Enabling Extensible Embodied Capabilities with Tools
Pith reviewed 2026-06-29 17:23 UTC · model grok-4.3
The pith
Decoupling embodied skills into external tools improves task performance by 31 percent on average while exposing limits in execution capabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
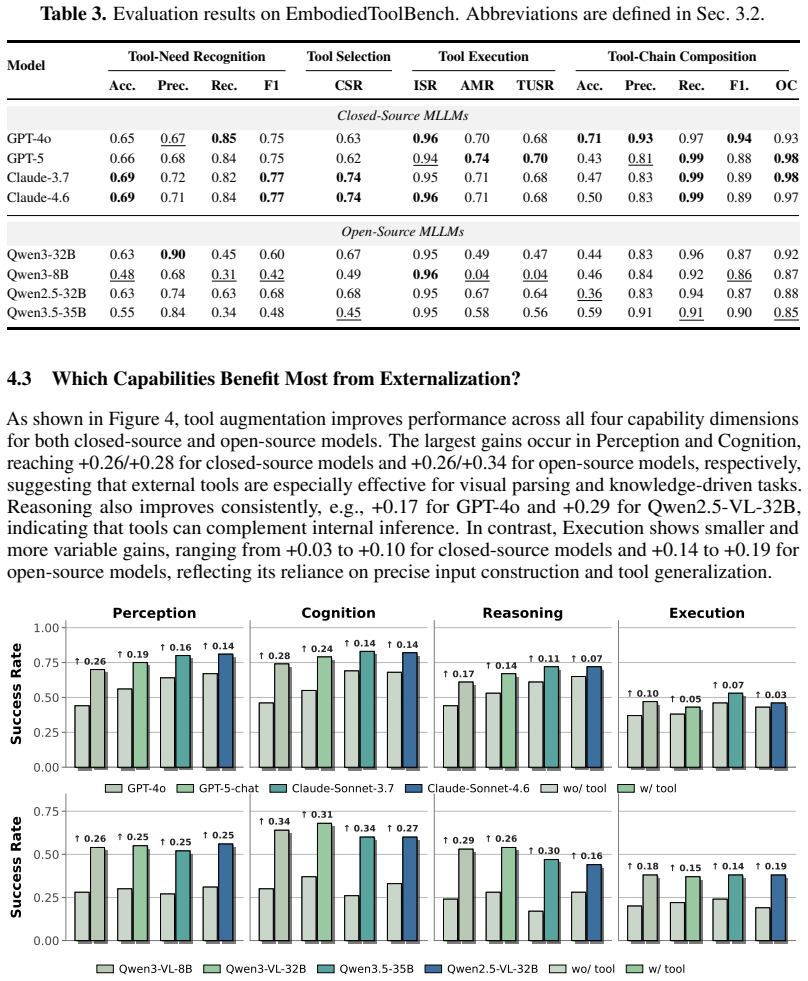
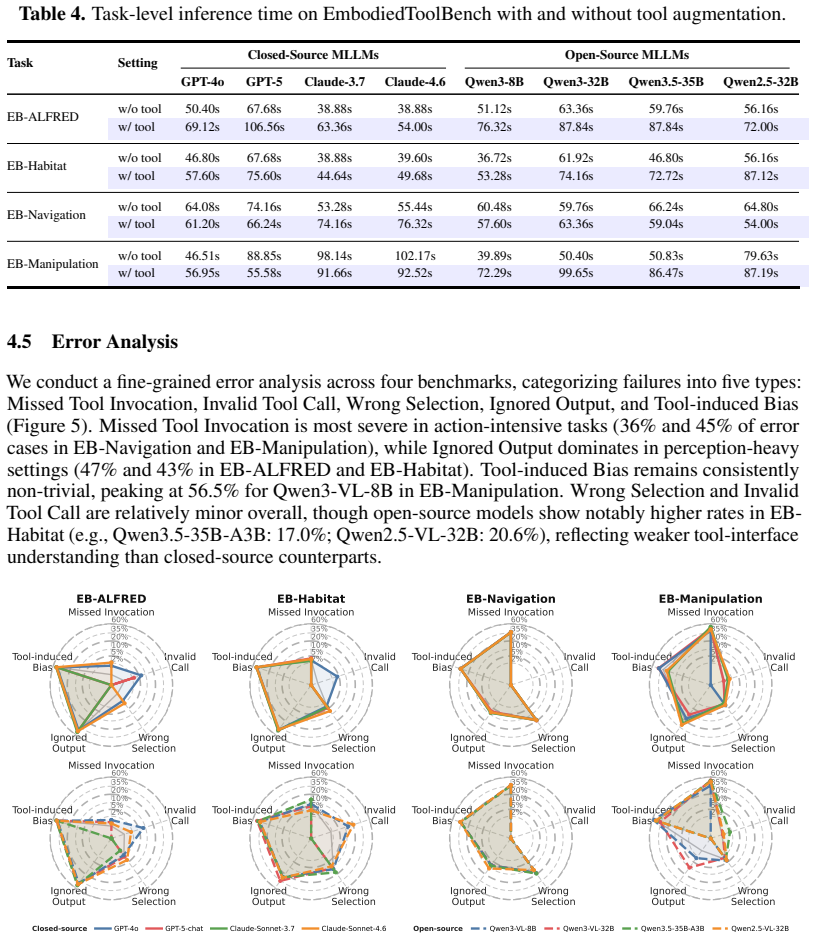
Capability externalization, achieved by registering heterogeneous skills as independently optimized tools under the Embodied Tool Protocol and invoking them dynamically, produces average performance gains of 31 percent on EB-ALFRED and 36 percent on EB-Navigation; the gains are large for perception and cognition tools yet remain limited for execution tools, and models across families continue to struggle with tool-necessity recognition, selection, execution, and chain composition.
What carries the argument
Embodied Tool Protocol (ETP), a standardized interface for tool registration, discovery, invocation, and execution that allows heterogeneous capabilities to be maintained and called outside a single policy network.
If this is right
- Tool use produces larger gains for cognition and perception than for execution-type capabilities.
- A persistent gap remains in models' ability to recognize tool need, choose the right tool, execute it correctly, and compose tool chains.
- The approach is validated across both simulation and real-world robot platforms.
- Over 100 validated tools spanning perception, cognition, reasoning, and execution form a reusable base for future work.
Where Pith is reading between the lines
- The boundary between cognitive and execution gains suggests that future tool design should prioritize tighter integration with low-level controllers rather than treating execution as just another callable module.
- If tool-invocation competence improves, the same externalization method could extend to longer-horizon tasks where unified models currently plateau.
- The benchmark results imply that progress on tool-use reasoning may now be a higher-leverage research target than further scaling of monolithic embodied policies.
Load-bearing premise
Heterogeneous capabilities can be reliably split into separate tools that a model invokes at inference time without losing coherence or adding major overhead.
What would settle it
Running the same EB-ALFRED and EB-Navigation tasks with the full tool set and finding no net improvement over a unified baseline policy, or finding measurable coherence loss during dynamic tool calls, would falsify the central claim.
