Geometry-Aware Contrastive Learning for Few-Shot Automatic Modulation Recognition
Pith reviewed 2026-06-29 19:47 UTC · model grok-4.3
The pith
DyCo-CL couples virtual adversarial augmentation with semantic consistency loss to improve 1-shot automatic modulation recognition by 6.27%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
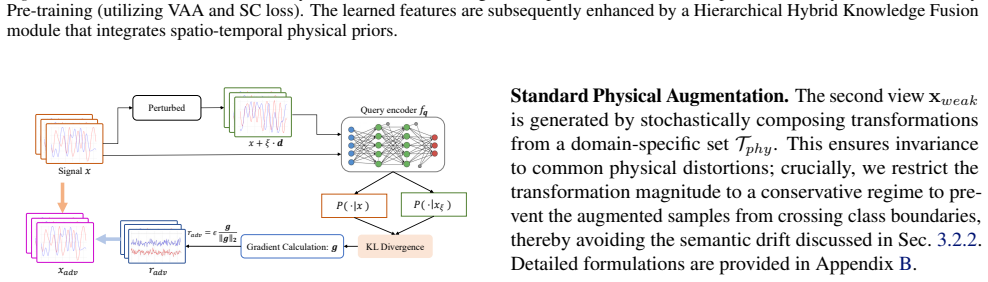
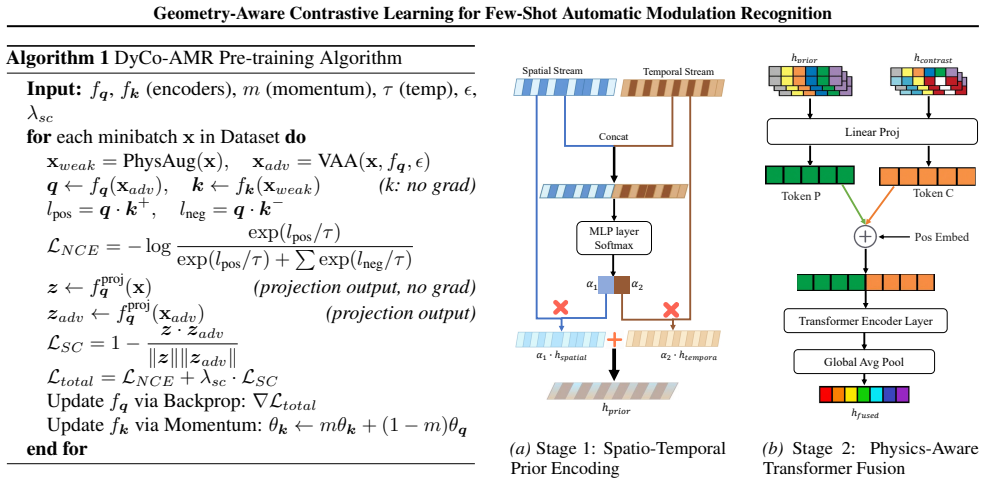
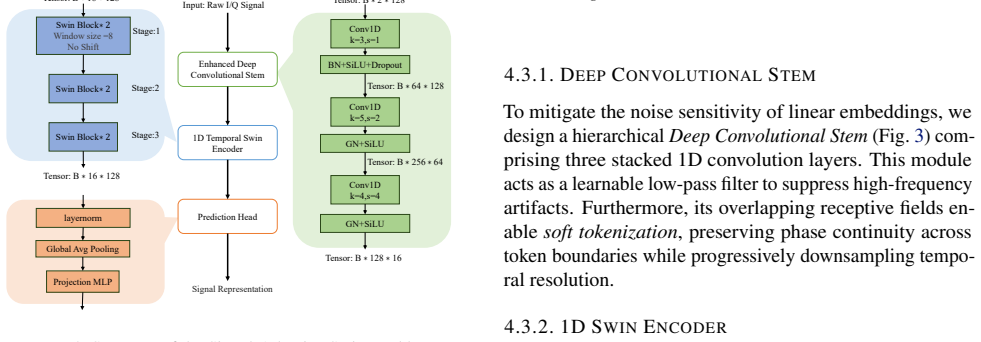
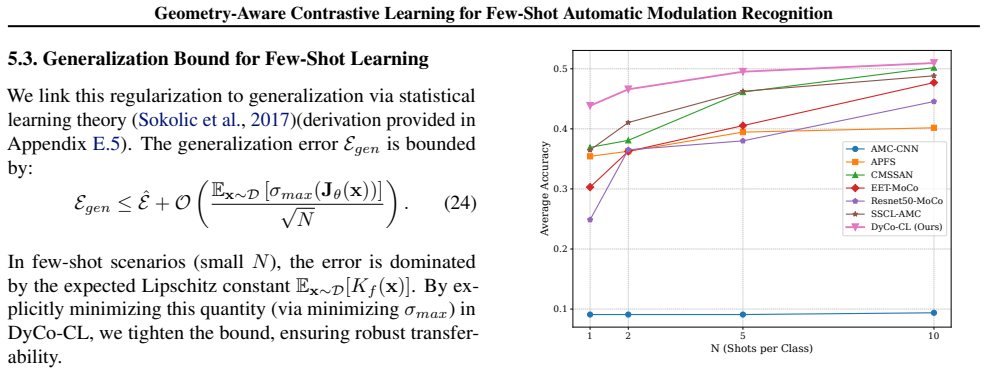
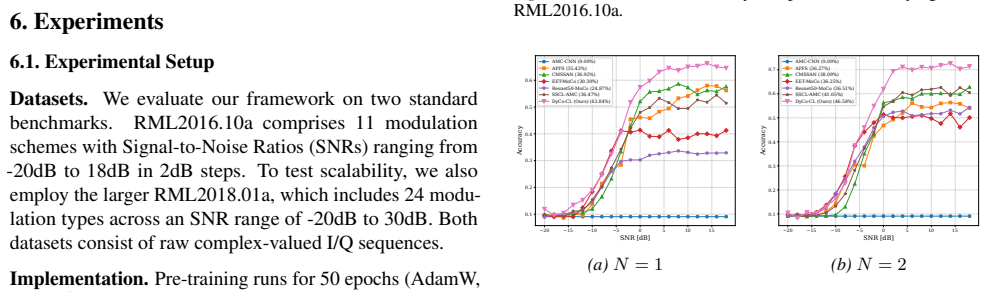
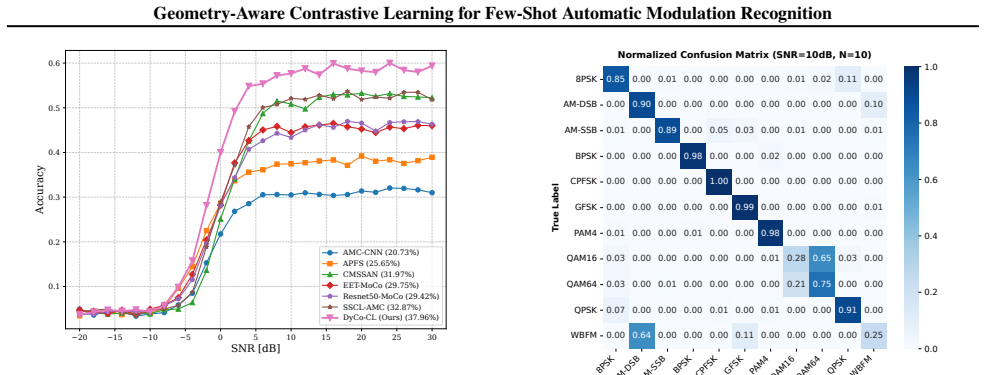
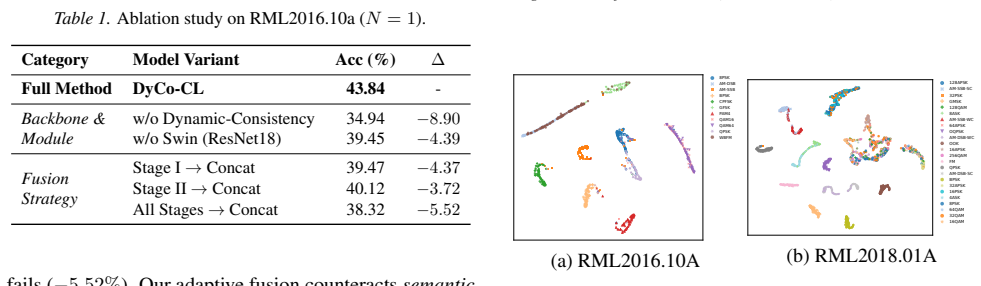
DyCo-CL is a geometry-aware contrastive learning framework that couples Virtual Adversarial Augmentation with a semantic consistency loss; the authors' theoretical analysis states that this coupling acts as an implicit spectral regularizer for the encoder and thereby enables stable manifold exploration. The framework adds a Signal-Adaptive Swin Backbone to improve structural stability through constrained attention locality and a Hybrid Knowledge Fusion module to anchor representations with physical priors, resulting in a measured 6.27% accuracy gain over prior methods in 1-shot AMR on RML benchmarks.
