Orion: Enabling Self-adaptive Memory Management for On-device Online Continual Learning
Pith reviewed 2026-06-29 16:23 UTC · model grok-4.3
The pith
Orion uses a buckets-effect runtime indicator to dynamically reallocate memory across online continual learning components for on-device robotic deployment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Orion is a holistic framework that leverages URGE, a unified runtime indicator grounded in the Buckets effect, to dynamically reallocate memory across OCL components by jointly coordinating batch processing, replay buffers, and optimization strategies at both the OS and application level, together with system-level data prefetching, thereby enabling feasible on-device deployment while achieving significant training speedups with minimal runtime, memory, and energy overhead.
What carries the argument
URGE, a unified runtime indicator grounded in the Buckets effect principle that system performance is bounded by its scarcest resource, which dynamically coordinates memory reallocation across OCL components.
If this is right
- State-of-the-art OCL algorithms become deployable on memory-constrained robotic hardware without offline retuning.
- Training latency decreases while plasticity-stability balance is preserved across changing data distributions.
- Memory pressure shifts during learning are handled automatically rather than through manual intervention.
- System-level prefetching further reduces I/O stalls without extra application changes.
- The same prototype integrates with Avalanche-lib and runs on standard autonomous-robot platforms.
Where Pith is reading between the lines
- Similar indicator-driven reallocation could be tested on other edge devices such as drones or wearable sensors facing variable memory pressure.
- The buckets-effect logic may generalize to joint management of compute, bandwidth, and energy in multi-task on-device learning.
- Developers could explore whether URGE-style indicators improve non-continual on-device training under tight memory caps.
Load-bearing premise
URGE can reliably coordinate memory reallocation across OCL components at OS and application levels without introducing instability or unacceptable overhead in real robotic workloads.
What would settle it
A controlled run on the target robotic platform in which URGE-driven reallocation produces either measurable instability, increased energy draw, or slower convergence compared with static allocation under identical data streams.
Figures

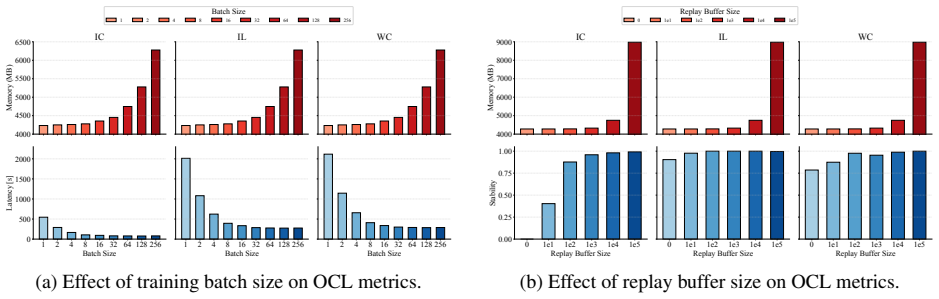
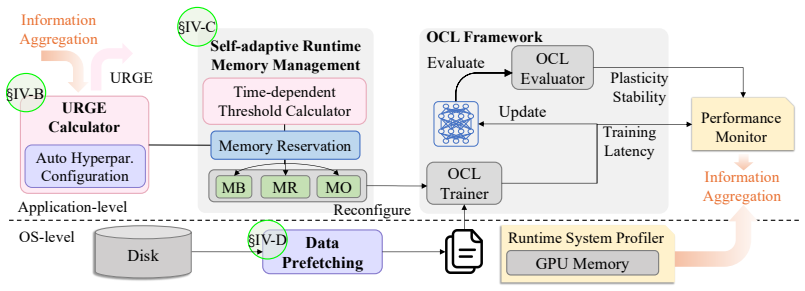

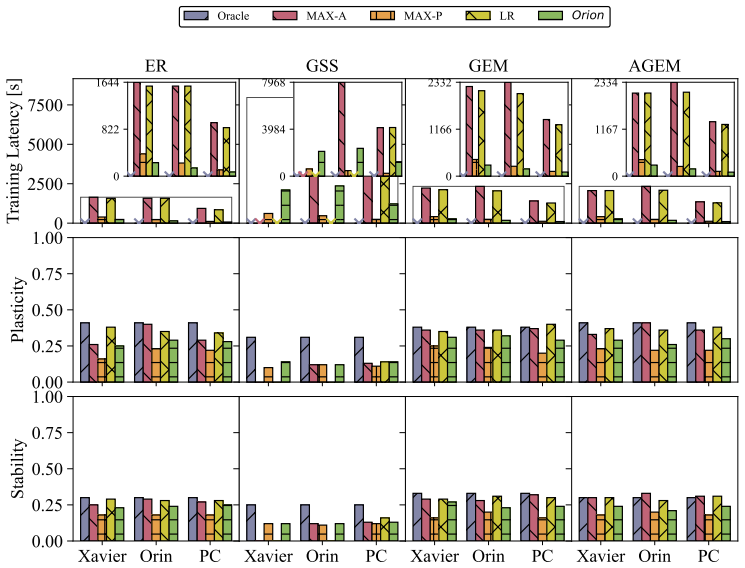

