Is Position Bias in Dense Retrievers Built In-or Learned from Data?
Pith reviewed 2026-06-29 16:18 UTC · model grok-4.3
The pith
Dense retrievers learn positional bias mainly from where relevant evidence sits in their training documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
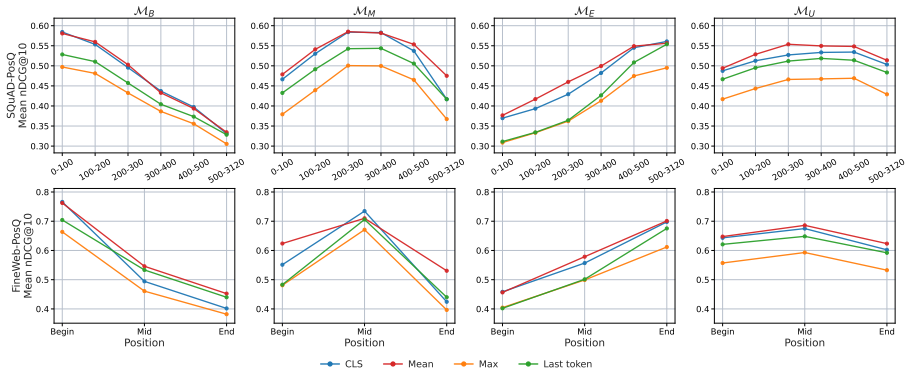
Skewed training distributions cause dense retrievers to favor evidence at the positions where relevant content appeared during training; position-balanced training reduces positional sensitivity by 57--87% on position-aware benchmarks with competitive mean retrieval performance.
What carries the argument
Synthetic position-targeted training sets that fix query-relevant evidence at one chosen document position (beginning, middle, or end) while holding other factors constant.
If this is right
- Skewed training sets produce ranking-level bias that matches the direction of the skew.
- Balanced training reduces positional sensitivity while preserving mean retrieval scores.
- Fine-tuning can reshape some learned positional preferences even when pretraining tendencies remain.
- Position distribution in training data functions as a major, adjustable source of retrieval bias.
Where Pith is reading between the lines
- Real training corpora could be re-balanced by position before fine-tuning to reduce bias in deployed retrievers.
- Models that retain strong architectural preferences after balanced training may need additional mitigation steps.
- Position effects observed here may generalize to other ranking or generation tasks that rely on similar fine-tuning.
Load-bearing premise
The synthetic position-targeted training sets isolate the effect of evidence position without introducing confounding factors from real-world data distributions or model pretraining.
What would settle it
A controlled experiment in which the same models are fine-tuned on balanced real retrieval corpora and then re-tested on the position-aware benchmarks; if sensitivity does not drop by a comparable amount, the training-distribution account would be weakened.
Figures







read the original abstract
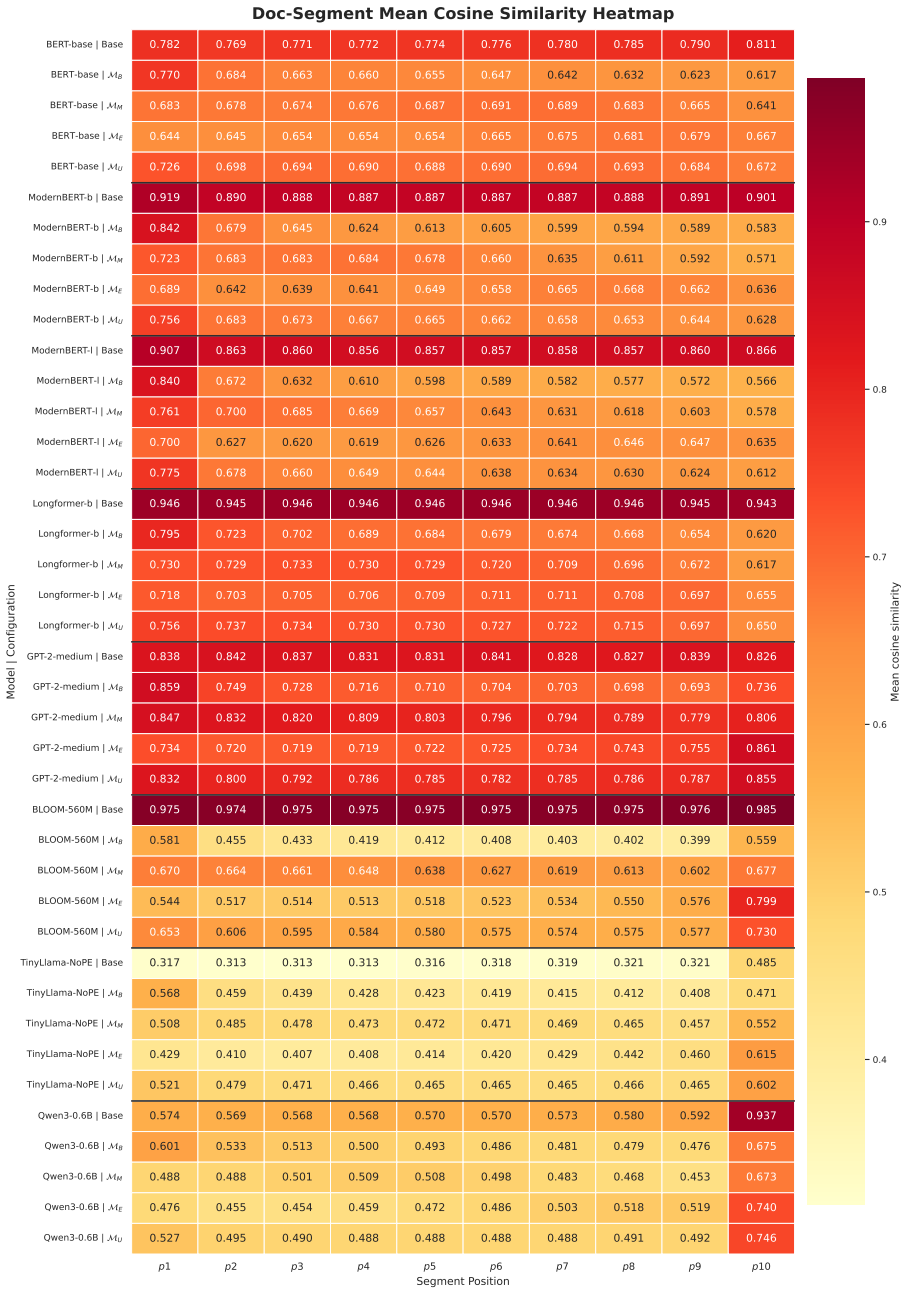
