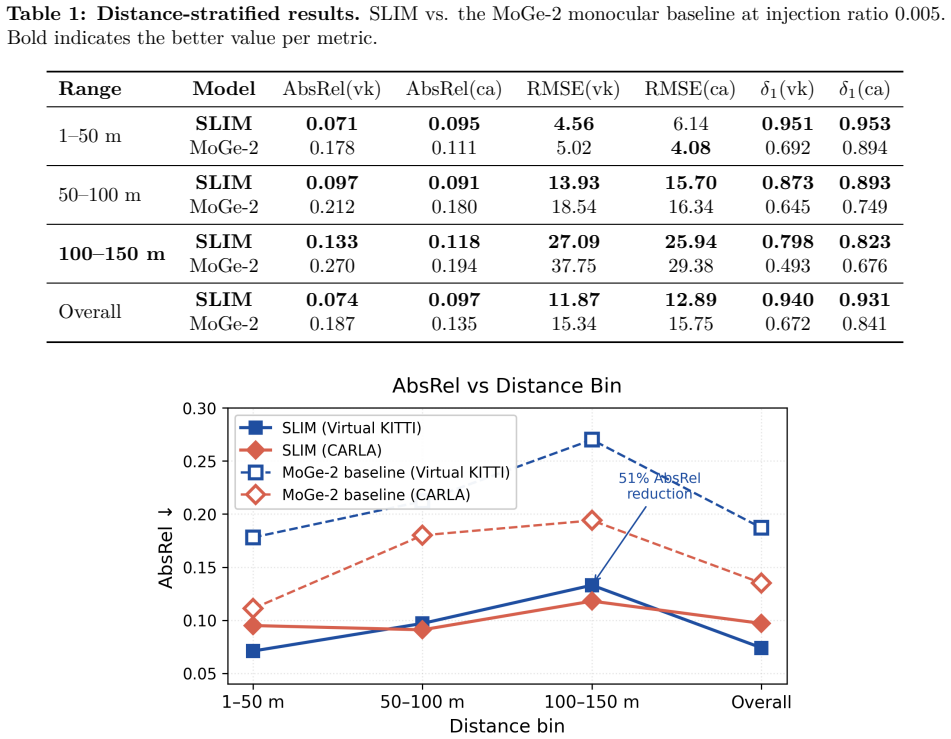
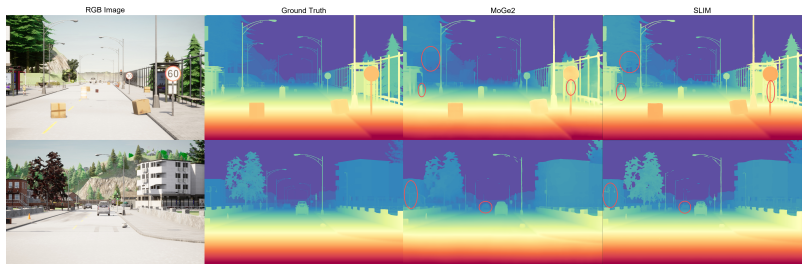
SLIM adapts MoGe-2 to accept truly sparse LiDAR input through a partial-convolution sparse encoder and a multi-scale fusion neck that fuses LiDAR features into the point-map decoder at five scales. The model is trained density-agnostically with random injection ratios in [0.005, 0.30] so a single set of weights handles diverse input densities. On Virtual KITTI and CARLA this yields an absolute relative error reduction of approximately 39-51% relative to the MoGe-2 baseline at 100-150 m distances.