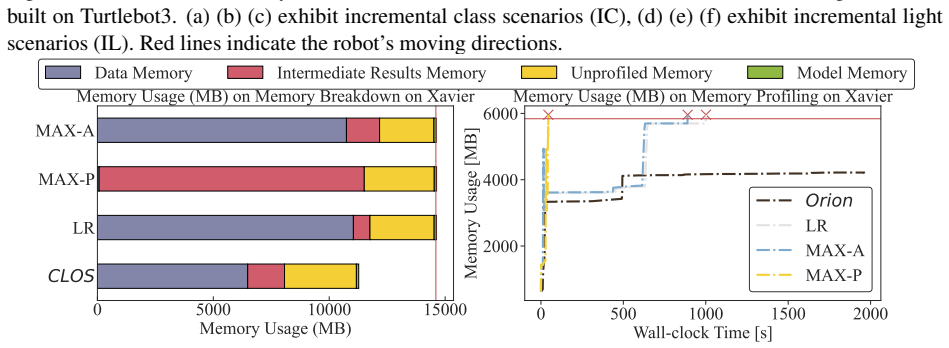

read the original abstract
Online continual learning (OCL) enables real-time adaptation to new data, making it crucial for dynamic robotic applications. However, its practical deployment is hindered by memory constraints in resource-limited systems, which affect key trade-offs in training latency, plasticity, and stability. Unlike offline parameter tuning, which cannot account for the dynamic shift in memory pressure and workload complexity as OCL progresses, an online and self-adaptive approach is essential for robust on-device deployment. This paper proposes Orion, a holistic framework designed to co-optimize training latency, plasticity, and stability of state-of-the-art OCL models under strict memory constraints, enabling feasible on-device deployment. At its core, Orion leverages URGE, a unified runtime indicator grounded in the ``Buckets effect'' principle that system performance is bounded by its scarcest resource, to dynamically reallocate memory across OCL components by jointly coordinating batch processing, replay buffers, and optimization strategies at both the OS and application level. Furthermore, Orion introduces system-level data prefetching techniques to maximize efficiency. A system prototype of Orion has been implemented using the widely adopted \texttt{Avalanche-lib} and thoroughly evaluated across a diverse range of OCL algorithms, benchmarks, and hardware platforms commonly used in autonomous robotic applications. To further demonstrate its practical utility, Orion is integrated into a realistic autonomous navigational robot powered by OCL. The results show that Orion achieves significant training speedups while maintaining balanced performance and effectively adapting to various scenarios, all with minimal runtime, memory, and energy overhead, making Orion a practical solution for on-device continual learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Orion, a holistic framework for co-optimizing training latency, plasticity, and stability in on-device online continual learning under memory constraints. It introduces URGE, a unified runtime indicator based on the buckets effect principle, to dynamically reallocate memory by jointly coordinating batch processing, replay buffers, and optimization strategies at both OS and application levels, along with system-level data prefetching. The framework is implemented using Avalanche-lib and evaluated across OCL algorithms, benchmarks, and hardware platforms, with additional integration into an autonomous navigational robot, claiming significant speedups with balanced performance and minimal overhead.