What carries the argument
The coupling of Virtual Adversarial Augmentation with semantic consistency loss, which the paper states functions as an implicit spectral regularizer enabling stable manifold exploration in the encoder.
If this is right
- The method produces a 6.27% accuracy improvement in 1-shot settings on RML benchmarks compared with prior approaches.
- Constraining attention locality in the signal-adaptive Swin backbone increases structural stability of the learned representations.
- Incorporating physical priors through the hybrid knowledge fusion module anchors the representations to domain knowledge.
- The implicit spectral regularization supports more stable exploration of the data manifold during contrastive training.
Where Pith is reading between the lines
- Similar regularization pairings could be tested on other few-shot time-series classification tasks where spectral stability matters.
- If the physical priors in the fusion module are domain-specific, the gains may vary when the modulation schemes or channel conditions change.
- The approach might lower the volume of labeled data required for practical deployment of modulation classifiers in wireless systems.
Load-bearing premise
The coupling of virtual adversarial augmentation with semantic consistency loss correctly acts as an implicit spectral regularizer that enables stable manifold exploration and directly produces the observed accuracy gains.
What would settle it
An ablation experiment in which removing the semantic consistency loss eliminates the 6.27% gain, or direct measurement showing that the encoder spectra do not stabilize as predicted by the regularizer, would falsify the central mechanism.
Figures


read the original abstract
Standard Self-Supervised Learning (SSL) for Automatic Modulation Recognition (AMR) struggles with ineffective isotropic augmentations, spectral instability, and semantic drift. To address these challenges, we propose Dynamic-Consistency Contrastive Learning (DyCo-CL), a geometry-aware framework that couples Virtual Adversarial Augmentation (VAA) with a semantic consistency loss. We provide a theoretical analysis indicating that this strategy acts as an implicit spectral regularizer for the encoder, enabling stable manifold exploration. Complementing this, our Signal-Adaptive Swin Backbone with fixed-window attention improves structural stability by constraining attention locality, while a Hybrid Knowledge Fusion module anchors representations with physical priors. Experiments on RML benchmarks show that DyCo-CL achieves a 6.27% accuracy gain in 1-shot settings over prior methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dynamic-Consistency Contrastive Learning (DyCo-CL), a geometry-aware SSL framework for few-shot Automatic Modulation Recognition. It couples Virtual Adversarial Augmentation (VAA) with a semantic consistency loss (claimed to act as an implicit spectral regularizer), introduces a Signal-Adaptive Swin Backbone with fixed-window attention, and a Hybrid Knowledge Fusion module that incorporates physical priors. The central claim is a 6.27% accuracy improvement in 1-shot settings on RML benchmarks relative to prior methods.
Significance. If the empirical gains prove robust under repeated sampling and the theoretical regularization claim is independently verifiable, the approach could meaningfully advance few-shot AMR by mitigating augmentation ineffectiveness and spectral instability. No machine-checked proofs, reproducible code artifacts, or parameter-free derivations are mentioned.
major comments (2)
- [Abstract / Experiments] Abstract / Experiments: The headline result of a 6.27% accuracy gain in 1-shot settings is stated without any mention of the number of independent trials, standard deviation across episodes, support-set sampling procedure, dataset splits, baseline implementations, or statistical significance testing. In 1-shot AMR, accuracy is known to be highly sensitive to the particular support set; a single delta without these controls cannot be treated as evidence that the gain is reliable.
- [Theoretical Analysis] Theoretical Analysis section: The claim that coupling VAA with the semantic consistency loss 'acts as an implicit spectral regularizer enabling stable manifold exploration' is asserted without any visible derivation, eigenvalue bounds, or explicit connection to the encoder's spectrum. No equations are supplied that would allow verification that the combined objective produces the stated regularization effect rather than an ad-hoc combination.
minor comments (2)
- Define all acronyms (VAA, DyCo-CL, RML) at first use and ensure consistent notation for loss terms across text and equations.