Dense retrievers exhibit positional bias, favoring documents whose query-relevant information appears near the beginning and degrading retrieval performance when the information appears later. While prior work on positional bias in dense retrievers has largely focused on architectural explanations, we study how the positional distribution of evidence in training data affects retrieval-level bias direction. To test this, we construct synthetic position-targeted training sets in which query-relevant evidence appears at the beginning, middle, or end of documents, and fine-tune eight architecturally diverse pretrained models under position-skewed and balanced training distributions. At the ranking level, we observe a strong directional pattern across the examined models: skewed training distributions favor evidence at the corresponding positions. Position-balanced training reduces positional sensitivity by 57--87\% on position-aware benchmarks, with competitive mean retrieval performance in our controlled setting. Representation-level analyses further suggest that fine-tuning often reshapes learned positional preferences, although pre-existing architectural or pretraining-specific tendencies persist in some models. These results identify training-position distribution as a major controllable factor in retrieval-level position bias and suggest balanced data curation as a practical mitigation strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that positional bias in dense retrievers is learned from the positional distribution of query-relevant evidence in training data rather than being inherent to model architectures or pretraining. It constructs synthetic position-targeted training sets (evidence at begin/mid/end), fine-tunes eight architecturally diverse models under skewed and balanced distributions, and reports that skewed training produces corresponding directional bias at ranking level while position-balanced training reduces positional sensitivity by 57-87% on position-aware benchmarks with competitive mean retrieval performance. Representation-level analyses are used to examine whether fine-tuning reshapes preferences.
