What Makes Chain-of-Thought Work at Probe Time? Local Co-occurrence Rather Than Global Derivation
Pith reviewed 2026-06-29 17:21 UTC · model grok-4.3
The pith
Chain-of-thought gains at probe time come from lexical activation and short-range token pairs rather than sentence-level logic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
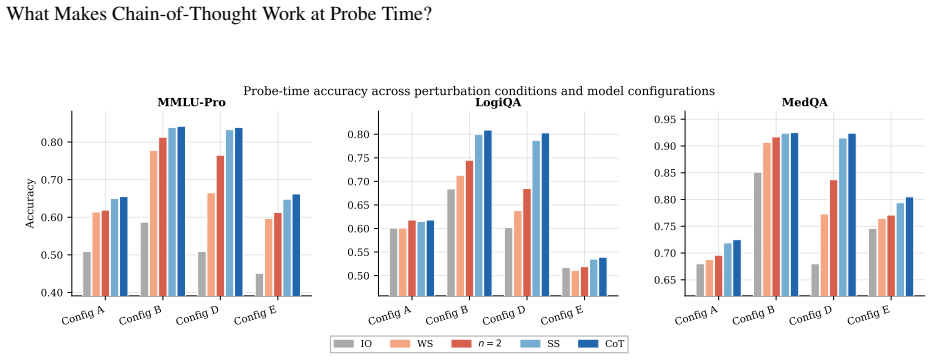
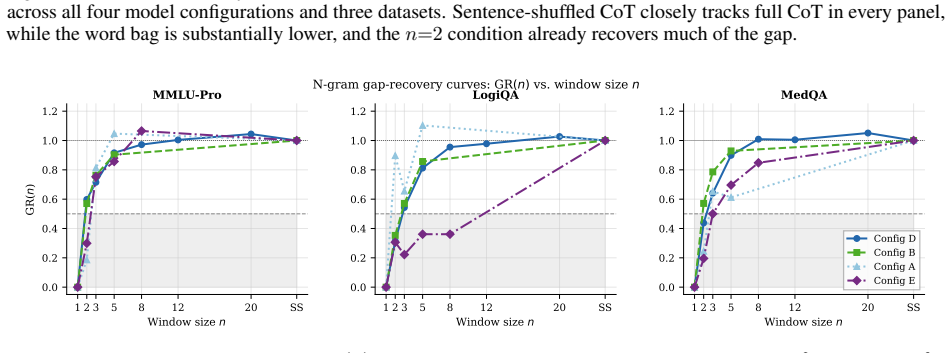
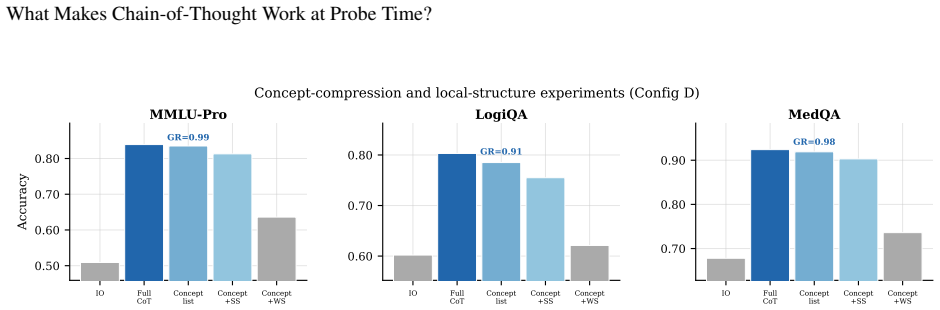
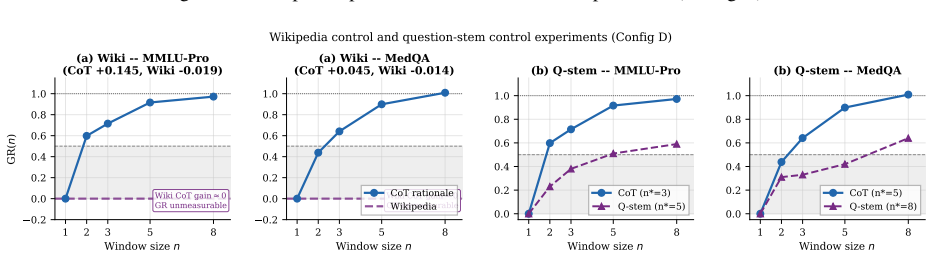
Even globally word-shuffled rationales substantially outperform the no-rationale baseline, indicating strong lexical activation; the remaining structured gain arises primarily from short-range token adjacency, as contiguous windows of n*=2--3 tokens recover most of the performance toward full CoT, while sentence-level logical ordering contributes less.