What carries the argument
Partial-convolution sparse encoder plus multi-scale fusion neck that injects LiDAR features into the point-map decoder at five scales, under density-agnostic training with random injection ratios
If this is right
- A single model trained density-agnostically performs across injection ratios from 0.5% to 30% without retraining
- Partial-convolution injection improves absolute relative error and RMSE on Virtual KITTI in all six tested ratios and improves absolute relative error in five of six ratios on CARLA
- Error reductions concentrate in the long-range regime (100-150 m) where baseline monocular point-map models show largest shortfalls
- The method operates directly on point-map foundations without requiring pre-interpolated dense priors used in earlier disparity-based prompting work
Where Pith is reading between the lines
- If the simulated gains hold, sparse-LiDAR prompting could lower the sensor density required for reliable long-range perception in driving systems
- The five-scale fusion pattern may transfer to other point-map foundation models beyond MoGe-2 with similar architecture
- Real sensor noise and calibration drift absent from simulation could narrow the observed accuracy margin and would require targeted robustness tests
- The density-agnostic training schedule might also stabilize performance when LiDAR point density varies dynamically during a drive
Load-bearing premise
Performance gains measured on the simulated Virtual KITTI and CARLA environments will translate to real-world driving data with actual sensors, lighting, and weather variations
What would settle it
Evaluating SLIM and the MoGe-2 baseline on real-world long-range depth datasets such as the original KITTI or nuScenes with ground-truth depths beyond 80 m would show whether the reported error reductions persist outside simulation
Figures

read the original abstract
Sparse-LiDAR-prompted depth foundation models (PromptDA, Prior Depth Anything, DMD3C) have shown strong results on indoor scenes or within KITTI's standard 80-meter evaluation cap. However, two limitations remain: (i) systematic distance-stratified evaluation in long-range driving regimes (50-150 m) is largely absent; (ii) prior approaches built on disparity-based foundations rely on pre-interpolated dense priors, leaving truly sparse LiDAR injection on point-map foundations (e.g., MoGe-2, NeurIPS 2025) unexplored. We present SLIM (Sparse-LiDAR Injected Monocular geometry), the first adaptation of MoGe-2 to accept truly sparse LiDAR input. SLIM integrates a partial-convolution sparse encoder with a multi-scale fusion neck that fuses LiDAR features into the point-map decoder at five scales. We adopt density-agnostic training (random injection ratio in [0.005, 0.30]) so a single model serves diverse input densities. On Virtual KITTI and CARLA, SLIM reduces the absolute relative error of the MoGe-2 baseline by approximately 39-51% at 100-150 m. Ablation across six injection ratios shows partial-convolution injection improves both AbsRel and RMSE on Virtual KITTI in all six settings; on CARLA, AbsRel improves in five of six settings (one near-tie at 0.015 differs by 0.0013), and RMSE is comparable across encoders, with partial-convolution improving in three settings (by up to 0.31 unit) and losing by at most 0.11 unit in the other three.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SLIM, an adaptation of the MoGe-2 point-map foundation model to accept truly sparse LiDAR inputs via a partial-convolution sparse encoder and multi-scale fusion neck at five scales. It uses density-agnostic training with random injection ratios in [0.005, 0.30] and reports that SLIM reduces AbsRel of the MoGe-2 baseline by 39-51% at 100-150 m on Virtual KITTI and CARLA, with ablations across six injection ratios showing partial-convolution improvements in AbsRel on both datasets in nearly all settings.
Significance. If the reported numerical gains hold under the described protocol, the work supplies a useful empirical ablation on sparse prompting of point-map foundations in long-range regimes beyond the typical 80 m KITTI cap, with the density-agnostic training and consistent cross-ratio gains as clear strengths. The partial-convolution design is shown to be effective in the provided synthetic settings.
major comments (2)
- [Abstract and §4] Abstract and §4 (results): the central 39-51% AbsRel reduction claim at 100-150 m is presented without error bars, standard deviations across runs, or explicit description of the MoGe-2 baseline implementation details and any simulation-specific artifacts (e.g., perfect depth values or idealized sparsity) that could affect the long-range regime; these omissions directly impact assessment of result reliability.
- [§1 and §5] §1 and §5 (discussion): the framing as an empirical study 'toward long-range driving depth' relies on the assumption that gains on Virtual KITTI/CARLA will inform real driving, yet no analysis or caveats address domain shift factors such as sensor noise, calibration, or weather; while the synthetic results themselves can stand, this limits the load-bearing relevance of the application claim.
minor comments (2)
- [§3.2] Figure captions and §3.2: the multi-scale fusion neck diagram would benefit from explicit labeling of the five fusion scales and how partial-convolution features are injected at each.
