PRISM: A Multi-Dimensional Benchmark for Evaluating LLM Peer Reviewers
Pith reviewed 2026-06-29 17:56 UTC · model grok-4.3
The pith
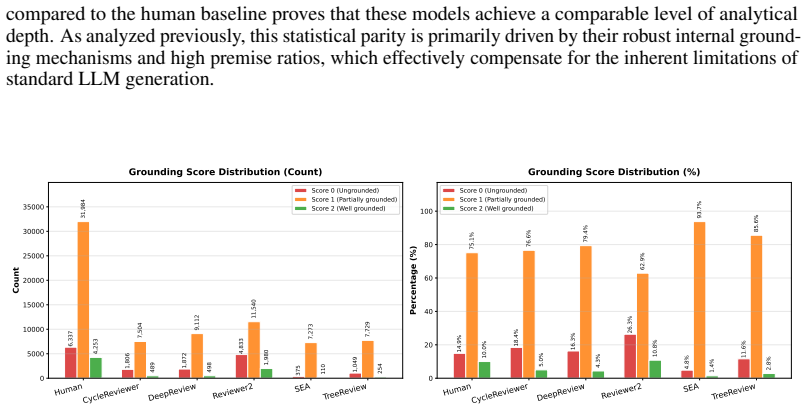
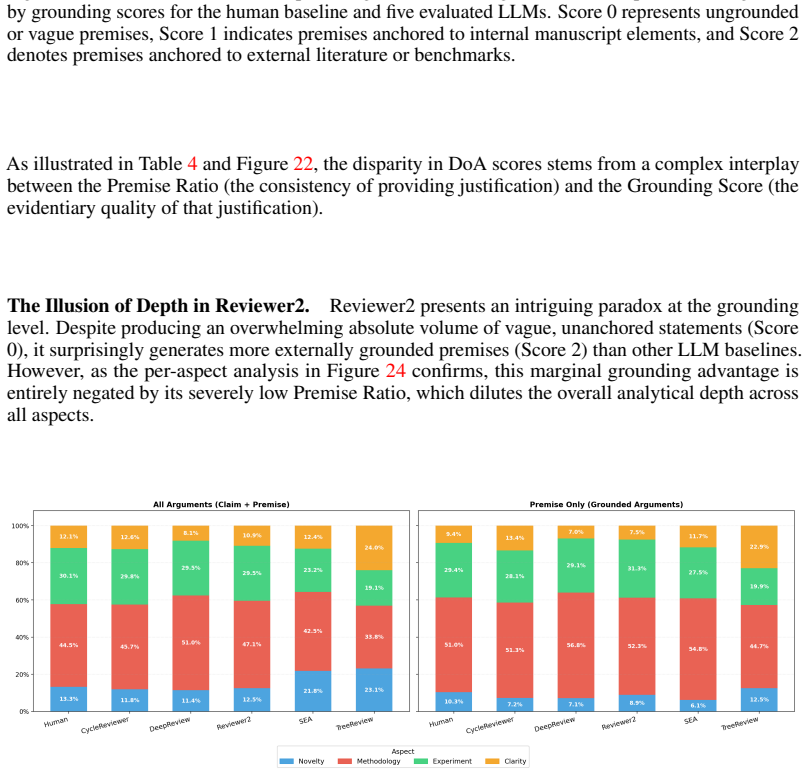
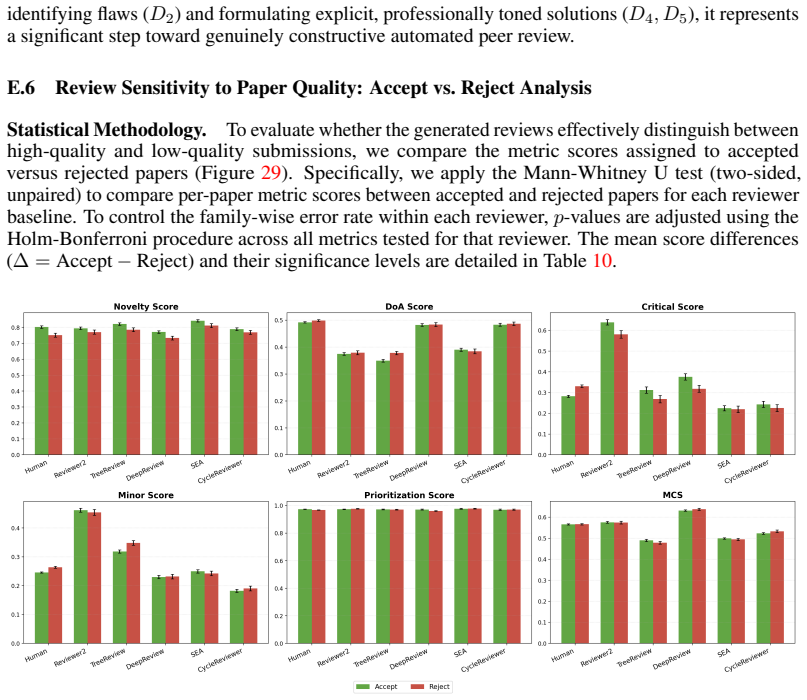
LLM peer reviewers match or beat humans on single review dimensions but lack the balanced performance humans show across all dimensions at once.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
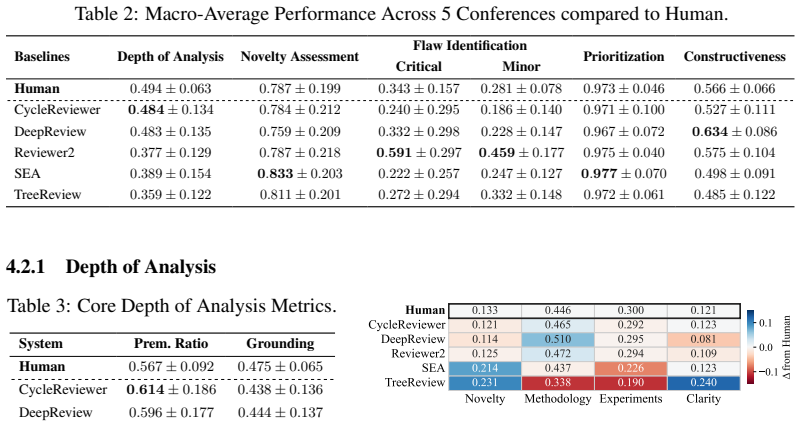
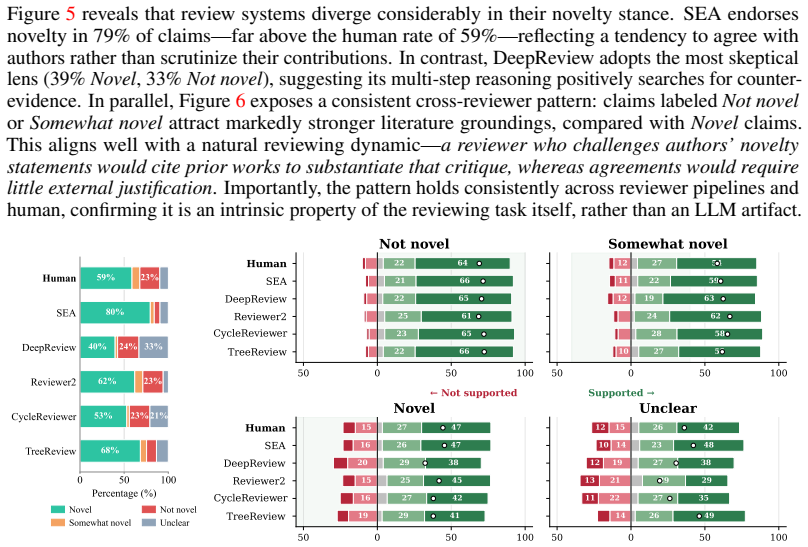
