DelowlightSplat: Feed-Forward Gaussian Splatting for Lowlight 3D Scene Reconstruction
Pith reviewed 2026-06-29 18:16 UTC · model grok-4.3
The pith
DelowlightSplat uses a lightweight adapter and cost-volume inference to predict clean 3D Gaussians directly from lowlight inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DelowlightSplat is a lowlight-aware feed-forward Gaussian splatting framework that introduces a lightweight Lowlight Adapter for residual enhancement to improve matchability and couples it with cost-volume-based multi-view inference to directly predict clean 3D Gaussians from lowlight-degraded context views.
What carries the argument
The Lowlight Adapter for residual enhancement, paired with cost-volume-based multi-view inference, which together enable direct prediction of clean 3D Gaussians.
If this is right
- DelowlightSplat produces higher-quality novel-view renderings than prior feed-forward methods and two-stage pipelines when inputs are lowlight.
- The single-pass design removes the need for a separate lowlight enhancement network before 3D reconstruction.
- The benchmark construction method allows controlled testing of lowlight robustness without requiring paired real lowlight data.
- Direct Gaussian prediction from enhanced features supports faster inference for robotics and AR/VR use cases.
Where Pith is reading between the lines
- The residual-enhancement idea could be tested on other input degradations such as motion blur or fog by retraining only the adapter module.
- Replacing the cost-volume step with learned alternatives might further reduce memory use while preserving the clean-output property.
- The benchmark design suggests a general template for evaluating other reconstruction methods under asymmetric view quality.
Load-bearing premise
The controllable benchmark that degrades only context views while keeping target views clean accurately represents real lowlight imaging conditions without introducing artifacts that favor the adapter and inference pipeline.
What would settle it
Running the trained model on real captured lowlight multi-view datasets where all views including targets are noisy, then measuring whether novel-view PSNR and visual quality remain higher than two-stage baselines.
Figures


read the original abstract
Novel-view synthesis and 3D reconstruction from sparse posed images are central to robotics and AR/VR. Yet, feed-forward 3D Gaussian reconstruction fails under lowlight due to noise, color shifts, and unreliable correspondence. We propose DelowlightSplat, a lowlight-aware feed-forward Gaussian splatting framework for clean novel-view rendering. We build a controllable multi-view lowlight benchmark by degrading only context views while keeping target views clean. We introduce a lightweight Lowlight Adapter for residual enhancement to improve matchability, and couple it with cost-volume-based multi-view inference to directly predict clean 3D Gaussians. Experiments show that DelowlightSplat significantly outperforms previous feed-forward method and two-stage pipeline under lowlight conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DelowlightSplat, a lowlight-aware feed-forward 3D Gaussian splatting framework. It constructs a controllable multi-view lowlight benchmark by degrading only the context views while keeping target views clean, introduces a lightweight Lowlight Adapter for residual enhancement to improve matchability, and couples it with cost-volume-based multi-view inference to directly predict clean 3D Gaussians from sparse posed images. The central claim is that this approach significantly outperforms prior feed-forward methods and two-stage pipelines under lowlight conditions for novel-view synthesis and 3D reconstruction.
Significance. If the experimental claims hold with proper validation, the work would address a practical gap in feed-forward 3D reconstruction under challenging lowlight conditions, relevant to robotics and AR/VR. The benchmark design and adapter could serve as a starting point for further lowlight-aware methods, though the absence of any reported metrics or implementation details in the manuscript prevents assessing whether the gains are substantive or generalizable.
major comments (2)
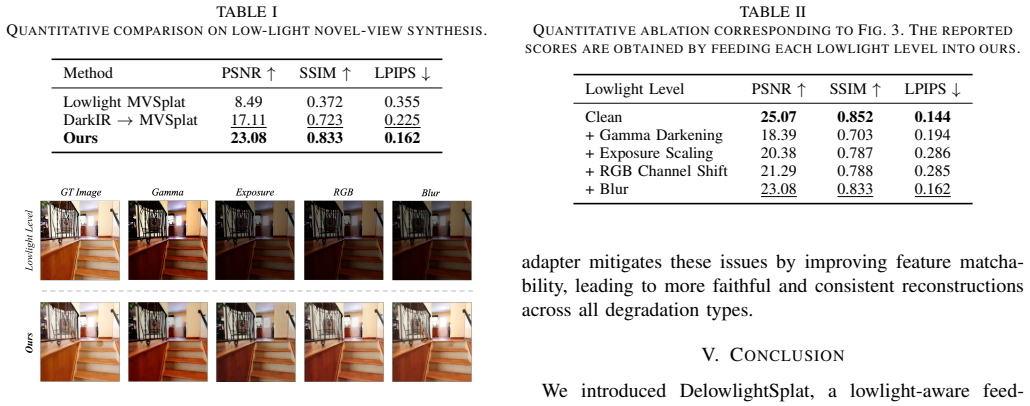
- [Abstract] Abstract: the assertion that 'Experiments show that DelowlightSplat significantly outperforms previous feed-forward method and two-stage pipeline under lowlight conditions' supplies no quantitative metrics, no details on network architecture, training procedure, loss functions, or statistical significance. Without these, the central experimental claim cannot be evaluated and is load-bearing for the paper's contribution.