Significance. If the claims hold with independent measurements, Orion would represent a practical advance for on-device OCL in dynamic robotic settings by providing online self-adaptation to varying memory pressure, which static offline tuning cannot achieve. The prototype implementation, evaluation across algorithms/benchmarks/hardware, and real-robot integration are strengths that support applicability.
major comments (2)
- [Abstract] Abstract: the central claim that Orion 'achieves significant training speedups while maintaining balanced performance' with 'minimal runtime, memory, and energy overhead' is load-bearing for the practicality assertion, yet no quantitative results, baselines, error bars, or stability metrics (e.g., variance under memory pressure shifts) are supplied, preventing verification that numbers are independent of tuning parameters.
- [Evaluation] Evaluation: the assumption that URGE can jointly coordinate reallocation without instability is load-bearing for the self-adaptive claim, but no concrete metrics on robustness (such as plasticity/stability trade-off variance during sudden memory pressure changes in robotic workloads) are reported.
minor comments (1)
- [Abstract] The 'Buckets effect' principle is invoked without a citation or short explanation of its mapping to OCL memory components.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Orion 'achieves significant training speedups while maintaining balanced performance' with 'minimal runtime, memory, and energy overhead' is load-bearing for the practicality assertion, yet no quantitative results, baselines, error bars, or stability metrics (e.g., variance under memory pressure shifts) are supplied, preventing verification that numbers are independent of tuning parameters.
Authors: We agree that the abstract would be strengthened by including quantitative highlights. The evaluation sections of the manuscript report detailed results with baselines, multiple runs, error bars, and overhead measurements across algorithms, benchmarks, and hardware. In the revision we will update the abstract to summarize key quantitative outcomes (e.g., observed speedups and overhead ranges) with explicit pointers to the corresponding figures and tables. revision: yes
-
Referee: [Evaluation] Evaluation: the assumption that URGE can jointly coordinate reallocation without instability is load-bearing for the self-adaptive claim, but no concrete metrics on robustness (such as plasticity/stability trade-off variance during sudden memory pressure changes in robotic workloads) are reported.
Authors: The referee correctly notes the absence of explicit robustness metrics for sudden memory-pressure shifts. While the current evaluation demonstrates adaptation across robotic workloads and varying conditions, it does not isolate variance in the plasticity/stability trade-off under abrupt pressure changes. We will add these metrics in a revised evaluation section, including targeted analysis or additional runs that quantify the trade-off variance during memory-pressure transitions. revision: yes
Circularity Check
No significant circularity; claims rest on independent empirical evaluation
full rationale
The abstract describes Orion as a framework that uses the URGE indicator (grounded in the external 'Buckets effect' principle) to coordinate memory reallocation across OCL components, with results from prototype evaluation on Avalanche-lib across algorithms/benchmarks/hardware and robot integration. No equations, fitted parameters, self-citations, or derivation steps are presented that would reduce claimed speedups, overhead, or stability metrics to quantities defined by the same inputs or by construction. The performance assertions appear as outcomes of system implementation and testing rather than tautological renamings or self-referential fits, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Continual learning with tiny episodic memories
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, P Dokania, P Torr, and M Ranzato. Continual learning with tiny episodic memories. InWorkshop on Multi-Task and Lifelong Reinforcement Learning, 2019
2019
-
[2]
Computationally budgeted continual learning: What does matter? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3698– 3707, 2023
Ameya Prabhu, Hasan Abed Al Kader Hammoud, Puneet K Dokania, Philip HS Torr, Ser-Nam Lim, Bernard Ghanem, and Adel Bibi. Computationally budgeted continual learning: What does matter? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3698– 3707, 2023
2023
-
[3]
Gradient episodic memory for continual learning.Ad- vances in neural information processing systems, 30, 2017
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning.Ad- vances in neural information processing systems, 30, 2017
2017
-
[4]
Efficient Lifelong Learning with A-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient life- long learning with a-gem.arXiv preprint arXiv:1812.00420, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Gradient based sample selection for online continual learning.Advances in neural information processing systems, 32, 2019