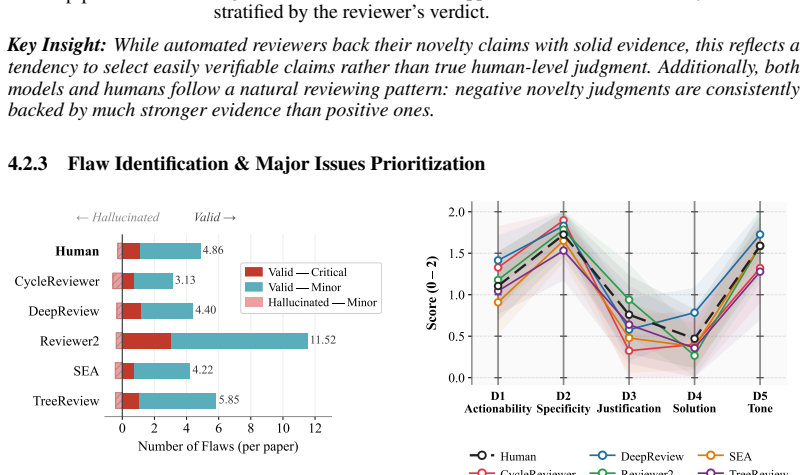
PRISM shows that LLM reviewer systems display distinct specialization profiles: they reach comparable depth of analysis, stronger novelty verification, and highly accurate critique prioritization relative to humans, yet no single system reproduces the balanced performance of the human baseline across Depth of Analysis, Novelty Assessment, Flaw Identification & Major Issues Prioritization, and Multi-dimensional Constructiveness on the stratified corpus of conference reviews.
