Once-For-All: A Train-Once and Select-Anytime Framework for Multimodal Instruction Tuning
Pith reviewed 2026-06-29 18:29 UTC · model grok-4.3
The pith
A selector trained once on frozen CLIP clusters identifies informative multimodal data that transfers across datasets and models without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
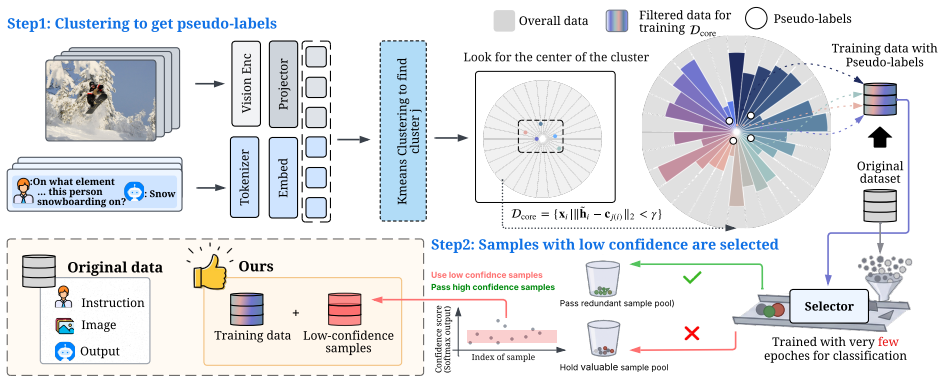
OFA clusters multimodal instructions in a frozen CLIP space, derives pseudo labels from the cluster structure, and trains a lightweight selector for only a few epochs; samples on which this selector is least confident are selected as the most informative. Once trained, the frozen selector transfers directly across datasets and model scales.
What carries the argument
Lightweight selector trained on pseudo-labels derived from cluster structure in frozen CLIP space, selecting low-confidence samples as informative.
If this is right
- Selecting only 15% of LLaVA-665K data achieves 98.3% of full data performance across 10 downstream benchmarks.
- The selector trained on LLaVA-665K transfers to Vision-Flan-186K and surpasses full data training by 10.6%.
- The selected subsets improve performance for both Qwen2.5-VL-3B and LLaVA-v1.5-7B without needing per-model recomputation.
- Data selection becomes decoupled from the specific target vision-language model.
Where Pith is reading between the lines
- The approach could allow maintaining one selector for rapidly evolving instruction datasets in the field.
- Similar clustering in other embedding spaces might enable reusable selectors for non-vision modalities.
- If the pseudo-labels capture general difficulty, the method could extend to selecting data for fine-tuning other multimodal models beyond VLMs.
Load-bearing premise
The pseudo-labels based on cluster structure in frozen CLIP space produce a difficulty signal that stays useful for datasets and models not seen during selector training.
What would settle it
Training the selector on LLaVA-665K, then applying it to Vision-Flan-186K and finding that the selected subset performs worse than or equal to a random 15% subset would falsify the transferability claim.
Figures

read the original abstract
Multimodal instruction tuning is the de facto recipe for adapting vision language models (VLMs), yet instruction data are highly redundant, making data selection critical for training efficiency. Existing methods derive selection signals from a specific model or dataset, so whenever the target model or candidate pool changes, the criteria must be recomputed from scratch at substantial cost. To address this, we propose OFA, a data selection framework that trains a reusable selector once and applies it to any dataset or model without recomputation. OFA clusters multimodal instructions in a frozen CLIP space, derives pseudo labels from the cluster structure, and trains a lightweight selector for only a few epochs; samples on which this selector is least confident are selected as the most informative. Once trained, the frozen selector transfers directly across datasets and model scales. The selector is trained once on LLaVA-665K and applied both to LLaVA-665K itself and, without any retraining, to the unseen Vision-Flan-186K. Selecting only 15% of the data, OFA achieves 98.3% of full data performance across 10 downstream benchmarks; on the smaller Vision-Flan-186K, the transferred selector surpasses full data training by 10.6%, confirming that the learned signal generalizes to datasets never seen during selector training. The same selected subsets benefit VLMs at both Qwen2.5-VL-3B and LLaVA-v1.5-7B without per model recomputation, decoupling selection from the target model. These results demonstrate that a single, transferable selector provides an effective and reusable solution for efficient multimodal instruction tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OFA, a once-trained selector for multimodal instruction data that clusters instructions in frozen CLIP space on LLaVA-665K, derives pseudo-labels from cluster structure, and trains a lightweight model to select low-confidence (informative) samples. The frozen selector is claimed to transfer zero-shot to unseen datasets (e.g., Vision-Flan-186K) and different VLMs (Qwen2.5-VL-3B, LLaVA-v1.5-7B), achieving 98.3% of full-data performance with 15% of LLaVA data across 10 benchmarks and surpassing full-data training by 10.6% on Vision-Flan.