What carries the argument
Local co-occurrence activation (LCA), the account that attributes probe-time CoT gains to lexical activation plus short-range token adjacency rather than global logical derivation.
If this is right
- Gains from local patterns remain stable across multiple model families, parameter scales, and datasets.
- Copying of explicit answer declarations or answer values is not the primary driver.
- Full grammatical realization of sentences is not required for most of the structured gain.
- The benefit is driven by lexical activation together with short-range token co-occurrence.
Where Pith is reading between the lines
- Prompt engineering could focus on inserting key local phrases instead of complete reasoning sentences.
- Models may be using statistical token associations at inference time even when the prompt looks like a reasoning chain.
- Training objectives that emphasize local co-occurrences might reproduce much of the CoT benefit without explicit rationales.
- The same local-effect pattern may appear in other structured prompting methods beyond CoT.
Load-bearing premise
Word-shuffling and contiguous-window manipulations cleanly isolate lexical and local co-occurrence effects without leftover confounds such as implicit answer leakage.
What would settle it
An experiment in which logical sentence structure is preserved but all short contiguous windows are broken (for example by systematic interleaving of tokens) yet accuracy still rises would falsify the local-co-occurrence claim.
Figures
read the original abstract
Chain-of-thought (CoT) prompting reliably improves language-model accuracy, but which properties of a rationale text drive the improvement is poorly understood. Prior work has largely studied generation-time behavior. We instead ask a probe-time question: given a fixed rationale in context, what in that text changes the answer? We identify two complementary sources of the gain. First, even a globally word-shuffled rationale substantially outperforms the no-rationale baseline, indicating a strong lexical activation effect. More importantly, the additional gain from structured text appears to arise less from sentence-level logical ordering and more from short-range token adjacency. Preserving contiguous windows of just $n^\star{=}2$--$3$ tokens recovers most of the remaining gain toward full CoT performance. Supporting experiments rule out copying of explicit answer declarations or answer values, as well as full grammatical realization, as primary drivers. Further generalization experiments show that the qualitative pattern remains stable across multiple model families, parameter scales, and datasets. These results support a local co-occurrence activation (LCA) account of probe-time CoT, in which the observed gains appear to arise primarily from lexical activation and short-range token co-occurrence rather than sentence-level logical derivation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
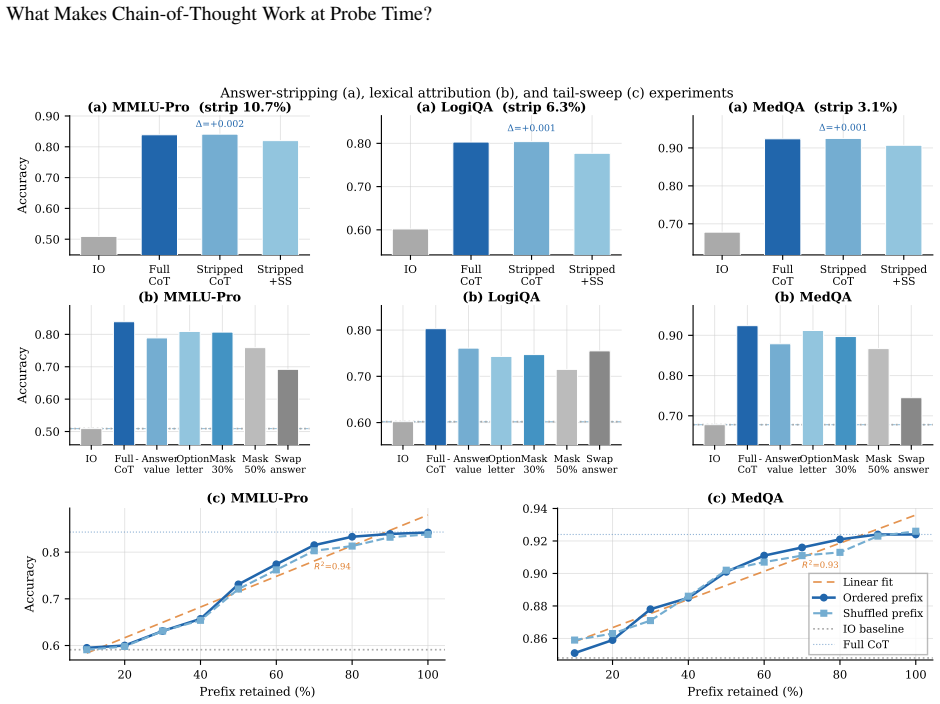
Summary. The paper examines what properties of a fixed rationale drive accuracy gains in chain-of-thought (CoT) prompting at probe time. Through ablation experiments, it reports that globally word-shuffled rationales still outperform no-rationale baselines (lexical activation effect), while contiguous windows of n=2–3 tokens recover most of the remaining gain toward full CoT performance; sentence-level logical ordering contributes little. Supporting controls rule out explicit answer copying and full grammatical realization as primary drivers, with the pattern stable across model families, scales, and datasets. The results are interpreted as supporting a local co-occurrence activation (LCA) account over global derivation.