Figures















read the original abstract
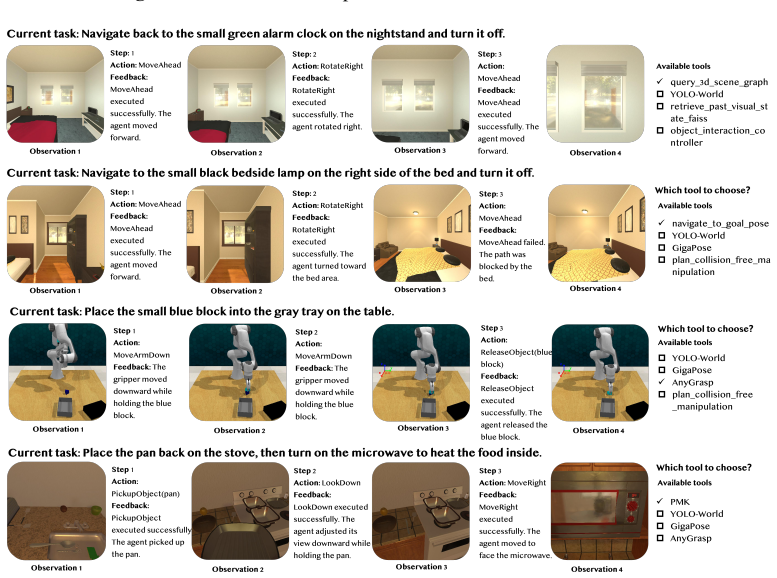
Most existing embodied intelligence methods formulate perception, reasoning, planning, and control within a unified parameterized policy. Yet these capabilities are inherently hierarchical and heterogeneous, making them difficult to reliably learn and modularize within a single model. We propose a capability externalization approach that decouples heterogeneous capabilities into independently optimized tools, dynamically invoked at inference time. To this end, we introduce Embodied Tool Protocol (ETP), a standardized protocol for embodied tool registration, discovery, invocation, and execution, and curate 100+ validated tools spanning perception, cognition, reasoning, and execution as the tool base. Building on this, we construct EmbodiedToolBench to evaluate both whether tool augmentation improves embodied performance and how well current models use tools across tool-necessity recognition, tool selection, tool execution, and tool-chain composition. Experiments across simulation and real-world platforms confirm that capability externalization consistently improves embodied performance (avg. gain 31% on EB-ALFRED and 36% on EB-Navigation), yet reveal a clear boundary: gains are substantial for cognition and perception but are limited for execution-type capabilities. Moreover, our analysis reveals that knowing when, which, and how to invoke tools remains a persistent challenge across all models, thereby highlighting embodied tool competence as a critical direction for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by decoupling heterogeneous embodied capabilities into independently optimized tools using the Embodied Tool Protocol (ETP) and curating 100+ tools, embodied performance can be consistently improved, with average gains of 31% on EB-ALFRED and 36% on EB-Navigation. Gains are substantial for cognition and perception but limited for execution-type capabilities. The paper introduces EmbodiedToolBench to evaluate tool use in terms of necessity recognition, selection, execution, and tool-chain composition, and notes that knowing when, which, and how to invoke tools remains a challenge.
