LongCat-Video-Avatar 1.5 Technical Report
Pith reviewed 2026-06-29 18:25 UTC · model grok-4.3
The pith
LongCat-Video-Avatar 1.5 reaches competitive or superior results to closed-source avatar systems by upgrading audio encoding, training scale, RLHF, and inference speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
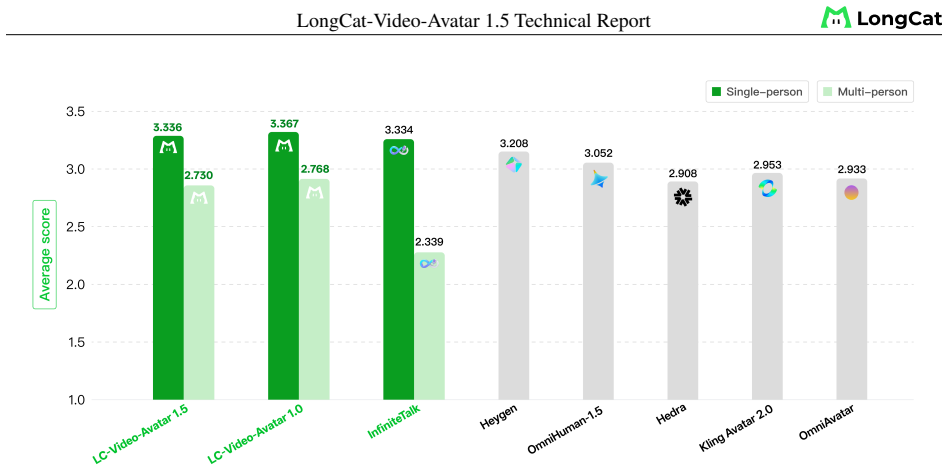
LongCat-Video-Avatar 1.5 shows that upgrading the audio encoder to Whisper Large, scaling training recipes, applying rigorous data curation and RLHF, plus step distillation to an optimal 8 NFE produces accurate lip-synchronization, full-body temporal stability, robust long-video generation with identity consistency, and native support for complex conditions including multi-person interactions and stylized domains such as anime and animals, while achieving competitive or superior human-likeness and expert quality scores against leading closed-source systems on an internal benchmark of over 500 cases.
What carries the argument
The suite of targeted upgrades—Whisper Large audio encoder, scaled training with RLHF, and 8-NFE step distillation—that together deliver stable, identity-consistent output and fast inference.
If this is right
- The model generalizes directly to stylized domains such as anime and animals without extra fine-tuning.
- Native support for multi-person interactions and object handling appears in the generated videos.
- Inference reaches an 8 NFE operating point that balances serving speed and visual fidelity.
- Open-source release enables industrial deployment without closed API dependence.
- Rigorous data curation and RLHF training support consistent identity across extended sequences.
Where Pith is reading between the lines
- Similar engineering-focused upgrades could be applied to other generative video tasks to improve stability without architectural changes.
- Widespread use of the released model would let developers test avatar pipelines locally rather than through paid services.
- Public release of the 500-case benchmark would allow direct comparison of future open models against the same reference.
Load-bearing premise
The paper's internal benchmark of over 500 test cases plus its human evaluation protocol provides an unbiased measure of real-world performance against closed-source competitors.
What would settle it
An independent evaluation on a separate public test set with new raters that shows LongCat-Video-Avatar 1.5 scoring lower than the listed closed-source systems on human-likeness or expert quality.