What carries the argument
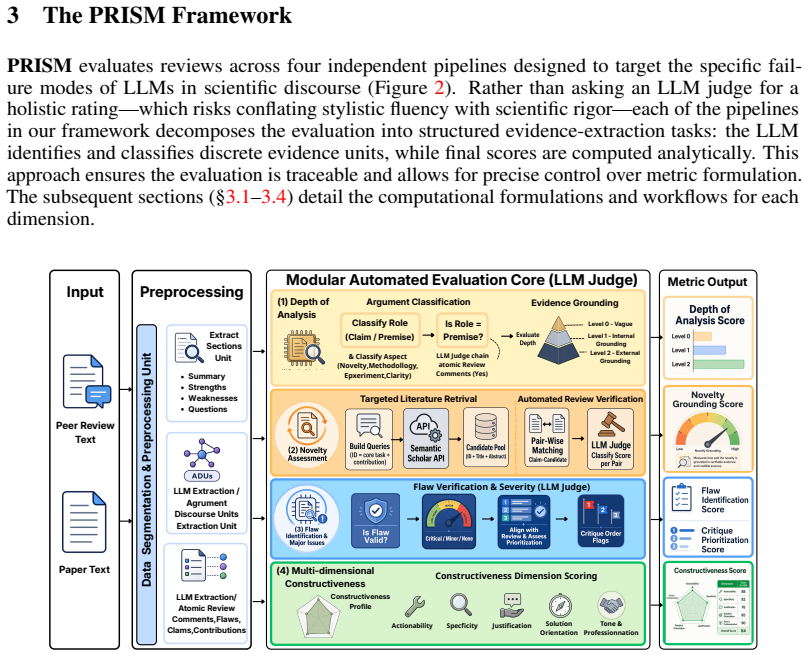
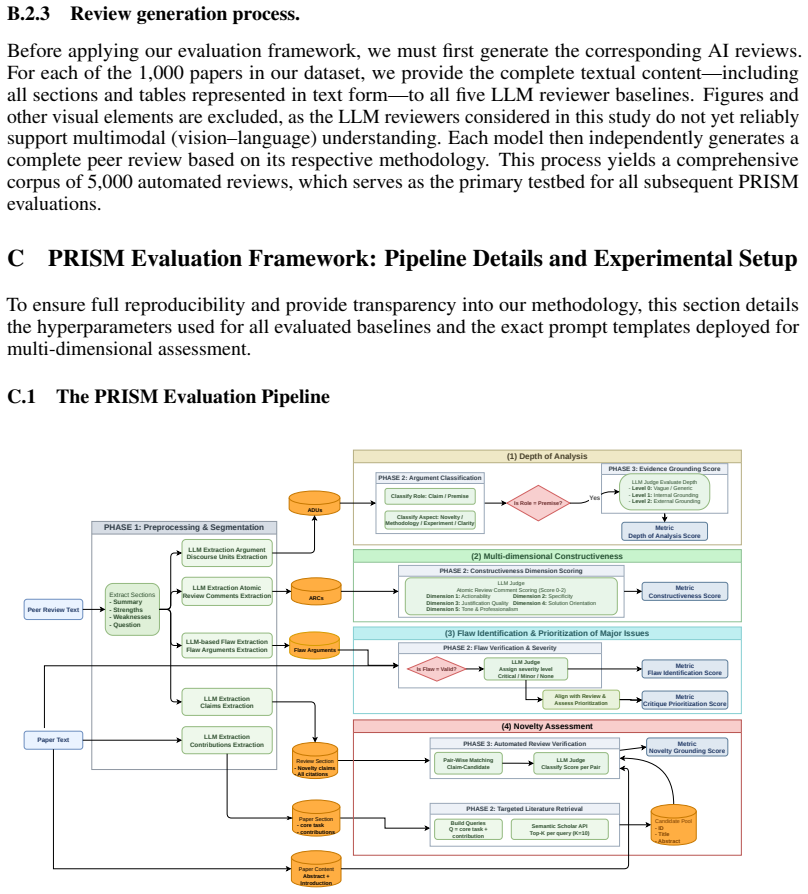
PRISM, a benchmarking framework that scores review quality on four dimensions through argument mining, retrieval-augmented verification, and consensus-based scoring.
If this is right
- LLM systems function best as targeted supplements for specific review tasks such as novelty verification rather than full replacements.
- Aggregate scores hide the specialization profiles and blind spots that appear only when dimensions are examined separately.
- Human reviewers continue to supply the integrated balance across dimensions that current LLM systems do not replicate.
- Evaluation of automated reviewers should shift from overall metrics to dimension-specific profiles to identify useful roles.
Where Pith is reading between the lines
- Review pipelines could route different dimensions to different specialized LLMs before final human synthesis.
- The same multi-dimensional approach could be tested on peer review in fields outside machine learning to check whether the pattern of partial strengths holds.
- Future LLM development might target closing the balance gap by training explicitly on the weaker dimensions identified here.
Load-bearing premise
The four chosen dimensions together with argument mining, retrieval-augmented verification, and consensus scoring provide a complete and unbiased measure of peer review quality on the selected conference corpus.