Rahaf Aljundi, Min Lin, Baptiste Goujaud, and Yoshua Bengio. Gradient based sample selection for online continual learning.Advances in neural information processing systems, 32, 2019
2019
-
[6]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13): 3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13): 3521–3526, 2017
2017
-
[7]
Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
2017
-
[8]
A comprehensive empirical evaluation on online continual learn- ing
Albin Soutif-Cormerais, Antonio Carta, Andrea Cossu, Julio Hurtado, Vincenzo Lomonaco, Joost Van de Weijer, and Hamed Hemati. A comprehensive empirical evaluation on online continual learn- ing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3518–3528, 2023
2023
-
[9]
Online active continual learning for robotic lifelong object recognition.IEEE Transactions on Neural Networks and Learning Systems, 2023
Xiangli Nie, Zhiguang Deng, Mingdong He, Mingyu Fan, and Zheng Tang. Online active continual learning for robotic lifelong object recognition.IEEE Transactions on Neural Networks and Learning Systems, 2023
2023
-
[10]
Covio: Online continual learning for visual-inertial odometry
Niclas Vödisch, Daniele Cattaneo, Wolfram Burgard, and Abhinav Valada. Covio: Online continual learning for visual-inertial odometry. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2464–2473, 2023. 19
2023
-
[11]
Niclas Vödisch, Kürsat Petek, Wolfram Burgard, and Abhinav Valada. Codeps: Online continual learning for depth estimation and panoptic segmentation.arXiv preprint arXiv:2303.10147, 2023
-
[12]
From continual learning to causal discovery in robotics
Luca Castri, Sariah Mghames, and Nicola Bellotto. From continual learning to causal discovery in robotics. InAAAI Bridge Program on Continual Causality, pages 85–91. PMLR, 2023
2023
-
[13]
Elvin Hajizada, Balachandran Swaminathan, and Yulia Sandamirskaya. Continual learning for au- tonomous robots: A prototype-based approach.arXiv preprint arXiv:2404.00418, 2024
-
[14]
Online con- tinual learning in image classification: An empirical survey.Neurocomputing, 469:28–51, 2022
Zheda Mai, Ruiwen Li, Jihwan Jeong, David Quispe, Hyunwoo Kim, and Scott Sanner. Online con- tinual learning in image classification: An empirical survey.Neurocomputing, 469:28–51, 2022
2022
-
[15]
Online continual learning with maximal interfered retrieval.Advances in neural information processing systems, 32, 2019
Rahaf Aljundi, Eugene Belilovsky, Tinne Tuytelaars, Laurent Charlin, Massimo Caccia, Min Lin, and Lucas Page-Caccia. Online continual learning with maximal interfered retrieval.Advances in neural information processing systems, 32, 2019
2019
-
[16]
Real-time evaluation in online continual learn- ing: A new hope
Yasir Ghunaim, Adel Bibi, Kumail Alhamoud, Motasem Alfarra, Hasan Abed Al Kader Hammoud, Ameya Prabhu, Philip HS Torr, and Bernard Ghanem. Real-time evaluation in online continual learn- ing: A new hope. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11888–11897, 2023
2023
-
[17]
Young D Kwon, Jagmohan Chauhan, Hong Jia, Stylianos I Venieris, and Cecilia Mascolo. Lifelearner: Hardware-aware meta continual learning system for embedded computing platforms.arXiv preprint arXiv:2311.11420, 2023
-
[18]
Ekya: Continuous learning of video analytics models on edge compute servers
Romil Bhardwaj, Zhengxu Xia, Ganesh Ananthanarayanan, Junchen Jiang, Yuanchao Shu, Nikolaos Karianakis, Kevin Hsieh, Paramvir Bahl, and Ion Stoica. Ekya: Continuous learning of video analytics models on edge compute servers. In19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), pages 119–135, 2022
2022
-
[19]
Latent replay for real-time continual learning
Lorenzo Pellegrini, Gabriele Graffieti, Vincenzo Lomonaco, and Davide Maltoni. Latent replay for real-time continual learning. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10203–10209. IEEE, 2020
2020
-
[20]
Saunders Philadelphia, 1971
Eugene Pleasants Odum, Gary W Barrett, et al.Fundamentals of ecology, volume 3. Saunders Philadelphia, 1971
1971
-
[21]
Avalanche: A pytorch library for deep continual learning.Journal of Machine Learning Research, 24(363):1–6, 2023
Antonio Carta, Lorenzo Pellegrini, Andrea Cossu, Hamed Hemati, and Vincenzo Lomonaco. Avalanche: A pytorch library for deep continual learning.Journal of Machine Learning Research, 24(363):1–6, 2023. URLhttp://jmlr.org/papers/v24/23-0130.html
2023
-
[22]
Hayes, Matthias De Lange, Marc Masana, Jary Pomponi, Gido van de Ven, Martin Mundt, Qi She, Keiland Cooper, Jeremy Forest, Eden Belouadah, Simone Calderara, German I
Vincenzo Lomonaco, Lorenzo Pellegrini, Andrea Cossu, Antonio Carta, Gabriele Graffieti, Tyler L. Hayes, Matthias De Lange, Marc Masana, Jary Pomponi, Gido van de Ven, Martin Mundt, Qi She, Keiland Cooper, Jeremy Forest, Eden Belouadah, Simone Calderara, German I. Parisi, Fabio Cuz- zolin, Andreas Tolias, Simone Scardapane, Luca Antiga, Subutai Amhad, Adri...