Figures




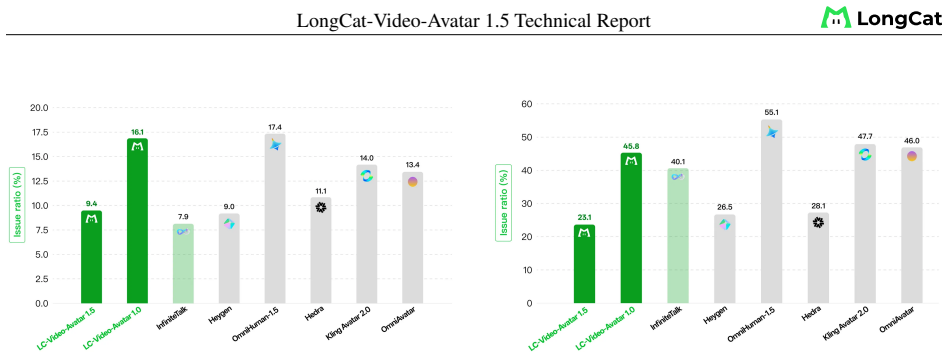
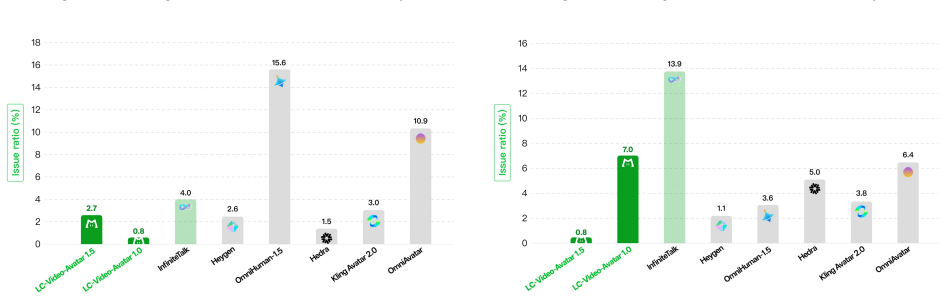
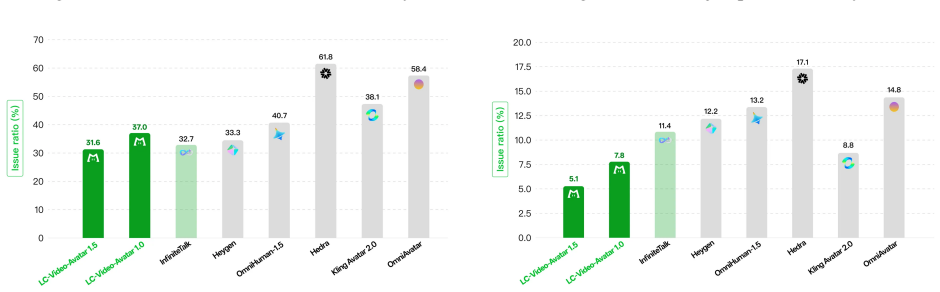
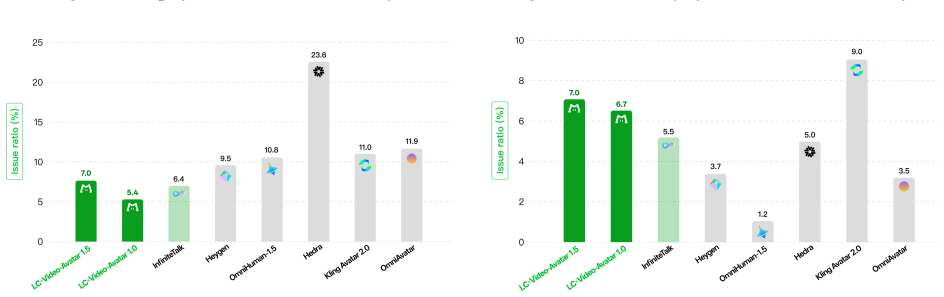







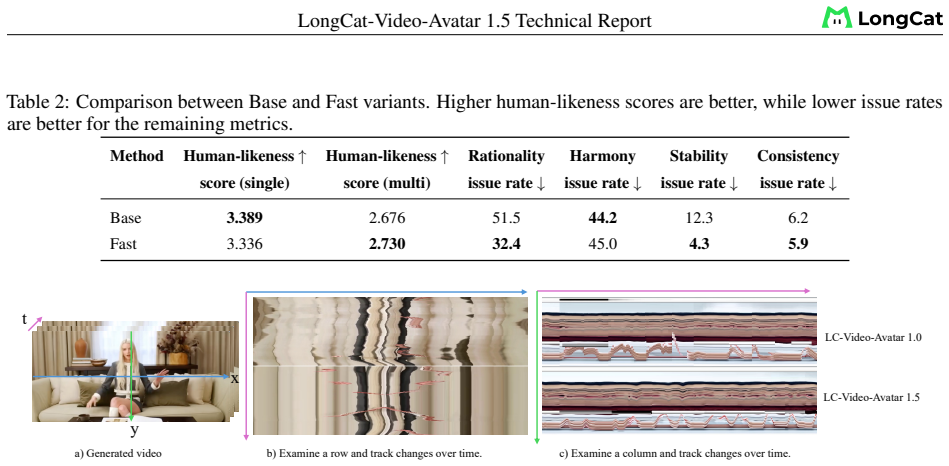

read the original abstract
Despite advances in audio-driven video generation, achieving commercial-grade stability remains challenging. We present LongCat-Video-Avatar 1.5, an upgraded open-source framework prioritizing systematic engineering and production-readiness over architectural novelty. By upgrading the audio encoder to Whisper Large and meticulously scaling our training recipes, v1.5 achieves accurate lip-synchronization, full-body temporal stability, and robust long-video generation with strict identity consistency. Through rigorous data curation and RLHF Training, the model readily generalizes to stylized domains such as anime and animals, and natively handles complex real-world conditions, such as multi-person interactions and object handling. Furthermore, addressing the practical demands of industrial deployment, we employ advanced step distillation to accelerate inference to an optimal 8 NFE, achieving a favorable trade-off between serving efficiency and visual fidelity. The superiority of our approach is validated through extensive quantitative metrics and a rigorous human evaluation conducted on a comprehensive benchmark of over 500 diverse test cases. Results show that v1.5 achieves competitive or superior performance compared to leading closed-source systems (e.g., HeyGen, OmniHuman 1.5, Kling Avatar 2.0) across human-likeness ratings and expert-level quality assessments on our benchmark. With its open-source release, LongCat-Video-Avatar 1.5 narrows the gap between academic research prototypes and commercial-grade deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LongCat-Video-Avatar 1.5, an open-source audio-driven video avatar framework that upgrades the audio encoder to Whisper Large, scales training recipes, applies RLHF for domain generalization (including anime and animals), and uses step distillation to reach 8 NFE inference. It claims accurate lip synchronization, full-body temporal stability, identity consistency, and multi-person/object handling, with the headline result that v1.5 achieves competitive or superior human-likeness and expert-level quality versus closed-source systems (HeyGen, OmniHuman 1.5, Kling Avatar 2.0) on an internal benchmark of over 500 diverse test cases.