Significance. If the results are substantiated, this work could be significant for advancing modular embodied AI by showing the benefits of capability externalization. The introduction of a standardized protocol (ETP) and a new benchmark (EmbodiedToolBench) are valuable for the field, enabling future research on tool-augmented systems. The empirical distinction between capability types where externalization helps is a useful finding.
major comments (2)
- [Abstract] The reported average gains of 31% on EB-ALFRED and 36% on EB-Navigation are presented without error bars, dataset details, baseline comparisons, or tool validation procedure, which is load-bearing for the central claim of consistent improvement from tool externalization.
- [Abstract] The assumption that heterogeneous capabilities can be decoupled into independently optimized tools dynamically invoked at inference without significant integration overhead or loss of coherence lacks quantitative validation of tool independence or invocation overhead; this is central to the proposed approach.
minor comments (2)
- The abstract refers to 'simulation and real-world platforms' without specifying which ones; this should be detailed in the experiments section for clarity.
- Ensure consistent use of terms like 'Embodied Tool Protocol (ETP)' and 'EmbodiedToolBench' throughout the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of capability externalization via ETP and EmbodiedToolBench. We address each major comment below with targeted revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] The reported average gains of 31% on EB-ALFRED and 36% on EB-Navigation are presented without error bars, dataset details, baseline comparisons, or tool validation procedure, which is load-bearing for the central claim of consistent improvement from tool externalization.
Authors: The full manuscript reports error bars in Tables 2 and 3, dataset splits and sizes in Section 4.1, baseline comparisons (including ablations) in Section 5.2, and tool validation criteria in Appendix B. The abstract is intentionally concise, but we agree it should better contextualize the central claim. We will revise the abstract to include a parenthetical note on statistical reporting and direct readers to the relevant sections. revision: yes
-
Referee: [Abstract] The assumption that heterogeneous capabilities can be decoupled into independently optimized tools dynamically invoked at inference without significant integration overhead or loss of coherence lacks quantitative validation of tool independence or invocation overhead; this is central to the proposed approach.