Significance. If the ablation results hold after tighter controls, the work would provide concrete empirical evidence that probe-time CoT gains are driven more by local statistical patterns than by step-by-step logical structure. This would have implications for mechanistic interpretability and prompt engineering. The cross-model and cross-dataset generalization is a positive feature; the absence of any parameter fitting or self-referential quantities in the central claims is also a strength.
major comments (2)
- [Abstract] Abstract: the claim that n^*=2–3 windows 'recover most of the remaining gain' is load-bearing for the LCA interpretation, yet the abstract supplies no quantitative deltas, error bars, dataset sizes, or statistical tests. Without these values it is impossible to judge whether the residual gap to full CoT is small enough to support the 'primarily local co-occurrence' conclusion.
- [Abstract] Abstract (supporting experiments paragraph): the statement that experiments 'rule out copying of explicit answer declarations or answer values' is central to isolating local co-occurrence from leakage. The description provides no detail on whether answer tokens appear inside the n=2–3 windows, how windows are concatenated, or what controls test for non-explicit pattern leakage via attention; this leaves open the possibility that preserved bigram/trigram–answer associations from pretraining explain the residual gain.
minor comments (2)
- [Abstract] Abstract: quantitative results, error bars, and exact dataset/model counts should be stated in the abstract itself rather than deferred to later sections.
- The term 'local co-occurrence activation (LCA)' is introduced without a precise operational definition or contrast to existing notions of n-gram statistics; a short definitional paragraph would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree the abstract would benefit from added quantitative detail and clearer control descriptions, and we will revise accordingly. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that n^*=2–3 windows 'recover most of the remaining gain' is load-bearing for the LCA interpretation, yet the abstract supplies no quantitative deltas, error bars, dataset sizes, or statistical tests. Without these values it is impossible to judge whether the residual gap to full CoT is small enough to support the 'primarily local co-occurrence' conclusion.
Authors: We agree the abstract should include key numbers to support the claim. The body (Section 4.2, Figure 3) reports that on GSM8K with Llama-7B, n=3 windows recover ~82% of the full CoT gain (mean over 5 seeds, SE < 3%), with similar fractions (75-88%) on other datasets; the residual gap is statistically significant but small relative to the lexical baseline. We will add concise deltas, error-bar mention, dataset sizes, and a note on stability to the abstract. revision: yes
-
Referee: [Abstract] Abstract (supporting experiments paragraph): the statement that experiments 'rule out copying of explicit answer declarations or answer values' is central to isolating local co-occurrence from leakage. The description provides no detail on whether answer tokens appear inside the n=2–3 windows, how windows are concatenated, or what controls test for non-explicit pattern leakage via attention; this leaves open the possibility that preserved bigram/trigram–answer associations from pretraining explain the residual gain.