2021
-
[23]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[24]
Fine-grained continual learning.arXiv preprint arXiv:1907.03799, 1, 2019
Vincenzo Lomonaco, Davide Maltoni, Lorenzo Pellegrini, et al. Fine-grained continual learning.arXiv preprint arXiv:1907.03799, 1, 2019. 20
-
[25]
Core50: a new dataset and benchmark for continual object recogni- tion
V Lomanco and Davide Maltoni. Core50: a new dataset and benchmark for continual object recogni- tion. InProceedings of the 1st Annual Conference on Robot Learning, pages 17–26, 2017
2017
-
[26]
Timm Hess, Martin Mundt, Iuliia Pliushch, and Visvanathan Ramesh. A procedural world generation framework for systematic evaluation of continual learning.arXiv preprint arXiv:2106.02585, 2021
-
[27]
Jetson agx xavier.https://developer.nvidia.com/embedded/ jetson-agx-xavier, 2020
NVIDIA. Jetson agx xavier.https://developer.nvidia.com/embedded/ jetson-agx-xavier, 2020
2020
-
[28]
Jetson agx orin.https://www.nvidia.com/en-us/autonomous-machines/ embedded-systems/jetson-orin/, 2022
NVIDIA. Jetson agx orin.https://www.nvidia.com/en-us/autonomous-machines/ embedded-systems/jetson-orin/, 2022
2022
-
[29]
Person re-identification for robot person following with online continual learning.IEEE Robotics and Automation Letters, 2024
Hanjing Ye, Jieting Zhao, Yu Zhan, Weinan Chen, Li He, and Hong Zhang. Person re-identification for robot person following with online continual learning.IEEE Robotics and Automation Letters, 2024
2024
-
[30]
Incremental learning of retrievable skills for efficient continual task adaptation.Advances in Neural Information Processing Systems, 37:17286–17312, 2024
Daehee Lee, Minjong Yoo, Woo Kyung Kim, Wonje Choi, and Honguk Woo. Incremental learning of retrievable skills for efficient continual task adaptation.Advances in Neural Information Processing Systems, 37:17286–17312, 2024
2024
-
[31]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Autoware on board: Enabling autonomous vehicles with embedded systems
Shinpei Kato, Shota Tokunaga, Yuya Maruyama, Seiya Maeda, Manato Hirabayashi, Yuki Kitsukawa, Abraham Monrroy, Tomohito Ando, Yusuke Fujii, and Takuya Azumi. Autoware on board: Enabling autonomous vehicles with embedded systems. In2018 ACM/IEEE 9th International Conference on Cyber-Physical Systems (ICCPS), pages 287–296. IEEE, 2018
2018
-
[33]
Deep learning for autonomous vehicles
Branislav Kisa ˇcanin. Deep learning for autonomous vehicles. In2017 IEEE 47th International Sym- posium on Multiple-Valued Logic (ISMVL), pages 142–142. IEEE, 2017
2017
-
[34]
Alexander Popov, Patrik Gebhardt, Ke Chen, Ryan Oldja, Heeseok Lee, Shane Murray, Ruchi Bhar- gava, and Nikolai Smolyanskiy. Nvradarnet: Real-time radar obstacle and free space detection for autonomous driving.arXiv preprint arXiv:2209.14499, 2022
-
[35]
Duckiebot (db-j).https://get.duckietown.com/products/ duckiebot-db21, 2022
NVIDIA. Duckiebot (db-j).https://get.duckietown.com/products/ duckiebot-db21, 2022
2022
-
[36]
Sparkfun jetbot ai kit.https://www.sparkfun.com/products/18486, 2022
NVIDIA. Sparkfun jetbot ai kit.https://www.sparkfun.com/products/18486, 2022
2022
-
[37]
Waveshare jetbot ai kit.https://www.amazon.com/ Waveshare-JetBot-AI-Kit-Accessories/dp/B07V8JL4TF/, 2022
NVIDIA. Waveshare jetbot ai kit.https://www.amazon.com/ Waveshare-JetBot-AI-Kit-Accessories/dp/B07V8JL4TF/, 2022
2022
-
[38]
Deep residual learning for image recog- nition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recog- nition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[39]
ROBOTIS, 2024
ROBOTIS.TurtleBot3 Overview. ROBOTIS, 2024. URLhttps://emanual.robotis.com/ docs/en/platform/turtlebot3/overview/. Accessed: 15 April 2024