- [Results tables] Table 1/2 (assumed results tables): ensure all six injection ratios are listed with both AbsRel and RMSE for both encoders to allow direct comparison of the near-tie case mentioned in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We address each major comment below and will incorporate the agreed changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results): the central 39-51% AbsRel reduction claim at 100-150 m is presented without error bars, standard deviations across runs, or explicit description of the MoGe-2 baseline implementation details and any simulation-specific artifacts (e.g., perfect depth values or idealized sparsity) that could affect the long-range regime; these omissions directly impact assessment of result reliability.
Authors: We agree the omissions affect reliability assessment. All reported results used single runs due to computational limits, so error bars and standard deviations cannot be added; we will explicitly state this limitation in the revised §4. We will expand the MoGe-2 baseline description in §4 to detail the point-map prompting procedure and any simulator-specific assumptions. A new paragraph will discuss simulation artifacts such as perfect ground-truth depths and idealized sparsity patterns. revision: partial
-
Referee: [§1 and §5] §1 and §5 (discussion): the framing as an empirical study 'toward long-range driving depth' relies on the assumption that gains on Virtual KITTI/CARLA will inform real driving, yet no analysis or caveats address domain shift factors such as sensor noise, calibration, or weather; while the synthetic results themselves can stand, this limits the load-bearing relevance of the application claim.
Authors: We agree that explicit caveats are needed. In the revised §1 and §5 we will add a dedicated limitations paragraph addressing domain shift, specifically noting the lack of real sensor noise, calibration errors, and weather variation in the synthetic benchmarks. This will clarify that the reported gains are confined to controlled synthetic settings and that real-world transfer would require separate validation. revision: yes
Circularity Check
Empirical ablation study; no derivation chain present
full rationale
The paper reports experimental results from an ablation study on simulated datasets (Virtual KITTI, CARLA) using density-agnostic training and partial-convolution fusion. No equations, derivations, or first-principles claims are described that could reduce to fitted parameters or self-citations by construction. The central numerical claims (39-51% AbsRel reduction) are direct metric outputs from test-set evaluation, not outputs of any internal model that re-uses the same quantities as inputs. This is a standard empirical paper with no load-bearing mathematical steps to inspect for circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- random injection ratio range [0.005, 0.30]
axioms (1)
- domain assumption MoGe-2 point-map decoder can accept multi-scale feature fusion from a partial-convolution sparse encoder without loss of its original geometric properties
Reference graph
Works this paper leans on
-
[1]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
R. Wanget al.MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details. In NeurIPS, 2025. arXiv:2507.02546
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Linet al.Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation
H. Linet al.Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation. In CVPR, 2025. arXiv:2412.14015. 5
- [3]
-
[4]
Lianget al.Distilling Monocular Foundation Model for Fine-grained Depth Completion (DMD3C)
J. Lianget al.Distilling Monocular Foundation Model for Fine-grained Depth Completion (DMD3C). InCVPR, 2025. arXiv:2503.16970
-
[5]
L. Yanget al.Depth Anything. InCVPR, 2024. arXiv:2401.10891
-
[6]
TTA-Depth: Test-Time Adaptation for Rescaling Disparity in Zero-Shot Metric Depth Estimation. arXiv:2412.14103
-
[7]
DOC-Depth: Dense Depth Generation from Any LiDAR Sensor. arXiv:2502.02144
-
[8]
Image Inpainting for Irregular Holes Using Partial Convolutions
G. Liuet al.Image Inpainting for Irregular Holes Using Partial Convolutions. InECCV, 2018. arXiv:1804.07723
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Squeeze-and-Excitation Networks
J. Huet al.Squeeze-and-Excitation Networks. InCVPR, 2018. arXiv:1709.01507
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Y. Cabonet al.Virtual KITTI 2. arXiv:2001.10773
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[11]
Dosovitskiyet al.CARLA: An Open Urban Driving Simulator
A. Dosovitskiyet al.CARLA: An Open Urban Driving Simulator. InCoRL, 2017. 6
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.