- [Abstract] Abstract (benchmark description): the controllable benchmark degrades only context views while keeping target views clean. This design choice does not address whether the degradation model (noise, color shift, etc.) matches real low-light camera responses, including cross-view correlations or sensor-specific effects; if the synthetic artifacts are more easily exploited by the Lowlight Adapter and cost-volume inference than real data would allow, the reported gains would not generalize.
Simulated Author's Rebuttal
We thank the editor and the referee for the detailed and constructive feedback. We address each major comment point-by-point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experiments show that DelowlightSplat significantly outperforms previous feed-forward method and two-stage pipeline under lowlight conditions' supplies no quantitative metrics, no details on network architecture, training procedure, loss functions, or statistical significance. Without these, the central experimental claim cannot be evaluated and is load-bearing for the paper's contribution.
Authors: We agree that the abstract's phrasing of the experimental claim is too high-level and lacks supporting quantitative details, making it difficult to evaluate without reading the full paper. The body of the manuscript reports specific metrics (PSNR, SSIM, LPIPS) and architectural details in Sections 3 and 4, but these were not summarized in the abstract. We will revise the abstract to include key quantitative improvements and a concise reference to the evaluation protocol. revision: yes
-
Referee: [Abstract] Abstract (benchmark description): the controllable benchmark degrades only context views while keeping target views clean. This design choice does not address whether the degradation model (noise, color shift, etc.) matches real low-light camera responses, including cross-view correlations or sensor-specific effects; if the synthetic artifacts are more easily exploited by the Lowlight Adapter and cost-volume inference than real data would allow, the reported gains would not generalize.
Authors: The benchmark design prioritizes clean target views to enable reliable ground-truth evaluation of novel-view synthesis, which is a deliberate choice for controlled experimentation. We acknowledge that the synthetic degradation (based on standard noise and color-shift models) may not fully capture all real sensor-specific or cross-view correlation effects. We will expand the manuscript with additional details on the exact degradation parameters and add a dedicated limitations paragraph discussing generalizability to real low-light captures. revision: partial
Circularity Check
No circularity: new adapter and benchmark design are independent architectural contributions
full rationale
The paper introduces a Lowlight Adapter for residual enhancement and couples it with cost-volume multi-view inference to predict clean 3D Gaussians from degraded inputs. The controllable benchmark is constructed by synthetically degrading only context views while keeping targets clean; this is an explicit design choice for evaluation, not a fitted parameter or self-referential definition. No equations, predictions, or uniqueness claims reduce outputs to inputs by construction, and no self-citation chains are load-bearing in the abstract or described method. The derivation chain remains self-contained with externally falsifiable components.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
3D Gaussian splatting for real-time radiance field rendering,
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3D Gaussian splatting for real-time radiance field rendering,”ACM Trans. Graph., vol. 42, no. 4, Art. no. 139, pp. 1–14, 2023, doi: 10.1145/3592433
-
[2]
pixelSplat: 3D Gaussian splats from image pairs for scalable generalizable 3D re- construction,
D. Charatan, S. L. Li, A. Tagliasacchi, and V . Sitzmann, “pixelSplat: 3D Gaussian splats from image pairs for scalable generalizable 3D re- construction,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 19457–19467