Authors: The end-to-end gains on EB-ALFRED, EB-Navigation, and real-world platforms (Section 6) already demonstrate practical feasibility of dynamic invocation. Tool independence is evidenced by the modular ETP design allowing arbitrary tool substitution without base-model retraining. We acknowledge the value of explicit overhead metrics and will add a short quantitative analysis of invocation latency and coherence (drawn from our existing logs) in a new paragraph of Section 3.3. revision: partial
Circularity Check
No circularity: empirical claims rest on external benchmarks and tool curation, not self-definition
full rationale
The paper introduces a protocol and tool base, then reports measured performance deltas on EB-ALFRED and EB-Navigation. No equations, fitted parameters, or derivations appear; the central claim (gains from externalization) is presented as an experimental outcome rather than a quantity defined in terms of itself or recovered from self-citations. Tool independence and invocation overhead are asserted as design goals but are not used to construct the reported numbers, leaving the evaluation self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Embodied Tool Protocol (ETP)
no independent evidence
-
EmbodiedToolBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding language in robotic affordances
Ahn et al. Do As I Can, Not As I Say: Grounding language in robotic affordances. InConference on Robot Learning (CoRL), pages 287–318, 2022
2022
-
[2]
LLM-as-BT-Planner: Leveraging llms for behavior tree generation in robot task planning
Ao et al. LLM-as-BT-Planner: Leveraging llms for behavior tree generation in robot task planning. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 1233–1239, 2024
2024
-
[3]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Bhat et al. ZoeDepth: Zero-shot transfer by combining relative and metric depth.arXiv, 2023. doi: 10.48550/arXiv.2302.12288
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.12288 2023
-
[4]
Black et al.π 0: A vision-language-action flow model for general robot control.arXiv, 2024
2024
-
[5]
EmbodiedRAG: Dynamic 3d scene graph retrieval for efficient and scalable robot task planning.arXiv, 2024
Booker et al. EmbodiedRAG: Dynamic 3d scene graph retrieval for efficient and scalable robot task planning.arXiv, 2024
2024
-
[6]
Octo: An open-source generalist robot policy.arXiv, 2024
Brohan et al. Octo: An open-source generalist robot policy.arXiv, 2024
2024
-
[7]
Open-vocabulary queryable scene representations for real world planning
Chen et al. Open-vocabulary queryable scene representations for real world planning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 11509–11522, 2023
2023
-
[8]
AutoTAMP: Autoregressive task and motion planning with llms as translators and checkers
Chen et al. AutoTAMP: Autoregressive task and motion planning with llms as translators and checkers. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 6695–6702, 2024
2024
-
[9]
Putting the object back into video object segmentation.arXiv, 2023
Cheng et al. Putting the object back into video object segmentation.arXiv, 2023. doi: 10.48550/arXiv.2310.12982
-
[10]
YOLO-World: Real-time open-vocabulary object detection
Cheng et al. YOLO-World: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16901–16911, 2024
2024
-
[11]
Diffusion Policy: Visuomotor policy learning via action diffusion
Chi et al. Diffusion Policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023
2023
-
[12]
TAPIR: Tracking any point with per-frame initialization and temporal refinement
Doersch et al. TAPIR: Tracking any point with per-frame initialization and temporal refinement. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10061–10072, 2023
2023
-
[13]
PaLM-E: An embodied multimodal language model.arXiv, 2023
Driess et al. PaLM-E: An embodied multimodal language model.arXiv, 2023
2023
-
[14]
AnyGrasp: Robust and efficient grasp perception in spatial and temporal domains
Fang et al. AnyGrasp: Robust and efficient grasp perception in spatial and temporal domains. IEEE Transactions on Robotics, 2023. doi: 10.48550/arXiv.2212.08333
-
[15]
RoboNeuron: A modular framework linking foundation models and ros for embodied ai.arXiv, 2025
Guan et al. RoboNeuron: A modular framework linking foundation models and ros for embodied ai.arXiv, 2025. 10
2025
-
[16]
OctoMap: An efficient probabilistic 3d mapping framework based on octrees
Hornung et al. OctoMap: An efficient probabilistic 3d mapping framework based on octrees. Autonomous Robots, 34:189–206, 2013. doi: 10.1007/s10514-012-9321-0
-
[17]
Inner Monologue: Embodied reasoning through planning with language models
Huang et al. Inner Monologue: Embodied reasoning through planning with language models. arXiv, 2022