What would settle it
Demonstrating one LLM system that scores at or above the human baseline on all four dimensions simultaneously when run through PRISM on the same ICLR, ICML, and NeurIPS review corpus would falsify the central claim.
Figures


















read the original abstract
The rapid growth in submissions to machine learning venues has strained the scientific peer-review system and intensified interest in LLM-based automated peer reviewers. However, how good these systems are actually, especially compared to human reviewers at catching scientific gaps, remains poorly understood. In this work, we introduce PRISM (Peer Review Intelligence via Structured Multi-dimensional assessment), a benchmarking framework that evaluates review quality across four dimensions: Depth of Analysis, Novelty Assessment,Flaw Identification & Major Issues Prioritization, and Multi-dimensional Constructiveness. Unlike most existing evaluations based on surface-level metrics like ROUGE and BLEU, or unconstrained LLM-as-a-judge prompting that conflates fluency with rigor, PRISM grounds each dimension in argument mining, retrieval-augmented verification, and consensus-based scoring. We apply PRISM to benchmark five leading automated reviewer systems and human reviewers on a stratified corpus of reviews from ICLR, ICML, and NeurIPS. The results reveal that LLMs can match or beat human reviewers on individual dimensions: comparable depth of analysis, stronger novelty verification, and highly accurate critique prioritization. However, no single system consistently matches the balanced performance of the human baseline across all dimensions at once. Each exhibits a distinct specialization profile with characteristic blind spots -- failure modes that aggregate metrics miss entirely. The implication is that LLM reviewers are best understood as targeted supplements to human review, effective within specific dimensions, but unreliable as standalone replacements. Our demo and key results can be found at https://khanhthanhdev.github.io/prism-page/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRISM, a multi-dimensional benchmark for LLM peer reviewers that evaluates review quality across four dimensions (Depth of Analysis, Novelty Assessment, Flaw Identification & Major Issues Prioritization, and Multi-dimensional Constructiveness) using argument mining, retrieval-augmented verification, and consensus scoring. It applies the framework to five leading LLM reviewer systems and human reviewers on a stratified corpus of ICLR/ICML/NeurIPS reviews, claiming that LLMs match or exceed humans on isolated dimensions but lack the balanced performance of the human baseline, with each system showing distinct specialization profiles and blind spots.
Significance. If the benchmark holds, the work supplies a structured alternative to surface metrics like ROUGE/BLEU or unconstrained LLM-as-judge methods, offering concrete evidence on where LLMs can serve as targeted supplements rather than replacements. The emphasis on dimension-specific profiles and failure modes not captured by aggregate scores is a useful contribution to the growing literature on automated peer review.
major comments (2)
- [Abstract] Abstract and benchmark description: operational details on dimension scoring rules, inter-rater reliability metrics, and handling of post-hoc exclusions are absent, preventing verification that the reported LLM-human comparisons on individual dimensions are reproducible or robust.
- [Benchmark Construction] Benchmark construction (four dimensions + argument mining/retrieval/consensus): no external validation such as correlation with expert overall-quality ratings or meta-reviewer agreement is referenced, so it remains possible that the claimed specialization profiles and blind spots are artifacts of the chosen metric rather than intrinsic system properties.
minor comments (1)
- [Abstract] Abstract contains a missing space: 'Novelty Assessment,Flaw Identification'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will incorporate changes to improve reproducibility and validation of the benchmark.
read point-by-point responses
-
Referee: [Abstract] Abstract and benchmark description: operational details on dimension scoring rules, inter-rater reliability metrics, and handling of post-hoc exclusions are absent, preventing verification that the reported LLM-human comparisons on individual dimensions are reproducible or robust.
Authors: We agree that the abstract's brevity omits these details. The full manuscript describes dimension scoring rules (argument mining, retrieval-augmented verification, and consensus) in Section 3, reports inter-rater reliability (Fleiss' kappa = 0.72) in Section 4.2, and details post-hoc exclusions (e.g., short or incomplete reviews) in Section 3.3. To directly address reproducibility concerns, we will expand the abstract with a concise reference to these elements and insert a summary table of scoring rules in the benchmark section. revision: yes
-
Referee: [Benchmark Construction] Benchmark construction (four dimensions + argument mining/retrieval/consensus): no external validation such as correlation with expert overall-quality ratings or meta-reviewer agreement is referenced, so it remains possible that the claimed specialization profiles and blind spots are artifacts of the chosen metric rather than intrinsic system properties.