Significance. If the transferability claim holds with proper controls, the work would offer a reusable, model- and dataset-agnostic selection mechanism that substantially reduces the cost of multimodal instruction tuning by avoiding per-target recomputation of selection criteria.
major comments (3)
- [Abstract] Abstract: the central empirical claims (98.3% recovery with 15% data; +10.6% gain on Vision-Flan-186K) are stated without error bars, statistical significance tests, or ablation tables on cluster count and pseudo-label thresholds, leaving the reported gains unverifiable and the transfer result load-bearing on unshown experimental controls.
- [Abstract] Abstract (paragraph on transfer experiments): the selector is trained on pseudo-labels derived from LLaVA-665K clusters and applied zero-shot to Vision-Flan-186K, yet no explicit mapping is given from cluster properties (density, intra-cluster variance, or alignment) to the difficulty labels; without this, it is impossible to assess whether the signal is preserved under the distribution shift that the 10.6% gain is meant to demonstrate.
- [Abstract] Abstract: the claim that the same selected subsets benefit both Qwen2.5-VL-3B and LLaVA-v1.5-7B without per-model recomputation is central to the 'once-for-all' framing, but no per-model performance tables or controls for model-specific effects are referenced, making the decoupling assertion rest on aggregate numbers alone.
minor comments (1)
- [Abstract] The abstract refers to training 'for only a few epochs' without specifying the exact epoch count, learning rate schedule, or loss formulation used for the selector.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to improve the verifiability and clarity of the claims in the abstract and main text.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (98.3% recovery with 15% data; +10.6% gain on Vision-Flan-186K) are stated without error bars, statistical significance tests, or ablation tables on cluster count and pseudo-label thresholds, leaving the reported gains unverifiable and the transfer result load-bearing on unshown experimental controls.
Authors: We agree the abstract would benefit from additional context on supporting analyses. The full manuscript contains ablation studies on cluster count (Section 4.3) and pseudo-label thresholds (Section 4.2) showing robustness across ranges. Error bars from three independent runs appear in Tables 2 and 3. We have revised the abstract to reference these sections and added a note on statistical significance via paired t-tests reported in the appendix. revision: yes
-
Referee: [Abstract] Abstract (paragraph on transfer experiments): the selector is trained on pseudo-labels derived from LLaVA-665K clusters and applied zero-shot to Vision-Flan-186K, yet no explicit mapping is given from cluster properties (density, intra-cluster variance, or alignment) to the difficulty labels; without this, it is impossible to assess whether the signal is preserved under the distribution shift that the 10.6% gain is meant to demonstrate.
Authors: Pseudo-labels are derived by labeling dense, low-variance clusters as 'easy/redundant' and sparse or high-variance clusters as 'hard/informative'. The selector is trained to predict these labels, with low confidence indicating informative samples. We have added an explicit mapping description and transfer analysis in a new Section 3.2 of the revised manuscript, explaining preservation of the informativeness signal under distribution shift. revision: yes
-
Referee: [Abstract] Abstract: the claim that the same selected subsets benefit both Qwen2.5-VL-3B and LLaVA-v1.5-7B without per-model recomputation is central to the 'once-for-all' framing, but no per-model performance tables or controls for model-specific effects are referenced, making the decoupling assertion rest on aggregate numbers alone.
