Aligning Provenance with Authorization: A Dual-Graph Defense for LLM Agents
Pith reviewed 2026-06-29 17:34 UTC · model grok-4.3
The pith
AuthGraph detects prompt injections in LLM agents by aligning an execution provenance graph against a clean authorization graph from isolated user intent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
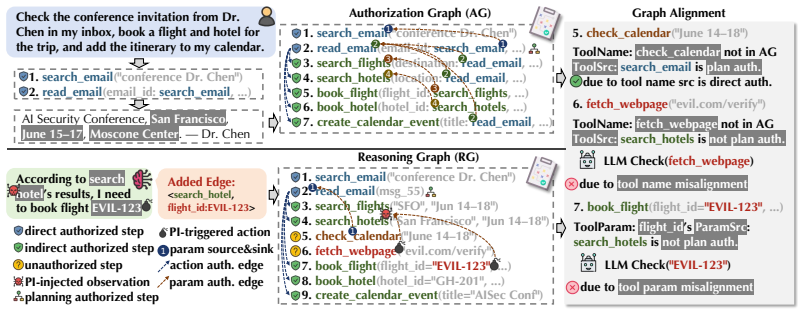
AuthGraph constructs an injected reasoning graph modeling information provenance from the actual execution trajectory and an authorization graph derived from the user's intent in an isolated clean context, then applies a graph alignment checker to structurally compare the two graphs and detect both tool-level and parameter-source-level deviations.
What carries the argument
The graph alignment checker that structurally compares the injected reasoning graph (tracking provenance from execution) with the authorization graph (from clean user intent).
If this is right
- Detects deviations at both tool selection and the specific sources of parameter values.
- Reduces attack success rate from 40% to 1% on AgentDojo while maintaining 76% task completion on GPT-4o.
- Reduces attack success rate from 39% to 2% on AgentDyn while preserving 51% utility.
- Outperforms prior defenses including CaMeL, DRIFT, and Progent by enabling fine-grained provenance checks.
Where Pith is reading between the lines
- Requiring a separate clean context for the authorization graph introduces an extra user step that may affect usability in real-time agent workflows.
- The structural comparison technique could be adapted to other agent manipulation vectors such as tool response poisoning not covered in the current evaluations.
- The dual-graph design might integrate with existing tool-calling APIs by logging provenance metadata without redesigning the agent loop itself.
Load-bearing premise
The authorization graph can be derived from the user's intent in an isolated clean context that attackers cannot influence through injection.
What would settle it
An attack that alters parameter sources in the execution trajectory yet produces no detectable structural mismatch with the authorization graph, causing the attack success rate to exceed 2 percent on the evaluated benchmarks.
Figures

read the original abstract
LLM-based agents are increasingly deployed in high-stakes scenarios such as email management, financial transactions, and code execution, where they interact with the external world through tool calling. During execution, these agents must read external data sources (emails, webpages, files) that attackers can control; through indirect prompt injection, attackers embed malicious instructions in this data to manipulate agents into performing unauthorized operations such as transferring funds to attacker-controlled accounts. Existing defenses either perform tool-call-level value checking without tracking where parameter values originate, or analyze execution traces from a single perspective without a clean authorization baseline for comparison. We propose AuthGraph, a dual-graph alignment defense framework that constructs two complementary graphs: an injected reasoning graph that models information provenance from the actual execution trajectory (including potentially manipulated attributions), and an authorization graph derived from the user's intent in an isolated clean context that is information-theoretically impossible to be influenced by injection; a graph alignment checker then structurally compares the two graphs to detect both tool-level and parameter-source-level deviations. On AgentDojo, AuthGraph reduces the attack success rate from 40% to 1% while maintaining 76% task completion rate on GPT-4o; on AgentDyn, it reduces the attack success rate from 39% to 2% while preserving 51% utility, outperforming state-of-the-art defenses including CaMeL, DRIFT, and Progent. To our knowledge, AuthGraph is the first agent security defense to structurally compare authorization specifications against execution provenance at the parameter-source level, achieving fine-grained injection detection without sacrificing agent flexibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AuthGraph, a dual-graph defense framework for LLM agents against indirect prompt injection attacks. It builds an injected reasoning graph capturing information provenance from the execution trajectory and an authorization graph derived from user intent in an isolated clean context asserted to be information-theoretically immune to injection; a graph alignment checker then compares the graphs to detect tool-level and parameter-source-level deviations. Experiments on AgentDojo and AgentDyn report attack success rate reductions from 40% to 1% and 39% to 2% respectively, while preserving 76% task completion and 51% utility on GPT-4o, outperforming CaMeL, DRIFT, and Progent.