Authors: This concern is well-taken. The current manuscript relies on internal consistency via consensus scoring and grounding in argument mining methods but does not report external correlations with meta-reviewer overall-quality ratings. We will add this validation in the revision by computing Spearman rank correlations between PRISM dimension scores and meta-reviewer ratings on the stratified corpus, to confirm that the observed LLM specialization profiles align with expert judgments rather than arising solely from the metric design. revision: yes
Circularity Check
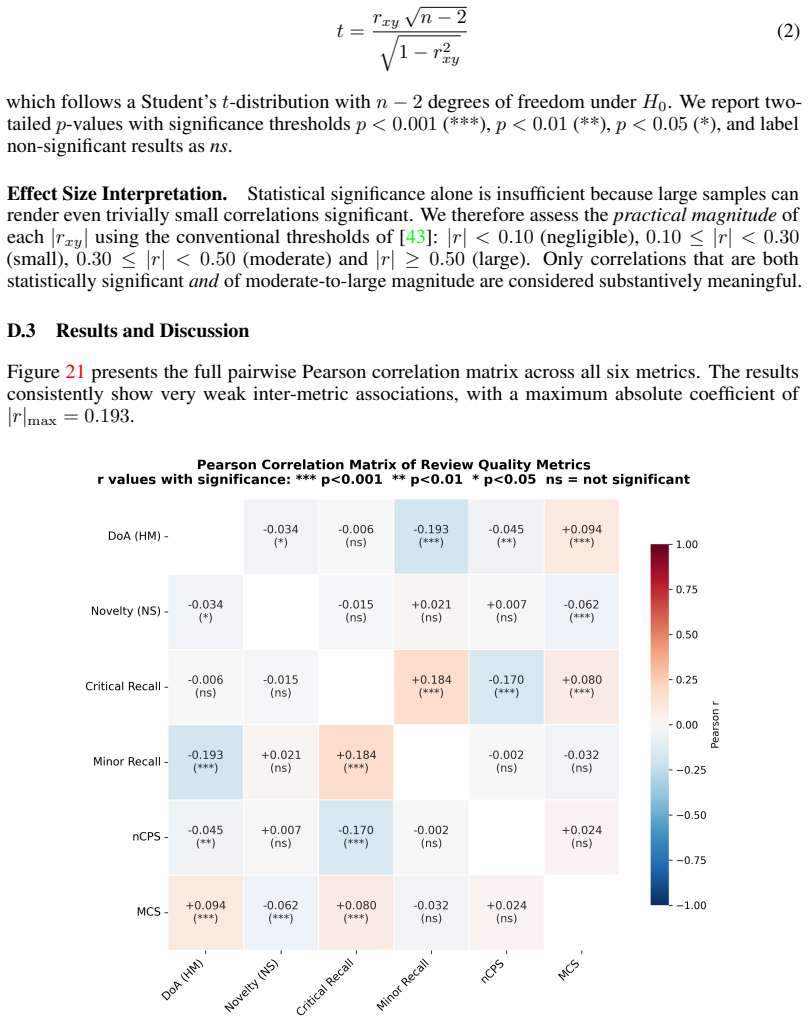
No significant circularity; benchmark relies on external techniques and held-out corpus
full rationale
The paper introduces PRISM as a new multi-dimensional evaluation framework grounded in argument mining, retrieval-augmented verification, and consensus scoring applied to a stratified held-out corpus from ICLR/ICML/NeurIPS. The reported LLM vs. human comparisons on the four dimensions are direct outputs of these external methods rather than any fitted parameters, self-definitions, or self-citation chains that reduce results to inputs by construction. No equations, ansatzes, or uniqueness theorems appear; the central claims rest on the benchmark's application to independent data without the forbidden reduction patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The four dimensions (Depth of Analysis, Novelty Assessment, Flaw Identification & Major Issues Prioritization, Multi-dimensional Constructiveness) comprehensively represent peer-review quality.
- domain assumption Argument mining combined with retrieval-augmented verification and consensus scoring yields objective, reproducible dimension scores.
Reference graph
Works this paper leans on
-
[1]
NeurIPS 2024 Statistics
Paper Copilot. NeurIPS 2024 Statistics. https://papercopilot.com/statistics/neur ips-statistics/neurips-2024-statistics/, 2024. Accessed: 2026-05-07
2024
-
[2]
Reflections on the 2025 review process from the program committee chairs
Communications Chairs 2025. Reflections on the 2025 review process from the program committee chairs. https://blog.neurips.cc/2025/09/30/reflections-on-the- 2025-review-process-from-the-program-committee-chairs/ , 2025. Accessed: 2026-05-07
2025
-
[3]
ICML 2023 statistics
Paper Copilot. ICML 2023 statistics. https://papercopilot.com/statistics/icml- statistics/icml-2023-statistics/, 2023. Accessed: 2026-04-06
2023
-
[4]
ICML 2024 statistics
Paper Copilot. ICML 2024 statistics. https://papercopilot.com/statistics/icml- statistics/icml-2024-statistics/, 2024. Accessed: 2026-04-06
2024
-
[5]
ICML 2025 statistics
Paper Copilot. ICML 2025 statistics. https://papercopilot.com/statistics/icml- statistics/icml-2025-statistics/, 2025. Accessed: 2026-05-06
2025
-
[6]
Introducing ICML 2026 policy for self-ranking in reviews
Weijie Su and Buxin Su. Introducing ICML 2026 policy for self-ranking in reviews. https: //blog.icml.cc/2026/01/12/introducing-icml-2026-policy-for-self-rankin g-in-reviews/, January 2026. Accessed: 2026-05-06
2026
-
[7]
Yuan Chang, Ziyue Li, Hengyuan Zhang, Yuanbo Kong, Yanru Wu, Hayden Kwok-Hay So, Zhijiang Guo, Liya Zhu, and Ngai Wong. TreeReview: A dynamic tree of questions framework for deep and efficient LLM-based scientific peer review. In Christos Christodoulopoulos, Tan- moy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on...