2024
-
[3]
MVSplat: Efficient multi-view 3D Gaussian splatting,
T. Huang, J. Wang, and Y . Wang, “MVSplat: Efficient multi-view 3D Gaussian splatting,” arXiv preprint arXiv:2403.14627, 2024
-
[4]
NeRF in the Dark: High dynamic range view synthesis from noisy raw images,
J. T. Barron, B. Mildenhall, M. Tancik, P. Hedman, R. Martin-Brualla, and P. Srinivasan, “NeRF in the Dark: High dynamic range view synthesis from noisy raw images,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 16190–16199
2022
-
[5]
FreeSplat: General- izable 3D Gaussian splatting for free-view synthesis of indoor scenes,
Y . Wang, Z. Yan, P. Guo, Z. Wang, and Y . Gao, “FreeSplat: General- izable 3D Gaussian splatting for free-view synthesis of indoor scenes,” arXiv preprint arXiv:2405.17958, 2024
-
[6]
PF3plat: Pose-free feed-forward 3D Gaussian splatting for novel view synthesis,
S. Hong, H. Lee, W. Han, and H. Kim, “PF3plat: Pose-free feed-forward 3D Gaussian splatting for novel view synthesis,” inProc. Int. Conf. Mach. Learn. (ICML), 2025, pp. 23662–23681
2025
-
[7]
S. Liu, C. Bao, Z. Cui, X. Chu, B. Ren, L. Gu, X. Chen, M. Li, L. Ma, M. V . Conde,et al., “NTIRE 2026 3D restoration and reconstruction in real- world adverse conditions: RealX3D challenge results,” arXiv preprint arXiv:2604.04135, 2026, doi: 10.48550/arXiv.2604.04135
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.04135 2026
-
[8]
SRSplat: Feed-forward super-resolution Gaussian splatting from sparse multi-view images,
X. Hu, C. Shi, C. Yang, M. Chen, J. Ding, T. Wei, C. Wei, Z. Yu, and M. Tan, “SRSplat: Feed-forward super-resolution Gaussian splatting from sparse multi-view images,” inProc. AAAI Conf. Artif. Intell., vol. 40, no. 6, pp. 4950–4958, 2026, doi: 10.1609/aaai.v40i6.42499
-
[9]
Q. Cao, X. Hu, C. Shi, J. Ding, Z. Yu, and J. Yu, “GenSmoke-GS: A multi-stage method for novel view synthesis from smoke-degraded images using a generative model,” arXiv preprint arXiv:2604.03039, 2026, doi: 10.48550/arXiv.2604.03039
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.03039 2026
-
[10]
MVSNet: Depth inference for unstructured multi-view stereo,
Y . Yao, Z. Luo, S. Li, T. Fang, and L. Quan, “MVSNet: Depth inference for unstructured multi-view stereo,” inComputer Vision – ECCV 2018, V . Ferrari, M. Hebert, C. Sminchisescu, and Y . Weiss, Eds. Cham, Switzerland: Springer, 2018, pp. 785–801
2018
-
[11]
Stereo magnifi- cation: Learning view synthesis using multiplane images,
T. Zhou, R. Tucker, J. Flynn, G. Fyffe, and N. Snavely, “Stereo magnifi- cation: Learning view synthesis using multiplane images,”ACM Trans. Graph., vol. 37, no. 4, Art. no. 65, 2018, doi: 10.1145/3197517.3201323
-
[12]
Deep retinex decomposition for low-light enhancement,
C. Wei, W. Wang, W. Yang, and J. Liu, “Deep retinex decomposition for low-light enhancement,” inProc. Brit. Mach. Vis. Conf. (BMVC), 2018
2018
-
[13]
Learning to see in the dark,
C. Chen, Q. Chen, J. Xu, and V . Koltun, “Learning to see in the dark,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 3291–3300
2018
-
[14]
Zero- reference deep curve estimation for low-light image enhancement,
C. Guo, C. Li, J. Guo, C. C. Loy, J. Hou, S. Kwong, and R. Cong, “Zero- reference deep curve estimation for low-light image enhancement,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 1780–1789
2020
-
[15]
EnlightenGAN: Deep light enhancement without paired supervision,
Y . Jiang, X. Gong, D. Liu, C. Yu, F. Chen, X. Shen, J. Yang, P. Zhou, and Z. Wang, “EnlightenGAN: Deep light enhancement without paired supervision,”IEEE Trans. Image Process., vol. 30, pp. 2340–2349, 2021, doi: 10.1109/TIP.2021.3051462
-
[16]
DarkIR: Robust low-light image restoration,
D. Feijoo, J. C. Benito, A. Garcia, and M. V . Conde, “DarkIR: Robust low-light image restoration,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 10879–10889
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.