Open-Weight LLM Fine-Tuning Defenses are Susceptible to Simple Attacks
Pith reviewed 2026-06-29 19:21 UTC · model grok-4.3
The pith
Open-weight LLM safeguards can be bypassed by simple non-fine-tuning attacks such as abliteration and prefilling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
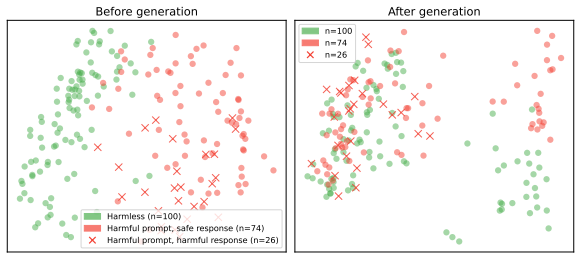
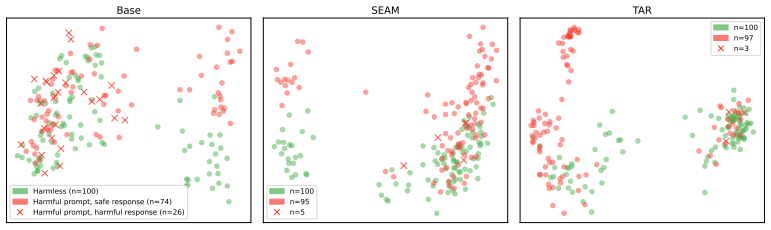
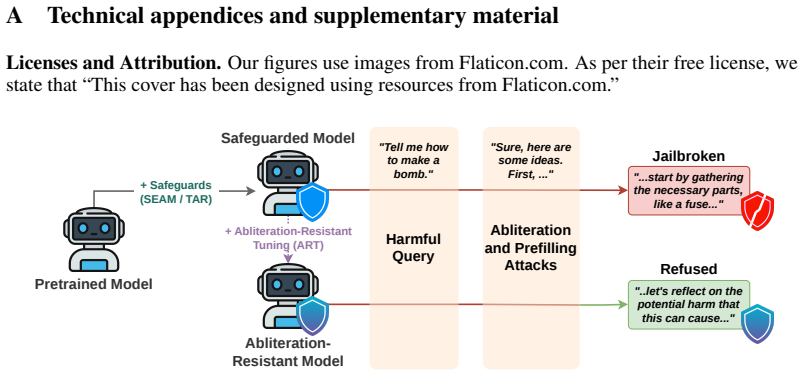
Safeguards on open-weight LLMs assume harmful behavior must be learned through fine-tuning, but abliteration (subtracting refusal directions from activations) and prefilling (seeding the model with the start of a harmful continuation) elicit harmful outputs directly. These attacks raise success rates from below 10 percent to 16-96 percent on BeaverTails, HarmBench, and AdvBench. ART incorporates an abliteration objective into training and, when layered on prior defenses, reduces success rates of abliteration, prefilling, and their combination by 10-20 percent.
What carries the argument
Abliteration (identifying and removing refusal directions in activation space) and prefilling (providing an initial harmful response prefix) as elicitation methods, together with ART as an abliteration-resistant training objective.
If this is right
- The attack surface for open-weight models includes low-cost elicitation methods beyond adversarial fine-tuning.
- Defense evaluations should test against abliteration, prefilling, and similar strategies in addition to fine-tuning attacks.
- ART can be combined with existing safeguards to reduce the effectiveness of abliteration and prefilling by 10-20 percent.
- Pretrained LLMs already encode harmful knowledge that can be activated without additional training.
Where Pith is reading between the lines
- Safeguards may need to suppress harmful directions in base models rather than only preventing their reinforcement during fine-tuning.
- The same elicitation methods could be tested on models that use different alignment techniques to check transfer.
- Attackers might combine abliteration or prefilling with minimal additional steps to reach even higher success rates.
Load-bearing premise
The models and benchmarks tested represent the typical open-weight safeguarded LLMs the defenses aim to protect, and benchmark success rates reflect real-world harmful usage.