2022
-
[18]
Visual language maps for robot navigation
Huang et al. Visual language maps for robot navigation. InProceedings of the IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 10608–10615, 2023
2023
-
[19]
Metatool benchmark for large language models: Deciding whether to use tools and which to use.arXiv, 2023
Huang et al. Metatool benchmark for large language models: Deciding whether to use tools and which to use.arXiv, 2023
2023
-
[20]
Hughes et al. Hydra: A real-time spatial perception system for 3d scene graph construction and optimization.arXiv, 2022. doi: 10.48550/arXiv.2201.13360
-
[21]
Action Genome: Actions as compositions of spatio-temporal scene graphs
Ji et al. Action Genome: Actions as compositions of spatio-temporal scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10236–10247, 2020
2020
-
[22]
LINGO-Space: Language-conditioned incremental grounding for space
Kim et al. LINGO-Space: Language-conditioned incremental grounding for space. InProceed- ings of the AAAI Conference on Artificial Intelligence, volume 38, pages 10314–10322, 2024. doi: 10.1609/aaai.v38i9.28898
-
[23]
Large Model Empowered Embodied AI: A survey on decision-making and embodied learning.arXiv, 2025
Liang et al. Large Model Empowered Embodied AI: A survey on decision-making and embodied learning.arXiv, 2025
2025
-
[24]
LLM+P: Empowering large language models with optimal planning proficiency
Liu et al. LLM+P: Empowering large language models with optimal planning proficiency. arXiv, 2023
2023
-
[25]
Lang2LTL: Translating natural language commands to temporal specification with large language models.arXiv, 2023
Liu et al. Lang2LTL: Translating natural language commands to temporal specification with large language models.arXiv, 2023
2023
-
[26]
A survey on vision-language-action models for embodied ai.arXiv, 2024
Ma et al. A survey on vision-language-action models for embodied ai.arXiv, 2024
2024
-
[27]
Orchestrating embodied systems through the embodied context protocol: Motivation, progress, and directions.Research, 2025
Ma et al. Orchestrating embodied systems through the embodied context protocol: Motivation, progress, and directions.Research, 2025
2025
-
[28]
The Marathon 2: A navigation system
Macenski et al. The Marathon 2: A navigation system. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020. URL https: //github.com/ros-planning/navigation2
2020
-
[29]
Embodied large language models enable robots to complete complex tasks in unpredictable environments.Nature Machine Intelligence, 7:592–601, 2025
Mon-Williams et al. Embodied large language models enable robots to complete complex tasks in unpredictable environments.Nature Machine Intelligence, 7:592–601, 2025
2025
-
[30]
ROS-LLM: A ros framework for embodied ai with task feedback and structured reasoning.arXiv, 2024
Mower et al. ROS-LLM: A ros framework for embodied ai with task feedback and structured reasoning.arXiv, 2024
2024
-
[31]
R3M: A Universal Visual Representation for Robot Manipulation
Nair et al. R3M: A universal visual representation for robot manipulation. InConference on Robot Learning (CoRL), 2022. doi: 10.48550/arXiv.2203.12601
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.12601 2022
-
[32]
GigaPose: Fast and robust novel object pose estimation via one correspondence
Nguyen et al. GigaPose: Fast and robust novel object pose estimation via one correspondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9903–9913, 2024
2024
-
[33]
Video object segmentation using space-time memory networks
Oh et al. Video object segmentation using space-time memory networks. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9226–9235, 2019
2019
-
[34]
Tool learning with large language models: A survey.Frontiers of Computer Science, 2025
Qu et al. Tool learning with large language models: A survey.Frontiers of Computer Science, 2025
2025
-
[35]
SayPlan: Grounding large language models using 3d scene graphs for scalable task planning
Rana et al. SayPlan: Grounding large language models using 3d scene graphs for scalable task planning. InConference on Robot Learning (CoRL), pages 23–72, 2023
2023
-
[36]
Enabling Novel Mission Operations and Interactions with ROSA: The robot operating system agent
Royce et al. Enabling Novel Mission Operations and Interactions with ROSA: The robot operating system agent. InIEEE Aerospace Conference, pages 1–16, 2024. 11
2024
-
[37]
Towards embodied agentic ai: Review and classification of llm- and vlm-driven robot autonomy and interaction.arXiv, 2025
Salimpour et al. Towards embodied agentic ai: Review and classification of llm- and vlm-driven robot autonomy and interaction.arXiv, 2025
2025
-
[38]
Toolformer: Language models can teach themselves to use tools.arXiv, 2023