- Figure captions and tables should explicitly state the number of runs and error bars if they are present in the full manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of experimental rigor and theoretical clarity. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract / Experiments: The headline result of a 6.27% accuracy gain in 1-shot settings is stated without any mention of the number of independent trials, standard deviation across episodes, support-set sampling procedure, dataset splits, baseline implementations, or statistical significance testing. In 1-shot AMR, accuracy is known to be highly sensitive to the particular support set; a single delta without these controls cannot be treated as evidence that the gain is reliable.
Authors: We agree that these details are essential for establishing reliability, particularly given the sensitivity of 1-shot AMR to support-set choice. The revised manuscript will report results averaged over 100 independent episodes with standard deviations, specify the random support-set sampling procedure (with fixed seeds for reproducibility), confirm the RML dataset splits, describe baseline re-implementations, and include statistical significance tests such as paired t-tests against the strongest baselines. revision: yes
-
Referee: [Theoretical Analysis] Theoretical Analysis section: The claim that coupling VAA with the semantic consistency loss 'acts as an implicit spectral regularizer enabling stable manifold exploration' is asserted without any visible derivation, eigenvalue bounds, or explicit connection to the encoder's spectrum. No equations are supplied that would allow verification that the combined objective produces the stated regularization effect rather than an ad-hoc combination.
Authors: The current Theoretical Analysis section offers a high-level indication based on the geometry-aware coupling of the losses. We acknowledge that it lacks explicit derivations and equations for independent verification. The revision will expand this section to include the combined objective function, a step-by-step derivation of the implicit spectral regularization effect, and connections to the encoder spectrum where analytically tractable. revision: yes
Circularity Check
No circularity; empirical result with no visible derivations or self-referential reductions
full rationale
The paper reports an empirical 6.27% accuracy gain on RML benchmarks in 1-shot AMR and mentions a theoretical analysis of VAA plus semantic consistency loss as an implicit spectral regularizer, but supplies no equations, derivations, or load-bearing steps. No self-definitional claims, fitted inputs renamed as predictions, or self-citation chains appear in the provided text. The central claim is therefore an experimental outcome rather than a derivation that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Feng, Y ., Duan, R., Li, S., Cheng, P., and Liu, W
doi: 10.1109/LCOMM.2022.3225566. Feng, Y ., Duan, R., Li, S., Cheng, P., and Liu, W. A dual- branch network with feature assistance for automatic modulation recognition.IEEE Signal Processing Letters, 32:701–705, 2025. doi: 10.1109/LSP.2025.3527901. Hazza, A., Shoaib, M., Alshebeili, S. A., and Fahad, A. An overview of feature-based methods for digital mo...
-
[2]
Liang, X., Sang, R., Qian, Y ., Guo, Q., Li, F., and Du, L
doi: 10.1109/TVT.2024.3483204. Liang, X., Sang, R., Qian, Y ., Guo, Q., Li, F., and Du, L. Robust automatic modulation classification with fuzzy regularization. InForty-second International Con- ference on Machine Learning, 2025. URL https: //openreview.net/forum?id=DDIGCk25BO. Liu, F., Pan, J., and Zhou, R. Contrastive learning-based multimodal fusion mo...
-
[3]
Instability of Global Attention.For standard dot-product attention, Kim et al. (Kim et al., 2021) proved that the Jacobian Jglobal is a dense matrix, and its spectral norm scales with the sequence length: sup X σmax(Jglobal(X)) =O( √ L).(49) AsL→ ∞, the Lipschitz constant diverges, causing spectral instability
2021
-
[4]
The function ff ixed operates independently on each window
Stability of Fixed-Window Attention.In our backbone, X is partitioned into Nw =L/M non-overlapping windows {Wk}. The function ff ixed operates independently on each window. Consequently, the Jacobian Jf ixed is strictly block-diagonal: Jf ixed =diag(J 1, . . . ,JNw),(50) whereJ k is the local Jacobian for thek-th window
-
[5]
Since M is a fixed constant (e.g., M= 16) andM≪L,C M is independent ofL
Derivation of the Bound.The largest singular value of a block-diagonal matrix is the maximum of the singular values of its blocks: σmax(Jf ixed) = max k σmax(Jk).(51) Let CM = supW σmax(Jϕ(W)) be the Lipschitz constant of the local window attention. Since M is a fixed constant (e.g., M= 16) andM≪L,C M is independent ofL. Thus: Kff ixed(X) =σ max(Jf ixed)≤...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.