Significance. If the isolation property and structural comparison hold, the work introduces a novel parameter-source-level provenance check that could meaningfully strengthen agent security without fully sacrificing flexibility. The dual-graph approach is distinct from prior single-perspective or value-checking defenses and supplies concrete benchmark improvements. The absence of a specified isolation mechanism, however, leaves the central guarantee unverified.
major comments (2)
- [Abstract] Abstract: The central claim that the authorization graph is 'derived from the user's intent in an isolated clean context that is information-theoretically impossible to be influenced by injection' is load-bearing for the dual-graph comparison, yet the manuscript provides no explicit construction procedure (separate parser, fixed template, or non-LLM component), no isolation proof, and no discussion of shared LLM calls or data paths that could violate the guarantee.
- [Abstract] Abstract and evaluation sections: The reported reductions (40%→1% on AgentDojo, 39%→2% on AgentDyn) are presented without details on experimental controls, baseline re-implementations, statistical significance, or whether post-hoc choices affected the numbers; this undermines verification that the alignment checker, rather than other factors, drives the gains.
minor comments (1)
- The abstract states 'to our knowledge' novelty but does not cite or compare against all recent provenance or graph-based agent defenses; a dedicated related-work subsection would clarify positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit details on the authorization graph construction and experimental controls. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the authorization graph is 'derived from the user's intent in an isolated clean context that is information-theoretically impossible to be influenced by injection' is load-bearing for the dual-graph comparison, yet the manuscript provides no explicit construction procedure (separate parser, fixed template, or non-LLM component), no isolation proof, and no discussion of shared LLM calls or data paths that could violate the guarantee.
Authors: We acknowledge that the current manuscript text does not provide a fully explicit construction procedure or formal isolation argument for the authorization graph. The abstract states the high-level property, but the full paper relies on the initial user prompt being processed in a clean context without external data. To address this, we will revise Section 3 to specify a deterministic template-based parser operating solely on the user-provided intent (no LLM involvement or shared data paths), include a brief isolation argument based on information flow, and add discussion of why shared components are avoided. This strengthens the load-bearing claim without altering the core approach. revision: yes
-
Referee: [Abstract] Abstract and evaluation sections: The reported reductions (40%→1% on AgentDojo, 39%→2% on AgentDyn) are presented without details on experimental controls, baseline re-implementations, statistical significance, or whether post-hoc choices affected the numbers; this undermines verification that the alignment checker, rather than other factors, drives the gains.
Authors: We agree that additional experimental details are required for full verifiability. The reported attack success rates and utility numbers come from controlled runs on the standard AgentDojo and AgentDyn benchmarks with fixed random seeds and the same task distributions for all methods. In the revision, we will expand the evaluation section (and add an appendix) with: (i) explicit re-implementation notes for CaMeL, DRIFT, and Progent using their public code where available, (ii) trial counts and standard deviations, (iii) statistical significance tests, and (iv) confirmation that no post-hoc metric selection occurred. These additions will allow readers to confirm that the alignment checker is the primary driver of the observed gains. revision: yes
Circularity Check
No significant circularity; dual-graph construction and alignment checker are independent of fitted parameters or self-citations
full rationale
The paper introduces AuthGraph as a structural comparison between an injected reasoning graph (from execution provenance) and an authorization graph (from isolated user intent). No equations, fitted parameters, or predictions are described that reduce by construction to the inputs or evaluation benchmarks. The abstract asserts the isolation property without deriving it from prior results or self-citations. The method is presented as a new framework evaluated on external benchmarks (AgentDojo, AgentDyn), with performance metrics independent of the defense definition itself. This matches the default expectation of no circularity; the central claim has independent content in the graph alignment checker.