2024
-
[40]
ImageNet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848. 21
-
[41]
Joohyung Kim, Janghun Hyeon, Hyunga Choi, Bumchul Jang, Bokyeon Jeong, and Nakju Doh. Cloc: Confident initial estimation of long-term visual localization using a few sequential images in large- scale spaces.IEEE Sensors Journal, 23(8):8613–8629, 2023. doi: 10.1109/JSEN.2023.3253872
-
[42]
Continual variational autoencoder via continual generative knowledge distillation
Fei Ye and Adrian G Bors. Continual variational autoencoder via continual generative knowledge distillation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 10918– 10926, 2023
2023
-
[43]
Wenxuan Zhang, Youssef Mohamed, Bernard Ghanem, Philip HS Torr, Adel Bibi, and Mohamed Elhoseiny. Continual learning on a diet: Learning from sparsely labeled streams under constrained computation.arXiv preprint arXiv:2404.12766, 2024
-
[44]
A unified architecture for accelerating distributed{DNN}training in heterogeneous{GPU/CPU}clusters
Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, and Chuanxiong Guo. A unified architecture for accelerating distributed{DNN}training in heterogeneous{GPU/CPU}clusters. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pages 463–479, 2020
2020
-
[45]
Varuna: scalable, low-cost training of massive deep learning models
Sanjith Athlur, Nitika Saran, Muthian Sivathanu, Ramachandran Ramjee, and Nipun Kwatra. Varuna: scalable, low-cost training of massive deep learning models. InProceedings of the Seventeenth Euro- pean Conference on Computer Systems, pages 472–487, 2022
2022
-
[46]
Large scale distributed deep networks.Advances in neural information processing systems, 25, 2012
Jeffrey Dean, Greg Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Mark Mao, Marc’aurelio Ran- zato, Andrew Senior, Paul Tucker, Ke Yang, et al. Large scale distributed deep networks.Advances in neural information processing systems, 25, 2012
2012
-
[47]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catan- zaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[48]
Pipefisher: Efficient training of large language models using pipelining and fisher information matrices.Proceedings of Machine Learning and Systems, 5, 2023
Kazuki Osawa, Shigang Li, and Torsten Hoefler. Pipefisher: Efficient training of large language models using pipelining and fisher information matrices.Proceedings of Machine Learning and Systems, 5, 2023
2023
-
[49]
Design and implemen- tation of a lightweight on-device ai-based real-time fault diagnosis system using continual learning
Youngjun Kim, Taewan Kim, Suhyun Kim, Seongjae Lee, and Taehyoun Kim. Design and implemen- tation of a lightweight on-device ai-based real-time fault diagnosis system using continual learning. IEMEK Journal of Embedded Systems and Applications, 19(3):151–158, 2024
2024
-
[50]
Contauth: Continual learning framework for behavioral-based user authentication.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 4(4):1–23, 2020
Jagmohan Chauhan, Young D Kwon, Pan Hui, and Cecilia Mascolo. Contauth: Continual learning framework for behavioral-based user authentication.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 4(4):1–23, 2020
2020
-
[51]
Continual learning for on-device speech recognition using disentangled con- formers
Anuj Diwan, Ching-Feng Yeh, Wei-Ning Hsu, Paden Tomasello, Eunsol Choi, David Harwath, and Abdelrahman Mohamed. Continual learning for on-device speech recognition using disentangled con- formers. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 1–5. IEEE, 2023
2023
-
[52]