-
[8]
Reviewer2: Optimizing review genera- tion through prompt generation, 2024
Zhaolin Gao, Kianté Brantley, and Thorsten Joachims. Reviewer2: Optimizing review genera- tion through prompt generation, 2024. URLhttps://arxiv.org/abs/2402.10886
-
[9]
Automated peer reviewing in paper SEA: Standardization, evaluation, and analysis
Jianxiang Yu, Zichen Ding, Jiaqi Tan, Kangyang Luo, Zhenmin Weng, Chenghua Gong, Long Zeng, RenJing Cui, Chengcheng Han, Qiushi Sun, Zhiyong Wu, Yunshi Lan, and Xiang Li. Automated peer reviewing in paper SEA: Standardization, evaluation, and analysis. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computatio...
-
[10]
DeepReview: Improving LLM- based paper review with human-like deep thinking process
Minjun Zhu, Yixuan Weng, Linyi Yang, and Yue Zhang. DeepReview: Improving LLM- based paper review with human-like deep thinking process. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29330–29355, ...
-
[11]
Cycleresearcher: Improving automated research via automated review
Yixuan Weng, Minjun Zhu, Guangsheng Bao, Hongbo Zhang, Jindong Wang, Yue Zhang, and Linyi Yang. Cycleresearcher: Improving automated research via automated review. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=bjcsVLoHYs. 11
2025
-
[12]
Weixin Liang, Yuhui Zhang, Hancheng Cao, Binglu Wang, Daisy Yi Ding, Xinyu Yang, Kailas V odrahalli, Siyu He, Daniel Scott Smith, Yian Yin, Daniel A. McFarland, and James Zou. Can large language models provide useful feedback on research papers? a large-scale empirical analysis.NEJM AI, 1(8):AIoa2400196, 2024. doi: 10.1056/AIoa2400196. URL https://ai.nejm...
-
[13]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6), March
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6), March
-
[14]
ISSN 2095-2236. doi: 10.1007/s11704-024-40231-1. URL http://dx.doi.org/10. 1007/s11704-024-40231-1
-
[15]
Policies on large language model usage at ICLR 2026
ICLR 2026 Program Chairs. Policies on large language model usage at ICLR 2026. https: //iclr.cc/FAQ/LLM, August 2025. Accessed: 2026-05-07
2026
-
[16]
Icml 2026 policy for llm use in reviewing
ICML. Icml 2026 policy for llm use in reviewing. https://icml.cc/Conferences/2026 /LLM-Policy, 2026. Accessed: 2026-04-28
2026
-
[17]
Alina Beygelzimer, Yann N Dauphin, Percy Liang, and Jennifer Wortman Vaughan. Has the machine learning review process become more arbitrary as the field has grown? the neurips 2021 consistency experiment.arXiv preprint arXiv:2306.03262, 2023
-
[18]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summariza- tion Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URLhttps://aclanthology.org/W04-1013/
2004
-
[19]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Pierre Isabelle, Eugene Charniak, and Dekang Lin, editors, Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association for Comput...
-
[20]
Why we need new evaluation metrics for NLG
Jekaterina Novikova, Ondˇrej Dušek, Amanda Cercas Curry, and Verena Rieser. Why we need new evaluation metrics for NLG. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2241–2252, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi: 10.18653/v1/D17-1238. URL https: //aclantholo...
-
[21]
G- eval: NLG evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G- eval: NLG evaluation using gpt-4 with better human alignment. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore, December 2023. Association for Computational...
-
[22]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Sys...
2023
-
[23]
Large language models are not robust multiple choice selectors
Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. Large language models are not robust multiple choice selectors. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,International Conference on Learning Representations, volume 2024, pages 19426–19454, 2024. URL https://proceedings.iclr.cc/paper_files/pa per/2024...
2024
-
[24]
Verbosity bias in preference labeling by large language models
Keita Saito, Akifumi Wachi, Koki Wataoka, and Youhei Akimoto. Verbosity bias in preference labeling by large language models. InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023. URLhttps://openreview.net/forum?id=magEgFpK1y. 12
2023
-
[25]
Llm evaluators recognize and favor their own generations.Advances in Neural Information Processing Systems, 37:68772–68802, 2024
Arjun Panickssery, Samuel R Bowman, and Shi Feng. Llm evaluators recognize and favor their own generations.Advances in Neural Information Processing Systems, 37:68772–68802, 2024
2024
-
[26]
ReviewEval: An evaluation framework for AI-generated reviews
Madhav Krishan Garg, Tejash Prasad, Tanmay Singhal, Chhavi Kirtani, Murari Mandal, and Dhruv Kumar. ReviewEval: An evaluation framework for AI-generated reviews. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Computational Linguistics: EMNLP 2025, pages 20542–20564, Suzhou, China,...