Authors: Answer tokens are excluded from all windows (final answer declaration is always appended separately after the rationale). Windows are formed by sliding contiguous n-token spans over the rationale text and concatenating them in original order while breaking sentence boundaries. Section 5.1 and Appendix C describe the explicit-answer removal control and a within-window bigram-shuffle ablation that reduces the residual gain, indicating the effect is not solely pretraining bigram–answer associations. Attention visualizations (Appendix B) further show localized rather than long-range answer leakage. We will expand the abstract paragraph to note these points briefly. revision: partial
Circularity Check
No circularity: purely empirical ablation study with no derivations or self-referential reductions
full rationale
The paper conducts an empirical investigation via word-shuffling and n=2-3 window manipulations on fixed rationales, measuring accuracy changes across models and datasets. No equations, fitted parameters, or derivation chains are present that could reduce to inputs by construction. Claims rest on experimental controls (explicit copying ruled out) rather than self-citations, ansatzes, or uniqueness theorems. The LCA account is an interpretive summary of ablation results, not a self-definitional or fitted prediction. This matches the default case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Shuffling and contiguous-window manipulations isolate lexical activation and short-range co-occurrence without introducing artifacts or residual logical structure.
invented entities (1)
-
Local Co-occurrence Activation (LCA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[2]
Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
2022
-
[3]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Show your work: Scratchpads for intermediate computation with language models
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, et al. Show your work: Scratchpads for intermediate computation with language models. 2021
2021
-
[5]
Chain-of-thoughts prompting with language models for accurate math problem-solving
Sze Ching Evelyn Fung, Man Fai Wong, and Chee Wei Tan. Chain-of-thoughts prompting with language models for accurate math problem-solving. In2023 IEEE MIT Undergraduate Research Technology Conference (URTC), pages 1–5. IEEE, 2023
2023
-
[6]
Towards better chain-of-thought prompting strategies: A survey.arXiv preprint arXiv:2310.04959, 2023
Zihan Yu, Liang He, Zhen Wu, Xinyu Dai, and Jiajun Chen. Towards better chain-of-thought prompting strategies: A survey.arXiv preprint arXiv:2310.04959, 2023. 9 What Makes Chain-of-Thought Work at Probe Time?
-
[7]
Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.Advances in Neural Information Processing Systems, 36:74952–74965, 2023
2023
-
[8]
Faithful logical reasoning via symbolic chain-of-thought
Jundong Xu, Hao Fei, Liangming Pan, Qian Liu, Mong-Li Lee, and Wynne Hsu. Faithful logical reasoning via symbolic chain-of-thought. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13326–13365, 2024
2024
-
[9]
Austin Meek, Eitan Sprejer, Iván Arcuschin, Austin J Brockmeier, and Steven Basart. Measuring chain-of-thought monitorability through faithfulness and verbosity.arXiv preprint arXiv:2510.27378, 2025
-
[10]
Walk the talk? measuring the faithfulness of large language model explanations
Katie Matton, Robert Ness, John Guttag, and Emre Kiciman. Walk the talk? measuring the faithfulness of large language model explanations. InInternational Conference on Learning Representations, volume 2025, pages 73212–73277, 2025
2025
-
[11]
Faithcot-bench: Benchmarking instance-level faithfulness of chain-of-thought reasoning
Xu Shen, Song Wang, Zhen Tan, Laura Yao, Xinyu Zhao, Kaidi Xu, Xin Wang, and Tianlong Chen. Faithcot- bench: Benchmarking instance-level faithfulness of chain-of-thought reasoning.arXiv preprint arXiv:2510.04040, 2025
-
[12]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Towards revealing the mystery behind chain of thought: a theoretical perspective.Advances in Neural Information Processing Systems, 36:70757– 70798, 2023
Guhao Feng, Bohang Zhang, Yuntian Gu, Haotian Ye, Di He, and Liwei Wang. Towards revealing the mystery behind chain of thought: a theoretical perspective.Advances in Neural Information Processing Systems, 36:70757– 70798, 2023
2023
-
[14]
Iteration head: A mechanistic study of chain-of-thought.Advances in Neural Information Processing Systems, 37:109101–109122, 2024