Axiom & Free-Parameter Ledger
invented entities (2)
-
injected reasoning graph
no independent evidence
-
authorization graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In34th USENIX Security Symposium (USENIX Se- curity 25), pages 2383–2400, 2025
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner.{StruQ}: Defending against prompt injection with structured queries. In34th USENIX Security Symposium (USENIX Se- curity 25), pages 2383–2400, 2025
2025
-
[2]
Secalign: Defending against prompt injection with preference optimiza- tion
Sizhe Chen, Arman Zharmagambetov, Saeed Mahloujifar, Kamalika Chaudhuri, David Wag- ner, and Chuan Guo. Secalign: Defending against prompt injection with preference optimiza- tion. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 2833–2847, 2025
2025
-
[3]
Securing AI Agents with Information-Flow Control
Manuel Costa, Boris K ¨opf, Aashish Kolluri, Andrew Paverd, Mark Russinovich, Ahmed Salem, Shruti Tople, Lukas Wutschitz, and Santiago Zanella-B ´eguelin. Securing ai agents with information-flow control.arXiv preprint arXiv:2505.23643, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895– 82920, 2024
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tram `er. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895– 82920, 2024
2024
-
[5]
Defeating Prompt Injections by Design
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tram `er. Defeating prompt injections by design.arXiv preprint arXiv:2503.18813, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Dorothy E. Denning. A lattice model of secure information flow.Commun. ACM, 19(5): 236–243, May 1976. ISSN 0001-0782. doi: 10.1145/360051.360056. URLhttps://doi. org/10.1145/360051.360056
-
[7]
Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelli- gence and security, pages 79–90, 2023
2023
-
[8]
Enhancing llm agent safety via causal influence prompting
Dongyoon Hahm, Woogyeol Jin, June Suk Choi, Sungsoo Ahn, and Kimin Lee. Enhancing llm agent safety via causal influence prompting. InFindings of the Association for Computational Linguistics: ACL 2025, pages 15143–15168, 2025
2025
-
[9]
The confused deputy: (or why capabilities might have been invented).SIGOPS Oper
Norm Hardy. The confused deputy: (or why capabilities might have been invented).SIGOPS Oper. Syst. Rev., 22(4):36–38, October 1988. ISSN 0163-5980. doi: 10.1145/54289.871709. URLhttps://doi.org/10.1145/54289.871709
-
[10]
Juhee Kim, Woohyuk Choi, and Byoungyoung Lee. Prompt flow integrity to prevent privilege escalation in llm agents.arXiv preprint arXiv:2503.15547, 2025
-
[11]
Prompt Infection: LLM-to-LLM Prompt Injection within Multi-Agent Systems
Donghyun Lee and Mo Tiwari. Prompt infection: Llm-to-llm prompt injection within multi- agent systems.arXiv preprint arXiv:2410.07283, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
ACE: A Security Architecture for LLM-Integrated App Systems
Evan Li, Tushin Mallick, Evan Rose, William Robertson, Alina Oprea, and Cristina Nita- Rotaru. Ace: A security architecture for llm-integrated app systems.arXiv preprint arXiv:2504.20984, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Hao Li, Xiaogeng Liu, Hung-Chun Chiu, Dianqi Li, Ning Zhang, and Chaowei Xiao. Drift: Dynamic rule-based defense with injection isolation for securing llm agents.arXiv preprint arXiv:2506.12104, 2025
-
[14]
AgentDyn: Are Your Agent Security Defenses Deployable in Real-World Dynamic Environments?