Lorenzo Pellegrini, Vincenzo Lomonaco, Gabriele Graffieti, and Davide Maltoni. Continual learning at the edge: Real-time training on smartphone devices.arXiv preprint arXiv:2105.13127, 2021
-
[53]
Memory-efficient domain incremental learning for in- ternet of things
Yuqing Zhao, Divya Saxena, and Jiannong Cao. Memory-efficient domain incremental learning for in- ternet of things. InProceedings of the 20th ACM Conference on Embedded Networked Sensor Systems, pages 1175–1181, 2022. 22
2022
-
[54]
Online continual learning for human activity recognition.Pervasive and Mobile Computing, 93:101817, 2023
Martin Schiemer, Lei Fang, Simon Dobson, and Juan Ye. Online continual learning for human activity recognition.Pervasive and Mobile Computing, 93:101817, 2023
2023
-
[55]
Mistify: Automating{DNN}model porting for{On-Device} inference at the edge
Peizhen Guo, Bo Hu, and Wenjun Hu. Mistify: Automating{DNN}model porting for{On-Device} inference at the edge. In18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21), pages 705–719, 2021
2021
-
[56]
Gemel: Model merging for{Memory- Efficient},{Real-Time}video analytics at the edge
Arthi Padmanabhan, Neil Agarwal, Anand Iyer, Ganesh Ananthanarayanan, Yuanchao Shu, Niko- laos Karianakis, Guoqing Harry Xu, and Ravi Netravali. Gemel: Model merging for{Memory- Efficient},{Real-Time}video analytics at the edge. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 973–994, 2023
2023
-
[57]
Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once-for-all: Train one network and specialize it for efficient deployment.arXiv preprint arXiv:1908.09791, 2019
-
[58]
Continual prune- and-select: class-incremental learning with specialized subnetworks.Applied Intelligence, 53(14): 17849–17864, 2023
Aleksandr Dekhovich, David MJ Tax, Marcel HF Sluiter, and Miguel A Bessa. Continual prune- and-select: class-incremental learning with specialized subnetworks.Applied Intelligence, 53(14): 17849–17864, 2023
2023
-
[59]
Esacl: Efficient continual learning of sparse models.arXiv preprint arXiv:2401.05667, 2024
Weijieying Ren and Vasant G Honavar. Esacl: Efficient continual learning of sparse models.arXiv preprint arXiv:2401.05667, 2024
-
[60]
Impact patterns of combining model pruning and continual learning on model performance
Xueyang Zhang, Hang Li, Xi Chen, and Xue Liu. Impact patterns of combining model pruning and continual learning on model performance. In2021 IEEE Third International Conference on Cognitive Machine Intelligence (CogMI), pages 27–33. IEEE, 2021
2021
-
[61]
Binzong Geng, Fajie Yuan, Qiancheng Xu, Ying Shen, Ruifeng Xu, and Min Yang. Continual learn- ing for task-oriented dialogue system with iterative network pruning, expanding and masking.arXiv preprint arXiv:2107.08173, 2021
-
[62]
Sparcl: Sparse continual learning on the edge.Advances in Neural Information Processing Systems, 35:20366–20380, 2022
Zifeng Wang, Zheng Zhan, Yifan Gong, Geng Yuan, Wei Niu, Tong Jian, Bin Ren, Stratis Ioannidis, Yanzhi Wang, and Jennifer Dy. Sparcl: Sparse continual learning on the edge.Advances in Neural Information Processing Systems, 35:20366–20380, 2022
2022
-
[63]
Mingyang Wang, Heike Adel, Lukas Lange, Jannik Strötgen, and Hinrich Schütze. Learn it or leave it: module composition and pruning for continual learning.arXiv preprint arXiv:2406.18708, 2024
-
[64]
Positcl: Compact continual learning with posit aware quantization
Vedant Karia, Abdullah Zyarah, and Dhireesha Kudithipudi. Positcl: Compact continual learning with posit aware quantization. InProceedings of the Great Lakes Symposium on VLSI 2024, pages 645–650, 2024
2024
-
[65]
Continual learning via bit-level information preserving