Vivien Cabannes, Charles Arnal, Wassim Bouaziz, Alice Yang, Francois Charton, and Julia Kempe. Iteration head: A mechanistic study of chain-of-thought.Advances in Neural Information Processing Systems, 37:109101–109122, 2024
2024
-
[15]
How does chain of thought think? mechanistic interpretability of chain-of-thought reasoning with sparse autoencoding
Xi Chen, Aske Plaat, and Niki van Stein. How does chain of thought think? mechanistic interpretability of chain-of-thought reasoning with sparse autoencoding. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 30297–30305, 2026
2026
-
[16]
Text and patterns: For effective chain of thought, it takes two to tango
Aman Madaan and Amir Yazdanbakhsh. Text and patterns: For effective chain of thought, it takes two to tango. arXiv preprint arXiv:2209.07686, 2022
-
[17]
Towards understanding chain-of-thought prompting: An empirical study of what matters
Boshi Wang, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer, and Huan Sun. Towards understanding chain-of-thought prompting: An empirical study of what matters. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2717–2739, 2023
2023
-
[18]
Jacob Pfau, William Merrill, and Samuel R Bowman. Let’s think dot by dot: Hidden computation in transformer language models.arXiv preprint arXiv:2404.15758, 2024
-
[19]
Chain-of-thought is not explainability.Preprint, alphaXiv, page v1, 2025
Fazl Barez, Tung-Yu Wu, Iván Arcuschin, Michael Lan, Vincent Wang, Noah Siegel, Nicolas Collignon, Clement Neo, Isabelle Lee, Alasdair Paren, et al. Chain-of-thought is not explainability.Preprint, alphaXiv, page v1, 2025
2025
-
[20]
Chain-of-Thought Reasoning In The Wild Is Not Always Faithful
Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy. Chain-of-thought reasoning in the wild is not always faithful.arXiv preprint arXiv:2503.08679, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning. arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Diagnosing memorization in chain-of-thought reasoning, one token at a time
Huihan Li, You Chen, Siyuan Wang, Yixin He, Ninareh Mehrabi, Rahul Gupta, and Xiang Ren. Diagnosing memorization in chain-of-thought reasoning, one token at a time. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3158–3180, 2025
2025
-
[23]
Can language models perform robust reasoning in chain-of-thought prompting with noisy rationales?Advances in Neural Information Processing Systems, 37:123846–123910, 2024
Zhanke Zhou, Rong Tao, Jianing Zhu, Yiwen Luo, Zengmao Wang, and Bo Han. Can language models perform robust reasoning in chain-of-thought prompting with noisy rationales?Advances in Neural Information Processing Systems, 37:123846–123910, 2024
2024
-
[24]
Zhen Xiang, Fengqing Jiang, Zidi Xiong, Bhaskar Ramasubramanian, Radha Poovendran, and Bo Li. Badchain: Backdoor chain-of-thought prompting for large language models.arXiv preprint arXiv:2401.12242, 2024
-
[25]
Preemptive answer “attacks” on chain-of-thought reasoning
Rongwu Xu, Zehan Qi, and Wei Xu. Preemptive answer “attacks” on chain-of-thought reasoning. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14708–14726, 2024
2024
-
[26]
Kun Zhang, Le Wu, Kui Yu, Guangyi Lv, and Dacao Zhang. Evaluating and improving robustness in large language models: a survey and future directions.arXiv preprint arXiv:2506.11111, 2025. 10 What Makes Chain-of-Thought Work at Probe Time?
-
[27]
Zongqian Wu, Baoduo Xu, Ruochen Cui, Mengmeng Zhan, Xiaofeng Zhu, and Lei Feng. Rethinking chain-of- thought from the perspective of self-training.arXiv preprint arXiv:2412.10827, 2024
-
[28]
Why think step by step? reasoning emerges from the locality of experience.Advances in Neural Information Processing Systems, 36:70926–70947, 2023
Ben Prystawski, Michael Li, and Noah Goodman. Why think step by step? reasoning emerges from the locality of experience.Advances in Neural Information Processing Systems, 36:70926–70947, 2023
2023
-
[29]
Xiaojuan Tang, Zilong Zheng, Jiaqi Li, Fanxu Meng, Song-Chun Zhu, Yitao Liang, and Muhan Zhang. Large lan- guage models are in-context semantic reasoners rather than symbolic reasoners.arXiv preprint arXiv:2305.14825, 2023
-
[30]
the answer is
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 13358–13376, 2023. A Full Experimental Setup A.1 Models and Configurations Table 3 lists the four generator–p...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.