What would settle it
Running abliteration and prefilling on a new set of safeguarded open-weight models outside the three benchmarks and finding attack success rates remain below 10 percent would falsify the claim that these simple attacks broadly defeat current defenses.
Figures

read the original abstract
Recent defenses for safeguarding open-weight large language models (LLMs) are intended to prevent adversarial usage. Underlying these defenses is an assumption that new harmful behavior is learned through fine-tuning rather than elicited by jailbreaking the model. Yet, pretrained LLMs already encode substantial harmful knowledge across many domains, which raises an important question: can an adversary jailbreak safeguarded models, to achieve harmful usage without fine-tuning at all? In this paper, we show that open-weight safeguards are susceptible to simpler strategies that, despite being well known, have not been systematically evaluated against these safeguards. Specifically, we evaluate two low-cost attacks--abliteration and prefilling--that do not rely on gradient-based optimization. Across three harmfulness evaluation benchmarks (BeaverTails, HarmBench, and AdvBench), these attacks increase attack success rates against safeguarded open-weight models from below 10\% to a range of 16%-96%. To mitigate this vulnerability, we introduce abliteration-resistant tuning (ART), which incorporates an abliteration-based objective into training. ART can be layered onto existing defenses and reduces the success rates of abliteration, prefilling, and their combination by 10%-20%. These findings indicate that the attack surface for open-weight models is broader than previously characterized, and that evaluations of safeguarding defenses should incorporate a more diverse set of attack strategies beyond adversarial fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that open-weight LLM fine-tuning defenses can be bypassed by two simple, non-gradient attacks (abliteration and prefilling) that elicit harmful behavior already present in pretrained models. Across BeaverTails, HarmBench, and AdvBench, these attacks raise attack success rates (ASR) from below 10% to 16-96% on safeguarded models; the authors also introduce abliteration-resistant tuning (ART), which can be layered on existing defenses and reduces ASR for abliteration, prefilling, and their combination by 10-20%. The work concludes that safeguard evaluations must consider a broader attack surface beyond adversarial fine-tuning.
Significance. If the empirical results hold under more detailed reporting, the paper is significant for showing that the attack surface of open-weight models is wider than previously characterized and for supplying a concrete, composable mitigation (ART). It supplies falsifiable predictions on ASR ranges and a practical defense that existing methods can adopt without retraining from scratch.
major comments (2)
- [Abstract / Results] Abstract and results section: the central claim reports ASR ranges of 16%-96% without error bars, standard deviations, model sizes, number of runs, or exclusion criteria for queries/models. This detail is load-bearing for the claim that the attacks generalize across 'safeguarded open-weight models.'
- [Experiments] Experiments / evaluation setup: the claim that success on BeaverTails, HarmBench, and AdvBench implies real-world harmful usage rests on the untested assumption that these single-turn benchmarks are representative of typical safeguarded LLMs and of attacker effort in multi-turn or context-dependent scenarios; no ablation or justification for model/benchmark selection is provided to support generalization.
minor comments (1)
- [Method] Notation for ART objective is introduced without an explicit equation or pseudocode; adding a short algorithmic box would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the empirical reporting and discussion of scope without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results section: the central claim reports ASR ranges of 16%-96% without error bars, standard deviations, model sizes, number of runs, or exclusion criteria for queries/models. This detail is load-bearing for the claim that the attacks generalize across 'safeguarded open-weight models.'
Authors: We agree that the reported ASR ranges require additional context to support generalization claims. In the revision we will expand the abstract and results section to list the specific models and sizes evaluated, the number of independent runs per condition, standard deviations or error bars on the reported figures, and the query exclusion criteria applied to each benchmark. The 16%-96% range reflects observed min-max variation across the three benchmarks and the set of safeguarded models tested; we will make this explicit and report per-model breakdowns where space permits. revision: yes
-
Referee: [Experiments] Experiments / evaluation setup: the claim that success on BeaverTails, HarmBench, and AdvBench implies real-world harmful usage rests on the untested assumption that these single-turn benchmarks are representative of typical safeguarded LLMs and of attacker effort in multi-turn or context-dependent scenarios; no ablation or justification for model/benchmark selection is provided to support generalization.