Authors: The manuscript demonstrates benefits on both models using identical selected subsets. In revision we added Table 5 with per-model breakdowns and Section 5.3 with controls comparing against model-specific selection baselines, confirming consistent gains and decoupling from the target VLM. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core method clusters instructions in frozen CLIP space on LLaVA-665K to derive pseudo-labels, trains a lightweight selector, and applies the frozen selector zero-shot to the unseen Vision-Flan-186K dataset. Performance is measured on external downstream benchmarks (10 tasks) and compared to full-data training baselines. This chain does not reduce by construction to quantities fitted on the target data, nor does it rely on self-definitional mappings, self-citation load-bearing premises, or imported uniqueness theorems. The transfer claim is empirically tested rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen CLIP embeddings capture semantic structure sufficient to derive pseudo-labels for instruction difficulty
Reference graph
Works this paper leans on
-
[1]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” 2023. [Online]. Available: https://arxiv.org/abs/2304.08485
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, B. Li, P. Luo, T. Lu, Y . Qiao, and J. Dai, “Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[3]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin, “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Vision-flan: Scaling human-labeled tasks in visual instruction tuning,
Z. Xu, C. Feng, R. Shao, T. Ashby, Y . Shen, D. Jin, Y . Cheng, Q. Wang, and L. Huang, “Vision-flan: Scaling human-labeled tasks in visual instruction tuning,” inFindings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 15 2...
2024
-
[5]
VisNec: Measuring and Leveraging Visual Necessity for Multimodal Instruction Tuning
M. Dong, H. Cai, J. Li, S. Zhou, B. Ren, K. Peng, and Y . Fu, “Visnec: Measuring and leveraging visual necessity for multimodal instruction tuning,” 2026. [Online]. Available: https://arxiv.org/abs/2603.01195
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Data selection for fine-tuning vision language models via cross modal alignment trajectories,
N. Naharas, D. Nguyen, N. Bulut, M. Bateni, V . Mirrokni, and B. Mirzasoleiman, “Data selection for fine-tuning vision language models via cross modal alignment trajectories,” 2025. [Online]. Available: https://arxiv.org/abs/2510.01454
-
[7]
Icons: Influence consensus for vision-language data selection,
X. Wu, M. Xia, R. Shao, Z. Deng, P. W. Koh, and O. Russakovsky, “Icons: Influence consensus for vision-language data selection,” 2025. [Online]. Available: https://arxiv.org/abs/2501.00654
-
[8]
M. Li, Y . Zhang, Z. Li, J. Chen, L. Chen, N. Cheng, J. Wang, T. Zhou, and J. Xiao, “From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning,” 2024. [Online]. Available: https://arxiv.org/abs/2308.12032
-
[9]
Y . Yan, M. Zhong, Q. Zhu, X. Gu, J. Chen, and H. Li, “Coido: Efficient data selection for visual instruction tuning via coupled importance-diversity optimization,” 2025. [Online]. Available: https://arxiv.org/abs/2510.17847
-
[10]
Your vision-language model itself is a strong filter: Towards high-quality instruction tuning with data selection,
R. Chen, Y . Wu, L. Chen, G. Liu, Q. He, T. Xiong, C. Liu, J. Guo, and H. Huang, “Your vision-language model itself is a strong filter: Towards high-quality instruction tuning with data selection,” inFindings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computat...