Significance. If the evaluation protocol and results can be substantiated, the work would be significant as a production-oriented open-source release that narrows the gap to commercial closed-source avatar systems while providing measurable gains in inference efficiency and robustness to real-world conditions.
major comments (1)
- [Abstract and Evaluation] Abstract and Evaluation section: The central superiority claims rest exclusively on a human evaluation conducted on an internal benchmark of >500 cases, yet no details are supplied on benchmark construction, diversity sampling strategy, prompt distribution, human-study protocol (blinding, rating scales, number of raters, inter-rater reliability statistics), or controls for inference settings when comparing against closed-source systems. This absence is load-bearing because it prevents any assessment of selection bias or reproducibility of the reported performance advantage.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in our evaluation protocol. We agree that the current description of the human study is insufficient to allow independent assessment of selection bias or reproducibility, and we will expand the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The central superiority claims rest exclusively on a human evaluation conducted on an internal benchmark of >500 cases, yet no details are supplied on benchmark construction, diversity sampling strategy, prompt distribution, human-study protocol (blinding, rating scales, number of raters, inter-rater reliability statistics), or controls for inference settings when comparing against closed-source systems. This absence is load-bearing because it prevents any assessment of selection bias or reproducibility of the reported performance advantage.
Authors: We agree with the referee that the absence of these details is a significant limitation. In the revised manuscript we will add a new subsection under Evaluation that explicitly describes: (1) benchmark construction and diversity sampling strategy (including prompt distribution across domains, identities, and conditions); (2) the human-study protocol, including blinding procedures, rating scales, number of raters, and inter-rater reliability statistics; and (3) the controls applied to ensure fair inference settings when comparing against closed-source systems. We will also clarify any constraints on releasing the full benchmark while providing sufficient methodological detail for reproducibility assessment. revision: yes
Circularity Check
No significant circularity; empirical superiority claims rest on external closed-source comparisons and stated benchmark evaluation rather than self-referential fits or derivations.