-
[27]
Rottenreviews: Benchmarking review quality with human and llm-based judgments
Sajad Ebrahimi, Soroush Sadeghian, Ali Ghorbanpour, Negar Arabzadeh, Sara Salamat, Muhan Li, Hai Son Le, Mahdi Bashari, and Ebrahim Bagheri. Rottenreviews: Benchmarking review quality with human and llm-based judgments. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, CIKM ’25, page 5642–5649, New York, NY , ...
-
[28]
Mind the blind spots: A focus-level evaluation framework for LLM reviews
Hyungyu Shin, Jingyu Tang, Yoonjoo Lee, Nayoung Kim, Hyunseung Lim, Ji Yong Cho, Hwajung Hong, Moontae Lee, and Juho Kim. Mind the blind spots: A focus-level evaluation framework for LLM reviews. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 35630–35656, Suzhou, China, nov 2025. Association for Computation...
-
[29]
Nils Dycke and Iryna Gurevych. Automatic reviewers fail to detect faulty reasoning in research papers: A new counterfactual evaluation framework.arXiv preprint arXiv:2508.21422, 2025. doi: 10.48550/arXiv.2508.21422. URLhttps://arxiv.org/abs/2508.21422
-
[30]
Argument mining for understanding peer reviews
Xinyu Hua, Mitko Nikolov, Nikhil Badugu, and Lu Wang. Argument mining for understanding peer reviews. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2131– 2137...
-
[31]
From argument diagrams to argumentation mining in texts: A survey.Int
Andreas Peldszus and Manfred Stede. From argument diagrams to argumentation mining in texts: A survey.Int. J. Cogn. Inform. Nat. Intell., 7(1):1–31, January 2013. ISSN 1557-3958. doi: 10.4018/jcini.2013010101. URLhttps://doi.org/10.4018/jcini.2013010101
- [32]
-
[33]
Shubhanshu Mishra and Vetle I. Torvik. Quantifying conceptual novelty in the biomedical literature.D-Lib magazine : the magazine of the Digital Library Forum, 22 9-10, 2016. doi: 10.1045/september2016-mishra. URL https://api.semanticscholar.org/CorpusID: 1732032
-
[34]
A review on the novelty measurements of academic papers
Yi Zhao and Chengzhi Zhang. A review on the novelty measurements of academic papers. Scientometrics, 130:727 – 753, 2025. doi: 10.1007/s11192-025-05234-0. URL https: //api.semanticscholar.org/CorpusID:275954035
-
[35]
Ming Zhang, Kexin Tan, Yueyuan Huang, Yujiong Shen, Chunchun Ma, Li Ju, Xinran Zhang, Yuhui Wang, Wenqing Jing, Jingyi Deng, et al. Opennovelty: An llm-powered agentic system for verifiable scholarly novelty assessment.arXiv preprint arXiv:2601.01576, 2026. doi: 10.48550/arXiv.2601.01576. URLhttps://arxiv.org/abs/2601.01576
-
[36]
Cumulated gain-based evaluation of ir techniques.ACM Trans
Kalervo Järvelin and Jaana Kekäläinen. Cumulated gain-based evaluation of ir techniques.ACM Trans. Inf. Syst., 20(4):422–446, October 2002. ISSN 1046-8188. doi: 10.1145/582415.582418. URLhttps://doi.org/10.1145/582415.582418. 13
-
[37]
DIS- APERE: A dataset for discourse structure in peer review discussions
Neha Nayak Kennard, Tim O’Gorman, Rajarshi Das, Akshay Sharma, Chhandak Bagchi, Matthew Clinton, Pranay Kumar Yelugam, Hamed Zamani, and Andrew McCallum. DIS- APERE: A dataset for discourse structure in peer review discussions. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz, editors,Proceedings of the 2022 Conference of the No...