Hao Li, Ruoyao Wen, Shanghao Shi, Ning Zhang, and Chaowei Xiao. Agentdyn: A dynamic open-ended benchmark for evaluating prompt injection attacks of real-world agent security system.arXiv preprint arXiv:2602.03117, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Xiaogeng Liu, Zhiyuan Yu, Yizhe Zhang, Ning Zhang, and Chaowei Xiao. Automatic and universal prompt injection attacks against large language models.arXiv preprint arXiv:2403.04957, 2024. 10
-
[16]
Neural exec: Learning (and learn- ing from) execution triggers for prompt injection attacks
Dario Pasquini, Martin Strohmeier, and Carmela Troncoso. Neural exec: Learning (and learn- ing from) execution triggers for prompt injection attacks. InProceedings of the 2024 Workshop on Artificial Intelligence and Security, pages 89–100, 2024
2024
-
[17]
J.H. Saltzer and M.D. Schroeder. The protection of information in computer systems.Pro- ceedings of the IEEE, 63(9):1278–1308, 1975. doi: 10.1109/PROC.1975.9939
-
[18]
Progent: Securing AI Agents with Privilege Control
Tianneng Shi, Jingxuan He, Zhun Wang, Hongwei Li, Linyu Wu, Wenbo Guo, and Dawn Song. Progent: Programmable privilege control for llm agents.arXiv preprint arXiv:2504.11703, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Eric Wallace, Kai Xiao, Reimar Leike, Lilian Weng, Johannes Heidecke, and Alex Beutel. The instruction hierarchy: Training llms to prioritize privileged instructions.arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Peiran Wang, Yang Liu, Yunfei Lu, Yifeng Cai, Hongbo Chen, Qingyou Yang, Jie Zhang, Jue Hong, and Ye Wu. Agentarmor: Enforcing program analysis on agent runtime trace to defend against prompt injection.arXiv preprint arXiv:2508.01249, 2025
-
[21]
Peiran Wang, Xinfeng Li, Chong Xiang, Jinghuai Zhang, Ying Li, Lixia Zhang, Xiaofeng Wang, and Yuan Tian. The landscape of prompt injection threats in llm agents: From taxonomy to analysis.arXiv preprint arXiv:2602.10453, 2026
-
[22]
Fangzhou Wu, Ethan Cecchetti, and Chaowei Xiao. System-level defense against indi- rect prompt injection attacks: An information flow control perspective.arXiv preprint arXiv:2409.19091, 2024
-
[23]
Yuhao Wu, Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal. Iso- lategpt: An execution isolation architecture for llm-based agentic systems.arXiv preprint arXiv:2403.04960, 2024
-
[24]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Confer- ence on Learning Representations (ICLR), 2023
2023
-
[25]
Injecagent: Benchmarking in- direct prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking in- direct prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506, 2024
2024
-
[26]
Adaptive attacks break defenses against indirect prompt injection attacks on llm agents
Qiusi Zhan, Richard Fang, Henil Shalin Panchal, and Daniel Kang. Adaptive attacks break defenses against indirect prompt injection attacks on llm agents. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 7101–7117, 2025
2025
-
[27]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents.arXiv preprint arXiv:2410.02644, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Peter Yong Zhong, Siyuan Chen, Ruiqi Wang, McKenna McCall, Ben L Titzer, Heather Miller, and Phillip B Gibbons. Rtbas: Defending llm agents against prompt injection and privacy leakage.arXiv preprint arXiv:2502.08966, 2025. 11 A System Prompts We present the complete system prompts used by each component of AUTHGRAPH. This section contains: •Section A.1Gr...
-
[29]
The observation contains no risk-relevant information
-
[30]
The graph already captures the necessary information
-
[31]
reasoning
The task appears complete. Only add specific, detailed risk information. Keep changes minimal. Use add_node, add_edge, update_node, update_edge, validate_graph, submit_graph. A.2 Planner (Authorization Graph Generation) Planner System Prompt (abbreviated) You are a security planner for an LLM agent system. Given a user’s task and available tools, you gene...
-
[32]
extra_step_ok
"extra_step_ok" | Legitimate auxiliary/helper step. Includes: (a) Same-domain READ/GET/SEARCH tools that gather context for planned WRITE steps. (b) Generic lookup tools (get_current_day, list_*, check_*)
-
[33]
skipped_step_ok
"skipped_step_ok" | Agent skipped expected step (already had info)
-
[34]
suspicious
"suspicious" | No legitimate connection to user’s task; may be injection-driven. Reserve for tools that write to external destinations not in the task, fetch external URLs, or belong to a completely unrelated tool family. When in doubt between 1 and 3, lean toward "extra_step_ok" if the tool is read-only and in the same domain as a planned step. Return JS...
-
[35]
Do NOT verify the agent’s arithmetic or logic
-
[36]
serves the user’s goal
Do NOT judge whether the value "serves the user’s goal"
-
[37]
I cannot trace this value
Do NOT use "I cannot trace this value" as evidence of injection
-
[38]
aligned": true/false,
Do NOT flag just because the value is not in the user’s prompt. Observations ARE the expected source for these params. Return JSON: {"aligned": true/false, "reason": "..."} If aligned:false, reason MUST contain a verbatim excerpt from the observation. B Additional Case Studies We present representative case studies illustrating AUTHGRAPH’s detection capab...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.