full rationale
The paper is a technical report focused on engineering upgrades (Whisper encoder, data curation, RLHF, step distillation) and reports performance via quantitative metrics plus human evaluation on an internal >500-case benchmark against external systems (HeyGen, OmniHuman, Kling). No mathematical derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing premises appear in the provided text. The central claim is an empirical comparison to independent external models, which does not reduce to the paper's own inputs by construction. This matches the default expectation of no circularity for systems papers whose results are benchmarked externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yingjie Zhou, Xilei Zhu, Siyu Ren, Ziyi Zhao, Ziwen Wang, Farong Wen, Yu Zhou, Jiezhang Cao, Xiongkuo Min, Fengjiao Chen, et al. Evaltalker: Learning to evaluate real-portrait-driven multi-subject talking humans.arXiv preprint arXiv:2512.01340,
-
[2]
Jianwen Jiang, Weihong Zeng, Zerong Zheng, Jiaqi Yang, Chao Liang, Wang Liao, Han Liang, Yuan Zhang, and Mingyuan Gao. Omnihuman-1.5: Instilling an active mind in avatars via cognitive simulation.arXiv preprint arXiv:2508.19209,
-
[3]
Longcat-video technical report, 2025
Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, et al. Longcat-video technical report.arXiv preprint arXiv:2510.22200,
-
[4]
Wan-s2v: Audio-driven cinematic video generation.arXiv preprint arXiv:2508.18621,
Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Dechao Meng, Jinwei Qi, Penchong Qiao, Zhen Shen, Yafei Song, et al. Wan-s2v: Audio-driven cinematic video generation.arXiv preprint arXiv:2508.18621,
-
[5]
Shaoshu Yang, Zhe Kong, Feng Gao, Meng Cheng, Xiangyu Liu, Yong Zhang, Zhuoliang Kang, Wenhan Luo, Xunliang Cai, Ran He, et al. Infinitetalk: Audio-driven video generation for sparse-frame video dubbing.arXiv preprint arXiv:2508.14033,
-
[6]
Yi Chen, Sen Liang, Zixiang Zhou, Ziyao Huang, Yifeng Ma, Junshu Tang, Qin Lin, Yuan Zhou, and Qinglin Lu. Hunyuanvideo-avatar: High-fidelity audio-driven human animation for multiple characters.arXiv preprint arXiv:2505.20156, 2025a. Qijun Gan, Ruizi Yang, Jianke Zhu, Shaofei Xue, and Steven Hoi. Omniavatar: Efficient audio-driven avatar video generation...
-
[7]
Chaochao Li, Ruikui Wang, Liangbo Zhou, Jinheng Feng, Huaishao Luo, Huan Zhang, Youzheng Wu, and Xiaodong He. Joyavatar-flash: Real-time and infinite audio-driven avatar generation with autoregressive diffusion.arXiv preprint arXiv:2512.11423, 2025a. Zhiyuan Li, Chi-Man Pun, Chen Fang, Jue Wang, and Xiaodong Cun. Personalive! expressive portrait image ani...
-
[8]
URLhttps://arxiv.org/abs/2512.23379. Ailing Zeng, Casper Yang, Chauncey Ge, Eddie Zhang, Garvey Xu, Gavin Lin, Gilbert Gu, Jeremy Pi, Leo Li, Mingyi Shi, et al. Lpm 1.0: Video-based character performance model.arXiv preprint arXiv:2604.07823,
-
[9]
Robust Speech Recognition via Large-Scale Weak Supervision
URLhttps://arxiv.org/abs/2212.04356. Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Revisiting Active Speaker Detection: An In-the-Wild Benchmark for Generalization and Robustness
Le Thien Phuc Nguyen, Zhuoran Yu, Khoa Quang Nhat Cao, Yuwei Guo, Tu Ho Manh Pham, Tuan Tai Nguyen, Toan Ngo Duc V o, Lucas Poon, Soochahn Lee, and Yong Jae Lee. Unitalk: Towards universal active speaker detection in real world scenarios.arXiv preprint arXiv:2505.21954,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Chuyi Li, Lulu Li, Hongliang Geng, Hongyu Jiang, Meng Cheng, Bo Zhang, Zaidan Ke, Xiaoming Xu, and Xiangxiang Chu. Yolov6: A single-stage object detection framework for industrial applications.arXiv preprint arXiv:2209.02976,
-
[12]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Humo: Human-centric video generation via collaborative multi-modal conditioning, 2025b
Liyang Chen, Tianxiang Ma, Jiawei Liu, Bingchuan Li, Zhuowei Chen, Lijie Liu, Xu He, Gen Li, Qian He, and Zhiyong Wu. Humo: Human-centric video generation via collaborative multi-modal conditioning, 2025b. URL https://arxiv.org/abs/2509.08519. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarw...
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
23 LongCat-Video-Avatar 1.5 Technical Report Yikang Ding, Jiwen Liu, Wenyuan Zhang, Zekun Wang, Wentao Hu, Liyuan Cui, Mingming Lao, Yingchao Shao, Hui Liu, Xiaohan Li, Ming Chen, Xiaoqiang Liu, Yu-shen Liu, and Wan Pengfei. Kling-avatar: Grounding multimodal instructions for cascaded long-duration avatar animation synthesis.arXiv preprint arXiv:2509.09595,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.