Schick et al. Toolformer: Language models can teach themselves to use tools.arXiv, 2023
2023
-
[39]
ProgPrompt: Generating situated robot task plans using large language models
Singh et al. ProgPrompt: Generating situated robot task plans using large language models. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 11523–11530, 2023
2023
-
[40]
RoboSpatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics.arXiv, 2024
Song et al. RoboSpatial: Teaching spatial understanding to 2d and 3d vision-language models for robotics.arXiv, 2024
2024
-
[41]
Contact-GraspNet: Efficient 6-dof grasp generation in cluttered scenes
Sundermeyer et al. Contact-GraspNet: Efficient 6-dof grasp generation in cluttered scenes. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 13438–13444, 2021. doi: 10.1109/ICRA48506.2021.9561877
-
[42]
Large Language Models for Robotics: Opportunities, challenges, and perspectives
Wang et al. Large Language Models for Robotics: Opportunities, challenges, and perspectives. arXiv, 2024
2024
-
[43]
DUSt3R: Geometric 3d vision made easy
Wang et al. DUSt3R: Geometric 3d vision made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20697–20709, 2024
2024
-
[44]
Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation.arXiv, 2024
Werby et al. Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation.arXiv, 2024
2024
-
[45]
SceneGraphFusion: Incremental 3d scene graph prediction from rgb-d sequences
Wu et al. SceneGraphFusion: Incremental 3d scene graph prediction from rgb-d sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7515–7525, 2021
2021
-
[46]
Grounding Generative Planners in Verifiable Logic: A hybrid architecture for trustworthy embodied ai.arXiv, 2026
Wu et al. Grounding Generative Planners in Verifiable Logic: A hybrid architecture for trustworthy embodied ai.arXiv, 2026
2026
-
[47]
Open-Fusion: Real-time open-vocabulary 3d mapping and queryable scene rep- resentation
Yamazaki et al. Open-Fusion: Real-time open-vocabulary 3d mapping and queryable scene rep- resentation. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2024. doi: 10.1109/ICRA57147.2024.10610193
-
[48]
ReAct: Synergizing reasoning and acting in language models
Yao et al. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[49]
Center-based 3d object detection and tracking
Yin et al. Center-based 3d object detection and tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11784–11793, 2021
2021
-
[50]
Large Language Models for Robotics: A survey.arXiv, 2023
Zeng et al. Large Language Models for Robotics: A survey.arXiv, 2023
2023
-
[51]
Fast segment anything.arXiv preprint arXiv:2306.12156, 2023
Zhao et al. Fast segment anything.arXiv, 2023. doi: 10.48550/arXiv.2306.12156
-
[52]
A survey on evaluation of embodied ai
Liyu Hou, Linyuan Gao, Yuan Wu, and Yi Chang. A survey on evaluation of embodied ai. TechRxiv Preprint, 2026. doi: 10.22541/au.177023340.02874343/v1
-
[53]
Moveit motion planning framework
MoveIt Contributors. Moveit motion planning framework. https://moveit.ai/ , 2024. ROS-based motion planning framework for robotic manipulation
2024
-
[54]
OpenVLA: An open vision-language-action model.arXiv, 2024
OpenVLA Team. OpenVLA: An open vision-language-action model.arXiv, 2024
2024
-
[55]
EmbodiedBench: Comprehensive benchmarking multi-modal large language models for vision- driven embodied agents
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, Heng Ji, Huan Zhang, and Tong Zhang. EmbodiedBench: Comprehensive benchmarking multi-modal large language models for vision- driven embodied agents. InProceedings of the 42nd International Conference on Machine Learn...
2025
-
[56]
Directly solvable states, where the model can produce a valid action based solely on the current observationo t and interaction historyτ t, without resorting to any external tool
-
[57]
detect”, “grasp
Tool-redundant states, where the candidate tool set L is non-empty, yet no tool invocation is required at the current stage of the task. Class Balance.To prevent systematic prediction bias, we maintain a positive-to-negative sample ratio of 1:1 and apply stratified sampling across task types (navigation, planning, and manipulation), ensuring that each sce...
-
[58]
Data dependencies: the input parameters of tool zb are derived from the output of tool za, forming a direct dataflow dependency
-
[59]
w/ tool” over “w/o tool
State dependencies: the preconditions of zb require the environmental state produced by the execution of za (e.g., GraspPlanner can only plan a grasping path after ObjectDetector has successfully localized the target). All constraints are formally verified to ensure their logical necessity and completeness. Candidate Tool Set Construction (Distractor Stra...