Significance. If the central empirical result holds after verification of the synthetic construction, the work identifies training-data position distribution as a major controllable factor in retrieval-level position bias and positions balanced data curation as a practical mitigation. The multi-model scope (eight models) and the combination of ranking-level plus representation-level measurements strengthen the contribution; the absence of free parameters in the core claim and the falsifiable directional predictions are positive features.
major comments (1)
- [Data construction / Methods] Data construction section (likely §3 or §4): the abstract and provided description give no implementation details on how the three synthetic position-targeted training sets are generated (sentence reordering, segment extraction/insertion, or padding). Without explicit controls or ablations showing that term adjacency, document coherence, and non-evidence token distributions remain matched across variants, the observed directional bias and the 57-87% sensitivity reduction cannot be attributed solely to positional skew. This isolation is load-bearing for the central claim.
minor comments (2)
- [Abstract / Results] Abstract and results: the 57-87% reduction figures are reported without error bars, confidence intervals, or statistical tests across the eight models; adding these would strengthen the quantitative claim.
- [Abstract] The position-aware benchmarks used for the sensitivity metric are referenced but not named or described in the abstract; a brief definition or citation in the summary would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback identifying the need for greater transparency in our data construction procedure. We address the single major comment below and will incorporate the requested details and controls into the revised manuscript.
read point-by-point responses
-
Referee: [Data construction / Methods] Data construction section (likely §3 or §4): the abstract and provided description give no implementation details on how the three synthetic position-targeted training sets are generated (sentence reordering, segment extraction/insertion, or padding). Without explicit controls or ablations showing that term adjacency, document coherence, and non-evidence token distributions remain matched across variants, the observed directional bias and the 57-87% sensitivity reduction cannot be attributed solely to positional skew. This isolation is load-bearing for the central claim.
Authors: We agree that the current manuscript lacks sufficient implementation details on the synthetic data generation process and does not report explicit controls for term adjacency, document coherence, and non-evidence token distributions. In the revision we will expand the data construction section to specify the exact generation method (including any use of sentence reordering, segment extraction/insertion, or padding) and will add ablations or matching statistics confirming that these non-positional factors remain comparable across the begin/mid/end variants. These additions will allow readers to verify that the directional bias and sensitivity reductions can be attributed to positional skew. revision: yes
Circularity Check
No circularity; empirical claims rest on controlled experiments
full rationale
The paper presents no derivation chain, equations, or first-principles predictions. All central claims (directional bias from skewed training distributions, 57-87% sensitivity reduction under balanced training) are framed as direct empirical observations from fine-tuning eight models on synthetically constructed position-targeted datasets. No fitted parameters are renamed as predictions, no self-citations supply load-bearing uniqueness theorems, and no ansatz or renaming of known results occurs. The work is therefore self-contained against external benchmarks and receives a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic position-targeted training sets isolate the effect of evidence position on model behavior without confounding factors
Reference graph
Works this paper leans on
-
[1]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer. Preprint, arXiv:2004.05150. Matteo Catena, Ophir Frieder, Cristina Ioana Muntean, Franco Maria Nardini, Raffaele Perego, and Nicola Tonellotto. 2019. Enhanced news retrieval: Passages lead the way! InProceedings of the 42nd Interna- tional ACM SIGIR Conference on Research and De- velopment in Information Retrieva...
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[2]
Length generalization of causal transformers without position encoding. InFindings of the As- sociation for Computational Linguistics: ACL 2024, pages 14024–14040, Bangkok, Thailand. Association for Computational Linguistics. Ziqi Wang, Hanlin Zhang, Xiner Li, Kuan-Hao Huang, Chi Han, Shuiwang Ji, Sham M. Kakade, Hao Peng, and Heng Ji. 2025. Eliminating p...
-
[3]
Both stages use GPT-4o-mini with temperatureT=1.0and top-p=1.0
by embedding similarity using BGE-M3 (top-k=20). Both stages use GPT-4o-mini with temperatureT=1.0and top-p=1.0. A.1 Prompt for Configuration Selection (Stage 1) Given a document and a set of candidate personas, the model selects the most appropriate generation configuration. This configuration is shared across all three positional queries for the same do...
-
[4]
Character: A persona who would naturally search for this information
-
[5]
Difficulty: The education level appropriate for understanding this content
-
[6]
Query_Length: The appropriate length for the query </instructions> <options> Character Candidates: {CHARACTERS} Difficulties: high_school, university, phd Query_Lengths: short (under 10 words), medium (10--20 words), long (over 20 words) </options> Output as JSON: {"Character": " selected character description", " Difficulty": "selected difficulty", "Quer...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.