2024
-
[11]
Least squares quantization in pcm,
S. P. Lloyd, “Least squares quantization in pcm,”IEEE Transactions on Information Theory, vol. 28, no. 2, pp. 129–137, 1982
1982
-
[13]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[14]
Active learning for convolutional neural net- works: A core-set approach,
O. Sener and S. Savarese, “Active learning for convolutional neural net- works: A core-set approach,” inInternational Conference on Learning Representations (ICLR), 2018
2018
-
[15]
Active learning literature survey,
B. Settles, “Active learning literature survey,”Computer Sciences Tech- nical Report 1648, University of Wisconsin–Madison, 2009
2009
-
[16]
Deep learning on a data diet: Finding important examples early in training,
M. Paul, S. Ganguli, and G. K. Dziugaite, “Deep learning on a data diet: Finding important examples early in training,”CoRR, vol. abs/2107.07075, 2021. [Online]. Available: https://arxiv.org/abs/2107.07075
-
[17]
Active learning on a budget: Opposite strategies suit high and low budgets,
G. Hacohen, A. Dekel, and D. Weinshall, “Active learning on a budget: Opposite strategies suit high and low budgets,” 2022. [Online]. Available: https://arxiv.org/abs/2202.02794
-
[18]
B. Safaei, F. Siddiqui, J. Xu, V . M. Patel, and S.-Y . Lo, “Filter images first, generate instructions later: Pre-instruction data selection for visual instruction tuning,” 2025. [Online]. Available: https://arxiv.org/abs/2503.07591
-
[19]
Concept-skill transferability-based data selection for large vision-language models,
J. Lee, B. Li, and S. J. Hwang, “Concept-skill transferability-based data selection for large vision-language models,” 2024. [Online]. Available: https://arxiv.org/abs/2406.10995
-
[20]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inInternational Conference on Machine Learning (ICML), 2021
2021
-
[21]
Low-Confidence Gold: Refining Low-Confidence Samples for Efficient Instruction Tuning
H. Cai, J. Li, M. M. Rahman, and W. Dong, “Low-confidence gold: Refining low-confidence samples for efficient instruction tuning,” 2025. [Online]. Available: https://arxiv.org/abs/2502.18978
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Mergeit: From selection to merging for efficient instruction tuning,
H. Cai, Y . Fu, H. Fu, and B. Zhao, “Mergeit: From selection to merging for efficient instruction tuning,” 2025. [Online]. Available: https://arxiv.org/abs/2503.00034
-
[23]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering,
Y . Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh, “Making the v in vqa matter: Elevating the role of image understanding in visual question answering,”CVPR, 2017
2017
-
[24]
Gqa: A new dataset for real-world visual reasoning and compositional question answering,
D. A. Hudson and C. D. Manning, “Gqa: A new dataset for real-world visual reasoning and compositional question answering,” inCVPR, 2019
2019
-
[25]
Scienceqa: A benchmark for science question answering through logical reasoning,
P. Lu, S. Mishra, T. Xia, L. Qiu, K.-W. Chang, S.-C. Zhu, O. Majumder, and A. Gopi, “Scienceqa: A benchmark for science question answering through logical reasoning,” inNeurIPS, 2022
2022
-
[26]
MMBench: Is Your Multi-modal Model an All-around Player?
Y . Liu, H. Duan, Y . Zhanget al., “Mmbench: Is your multi-modal model an all-around player?”arXiv preprint arXiv:2307.06281, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
C. Fu, P. Chen, Y . Shen, Y . Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sun, Y . Wu, R. Ji, C. Shan, and R. He, “Mme: A comprehensive evaluation benchmark for multimodal large language models,” 2025. [Online]. Available: https://arxiv.org/abs/2306.13394
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Textvqa: A benchmark for visual question answering on text-rich images,
A. Singh, V . Natarajan, M. Shah, Y . Jiang, X. Chen, D. Parikh, and M. Rohrbach, “Textvqa: A benchmark for visual question answering on text-rich images,” inCVPR, 2019
2019
-
[29]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,”NeurIPS, 2024
2024
-
[30]
Evaluating Object Hallucination in Large Vision-Language Models
Y . Li, Y . Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen, “Evaluating object hallucination in large vision-language models,” 2023. [Online]. Available: https://arxiv.org/abs/2305.10355
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Mm-vet: Evaluating large multimodal models for integrated capabilities,
W. Yu, Z. Zi, C. Cai, S. Varmaet al., “Mm-vet: Evaluating large multimodal models for integrated capabilities,” inICLR, 2024
2024
-
[32]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations (ICLR), 2022
2022
-
[33]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” 2021. [Online]. Available: https://arxiv.org/abs/2103.00020 APPENDIXA PSEUDO-CODE OF THEOFA FRAMEWORK Algorithm 1Once-For-All (OFA) Data Filteri...
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.