Yujun Shi, Li Yuan, Yunpeng Chen, and Jiashi Feng. Continual learning via bit-level information preserving. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 16674–16683, 2021
2021
-
[66]
A tinyml platform for on-device continual learning with quantized latent replays.IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 11(4):789–802, 2021
Leonardo Ravaglia, Manuele Rusci, Davide Nadalini, Alessandro Capotondi, Francesco Conti, and Luca Benini. A tinyml platform for on-device continual learning with quantized latent replays.IEEE Journal on Emerging and Selected Topics in Circuits and Systems, 11(4):789–802, 2021
2021
-
[67]
Andreas Griewank and Andrea Walther. Algorithm 799: revolve: an implementation of checkpointing for the reverse or adjoint mode of computational differentiation.ACM Transactions on Mathematical Software (TOMS), 26(1):19–45, 2000. 23
2000
-
[68]
Cost- effective on-device continual learning over memory hierarchy with miro
Xinyue Ma, Suyeon Jeong, Minjia Zhang, Di Wang, Jonghyun Choi, and Myeongjae Jeon. Cost- effective on-device continual learning over memory hierarchy with miro. InProceedings of the 29th Annual International Conference on Mobile Computing and Networking, pages 1–15, 2023
2023
-
[69]
Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
2019
-
[70]
Melon: Breaking the memory wall for resource-efficient on-device machine learning
Qipeng Wang, Mengwei Xu, Chao Jin, Xinran Dong, Jinliang Yuan, Xin Jin, Gang Huang, Yunxin Liu, and Xuanzhe Liu. Melon: Breaking the memory wall for resource-efficient on-device machine learning. InProceedings of the 20th Annual International Conference on Mobile Systems, Applications and Services, pages 450–463, 2022
2022
-
[71]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost.arXiv preprint arXiv:1604.06174, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[72]
E2-train: Training state-of-the-art cnns with over 80% energy savings.Advances in Neural Information Processing Systems, 32, 2019
Yue Wang, Ziyu Jiang, Xiaohan Chen, Pengfei Xu, Yang Zhao, Yingyan Lin, and Zhangyang Wang. E2-train: Training state-of-the-art cnns with over 80% energy savings.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[73]
Selective freezing for efficient continual learning
Amelia Sorrenti, Giovanni Bellitto, Federica Proietto Salanitri, Matteo Pennisi, Concetto Spamp- inato, and Simone Palazzo. Selective freezing for efficient continual learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3550–3559, 2023
2023
-
[74]
Egeria: Efficient dnn training with knowledge-guided layer freezing
Yiding Wang, Decang Sun, Kai Chen, Fan Lai, and Mosharaf Chowdhury. Egeria: Efficient dnn training with knowledge-guided layer freezing. InProceedings of the Eighteenth European Conference on Computer Systems, pages 851–866, 2023
2023
-
[75]
Sequel: A continual learning library in pytorch and jax.arXiv preprint arXiv:2304.10857, 2023
Nikolaos Dimitriadis, Francois Fleuret, and Pascal Frossard. Sequel: A continual learning library in pytorch and jax.arXiv preprint arXiv:2304.10857, 2023
-
[76]
Arthur Douillard and Timothée Lesort. Continuum: Simple management of complex continual learn- ing scenarios.arXiv preprint arXiv:2102.06253, 2021
-
[77]
Fabrice Normandin, Florian Golemo, Oleksiy Ostapenko, Pau Rodriguez, Matthew D Riemer, Julio Hurtado, Khimya Khetarpal, Ryan Lindeborg, Lucas Cecchi, Timothée Lesort, et al. Sequoia: A software framework to unify continual learning research.arXiv preprint arXiv:2108.01005, 2021
-
[78]
icarl: In- cremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: In- cremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017. 24
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.