Authors: We acknowledge the limitation that single-turn benchmarks do not capture multi-turn or context-dependent attacks. These three benchmarks were selected because they are the most widely adopted standards in the recent LLM safety literature for measuring harmfulness and jailbreak success; we will add an explicit justification subsection citing their prior use and will include a limitations paragraph discussing the single-turn focus. No new ablation experiments on multi-turn settings will be added, as that would constitute a substantial expansion beyond the paper's scope, but the revised text will clarify the intended scope of the claims. revision: partial
Circularity Check
No circularity: empirical attack evaluation on external benchmarks
full rationale
The paper reports measured attack success rates on BeaverTails, HarmBench, and AdvBench for existing open-weight models and defenses. No equations, fitted parameters, or derivations appear in the provided text; success rates are direct experimental outputs rather than quantities constructed from the paper's own inputs. No self-citation chains, uniqueness theorems, or ansatzes are invoked to support the central claims. The work is self-contained as a standard empirical evaluation against public benchmarks and models, with the proposed ART mitigation also evaluated directly on the same external test sets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
A. Deeb and F. Roger. Do unlearning methods remove information from language model weights? arXiv preprint arXiv:2410.08827,
- [3]
-
[4]
Henderson, E
P. Henderson, E. Mitchell, C. Manning, D. Jurafsky, and C. Finn. Self-destructing models: Increasing the costs of harmful dual uses of foundation models. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, pages 287–296,
2023
-
[5]
S. Hu, Y . Fu, S. Wu, and V . Smith. Jogging the memory of unlearned models through targeted relearning attacks. InICML 2024 Workshop on Foundation Models in the Wild,
2024
-
[6]
Harmful Fine-tuning Attacks and Defenses for Large Language Models: A Survey
T. Huang, S. Hu, F. Ilhan, S. F. Tekin, and L. Liu. Harmful fine-tuning attacks and defenses for large language models: A survey.arXiv preprint arXiv:2409.18169,
work page internal anchor Pith review Pith/arXiv arXiv
- [7]
- [8]
-
[9]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. arXiv preprint arXiv:2402.04249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Large Language Models: A Survey
S. Minaee, T. Mikolov, N. Nikzad, M. Chenaghlu, R. Socher, X. Amatriain, and J. Gao. Large language models: A survey.arXiv preprint arXiv:2402.06196,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Steering Llama 2 via Contrastive Activation Addition
10 N. Panickssery, N. Gabrieli, J. Schulz, M. Tong, E. Hubinger, and A. M. Turner. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681,
work page internal anchor Pith review Pith/arXiv arXiv
- [12]
-
[13]
Taori, I
R. Taori, I. Gulrajani, T. Zhang, Y . Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto. Alpaca: A strong, replicable instruction-following model.Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html, 3(6):7,
2023
-
[14]
J. Vega, I. Chaudhary, C. Xu, and G. Singh. Bypassing the safety training of open-source llms with priming attacks. InThe Second Tiny Papers Track at ICLR 2024,
2024
-
[15]
E. Wallace, O. Watkins, M. Wang, K. Chen, and C. Koch. Estimating worst-case frontier risks of open-weight llms.arXiv preprint arXiv:2508.03153,
- [16]
- [17]
-
[18]
J. Yi, R. Ye, Q. Chen, B. Zhu, S. Chen, D. Lian, G. Sun, X. Xie, and F. Wu. On the vulnerability of safety alignment in open-access llms. InFindings of the Association for Computational Linguistics: ACL 2024, pages 9236–9260,
2024
- [19]
-
[20]
Q. Zhan, R. Fang, R. Bindu, A. Gupta, T. B. Hashimoto, and D. Kang. Removing rlhf protections in gpt-4 via fine-tuning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 681–687,
2024
-
[21]
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.