-
[38]
This work is antithetical to the spirit of research
Ken Hyland and Feng Kevin Jiang. “This work is antithetical to the spirit of research”: An anatomy of harsh peer reviews.Journal of English for Academic Purposes, 46:100867, 2020. doi: 10.1016/j.jeap.2020.100867
-
[39]
Regression towards the mean—a plea for civility in peer review.BMJ, 379:o2886, 2022
Rahul Tony Rao and Beth Bareham. Regression towards the mean—a plea for civility in peer review.BMJ, 379:o2886, 2022. doi: 10.1136/bmj.o2886
-
[40]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URLhttps://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Wenqing Wu, Chengzhi Zhang, Yi Zhao, and Tong Bao. Impact of large language models on peer review opinions from a fine-grained perspective: Evidence from top conference proceedings in AI.arXiv preprint arXiv:2604.19578, 2026. URLhttps://arxiv.org/abs/2604.19578
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
MiMo-V2.5-Pro
Xiaomi MiMo Team. MiMo-V2.5-Pro. https://huggingface.co/XiaomiMiMo/MiMo- V2.5-Pro, 2026. Hugging Face model card. Accessed: 2026-05-07
2026
-
[43]
The use of mmr, diversity-based reranking for reordering documents and producing summaries
Jaime Carbonell and Jade Goldstein. The use of mmr, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval, pages 335–336, 1998. doi: 10.1145/290941.291025
-
[44]
Lawrence Erlbaum Associates, Hillsdale, NJ, 2nd edition, 1988
Jacob Cohen.Statistical Power Analysis for the Behavioral Sciences. Lawrence Erlbaum Associates, Hillsdale, NJ, 2nd edition, 1988. 14 Appendix Table of Contents A Formal Problem Definition B Experimental Details B.1 Dataset Selection B.2 Reviewer Baselines and Implementations B.3 Review Generation Process C PRISM Evaluation Framework: Pipeline Details C.1...
1988
-
[45]
After each independent logical unit, insert the exact marker<sep>
-
[46]
Keep the original text in the exact same order WITHOUT adding, removing, or altering any words
-
[47]
because",
CRITICAL: DO split complex/compound sentences when a conclusion/claim is joined with its supporting reason/evidence. Split at: • Logical and causal conjunctions ("because", "as", "since", "due to", "but", "however", etc). • Relative pronouns (e.g., "which", "that", "who", etc). • Participial phrases indicating result/proof ("demonstrating", "showing", "pr...
-
[48]
**Summary:**
IGNORE structural headings entirely (e.g., "**Summary:**", "**Strengths:**"). DO NOT append<sep>to them. INPUT REVIEW TEXT: {raw_review_text} Figure 10: PRISM Depth of Analysis Prompt (1/3): Argumentative Discourse Unit (ADU) Segmenta- tion. 19 Phase 2: Argument Role and Aspect Topic Classification ROLE AND OBJECTIVE Classify the Argument Role and Aspect ...
-
[49]
The proposed method is not novel. Similar architectures were already introduced by Smith et al. (2023)
ARGUMENT ROLE CLASSIFICATION (Choose exactly ONE) • Claim (Conclusion / Point):The statement that is being arguedfor. It is the controversial statement or the central point that needs support. • Premise (Reason / Support):The statement that is used tosupportthe Claim. It provides the reasons, evidence, justifications, or grounds to accept the Claim. Examp...
2023
-
[50]
Grounding Score
ASPECT TOPIC CLASSIFICATION (Choose exactly ONE) •Novelty & Related Work:Discusses originality, plagiarism, or literature review. • Methodology & Theoretical Soundness:Discusses math, algorithms, architecture, or dataset guidelines. • Experimental Design & Evaluation:Discusses empirical setups, baselines, abla- tion studies, and metrics. • Clarity, Presen...
2023
-
[51]
Do not merge distinct scientific issues merely because they share a broad topic
Conceptual Consistency (Must Split):Arguments grouped into the same Micro- flaw MUST address the same fundamental problem. Do not merge distinct scientific issues merely because they share a broad topic
-
[52]
Allowed Aggregation (Can Group):Arguments MAY be grouped if they point to the exact same specific error in the paper (e.g., multiple reviewers citing the same missing baseline)
-
[53]
No Forced Fit:If an argument does not fit any existing Micro-flaw precisely, create a new one
-
[54]
Critical
No Upper Bound:There is no limit on the number of Micro-flaws. Multiple Micro-flaws may share the same Macro-topic. TAXONOMY (7 Macro-topics):Novelty & Contribution; Clarity & Presentation; Appli- cability, Scalability & Limitations; Experimental Design & Evaluation; Related Work & Citations; Methodology & Theoretical Soundness; Reproducibility & Open Sci...
2022
-
[55]
Extract ALL distinct points from Summary, Strengths, Weaknesses, Questions, and Suggestions
-
[56]
One point per ARC:If a single sentence contains two critiques, split it into two separate ARCs
-
[57]
Anchor Quote:Provide a verbatim 5-25 word substring copied EXACTLY from the review to anchor the comment
-
[58]
Current-driven vortex oscillations in metallic nanocontacts
Comment Type:Classify each ARC as exactly one of: weakness, strength, question,suggestion, orobservation. OUTPUT FORMAT Respond ONLY with a valid JSON object. INPUT REVIEW TEXT: {raw_review_text} Figure 19: PRISM Constructiveness Prompt (1/2): Decomposing the review into distinct Atomic Review Comments (ARCs). 29 Phase 2: Multi-dimensional Constructivenes...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.