-
[61]
If an object is not visible, use Navigation to locate the object or its likely receptacle before attempting other operations
-
[62]
Do not perform actions that violate the validity rules
Match every action name with its corresponding action id. Do not perform actions that violate the validity rules
-
[63]
If previous actions did not lead to success, revise the plan
Do not repeatedly execute the same action or action sequence. If previous actions did not lead to success, revise the plan
-
[64]
Explore alternative instances when needed
Multiple instances may appear with numeric suffixes, e.g., cabinet 2 or cabinet 3. Explore alternative instances when needed
-
[65]
If the last action failed, reflect on the failure reason and adjust the plan
Use interaction history and environment feedback to refine the current plan. If the last action failed, reflect on the failure reason and adjust the plan
-
[66]
Tool outputs are auxiliary evidence only
When visual evidence is ambiguous, when the target is small or occluded, or when spatial relations are needed, you may use tools such as habitat_toolchain, scene_graph, or yolo_world. Tool outputs are auxiliary evidence only
-
[67]
visual_state_description
Do not output bounding boxes, coordinates, scene-graph nodes, object ids, or raw tool payloads as the final executable plan. After tool use, translate the tool evidence into legal Habitat action ids. Output Format You are supposed to output exactly one JSON object and no surrounding markdown. The output JSON format should be: { "visual_state_description":...
-
[68]
Each plan should include no more than 20 actions
Avoid generating an empty plan. Each plan should include no more than 20 actions
-
[69]
Always locate a visible object using the Find action before interacting with it
-
[70]
For receptacle placement, prefer Put down rather than Drop
Match every action name with its corresponding action id. For receptacle placement, prefer Put down rather than Drop
-
[71]
If previous actions do not lead to success, modify the plan
Do not repeatedly execute the same action or sequence of actions. If previous actions do not lead to success, modify the plan
-
[72]
Explore alternative instances if the desired object is not found
Multiple instances may appear with suffixes, e.g., Cabinet_2 or Cabinet_3. Explore alternative instances if the desired object is not found
-
[73]
Use history and feedback to identify missing preconditions, such as opening a receptacle, turning on an appliance, or picking up a tool before slicing
-
[74]
Tool outputs are auxiliary evidence only
When the task involves small objects, object attributes, container contents, multiple object instances, or uncertain placement, you may use tools such as alfred_action_advisor, yolo_world, or visual object-tagging tools. Tool outputs are auxiliary evidence only
-
[75]
visual_state_description
Do not echo tool coordinates, masks, boxes, center points, foreground pixels, or raw detector outputs as the final plan. Translate tool results into legal EB-ALFRED action ids. Output Format You are supposed to output exactly one JSON object and no surrounding markdown. The output JSON format should be: { "visual_state_description": string, "reasoning_and...
-
[76]
Clearly describe the spatial location of the target object in the observation, such as front-left, front-right, nearby, or far away
Locate the target object type. Clearly describe the spatial location of the target object in the observation, such as front-left, front-right, nearby, or far away
-
[77]
A reachable point can usually be approached through a combination of moving forward, left, and right
Use forward and lateral motion as the main strategy. A reachable point can usually be approached through a combination of moving forward, left, and right
-
[78]
If the forward path is blocked, choose the safest local adjustment
Consider obstacles before moving. If the forward path is blocked, choose the safest local adjustment
-
[79]
Rotate only when the target is not visible or when orientation must be recovered
Use rotation sparingly. Rotate only when the target is not visible or when orientation must be recovered. Once the target appears, avoid unnecessary rotations
-
[80]
Continue moving closer until the robot cannot make additional safe progress toward the target
Do not stop too early. Continue moving closer until the robot cannot make additional safe progress toward the target
-
[81]
If the target is invisible, the robot is stuck, or the route is ambiguous, use tools such as navigation_action_advisor, scene_graph, or query_3d_scene_graph as GPS-like guidance
Do not rely solely on blind exploration. If the target is invisible, the robot is stuck, or the route is ambiguous, use tools such as navigation_action_advisor, scene_graph, or query_3d_scene_graph as GPS-like guidance
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.